






对bilibili平台的评论进行获取,包含(角色ID,角色名称,评论ID,评论时间,点赞)
对于数据采集,需要获取网页,网页解析,数据获取三步骤
1.网页获取
bilibili上二次元同学比较多,那么就把网页定在二次元上:
进入网页,F12打开开发者页面;
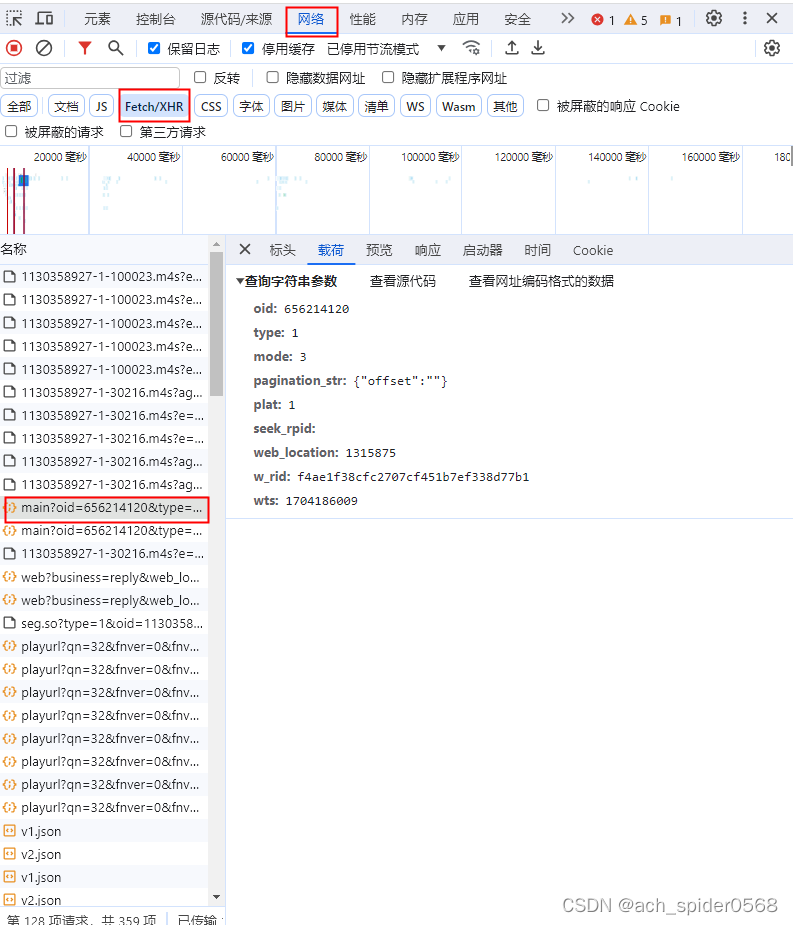
对于如何确定在那个列表下,可以让其按照大小进行排序,然后再把网页上的内容搜索进行确认;
既然已经确定了是main?oid=.......这个链接那么对其进行获取;
最简单无脑的方式:
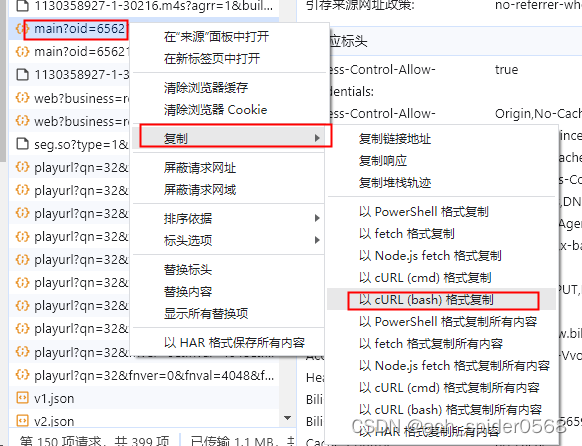
复制这个url的curl(bash)然后将内容复制至Convert curl commands to code
转化为python语言,然后将内容复制到python编译器中,添加输出,就可以拿到这个reponse
然后再对内容信息进行分析提取;
