







parser 分析、剖析。
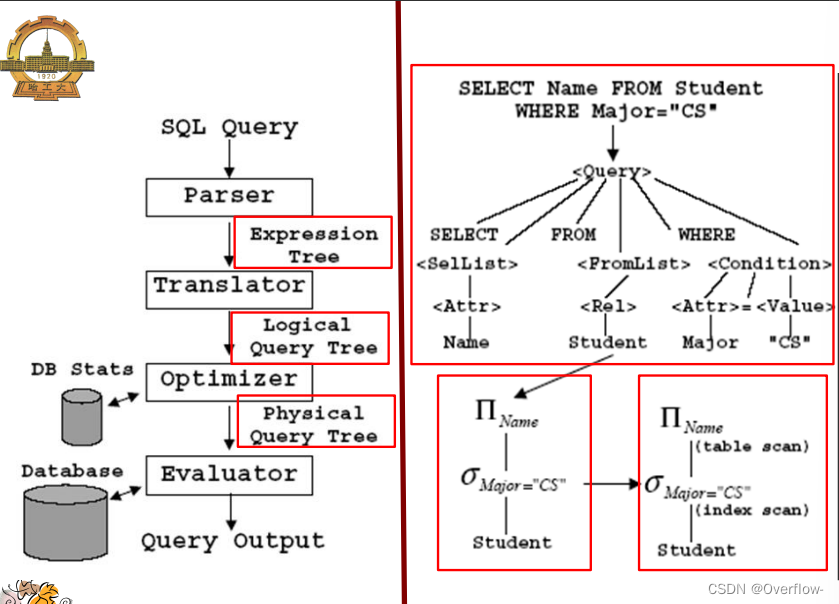
一个Query输入Mysql后经过语法分析器变成表达式树(Expression Tree),经过翻译器处理变成逻辑查询树,再经过优化器处理(最重要耗时的步骤)变成物理查询树,最后经过求值程序转化为输出。(上图)



parameter 参数




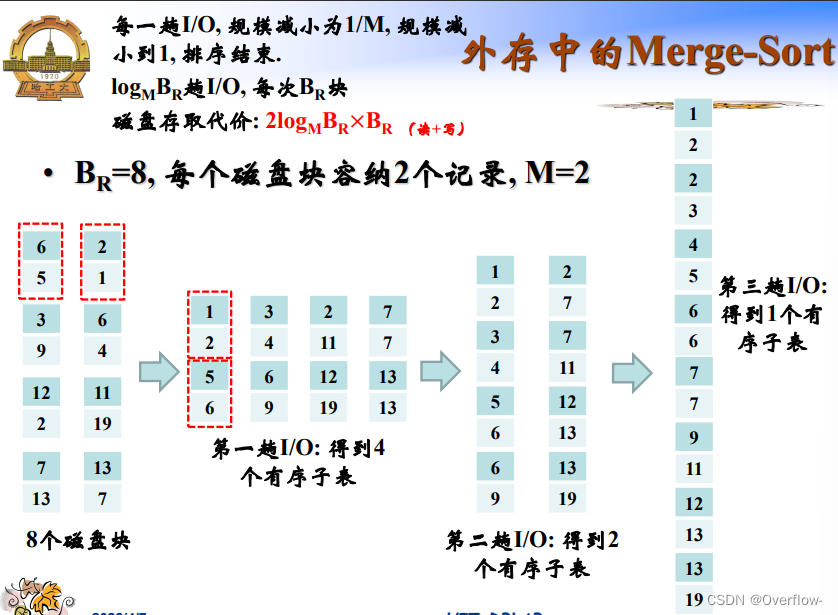
每一趟排序读BR个文件,写BR个文件,所以有一个二倍。

写出到外存是指重新写回去?一趟?
1.选择操作算法:


经典相等比较+排序=二分。



合取简单理解为AND?


2.投影操作算法:

把每一个重复多次的元组块的第一个放入结果T中,往后的重复元组全部剔除。

即使投影属性不包含键属性,如果关系R足够小能够在内存中进行操作,我们也只需要一趟就行了。如果R太大我们就需要进行多趟的排序算法。
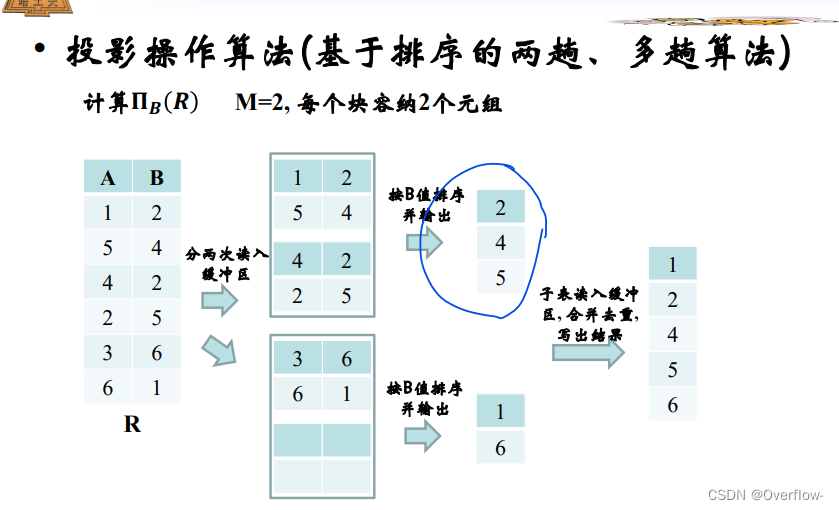 同时在Sort的过程中就已经进行了去重,上图中按B值排序并输出应该有两个2,但只输出一个。这样整个算法的输入都会少很多。(每一趟的代价都可能小于BR/M)
同时在Sort的过程中就已经进行了去重,上图中按B值排序并输出应该有两个2,但只输出一个。这样整个算法的输入都会少很多。(每一趟的代价都可能小于BR/M)
3. 连接操作算法:

