






基本原理
x,y同时发生的概率为

所以可以得到
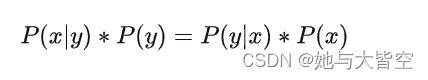

朴素贝叶斯
NaïveBayes算法,又叫朴素贝叶斯算法。
朴素:特征条件独立;贝叶斯:基于贝叶斯定理。属于监督学习的生成模型,实现简单,没有迭代,并有坚实的数学理论(即贝叶斯定理)作为支撑。在大量样本下会有较好的表现,不适用于输入向量的特征条件有关联的场景。朴素贝叶斯(Naive Bayesian)是基于贝叶斯定理和特征条件独立假设的分类方法,它 通过特征计算分类的概率,选取概率大的情况,是基于概率论的一种机器学习分类(监督学习)方法。
当发生的事件非常多时,我们可以依据这个方式算出某事件发生的概率,公式如下
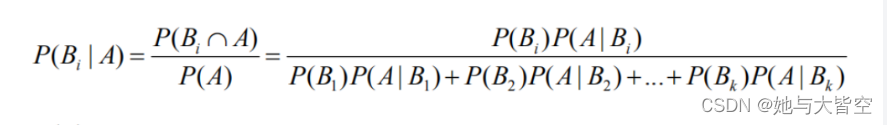
这里的A就是根据历史经验得出的能够对B进行分类的概率,即是经验所得,也被称为先验概率。
而与之相反的就是后验概率,是当知道了所有样本后,得到B的概率。
拉普拉斯修正
在求先验概率时,某个事件B与A没有同时发生过,则将其概率记为0,这样在计算连续型概率时便会将概率置零,这样明显是不符合客观事实的,因此为了解决这个问题,我们引入Laplace校准(这就引出了我们的拉普拉斯平滑),它的思想非常简单,就是对每个类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
防溢出
条件概率乘法计算过程中,因子一般较小(均是小于1的实数)。当属性数量增多时候,会导致累乘结果下溢出的现象。 在代数中有ln(a*b) = ln(a)+ln(b),因此可以把条件概率累乘转化成对数累加。分类结果仅需对比概率的对数累加法运算后的数值,以确定划分的类别。
应用实例垃圾邮件分类
准备数据集

定义分类器训练函数

定义分类函数
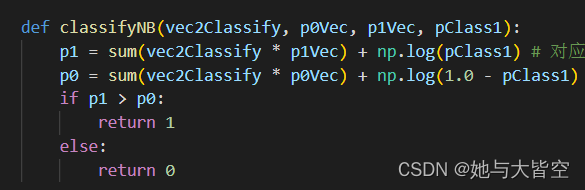
分类器实现


将邮件转换为字符串列表进行处理(文件预处理部分不展示)
将数据集随机标注分为训练集和测试集,遍历进行模型训练,然后对测试集进行测试并计算错误率
结构如下所示

![]()















 2745
2745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