不过这样也会导致很多问题,譬如没有登录只有少量的评论,不灵活,翻页等
2.网页解析
首先,先登录自己的账号,这样就可以看完整的评论了;
然后开始正式的分析网页,还是刚刚的main?oid=,这个时候就可以发现 这个响应的内容对于整个评论信息是不完整的,鼠标齿轮下滑再进行获取数据,加载出新的页面,再继续滑动获取三个页面的信息,进行分析;
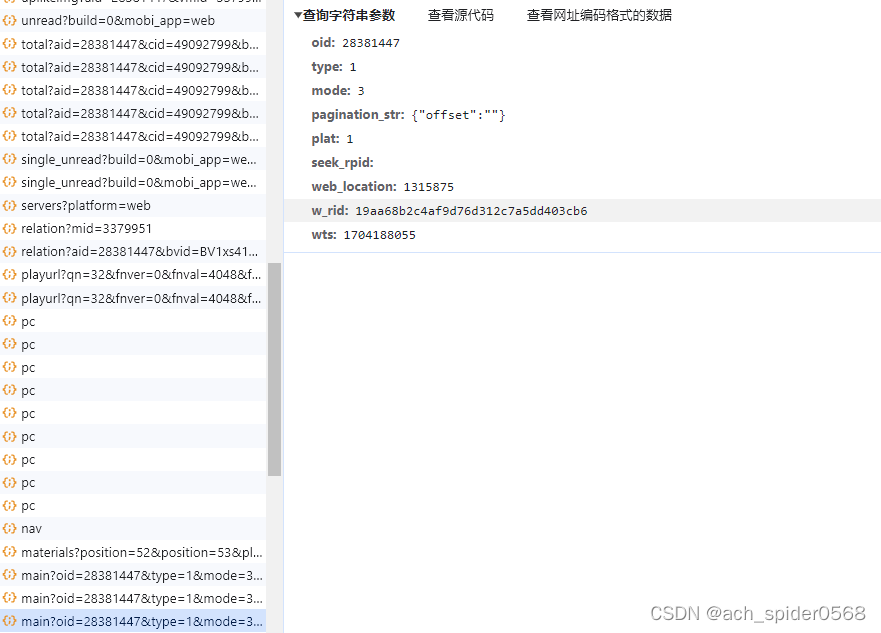
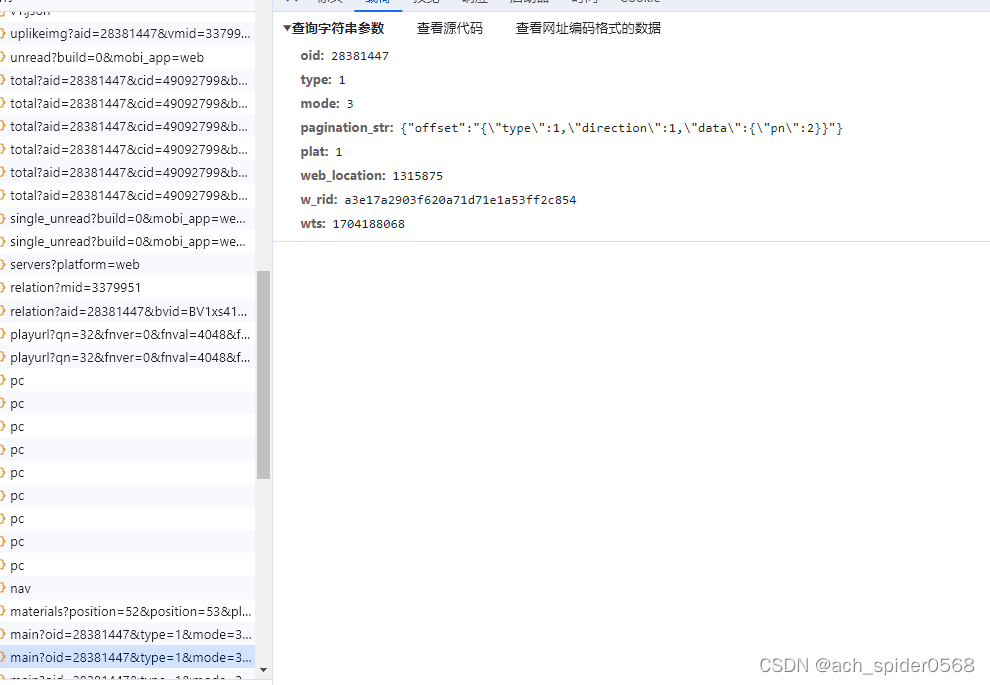
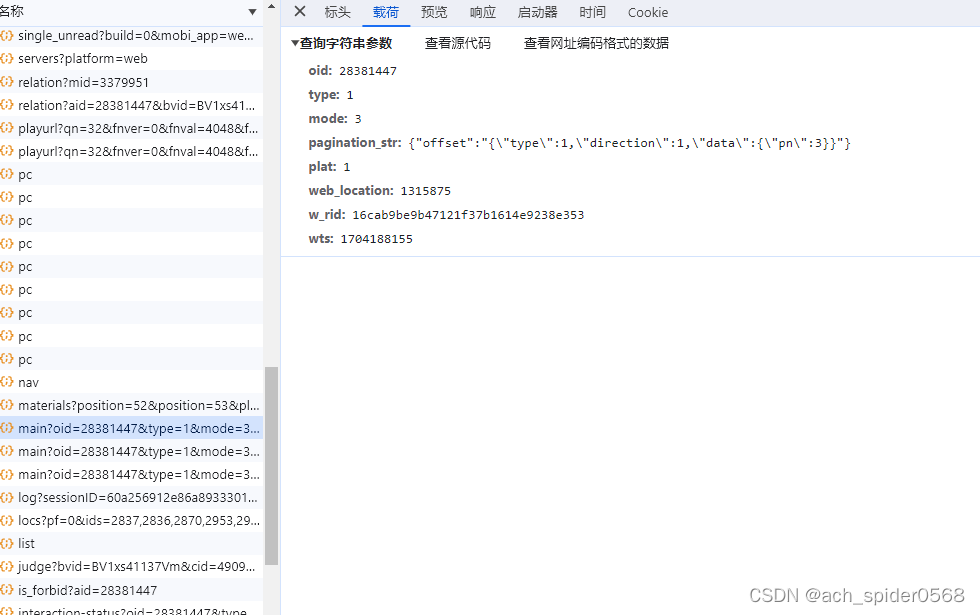
第一页和第二页,第三页的区别很明显pagination_str结构不同,第一页字段多个seek_rpid,还有就是w_rid和wts的不同,第二页和第三页的区别就是pagination_str中pn的增加,很明显第几页对应的就是多少,同时w_rid和wts也是不同的(有些基础的可以感受到wts可能就是时间戳,w_rid就就是需要解析的部分)