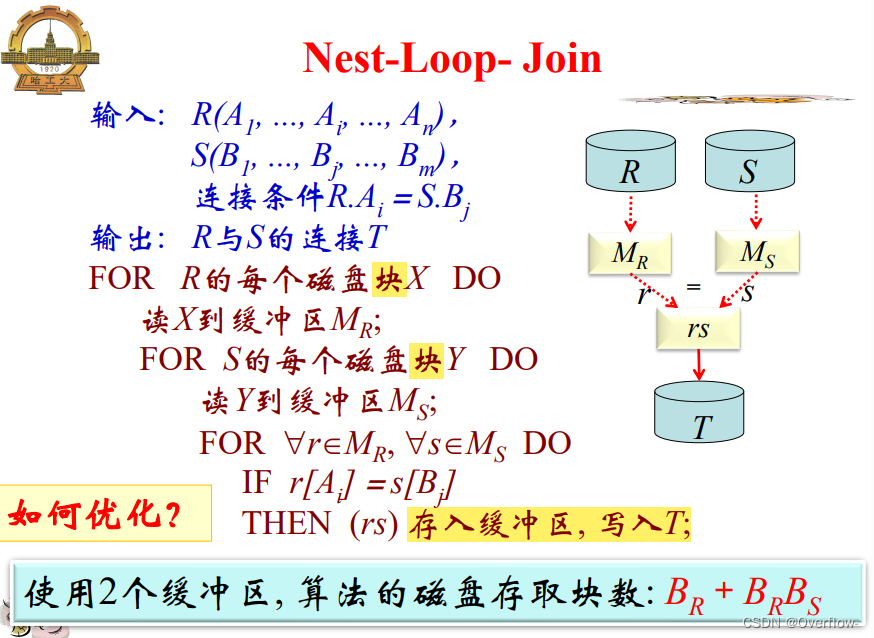
又名“Blocked Nest-Loop-Join”,以块为基础进行数据的比较。比较通过的数据将存入输出缓冲区,等到块满了一次写入T或者传数据到更上层的操作中去。
每次固定R比较S,所以花费BR+BR*BS。
磁头寻址次数: 最好情况下全局只输出一次join的结果,磁头寻址次数为2BR(每次读入R的一个磁盘块寻址一次,在读入S的所有块时也只需要寻址一次);
最坏情况下每读S的一个块都有join结果输出,磁头寻址次数为BR+BR*BS(每次读入R的块寻址一次,在读入S的每个块时都寻址一次)。

将最多的缓冲区块用于读入外层循环,只留一个用于内层循环。可以减少外层循环的次数。
这种方法的磁盘寻址次数:最好时2BR/(M-1);最坏时等于上图的I/O数量。
看着是BR和BS相乘的量级,但是如果BR非常小,BS非常大,BR小到M-1个磁盘块就能装下,那么只需要一趟I/O就能做完,小的关系全放在缓冲区中,大的关系只读一遍就可以了。

