









中间代码的形式:




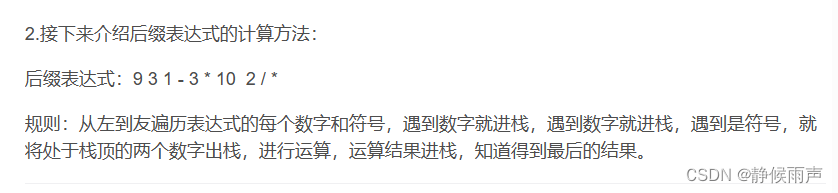
三地址码:

每条指令最多包含三个地址:两个操作数地址和一个结果地址。








 这里的||表示后缀式的连接。
这里的||表示后缀式的连接。


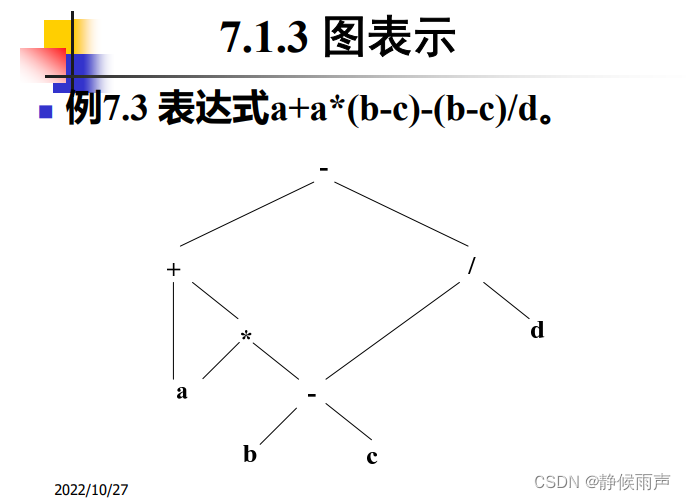
还是后根遍历读取。注意可能有多个父亲。


产 生 式 语 义 规 则 ⑴ E → E1 + T E.node := mknode('+', E 1 .node, T.node ) ⑵ E → E1 - T E.node := mknode('-', E 1 .node, T.node ) ⑶ E → T E.node := T.node ⑷ T → T1 * F T.node := mknode('*', T1 .node, F.node ) ⑸ T → T1 / F T.node := mknode('/', T1 .node, F.node ) ⑹ T → F T.node := F.node ⑺ F → (E ) F.node:= E.node ⑻ F → id F.node := mkleaf(id, id.entry ) ⑼ F → num F.node := mkleaf(num, num.val)
声明语句的翻译:


类型主要为了辅助翻译和类型检查(辅助检查程序)。

类型表达式:



array(I,T),举例:array(3,int)表示的是int【3】。int[3]一整个作为标识符的类型~
int【2】【3】则是array(2,array(3,int))
还有指针构造符pointer

这个类型表达式表示记录,这个记录有n个字段,每个字段的名字分别是Nn,每个字段的类型分别是Tn。
看个例子:

record可以用来表示结构体~

注意定义域不是char,而是char*char。
类型等价:




语义属性、辅助过程与全局变量设置:

过程内声明语句翻译:

看个例子:

P代表程序,D是声明序列,T表示标识符的类型,B表示的基本类型关键字,C生成数组下标表达式序列。
为符号B C T设置综合属性type和width,还有三个变量,offset表示的是偏移量,也就是下一个可用的相对地址,t、w将类型和宽度信息从语法分析树中的B节点传递到对应于产生式C->epsilon的节点。
enter(name,type,offset):在符号表中为名字name创建记录,将name的类型设置为type,相对地址设置为offset。跟在声明语句后面(D)
这个SDT对应的是一个L属性定义,如果它对应的是一个LL(1)文法的话就可以进行自顶向下的分析。判定一个文法是不是LL(1)文法,就要看具有相同左部的产生式它们的select集是否不相交。
2号3号左部相同,2号的select集就是T的first集