接下来,开始对评论的首页进行分析获取;
w_rid这个字段,是需要逆向解析的,可以通过跑断点在源代码中发现进行分析;可以使用关键词搜索的方法;全局搜索,找到加密的位置,分析解析,代码实现;步骤如下:
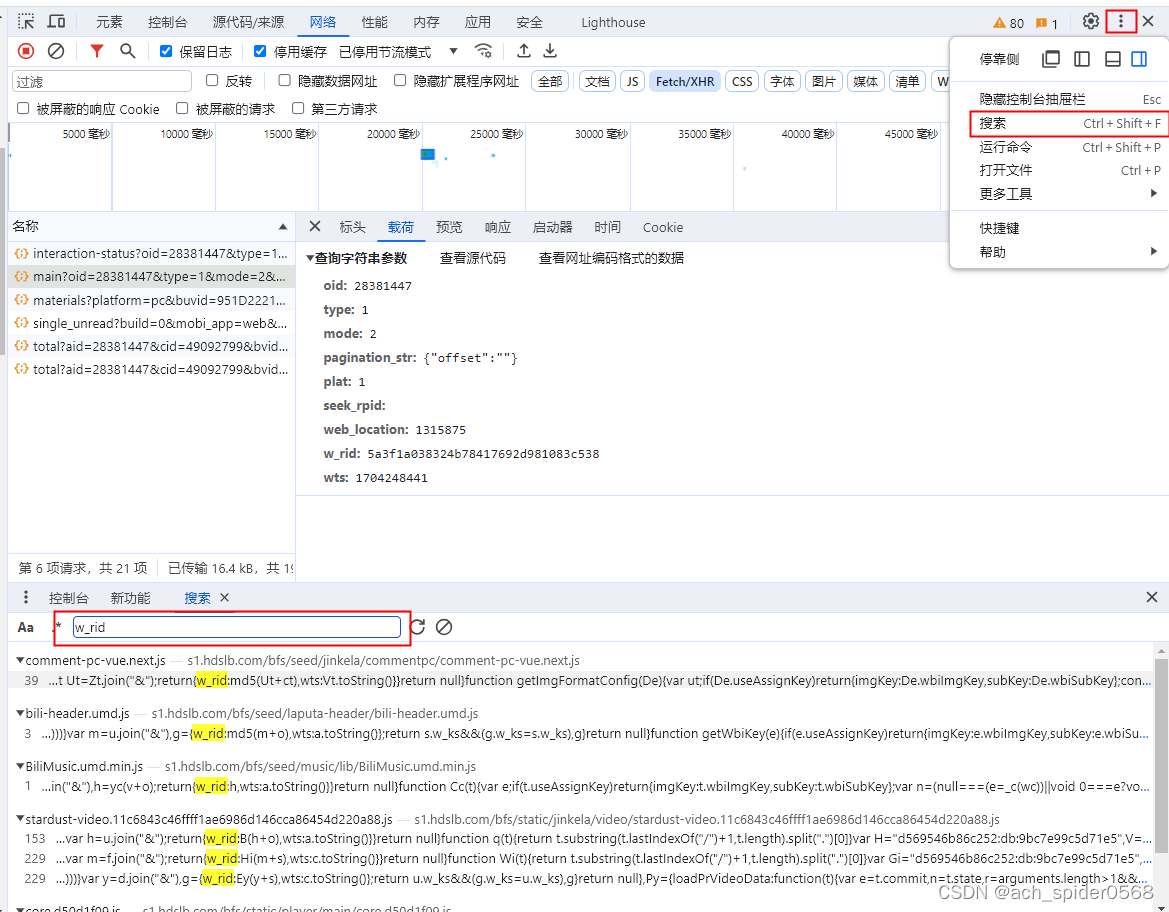
搜索到;
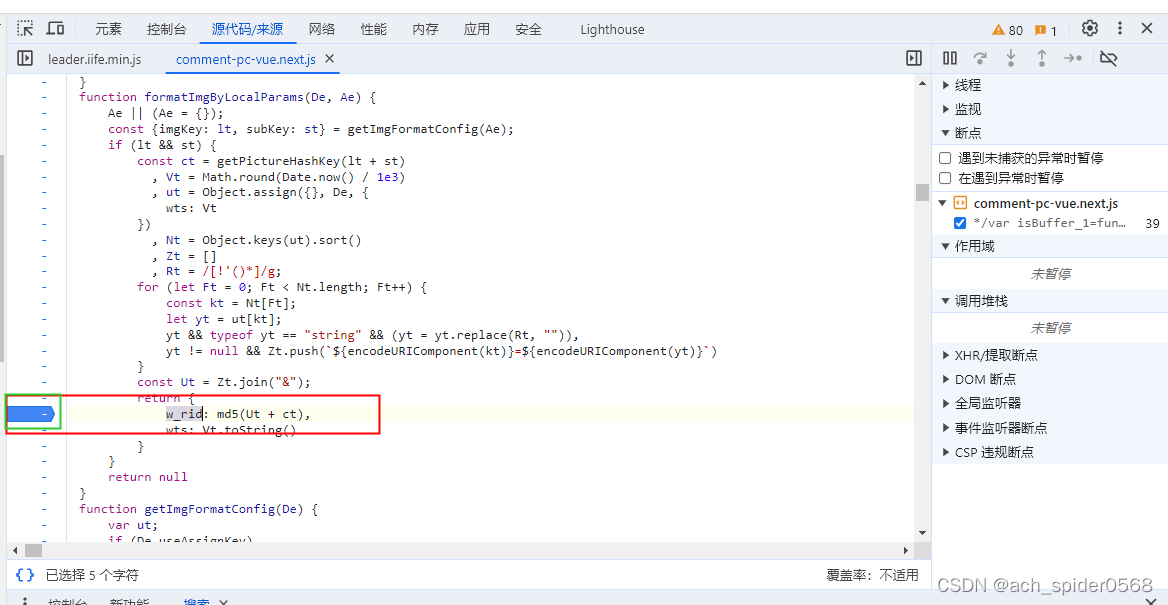
然后切换,进行断点

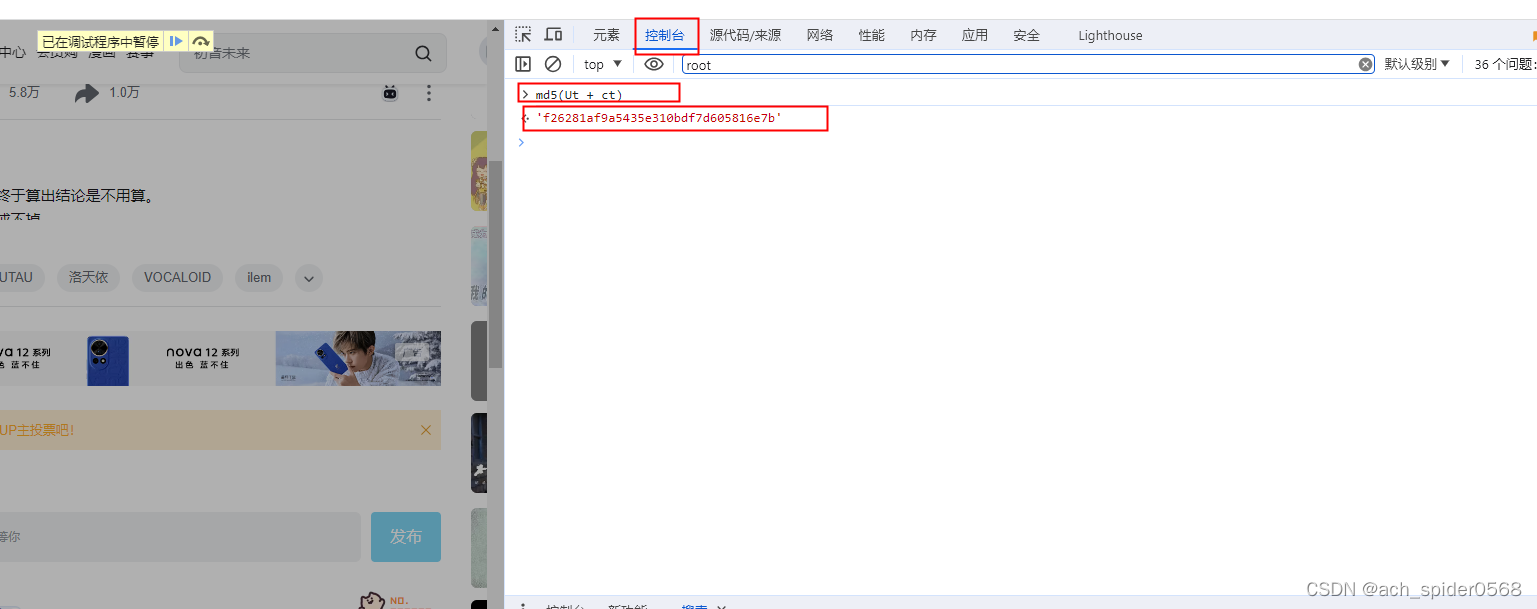
将加密的在控制台中输出,得到密文
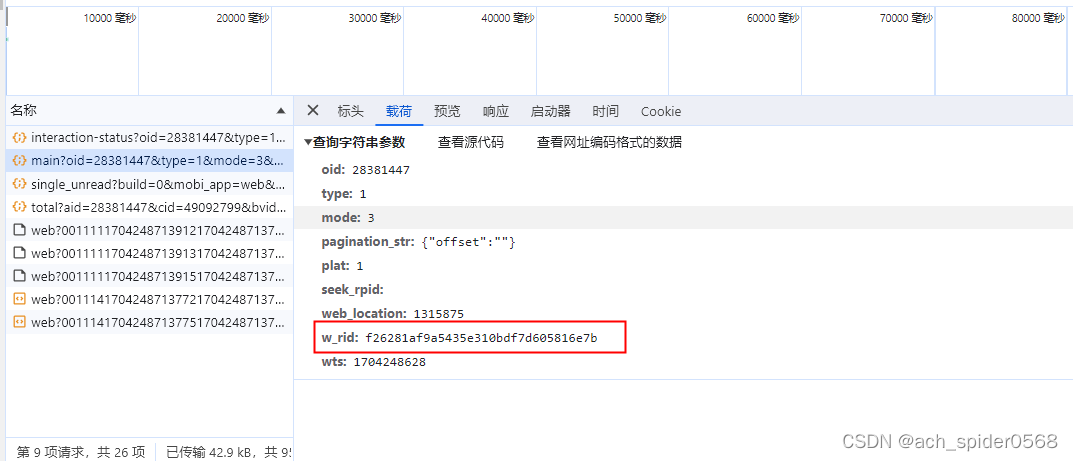
释放后可以发现就是在此处进行加密的
w_rid: md5(Ut + ct)
通过md5方法,分析一个Ut和ct,也是通过跑断点去解析的;然后在控制台中进行输出

ct是固定值,可以多更改基础发现还是不变的,Ut是拼出来的