差了500,这500就是BS和BR的差距。看公式可知换位之后差的就是他俩的差值而已。

使用和上方的Nest-Loop-Join差不多的方法。
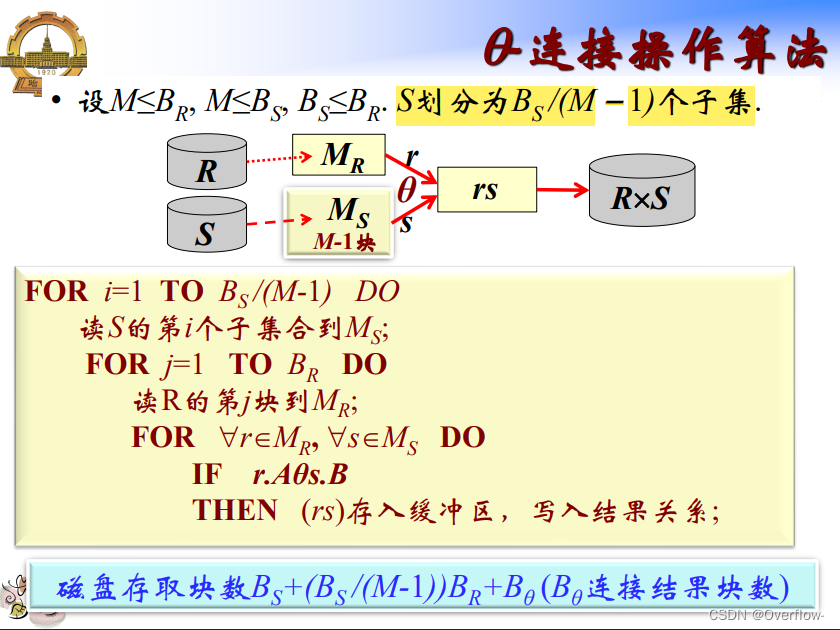
Bθ可要可不要。如果最后结果写入磁盘可以加上,但是对于不同的Join算法这个值都是一样的,对算法的比较也没有啥帮助。
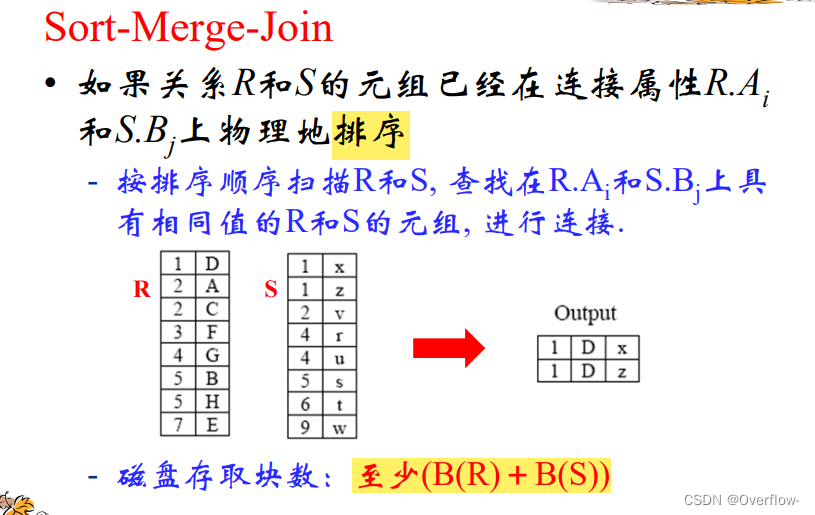
元素都排好了,那么两个表各自扫一遍就行了。不过这只是最好情况,如果某个元组在R和S里都大量的重复出现以至于M-1个块装不下,那么只扫一遍就解决不了了。
上面这个情况下,如果R或S中某一个的重复元组用M-1个块能装下,还是能一遍读完(和优化的Nest-Loop-Join一个道理。)
两个关系的重复元组都装不下,这个时候就只能局部退化成Nest-Loop-Join,先读R的M-1个块和S的所有块比较,再读R的剩余块和S所有块比较。相当于在重复区域做Nest-Loop-Join。

