






LinCE 介绍
A centralized benchmark for Linguistic Code-switching Evaluation (LinCE) that combines ten corpora covering four different code-switched language pairs (i.e., Spanish-English, Nepali-English, Hindi-English, and Modern Standard Arabic-Egyptian Arabic) and four tasks (i.e., language identification, named entity recognition, part-of-speech tagging, and sentiment analysis).
一个用于语言代码切换评估(LinCE)的集中式基准,它结合了涵盖四种不同代码切换语言对(即西班牙语 - 英语、尼泊尔语 - 英语、印地语 - 英语和现代标准阿拉伯语 - 埃及阿拉伯语)以及四项任务(即语言识别、命名实体识别、词性标注和情感分析)的十个语料库。
数据集下载
LINCE网页:https://ritual.uh.edu/lince/datasets
数据集下载使用需要先登录谷歌账号才能点击Data下载
网站部分截图:
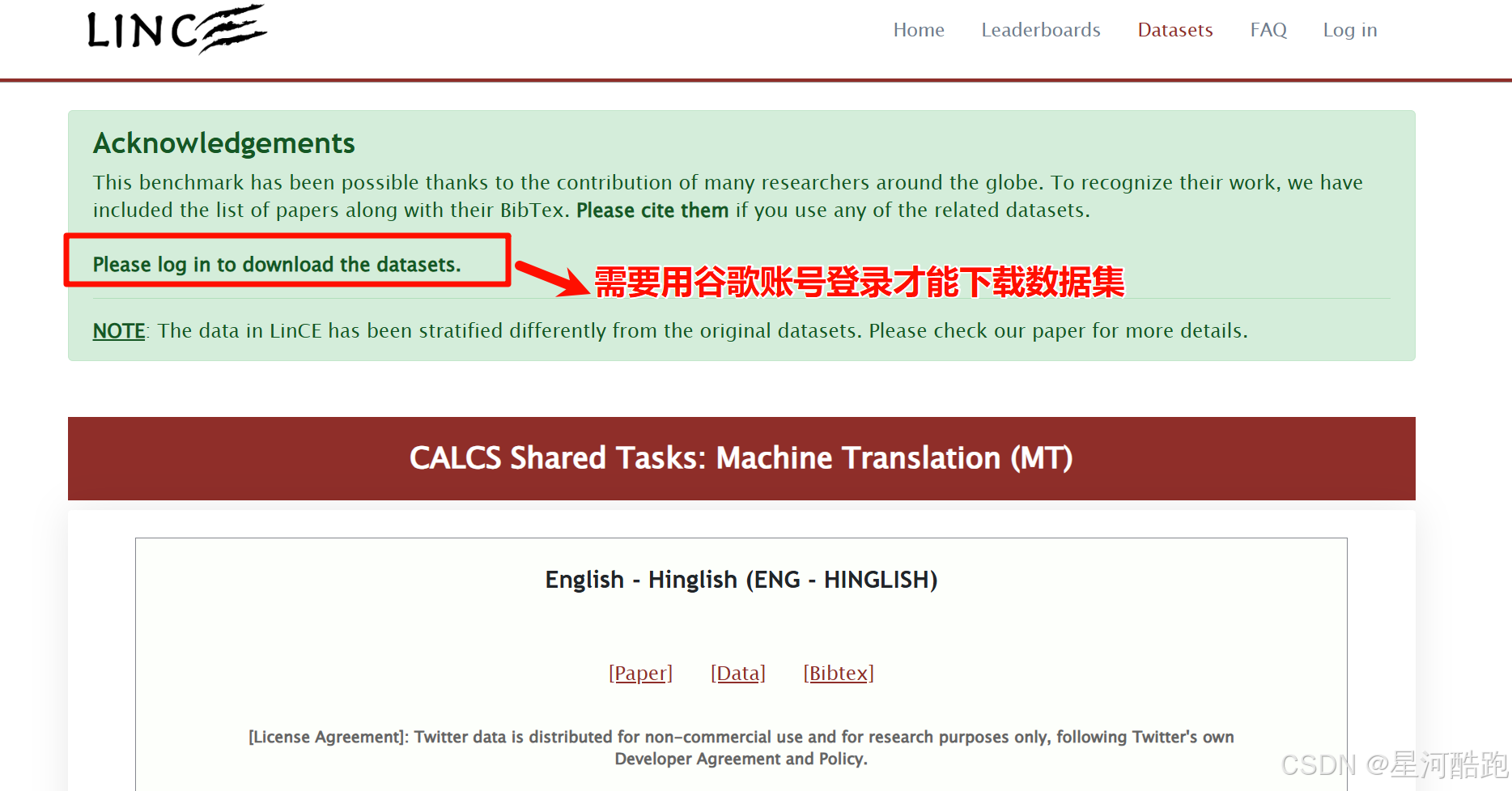

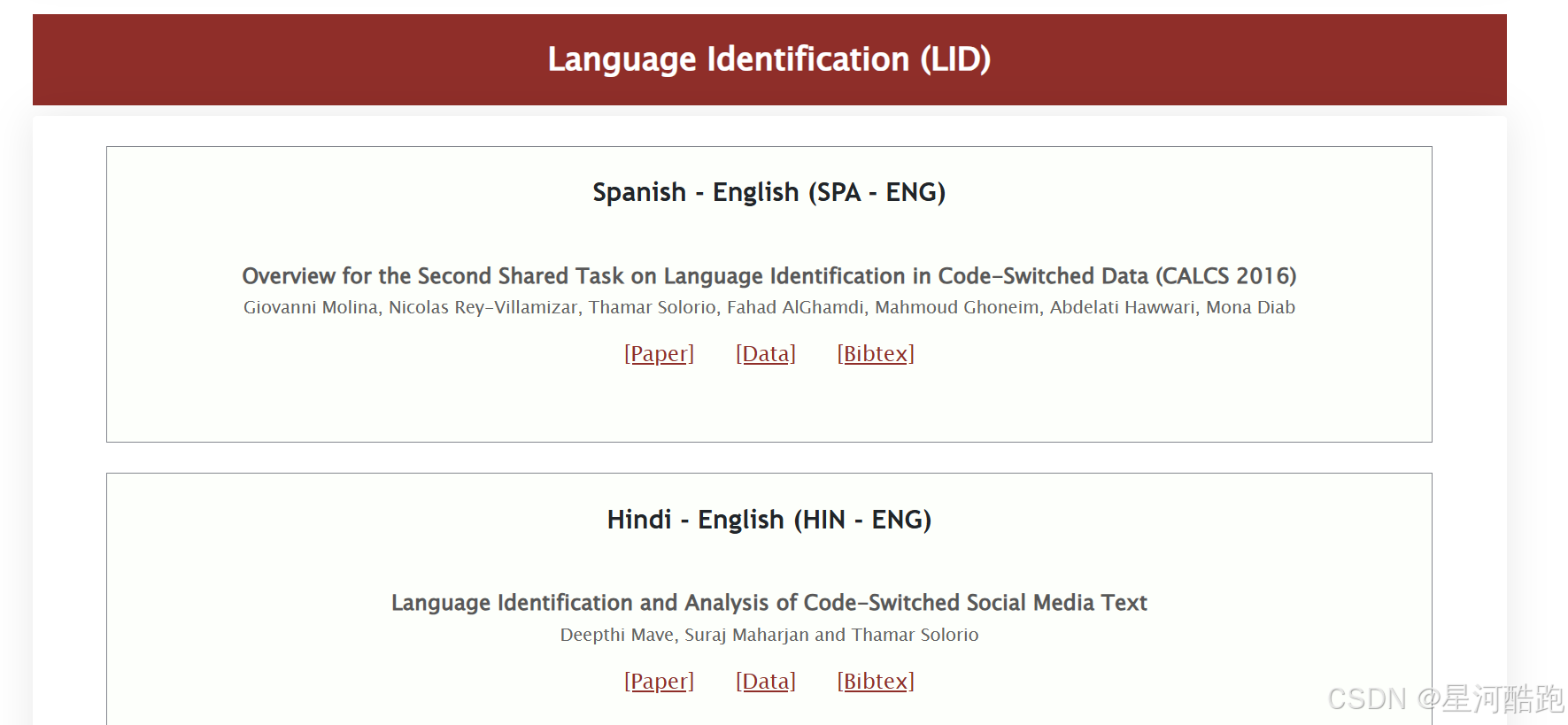
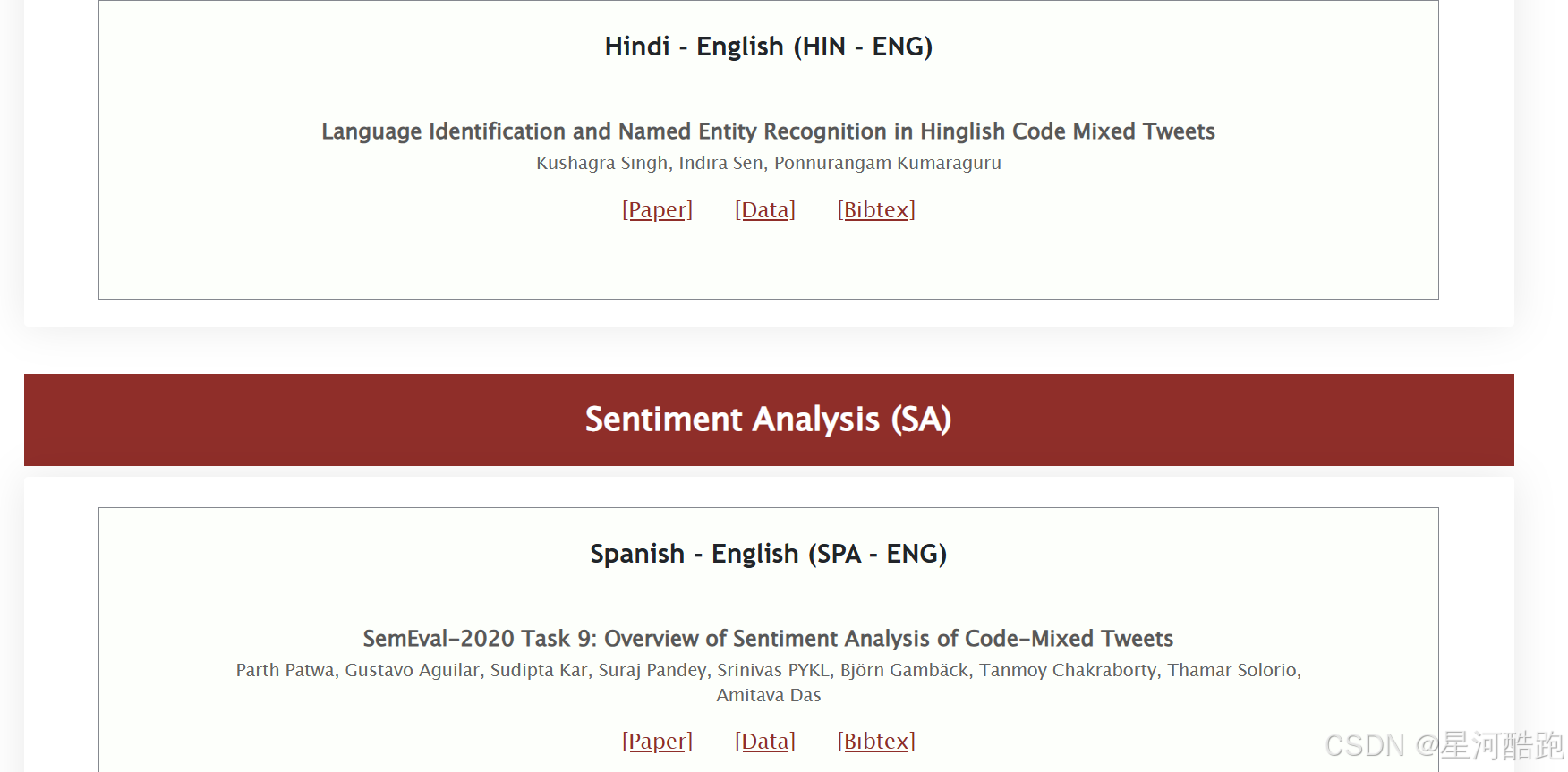
账号登录:
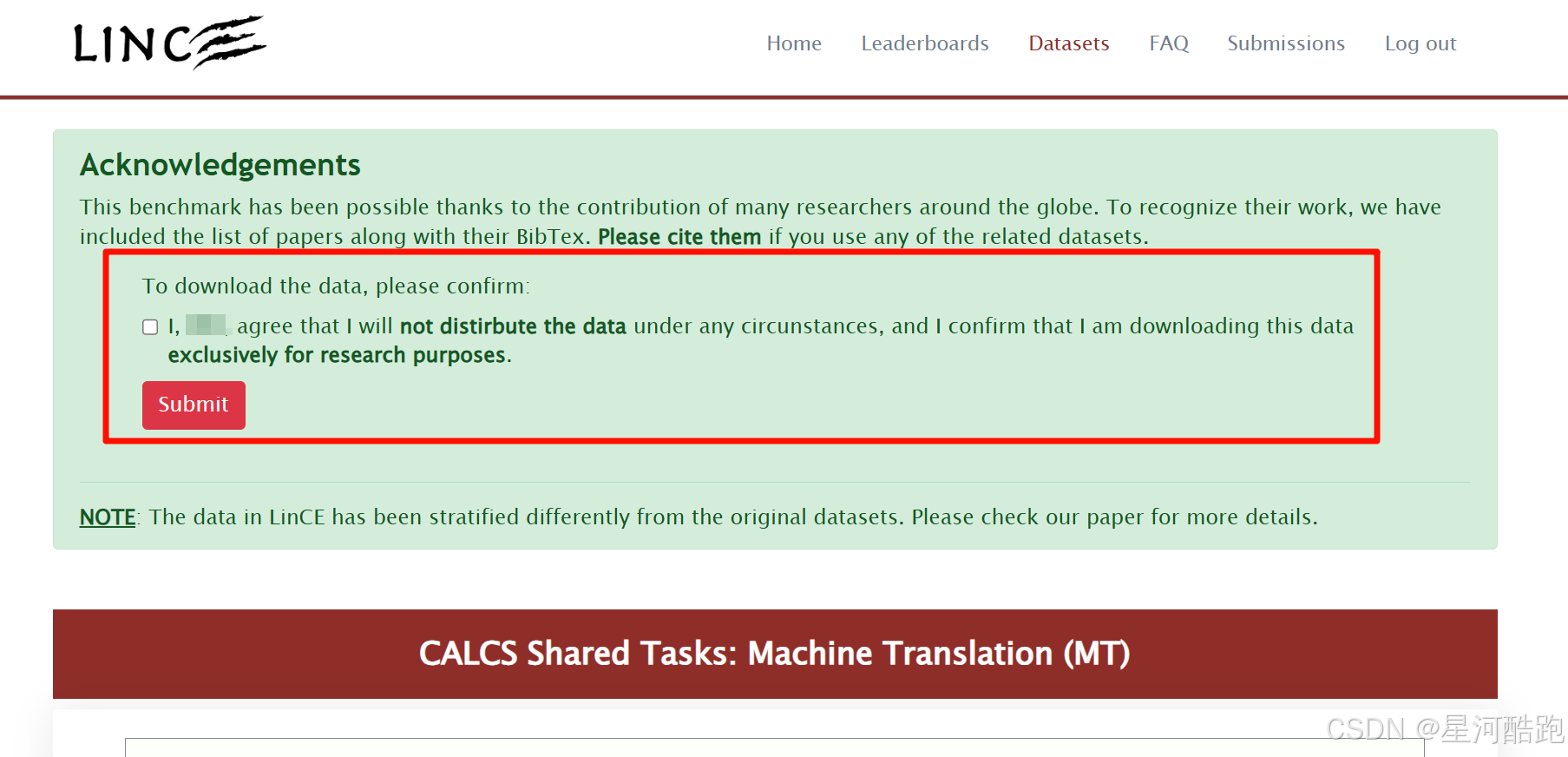
要下载数据,请确认:
同意在任何情况下,都不会透露数据,并且确认下载这些数据仅用于研究目的。
数据格式:
包括train.conll dev.conll test.conll 文件
eg: 下面是情感分析任务中的Spa-Eng数据集的部分展示⬇️
# sent_enum = 1 positive
After lang1
this lang1
I lang1
'm lang1
just lang1
gonna lang1
go lang1
home lang1
drink lang1
summ lang1
hot lang1
chocolate ambiguous
con lang2
bolillo lang2
and lang1
sleep lang1
# sent_enum = 2 positive
Eating lang1
a lang1
good lang1
as lang1
posole lang2
ha ambiguous
# sent_enum = 3 neutral
Dale lang2
mijo lang2
, other
no lang2
cop ambiguous
no lang2
stop lang1
# sent_enum = 4 positive
Damn lang1
I lang1
love lang1
listening lang1
to lang1
los lang2
cardenales lang2
de lang2
nuevo lang2
leon lang2
y lang2
el lang2
poder lang2
del lang2
norte lang2
at lang1
night lang1



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