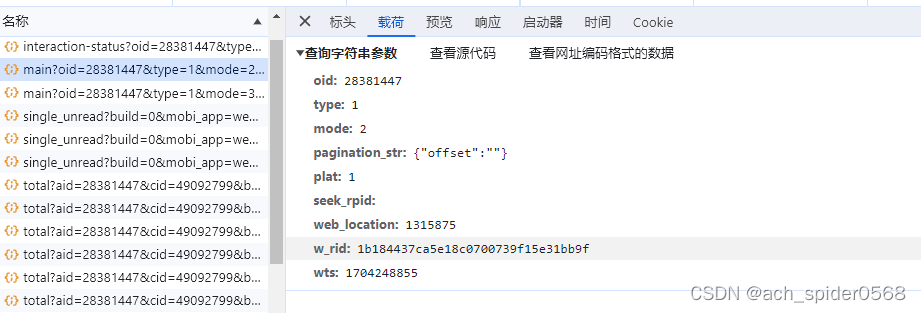
ut是根据这个载荷中信息拼凑的 oid就是这个视频ID,mode(2:视频评论按照最新排序,3:视频评论按照最热排序),pagination_str分页,w_rid逆向,wts时间戳;按照顺序拼凑至Ut中,第二页的区别也就是在pagination_str这个字段中。加密方式是一致的
wts:时间戳 python实现(str(int(time.time())))
接下来代码解析过程
md5在python中实现:
def md5_encrypt(string):
m = hashlib.md5()
m.update(string.encode("utf8"))
return m.hexdigest()
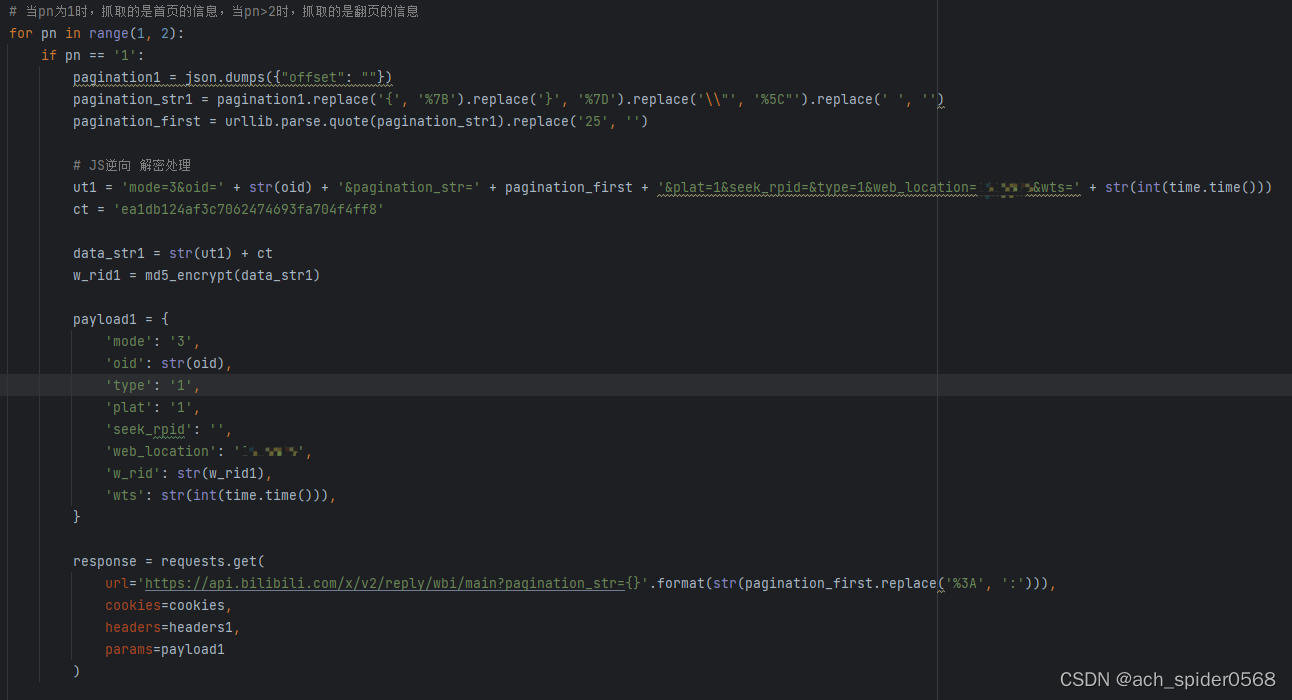
# 分页参数的两种情况 首页和翻页 先访问首页 再访问翻页内容
pagination1 = json.dumps({"offset": ""})