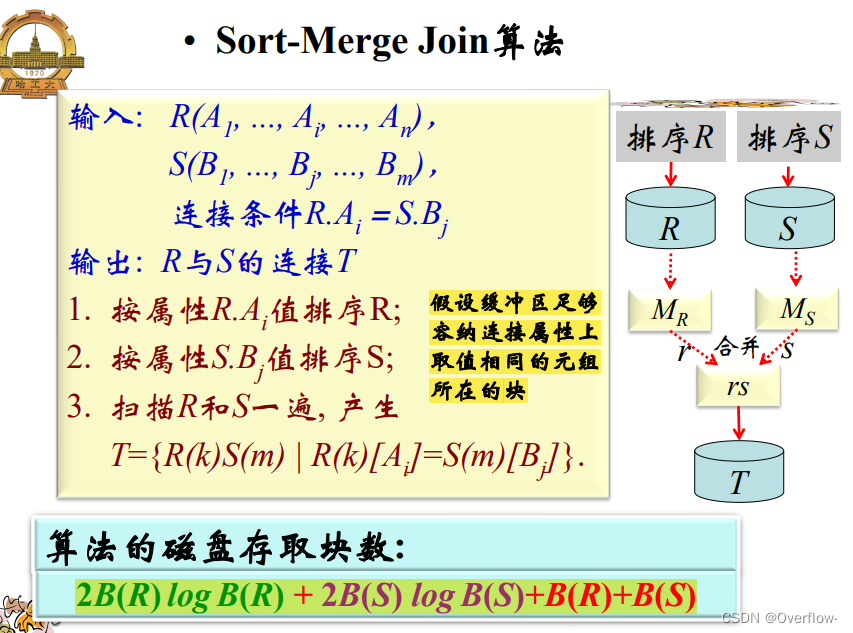
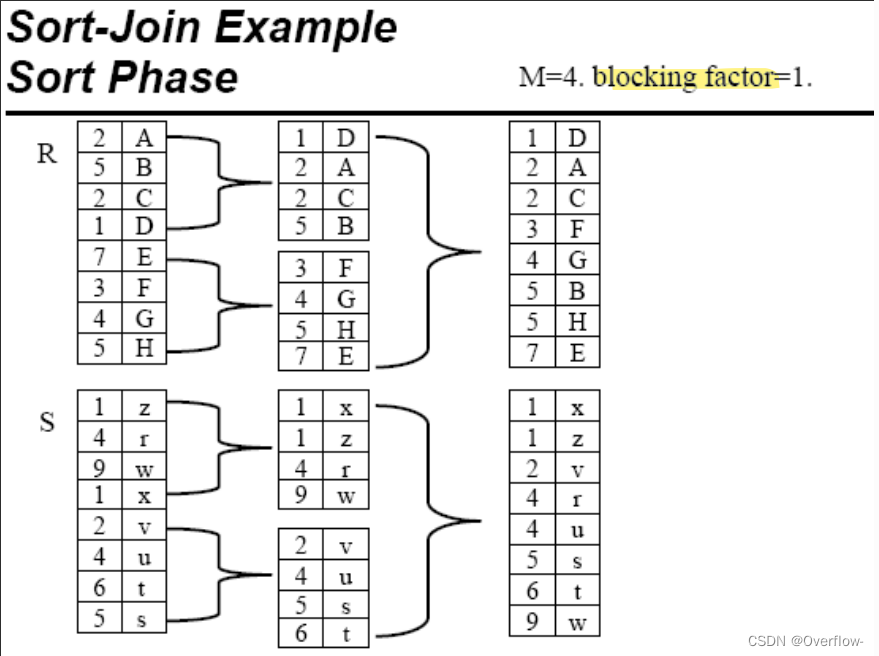
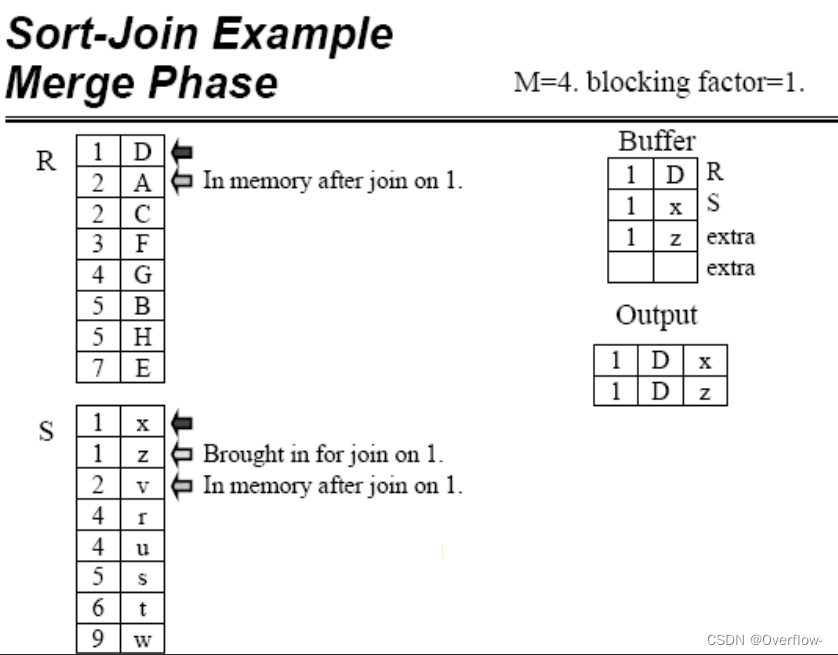
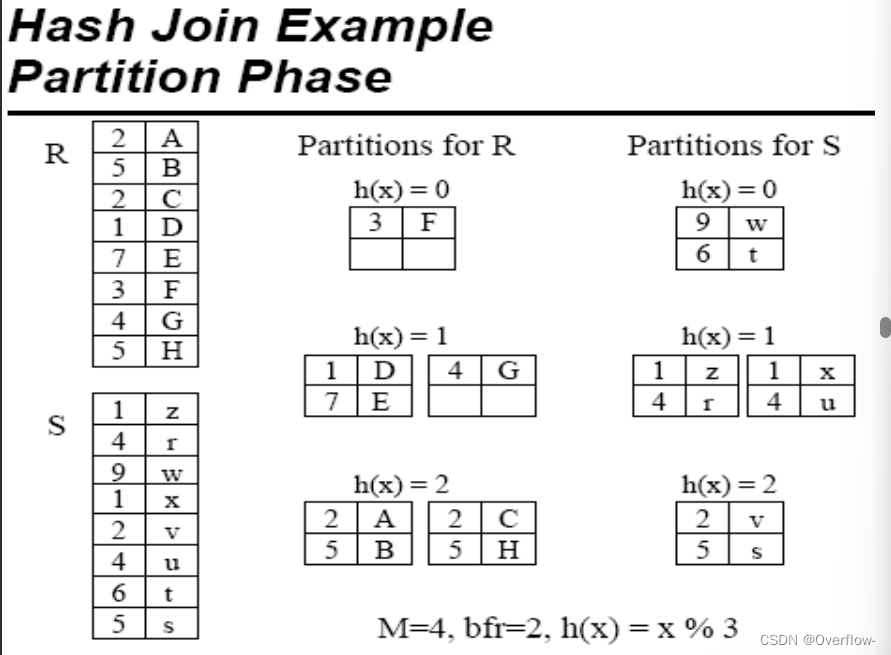
Phase 阶段、时期、位相。 blocking factor 一个缓冲区能够放多少个元组。
排序过程是在内存中完成的)
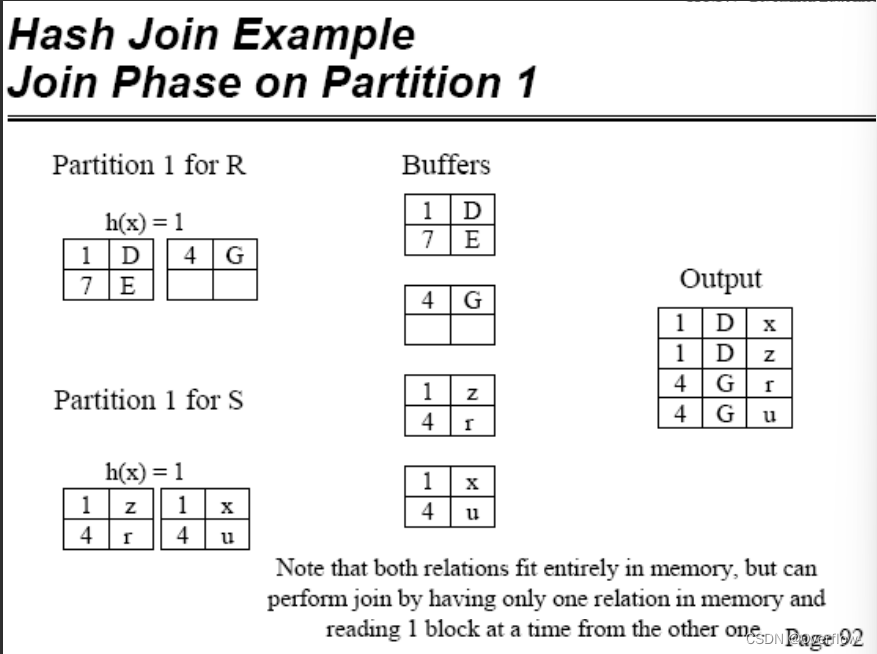
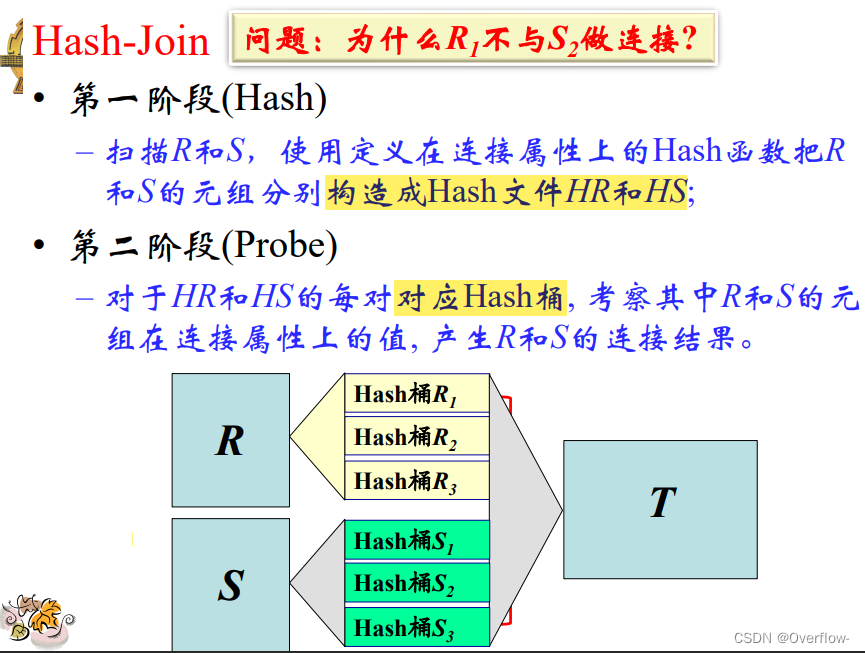 只需要做对应桶之间的连接~
只需要做对应桶之间的连接~

