









与存储组织有关的源语言概念与特征:

一个是编译时 一个是程序执行时。
名字及其绑定:
 名字表示编译时的特定对象;变量表示运行时该名字所代表的内存位置。标识符则是为了指示数据对象、过程、类&对象的入口。
名字表示编译时的特定对象;变量表示运行时该名字所代表的内存位置。标识符则是为了指示数据对象、过程、类&对象的入口。
所有标识符都是名字 但是名字还包括表达式。

同一标识符可以被声明多次 但每个声明都引入了一个新的变量。

变量侧重于表示开辟了某个特定的内存位置以供使用。
声明的作用域:

编译时可以确定的是静态的~

注意这里静态作用域规则下 x=1而不是我们自己“想出来”的4 想出来就是运行了么
静态作用域:

显式访问控制:



“包围该引用”
过程及其活动:




a和b是同一个过程的活动 那么他们的生存期要么不交迭 要么是嵌套的结构
参数传递形式:



传值:传的是实参右值。
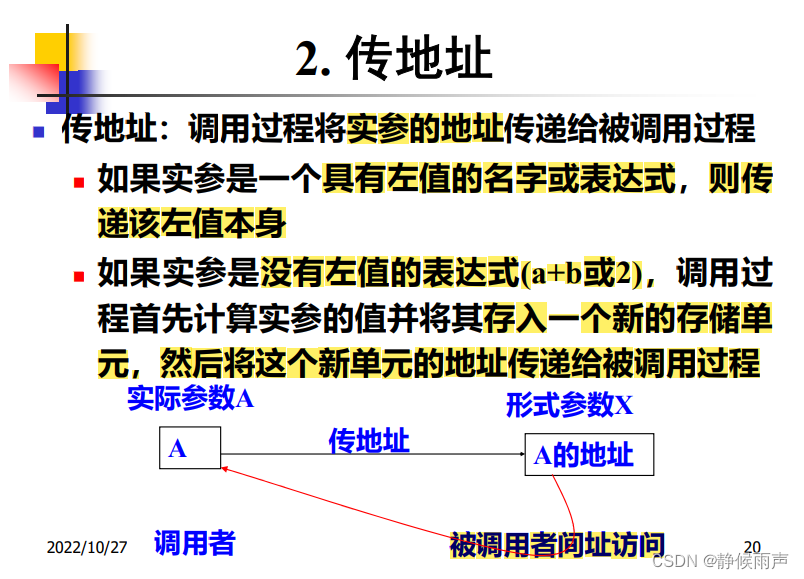
传地址:被调用者间址访问 这也是传地址能真正改变变量的值的原因。



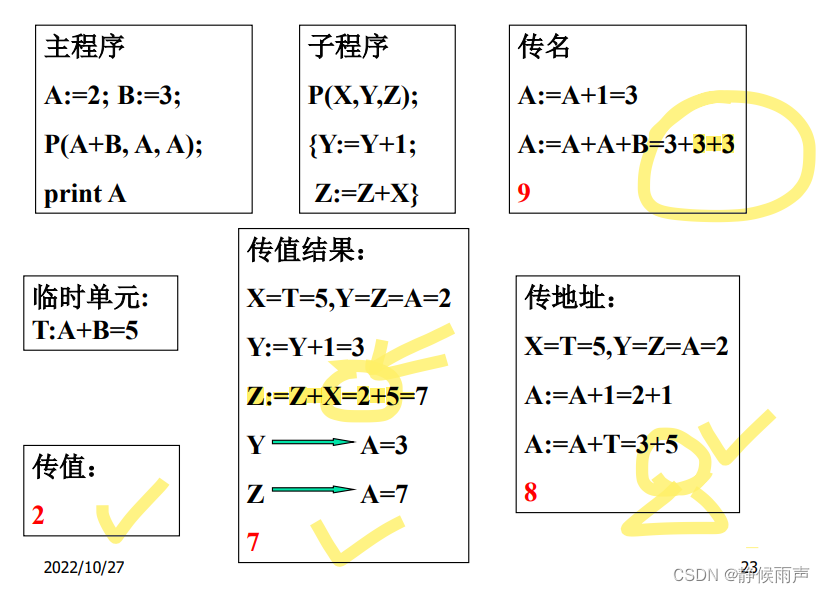
注意:传值结果的方式 实参的右值和左值同时传给被调用者;但是 在被调用过程中是像传值方式一样使用实参的右值 直到控制返回调用过程的时候才将形参当前的值复制到实参的实际存储单元去。所以这里传值结果是2+5=7.
而传名方式是“文字替换” 类似于宏替换 这里直接换成A=A+A+B来算 最后得出9.
传地址这里T分配了一个新的地址 并不是说A+1之后它也加一了 可以理解为两个独立的变量来使用。
存储组织:

运行时内存的划分:

存储区分为:静态区 常量区 堆 栈。
栈存放临时变量、管理过程的调用活动;堆存放程序运行过程中被动态分配的内存段。

活动记录:


活动记录一般含有连接数据、形式单元、局部变量、局部数组的内情向量和临时工作单元。



局部数据的组织:

局部数据是编译过程中处理声明语句时进行分配的。就可以看出是静态分配~


这里的例子里char占字节数1 long占4 double占8.

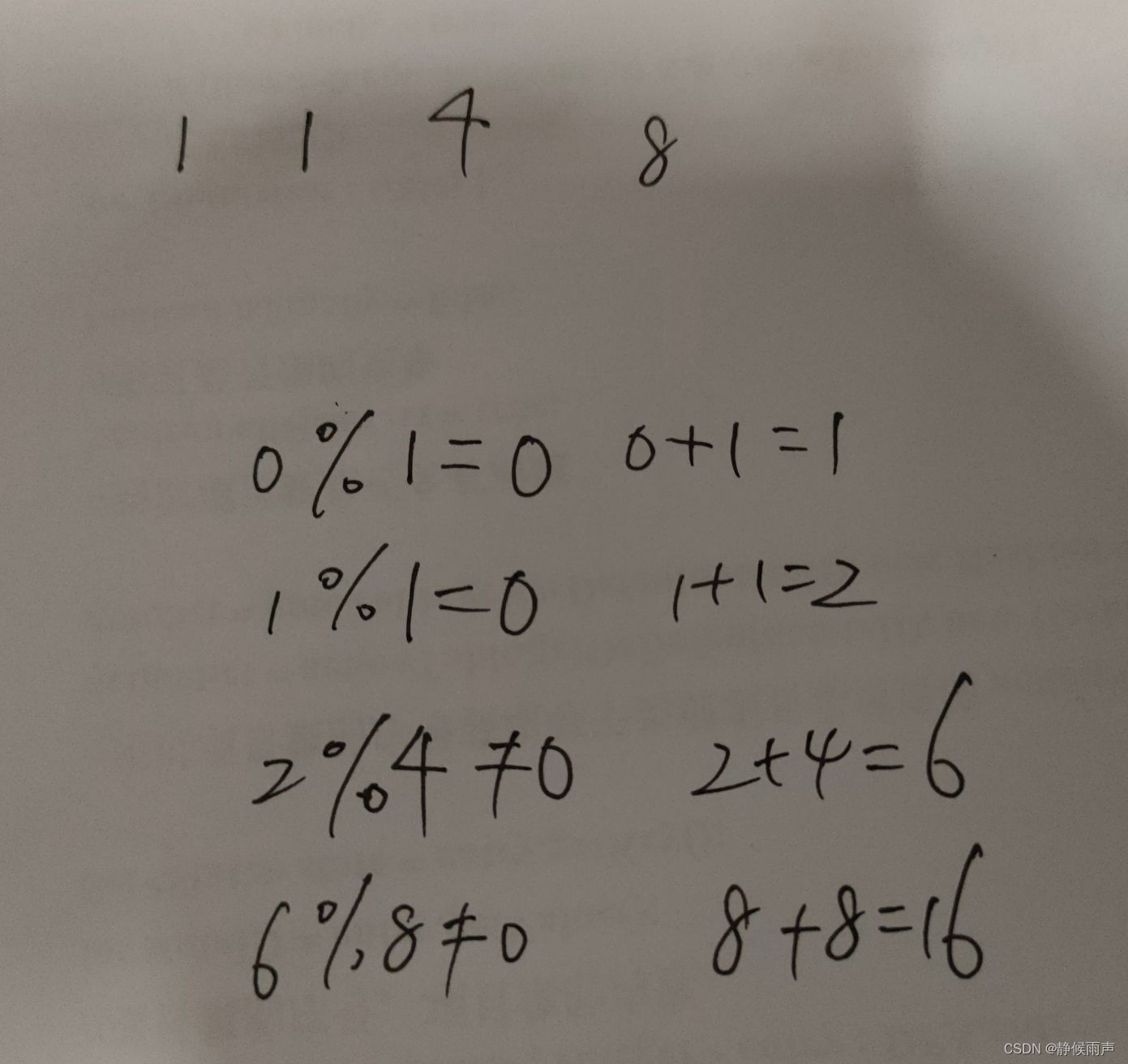
可以算出是24和16.