pagination_str1 = pagination1.replace('{', '%7B').replace('}', '%7D').replace('\\"', '%5C"').replace(' ', '')
pagination_first = urllib.parse.quote(pagination_str1).replace('25', '')
# JS逆向 解密处理
ut1 = 'mode=3&oid=' + str(oid) + '&pagination_str=' + pagination_first + '&plat=1&seek_rpid=&type=1&web_location=(载荷中的显示)&wts=' + str(int(time.time()))
ct = 'ea1db124af3c7062474693fa704f4ff8'
data_str1 = str(ut1) + ct
w_rid1 = md5_encrypt(data_str1)
这样就可以解析出首页的了
翻页也是一样的解析过程;
代码如下:
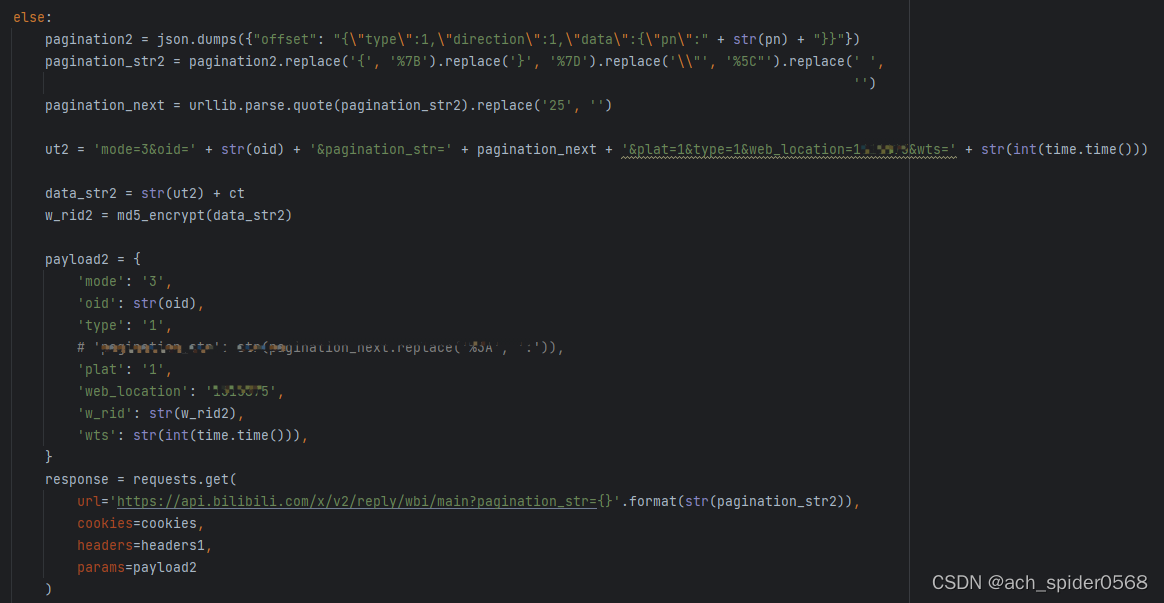
pagination2 = json.dumps({"offset": "{\"type\":1,\"direction\":1,\"data\":{\"pn\":" + str(pn) + "}}"})
pagination_str2 = pagination2.replace('{', '%7B').replace('}', '%7D').replace('\\"', '%5C"').replace(' ','')
pagination_next = urllib.parse.quote(pagination_str2).replace('25', '')