HR和HS的第i个桶可以一趟完成Join的条件是什么?
如果R、S能用M个块装下,当然可以;如果它们中的任一个用M-1个块能装下自然也行(不过要求另一个的一个桶用一个块能装得下)。

为了实现HR和HS的第i个桶可以一趟完成Join,R和S都需要经历logM(BR/M-1)次哈希。最后再读一遍,最后得到:
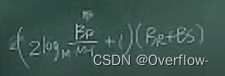
在M足够大时进行估计,将M-1视作M,得到:



除了利用排序的方法,也可以利用Hash-Join的思路来进行并、交、差。

聚集函数对应中间结果类型:
也就是说算Count、Sum、Max、Min时在归并时只需要维护上个子表的Count、Sum、Max、Min的值;而算Avg时需要维护Count和Sum的值。
二、查询优化




在第二条OR操作中 只有R为集合时才成立,如果R为包,假设左式选出两条重复的元组同时满足条件C1和C2,右侧将会有4条一样的元组。

![]()
RUS的前提条件是:R和S的属性集合一致,它们是相容的。
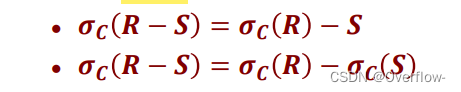
减去S和Seclect之后的S是一样的结果。对于减去S来说,对比二式他多减去的都是“无关紧要的”,因为Seclect * From R Where C选的是所有符合C条件的S中的元组(就是下式)~
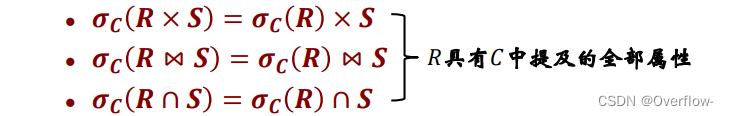

当R和S都包含C中全部属性时,能够进一步减少输入(让S也经过Select)