20和16同理~
全局存储分配策略:


静态存储分配策略:在编译时刻为每个数据项目确定出在运行时刻的存储空间中的位置。


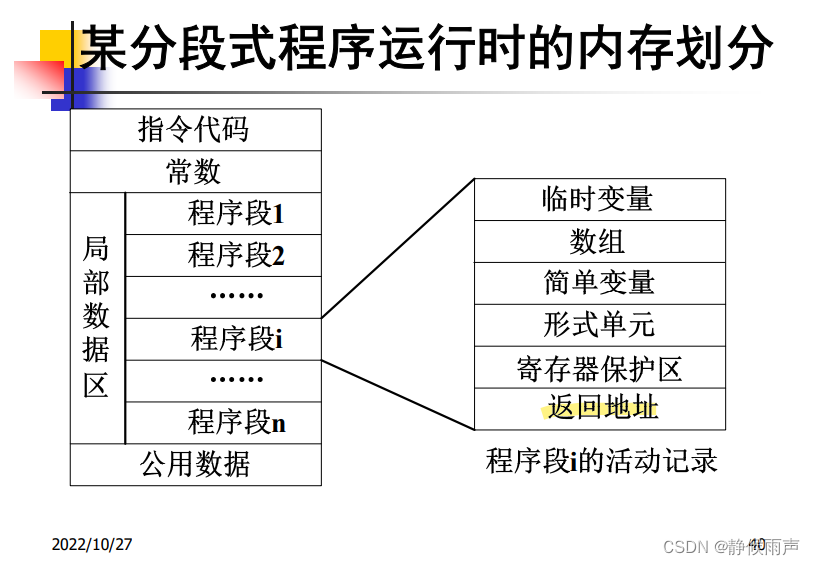
共用数据指全局区?局部数据区指的是栈?所以活动记录全都存放在栈中?
顺序分配算法(组织局部数据区):
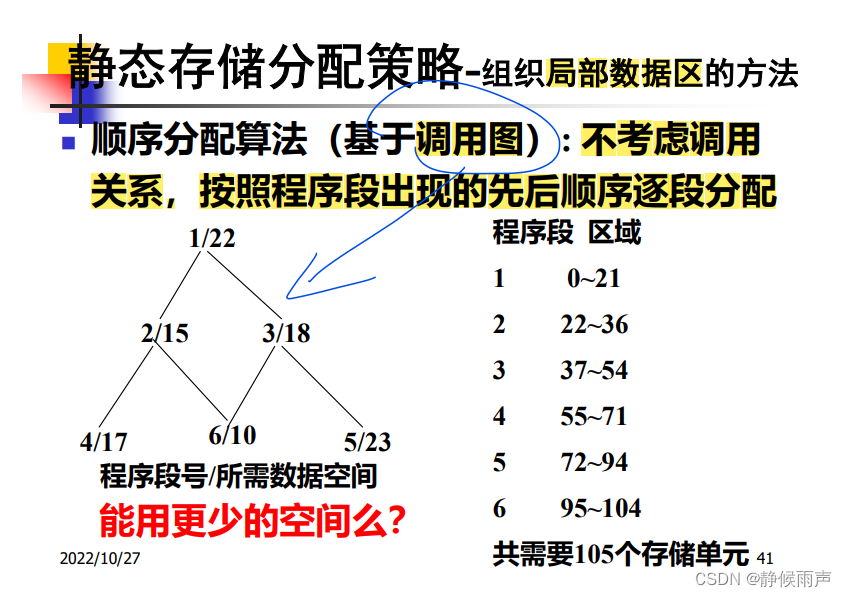
虽说基于调用图 可是只利用了调用图中出现的先后 并没有考虑调用关系 比如程序段2/3不会同时运转 但2/4会嵌套运行。
分层分配算法:
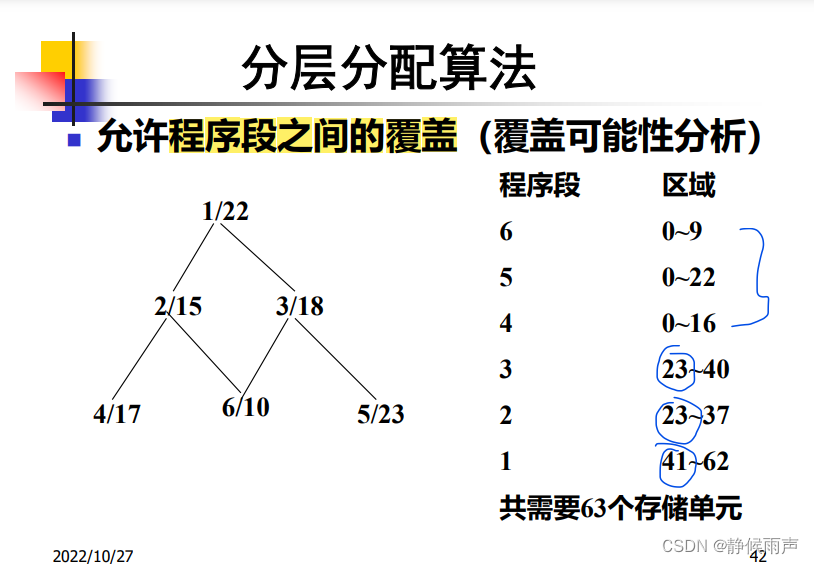
5 6不会同时被调用 所以可以共用一块空间 这里共用0~22(因为最大的5需要23) 而3号可能和5 6嵌套运行 所以3号就得和他们划清界限 从23开始 给他23~40;2和3不会同时被调用 所以共享空间 给2:23~37;1号则从41开始分配。倒序分配是为了给没有相互调用关系的过程分配共享的存储区。
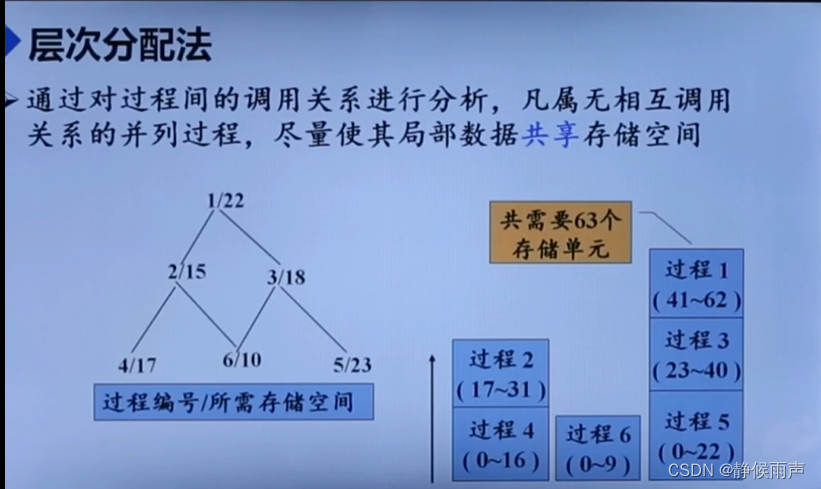

