






k近邻算法是一种基本分类和回归方法
基本原理
给定一个数据集,对新输入的样例进行比较,找到最邻近的K个样例,这K个样例的多数属于哪一类,则这个输入也属于哪一类,也就是利用服从多数的性质对输入进行分类。
距离
上文中出现的两个重要量,一个是最邻近也就是指距离,一个是K,这里先对距离进行解释。
距离分为两种 一种是欧氏距离,一种是曼哈顿距离,以下公式参考于现有资料

简单解释一下,欧氏距离就是在多维空间中直接计算两点之间的距离,可以参考平面直角坐标系中计算的两点间距离,而曼哈顿距离是平面直角坐标系中两点的X,Y的差值和,也就是X2-X1,再计算Y2-Y1,得到的就是只能通过水平和竖直方向上的移动到达的第二个点的距离,也就是曼哈顿距离。
K值
K值的选择也十分重要,当K过大时,模型会过于简单,因为这样将会在一个较大的范围内选择较多的一类,也就变成了对现有实例进行分类的作用,而K值较小时,容易学习到噪音,周围存在多个噪声点时,输出结果会与噪声点一致出现错误,所以需要用各种方法寻找该参数的最优值。
归一化
在回归问题中,当出现的数据较大时,可能会出现单方面数据主导训练结果的情况,为了解决这个问题,往往采用加权处理的方法,例如归一化处理
newValue = (oldValue - min) / (max - min)这个公式就可以将数据集中在0~1之间,使训练结果更加科学客观
实现

对给定的数据集进行处理,此处返回的是矩阵和元素标签。
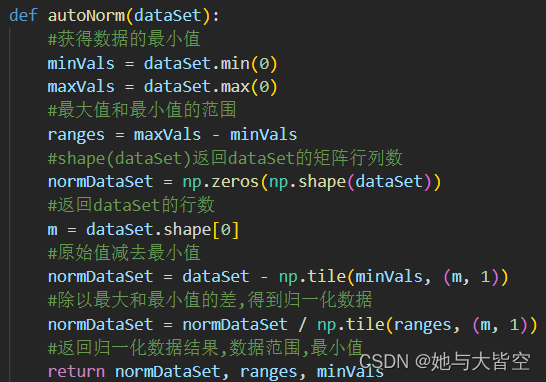
根据上述原因进行归一化处理

创建分类器给后续进行使用
这里用特征归一化后的矩阵,取一部分进行测试,数量为m*0.1,得到错误率为百分之4,但是当m*0.05时会变成百分之0.000,我的理解是存在偏差,而不是完全没有误差,因为测试样例太少,测试出来都符合,所以为0。
最后写一段把前面函数进行调用,输入5000,70,1得到结果为第1类















 1624
1624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