下推选择也不总是好的,举个例子:
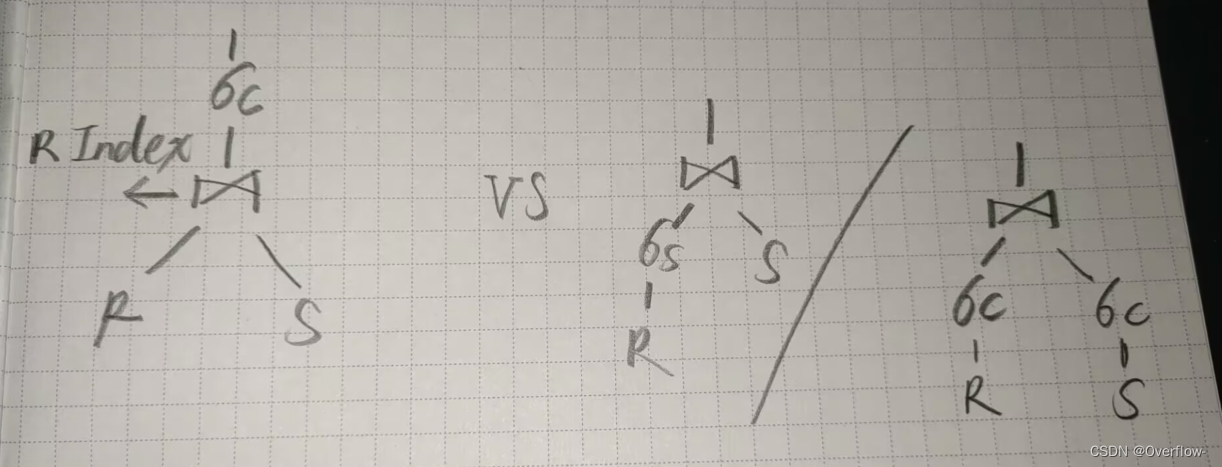
如果R上建立了索引,能够比较方便的做连接操作,实际花费代价可能比右边更小(右边对R/S做Select操作比较坏的情况是全局扫描)

先上移再下推。

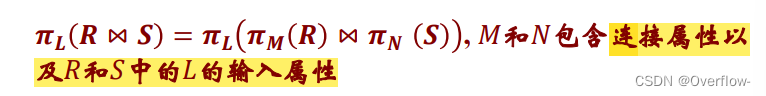
左式是先自然连接再投影,右式如果M、N不包含连接属性就无法自然连接;如果不包含L的输入属性就无法正常投影结果。
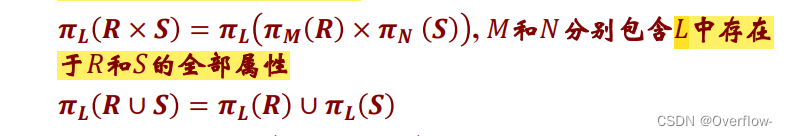
上式也只有当R、S为集合而不是包才行。
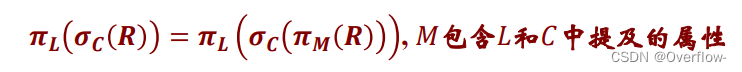
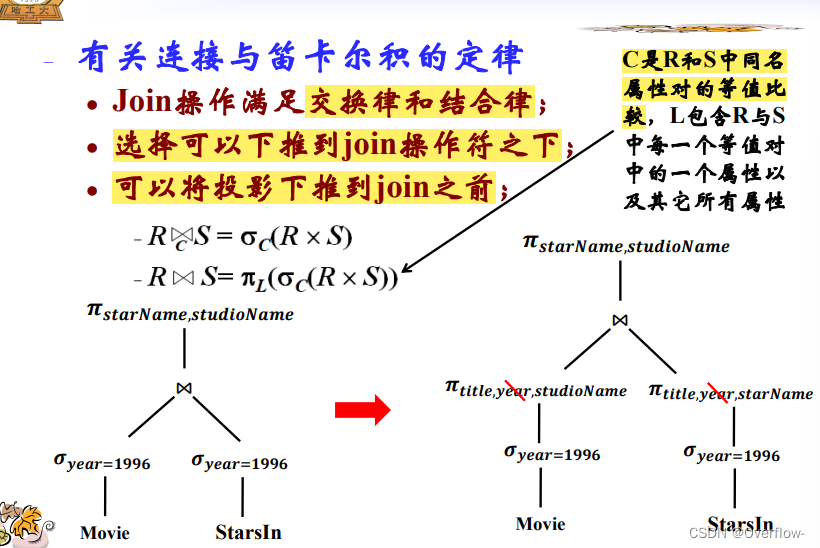
因为已经有year的select操作,所以在投影时可以去掉year属性。