动态与静态相比:1.允许过程的递归调用(无法预先确定递归活动和递归深度) 2.允许动态申请、释放内存。
在编译时不能确定运行时数据空间的大小,则必须采用动态分配方法。
栈式存储分配策略:

调用序列&返回序列:


调用序列和被调用序列都被分割为两部分 进入两个过程中。

假设地址是从上往下逐渐增大的 因此把栈底画在上方 栈顶画在下方。
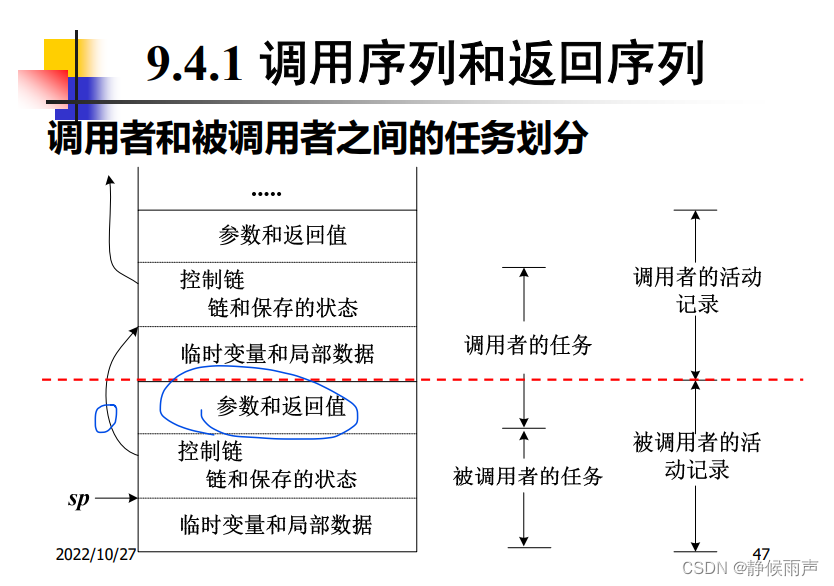
在调用者与被调用者之间传递的值一般放在被调用者的活动记录开始的地方,这样他们可以尽可能地靠近调用者的活动记录。
固定长度的项被放置在中间位置(控制链 访问链和机器状态字)
在早期不知道大小的项被放置在活动记录的尾部(临时变量和局部数据)
栈顶指针寄存器top_sp并不是指向真正的栈顶 而是指向活动记录中局部数据开始的位置,以该位置作为基地址。