ut2 = 'mode=3&oid=' + str(oid) + '&pagination_str=' + pagination_next + '&plat=1&type=1&web_location=1315875&wts=' + str(int(time.time()))
data_str2 = str(ut2) + ct
w_rid2 = md5_encrypt(data_str2)
pagination_str 这个解析可能有点粗糙,不过好像也算有用,如果有好的方法麻烦交流一下;
然后结合到一起后,通过循环和判断合并到一起;
如下:
然后对转换为js输出,就可以对得到的响应开始数据获取
3.数据获取
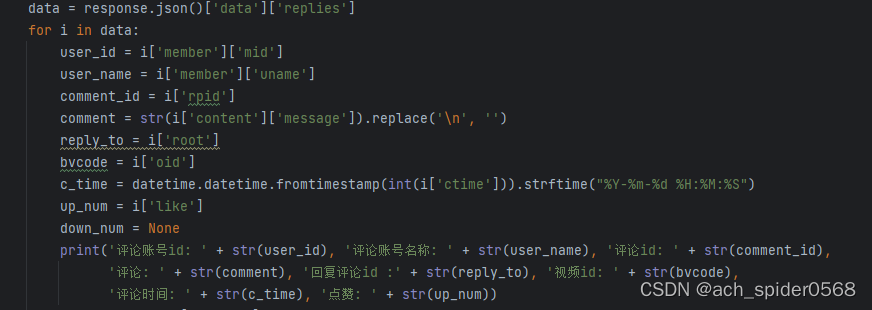
可以得到以下信息,不过很快就会发现问题,因为这样的解析得到的数据是缺少的,因为很多评论是由楼型的,大家可以互相回复,一个楼下的答复可能很多人会跟着评论,那么继续解析;

点击查看发送网页请求得到网页数据
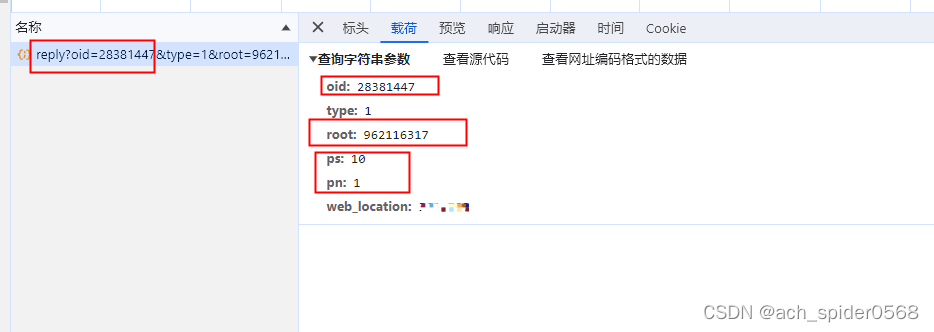
