







github链接:https://github.com/kaonashi-tyc/Rewrite
网络的结构框架以及相关参数:

每个卷积层后面是一个批处理归一化层,然后是一个ReLu层,一直到零填充。
正如Erik的博客中提到的,该网络针对预测输出和地面真相之间的像素级MAE(平均绝对误差)最小化,而不是更常用的MSE(均方误差)。MAE往往会产生更清晰、更清晰的图像,而MSE则会产生更模糊和偏灰的图像。同时,利用全变差损失来提高图像的平滑度。
层数n是可配置的,n越大,输出越详细,越干净,但需要更长的训练时间,通常选择在[2,4]之间。大于4的选项似乎达到了收益递减的点,增加了运行时间,但对损失或输出都没有明显的改善。
为了更好的细节,大的卷积。在我的实验中,我开始使用直接堆叠的普通3x3卷积,但它最终表现很差,或者在更困难和奇异的字体上没有收敛。所以我最终得到了这个向下延伸的形状架构,在不同的层上有不同大小的卷积,每个卷积包含大约相同数量的参数,所以网络可以在不同的层次上捕捉细节。
Dropout是收敛的必要条件。如果没有它,网络就会放弃或陷入琐碎的解决方案,就像所有的白色或黑色图像一样。
Erik和Shumeet的工作中使用的全连接层对汉字的效果不太好,产生更嘈杂和不稳定的输出。我的猜测是,汉字的结构要复杂得多,本质上更接近图像,而不是字母,所以基于CNN的方法在这种情况下更有意义。
与真实世界的图像不同,我们可以生成任意分辨率的字符图像。这一事实可以利用高分辨率源图像来近似低分辨率目标,从而保留更多的细节,并避免模糊和噪声。

顶部的图像显示了训练期间在验证集上所做的模型的进展,使用各种字体。它们都在2000个样例上进行训练,层数设置为3。看到模型如何从随机噪声慢慢收敛,首先捕捉角色的可识别形状,然后捕捉到更细微的细节是非常有趣的。下面是在训练过程中为单个字体捕获的进度。

与实际情况比较下图显示了预测结果与实际情况的对比。对于每种字体,我们以2000个最常用的字符作为训练集,运行3000次迭代。使用100个字符的测试集进行推理。对于所有字体,源字体都是SIMSUN。

对于大多数字体,网络成功地做出了合理的猜测。其中一些实际上非常接近事实。同样值得注意的是,网络保留了微小但可区分的细节,比如激进分子的卷曲端。
但就像许多其他神经网络驱动的应用程序一样,当网络失败时,它会失败得非常壮观。对于一些字体,尤其是那些重量很轻的字体,它只会出现一些模糊的墨水斑点。另一方面,对于那些沉重的字体,它失去了空格的关键细节,使字符可区分,只捕捉整体轮廓。即使在成功的案例中,部分自由基的丢失似乎也是一个普遍的问题。此外,网络似乎在松体字体家族(宋体或明朝体)上做得更好,但在KaiTi(楷体)上做得不好,这可能是因为SIMSUN本身是松体字体。
由于空间的限制,对于每种字体,我们从测试集中随机抽取一个字符。如果你希望看到更大的字符测试集的结果,请参考这个###需要多少字符?2000个字符可能是整个GBK标准的10%,但这仍然是很多字符。我选择这个数字是出于我的本能,它似乎适用于许多字体。但这真的有必要吗?
为了弄清楚这一点,我选择了一种字体(遗憾的是,在每种字体上进行这个实验花费了太多的时间),运行了一个训练示例的实验,范围从500到2000,并要求模型在一个公共测试集上呈现字符,如下所示。