1.调用者计算实际参数的值 并将其存放在被调用者的参数和返回值字段中;
2.调用者将返回地址(程序计数器PC的值)放到被调用者的机器状态字段中(位于保存的状态段),将调用者自己的top_sp的值放入到被调用者的控制链中,此时被调用者的控制链指向父亲的基地址。接着调用者增加top_sp的值 使其指向被调用者局部数据开始的位置(也就是自己的基地址) 注意明确是谁干的什么事。
3.被调用者保存寄存器的值和其他状态信息;
4.被调用者初始化其局部数据并开始执行。

1.被调用者将返回值放入到与参数相邻的位置;
2.被调用者使用控制链和机器状态字段中的信息恢复top_sp和其他寄存器的值,然后跳转到由调用者放在机器字段中的返回地址;
3.尽管top_sp已经复原成父亲自己的了(减小了),但是调用者知道返回值相对于当前top_sp值的位置。因此,调用者可以使用这个返回值。
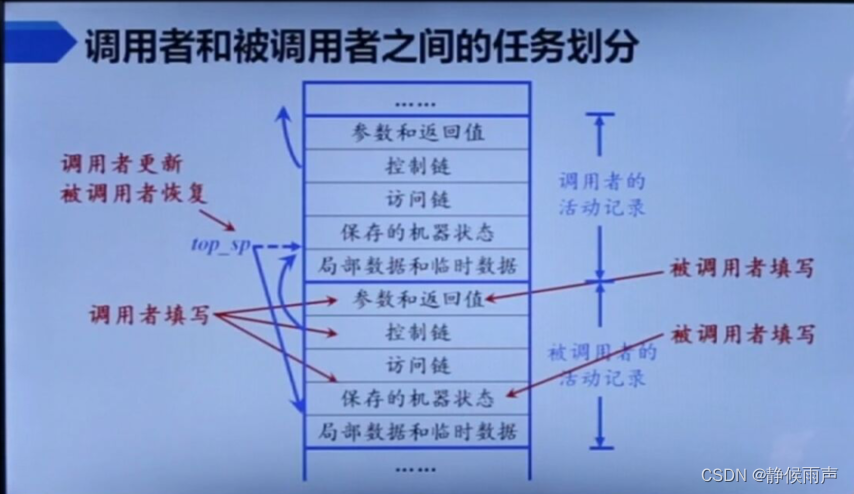