oid是视频ID,root是问题ID,ps和pn很明显是页数和每页多少条数据;
root在之前的commit_id就已经获取到了;
然后整理后发送请求,编写代码,没有逆向很简单
只有评论楼下超过三条才会进行折叠,可以获取到有多少评论进行判断,
代码如下:
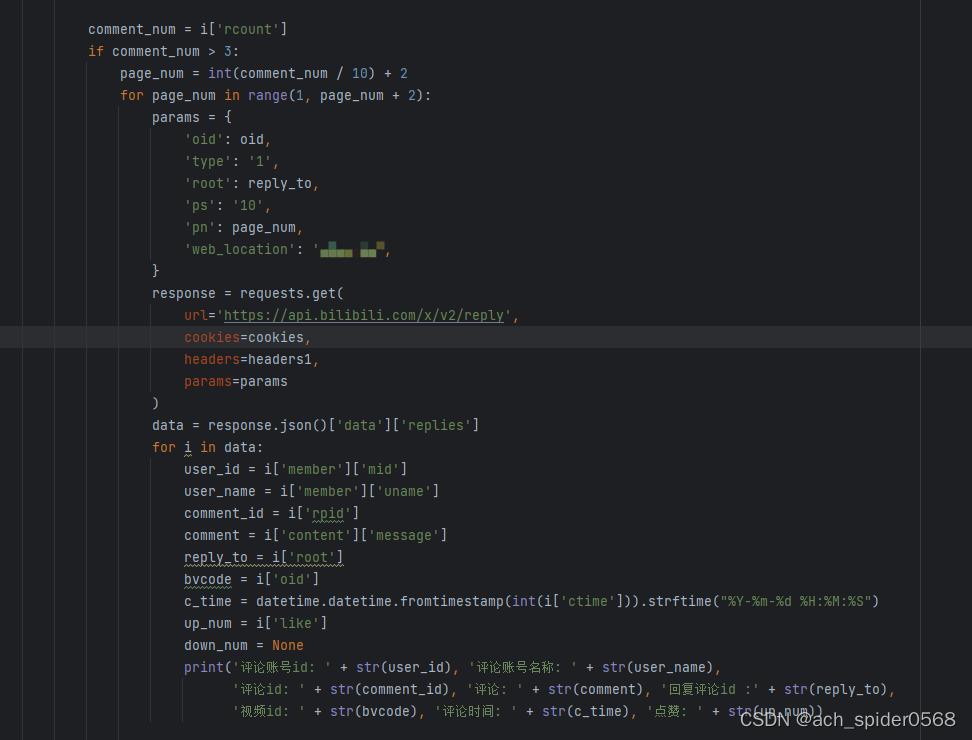
这样基本就可以完成对网页的数据采集了;
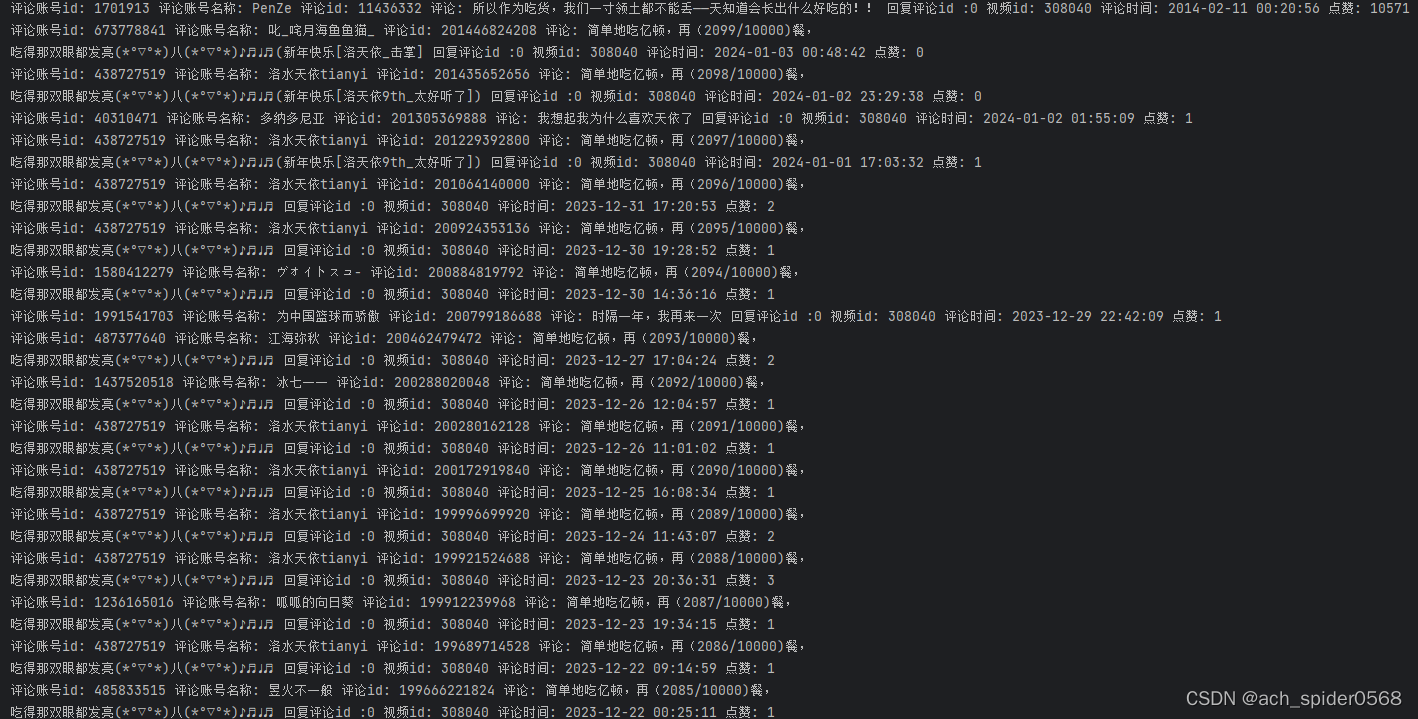
(B友水楼的还是很多的哈)
对于网页的获取注意访问频率,最好可以整个动态IP啊,user-agent_list之类的去模仿,防止自己被封,操作友善些;cookie可能也需要经常手动更新
该文章仅记录自己的一次学习过程,如有问题,多谢指导;

















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









