






Boss直聘反爬解决办法
欢迎参考我的博客网站:https://www.ccjinblog.info
方法一:更换网络
例如使用家里面wifi被网站进行了反爬的限制,此时只需要更换手机的热点,重新爬取即可,若是手机的wifi也被限制,则打开手机的飞行模式,再重启热点,此时就可以修改手机wifi的网络IP地址,接着进行爬取
方法二:浏览器复用
浏览器复用是什么?
在Web自动化测试中,通常要求在成功扫码登陆后才能执行后续操作。这里boss直聘的反爬操作中,会经过人工输入验证码,然后才能接着进行爬虫操作,但是每次爬取一个字段的时候,就会新打开一个浏览器,导致登录状态取消。采用浏览器复用,可以帮助我们保持一个浏览器的开启,不会在运行过程中,新打开一个浏览器。
实现方式
① 首先打开cmd,输入netstat -ano | findstr "9222"查看9222端口是否被占用

如果运行结果如上,则说明9222端口没有被占用
② 修改chrome浏览器设置,按照下图将关闭 Google Chrome 后继续运行后台应用按钮关闭
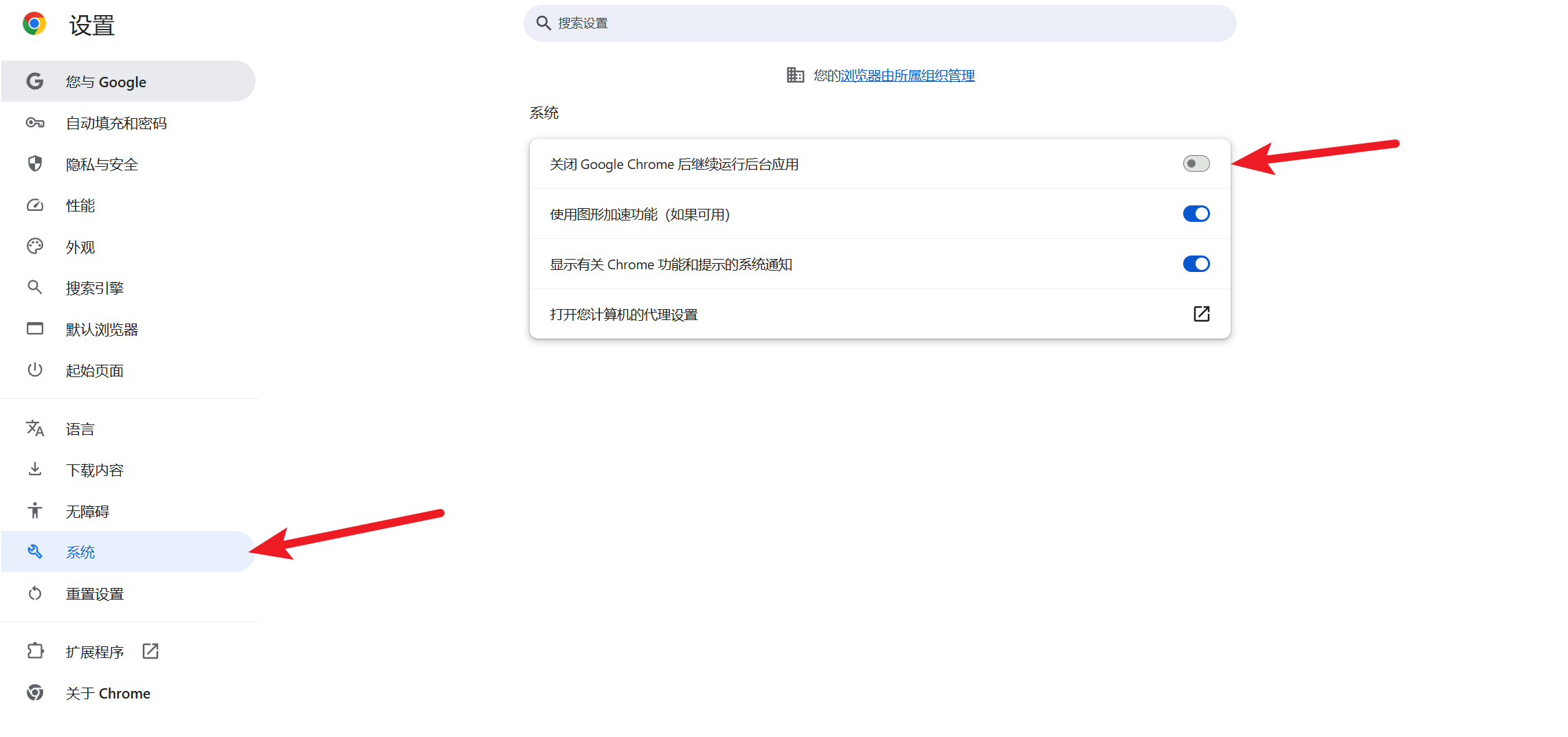
③ 在cmd中输入chrome.exe -remote-debugging-port=9222会弹出一个浏览器页面,此时我们登录我们的boss账号进行爬取操作即可

















 3440
3440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