这里ppt没看懂写的啥 先略了

在现代程序设计语言中 在编译时刻不能确定大小的对象将被分配在堆区。但是 如果他们是过程的局部对象 也可以将他们分配在运行时刻栈中。尽量将对象放置在栈区的原因:可以避免对他们的空间进行垃圾回收 减少了开销。
只有一个数据对象局部于某个过程 且当此过程结束时他变得不可访问 才可以使用栈为这个对象分配空间。
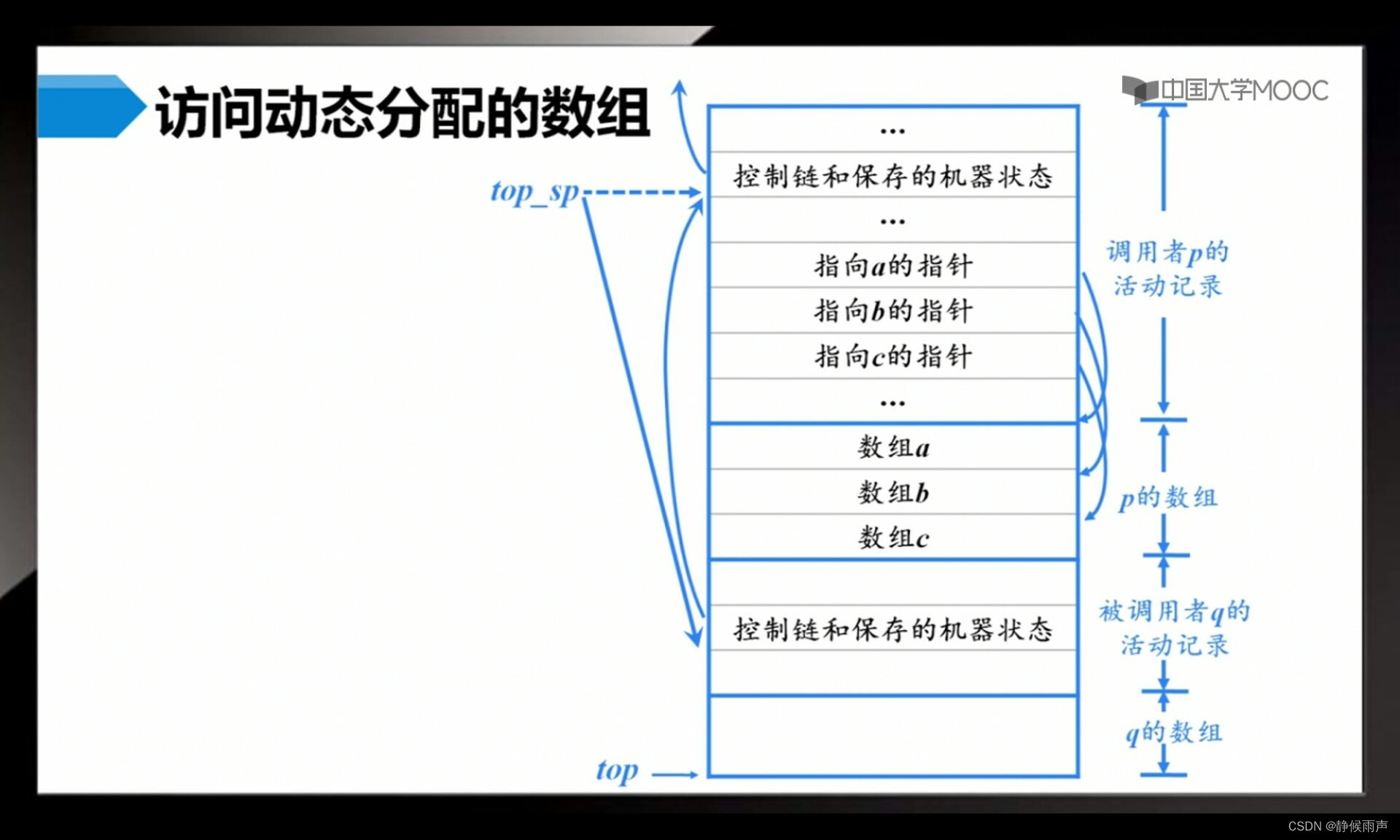
变长数据最常见的就是动态数组。这里给出为动态数组分配存储空间的常用策略 在过程p中包含3个数组 我们假设这三个数组的大小在编译时不能确定。尽管数组存在栈中 但它们并不是p的活动记录的一部分,活动记录中只存放了指向这些数组开始位置的指针 p执行时这些指针相对于栈顶指针的偏移量是已知的 因此目标代码可以通过这些指针来访问数组元素
栈式分配策略的局限:

堆管理:



内存管理器分配的空间是连续的;具有被请求大小。


空间效率:减少内存碎片的数量;
程序效率:利用程序的“局部性” 程序在访问内存时具有非随机性聚集的特性。
低开销:尽可能提高这些操作的执行效率。

虚拟内存(磁盘)-物理内存-二级高速缓存-一级高速缓存-寄存器。


将最常用的指令和数据放在快而小的内存中,而将其余部分放在慢而大的内存中(结合成本),这将显著降低程序的平均内存访问时间。

在某些数据密集型的程序中的作用,高速缓存的方法作用并不明显。


降低碎片量的堆区空间管理策略:


堆区空间分配策略:
最佳适应策略:





堆区:桶机制 空闲空间:设置空闲;合并空闲块。



接合相邻空闲块:边界标签;双向链接的空闲块列表。
小结:


关于动态数据区和静态数据区:http://t.csdnimg.cn/xwIYl
关于内存分配更详细的:http://t.csdnimg.cn/HsrQP

















 3843
3843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