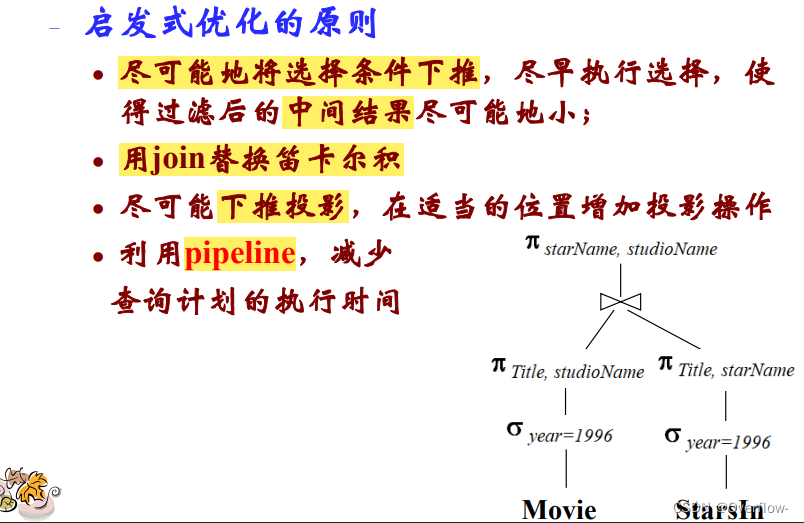
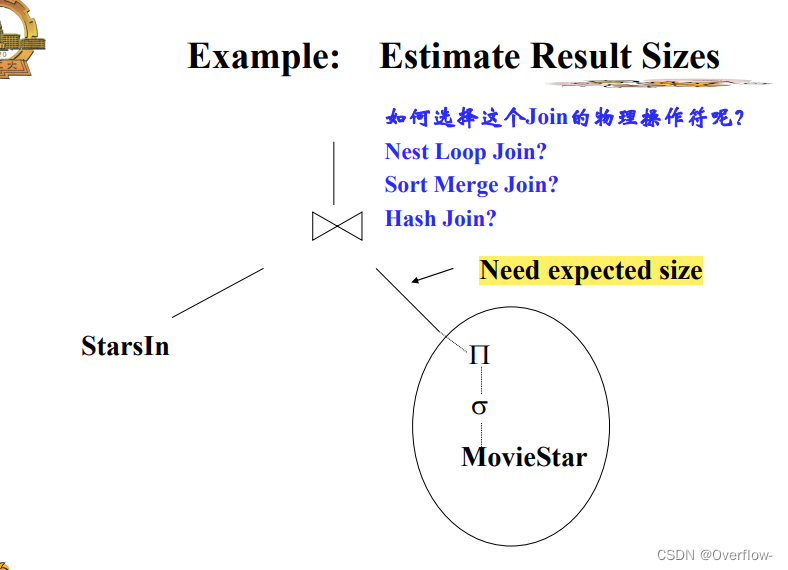
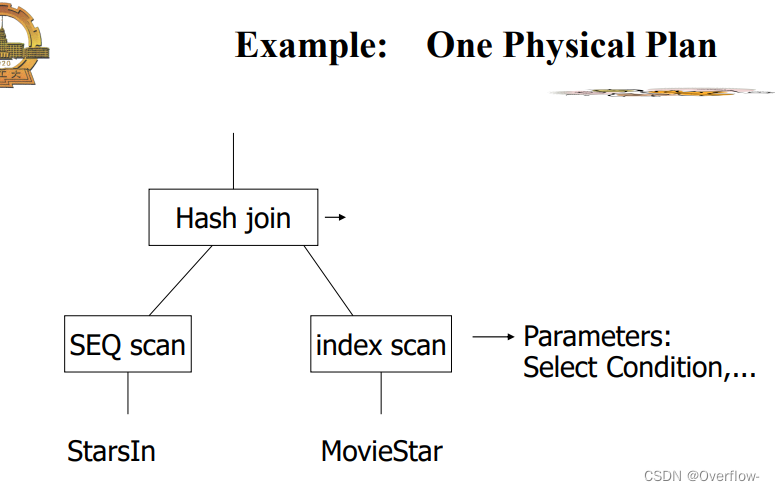
考察LQP(逻辑查询执行计划)标准:中间结果的大小。
操作代价的估计:



用R元组个数在值域上的一个平均分配来估计S的元组个数。
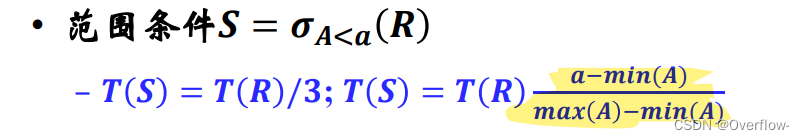
在一条定长线段上任选两个,它们之间的距离期望为L/3。或者用比例计算(几何概型)

AND条件就是各种概率限制的累乘(
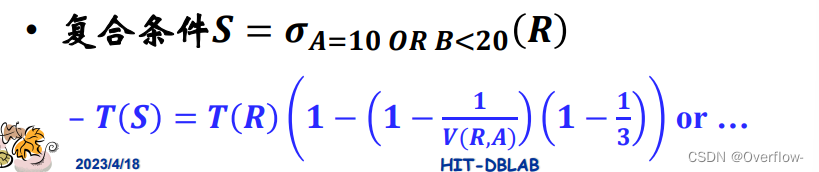
考察OR条件就用反向思维。除了这个式子还有:
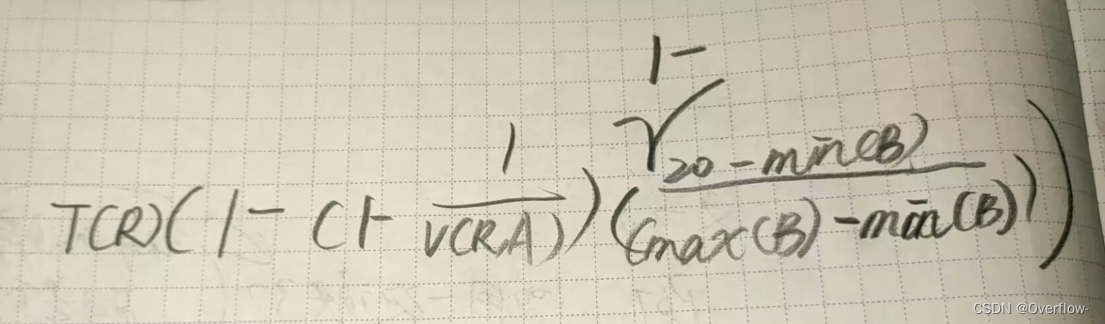