上图从上到下显示了训练集从500增加到2000的效果。在训练1500和2000之间,改善变得更小,这表明甜蜜点在两者之间。要使用这个包,需要安装TensorFlow(在0.10.0版本上测试)。其他python要求在requirements.txt中列出。另外,如果你希望在合理的时间内看到结果,强烈建议使用GPU。
所有实验都在一台Nvidia GTX 1080上运行。3000次迭代,batch size为16,小型模型大约需要20分钟,中型模型需要80分钟,大型模型需要2小时。(实测大概要1天)
实验步骤
在训练之前,您需要运行预处理脚本为源字体和目标字体生成字符位图:
python preprocess.py --source_font src.ttf
–target_font tgt.otf
–char_list charsets/top_3000_simplified.txt \
–save_dir path_to_save_bitmap
预处理脚本接受TrueType和OpenType字体,获取字符列表(一些常用字符集内置在这个repo的字符集目录中,比如最常用的3000个简体中文字符),然后以.npy格式保存这些字符的位图。默认情况下,对于源字体,每个字符的字体大小为128,保存在160x160的画布上,而目标字体大小为64,保存在80x80的画布上。这里不需要特殊的对齐方式,只需要确保字符不会被截断。
在预处理步骤之后,假设您已经有了源字体和目标字体的位图,标记为src. npy 和 tgt. npy,执行以下命令开始实际训练:
python rewrite.py --mode=train \
–model=medium
–source_font=src.npy
–target_font=tgt.npy \
–iter=3000
–num_examples=2100
–num_validations=100
–tv=0.0001
–alpha=0.2
–keep_prob=0.9 \
–num_ckpt=10
–ckpt_dir=path_to_save_checkpoints \
–summary_dir=path_to_save_summaries
–frame_dir=path_to_save_frames
这里有一些解释:
–mode:既可以是训练模式,也可以是推断模式,前者不言自明,后面再讲推断模式。
–model:这里表示模型的大小。有3种选择:小,中或大,相对于层数等于2,3,4。
–tv:总变化损失的权重,默认为0.0001。如果输出看起来破碎或不和谐,您可以选择增强它以迫使模型生成更平滑的输出
–Alpha:泄漏relu使用的Alpha斜率。启用它可能会看到某些字体的一些改进,但需要更长的训练时间。
–keep_prob:表示训练过程中某个值通过Dropout层的概率。这实际上是一个非常重要的参数,概率越高,预期的输出就越尖锐,但可能会断裂。如果效果不好,可以尝试降低数值,得到更嘈杂但更圆润的形状。典型的选项是0.5或0.9。
–Ckpt_dir:存储模型检查点的目录,用于后面的推断步骤。
–summary_dir:如果你想使用TensorBoard来可视化一些指标,比如迭代损失,这是保存所有摘要的地方。默认为/tmp/summary。您可以检查训练批次的损耗,以及验证集的损耗,以及它的分解。
–Frame_dir:在验证集中保存捕获输出的目录。用于选择推理的最佳模型。训练结束后,您还可以找到一个名为transition.gif的文件,向您展示模型在训练期间的动画进展,也是在验证集上。
对于其他选项,您可以使用-h签出确切的使用情况。
现在我们可以使用前面提到的推断模式来查看模型对未见字符的处理情况。您可以参考frame_dir中的捕获帧来帮助您选择最满意的模型checkpionts(剧透:它通常不是误差最小的模型)。运行以下命令:
python rewrite.py --mode=infer
–model=medium
–source_font=src.npy
–ckpt=path_to_your_favorite_model_checkpoints
–bitmap_dir=path_to_save_the_inferred_output
注意source_font可能与训练中使用的不同。事实上,它甚至可以是任何其他字体。但最好选择相同或相似的字体进行推断,以获得良好的输出。推理之后,您将发现所有输出字符的一系列图像和一个包含推理字符位图的npy文件。
环境参数配置
Pillow=9.1.1
scipy=1.10.1
numpy=1.21.5
imageio=2.4.1
tensorflow=2.11.0
torch=1.10.1+cu102
matplotlib=3.7.0
torchaudio= 0.10.1+cu102
python=3.9.2
torchvision =0.11.2+cu102
bug处理
首先是preprocess.py文件
1.将reload(sys)和sys.setdefaultencoding(“utf-8”)删除

2.with open(path) as f:
替换成with open(path, ‘r’, encoding=‘utf-8’) as f:

然后是utils.py文件
3.misc.toimage(canvas).save(path)
替换成image.imsave(path, canvas, cmap=‘gray’)
4.并在文件的开头from matplotlib import image


再然后是修改rewrite.py文件
5.在该文件的开头将import tensorflow as tf
替换成 import tensorflow._api.v2.compat.v1 as tf
tf.compat.v1.disable_v2_behavior()
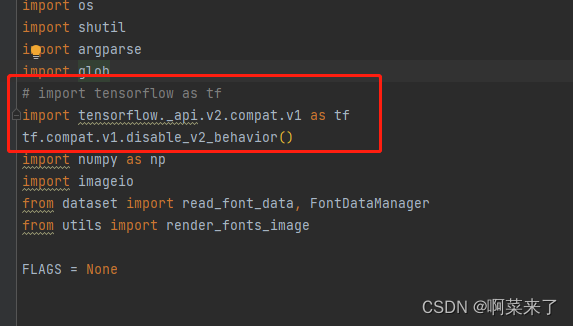
6.将tf.scalar_summary替换成tf.summary.scalar
将tf.merge_all_summaries()替换成tf.summary.merge_all()
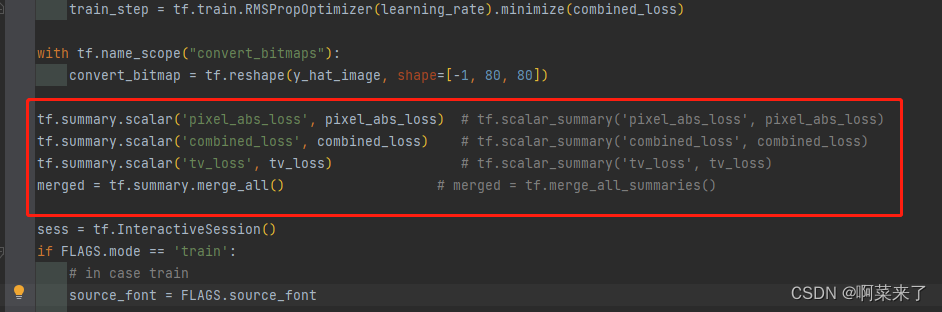
7.将tf.train.SummaryWriter替换成tf.summary.FileWriter

8.设置好相关的路劲
bug修改完后
在修改完bug后就进入训练了(附上一张在训练中的截图)

不懂他为啥用的cpu训练。怪怪的,用了一个下午的时间训练。
















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