有多个同名属性也是类同的取1/max 。


自然连接操作具有结合律~这两个代价的估计也是一样的

都是关系的元组相乘/连接属性个数中最大的那两个。

估计好代价中占大头的部分能够使整个估计更加精确。
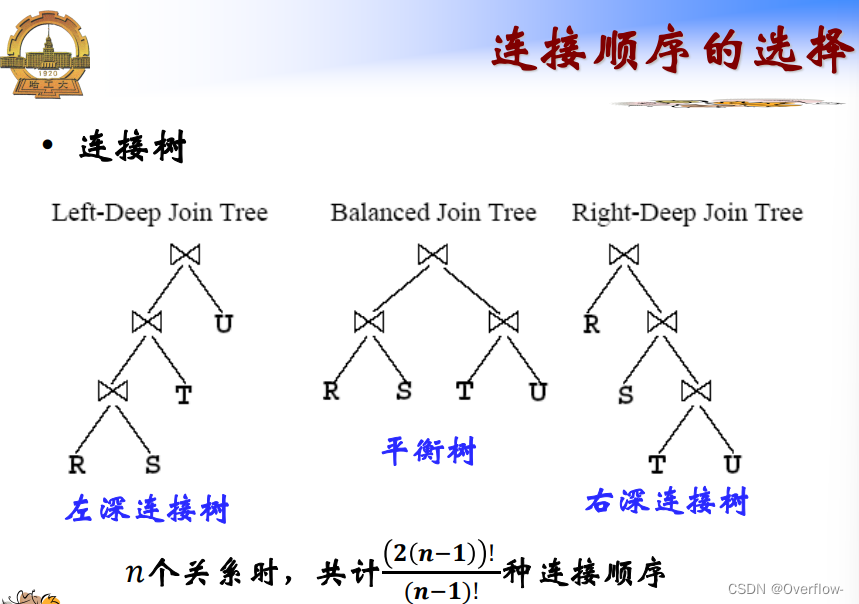
连接树问题可以表述为:一个具有n个节点的二叉树有多少种排列以及叶子节点的全排列(n!):
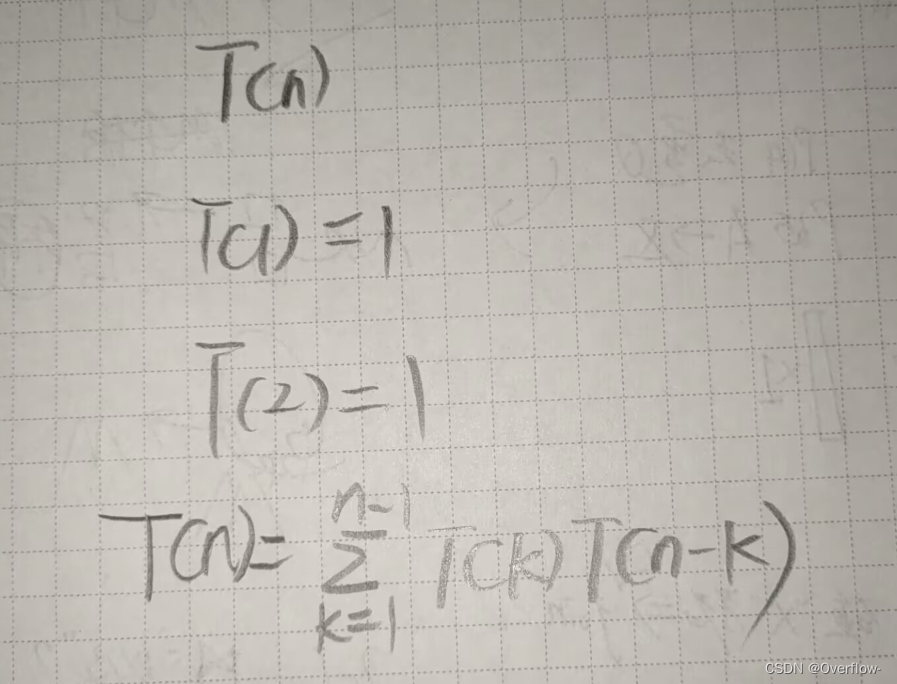
和当初算法课中学的“矩阵链乘法”直接暴力计算得到的递归方程一致~T(n)又被称为Catalan数。
http://t.csdn.cn/7O1jw
算出来T(n)是{ C(n-1)[2(n-1)] }/n,再乘上n!就有:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