T的first集取决于B的first集,有int和real和pointer。
第三个产生式的first集是follow(D),包括$。所以确实不相交。
再看4和5号产生式、6 7/8 9号产生式容易看出都不相交。所以该文法确实是LL(1)文法。
分析过程:
首先1号产生式进栈,动作在栈顶直接执行,使offset=0.
接着选择2号产生式:
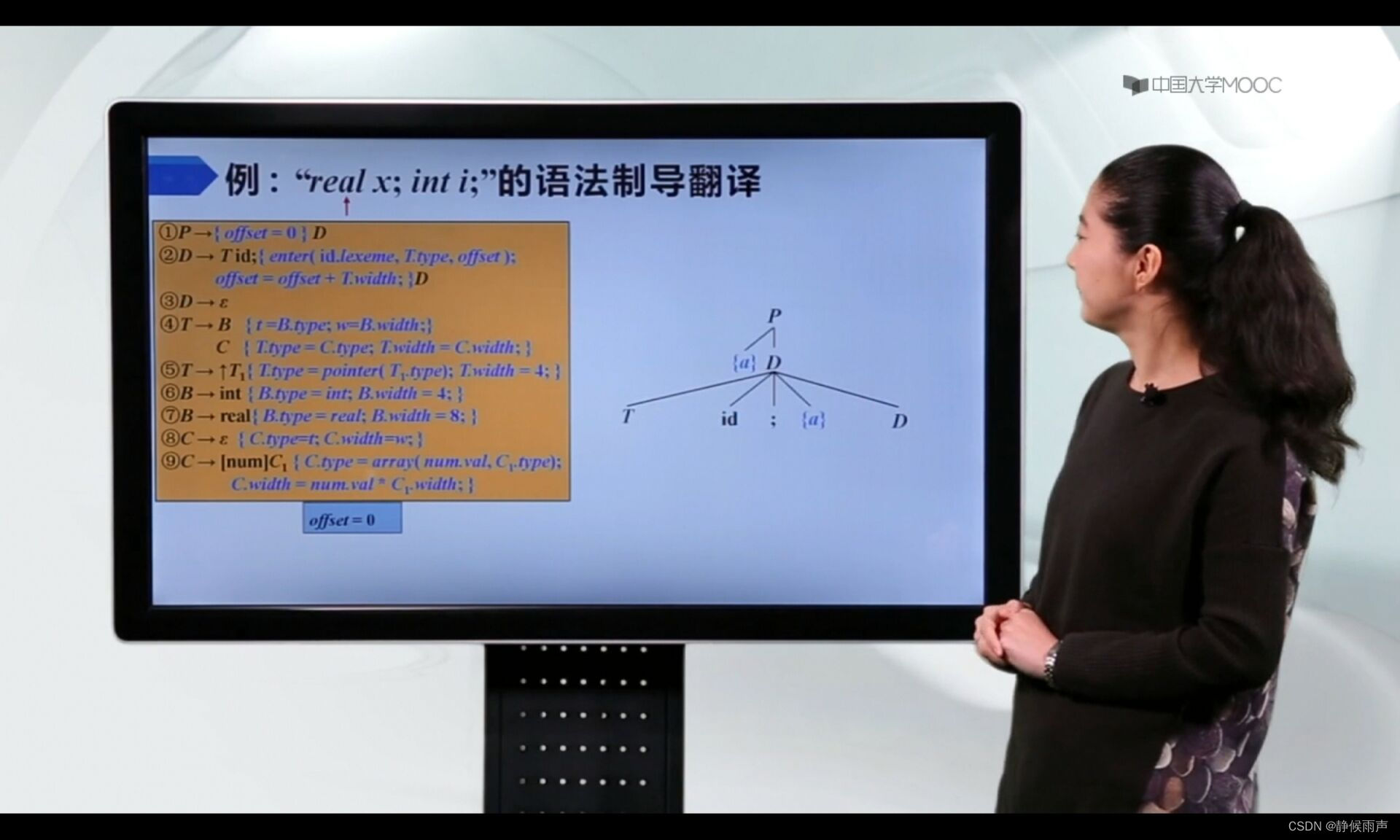
栈顶是T,选择4号产生式,B,动作,C进栈;接着real,动作进栈,real识别成功:
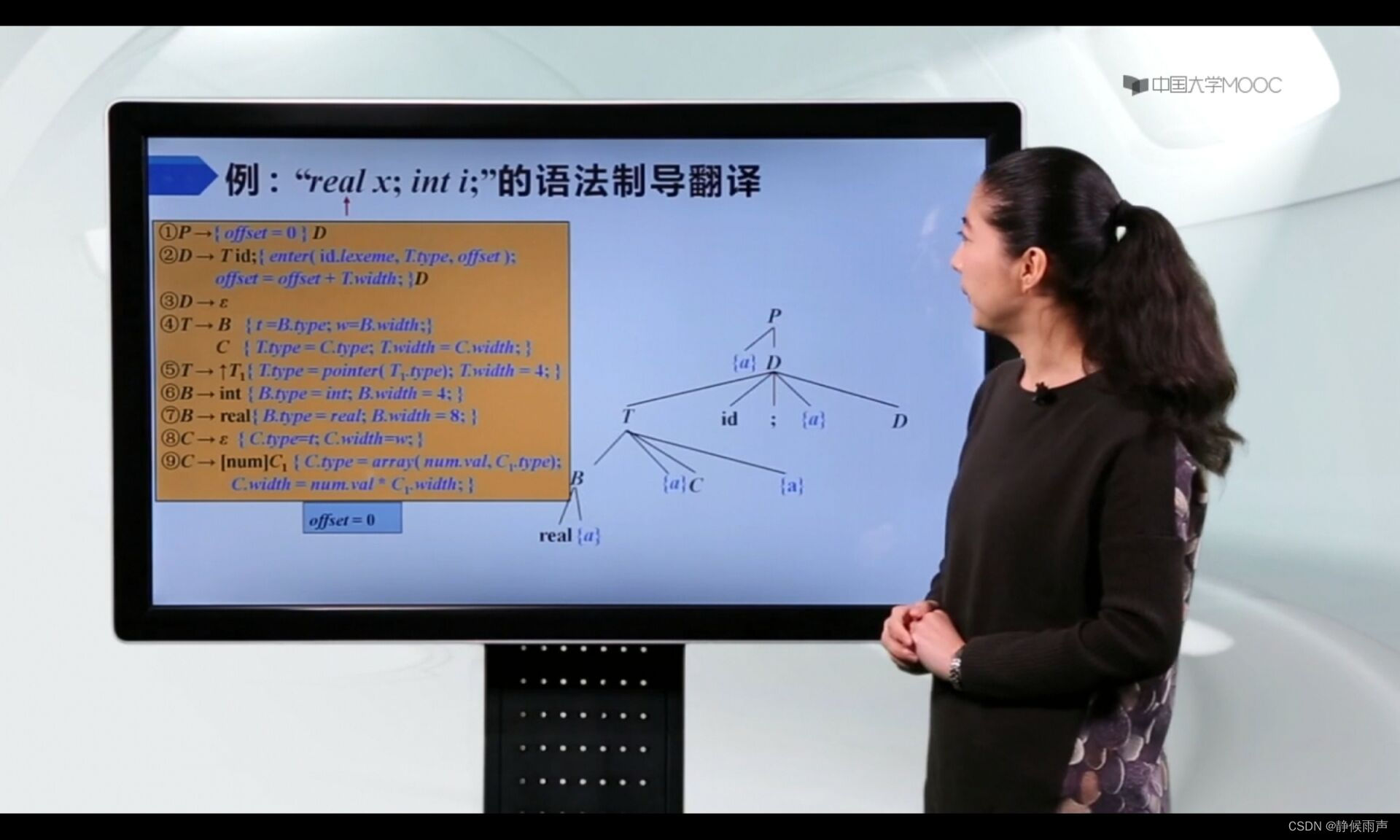
接着运行栈顶的动作,给B的属性赋值。
于是B带来的动作出栈,又露出栈顶的动作,使用t、w复制B的属性值。
接下来漏出栈顶的C,当前输入为x在8号产生式的select集中,使用8号产生式进行归约,于是栈顶又变成动作,使用t、w给C的属性赋值。
然后又露出动作(T带来的尾巴)给T的属性赋值;

T带来的东西都匹配执行完了之后轮到id,和x匹配成功;分号也匹配成功,接着又遇到动作,这次执行的是2号产生式的动作enter,为T的属性在符号表中建立记录。enter(x,real,0)
接着继续识别D 和前面的流程差不多。

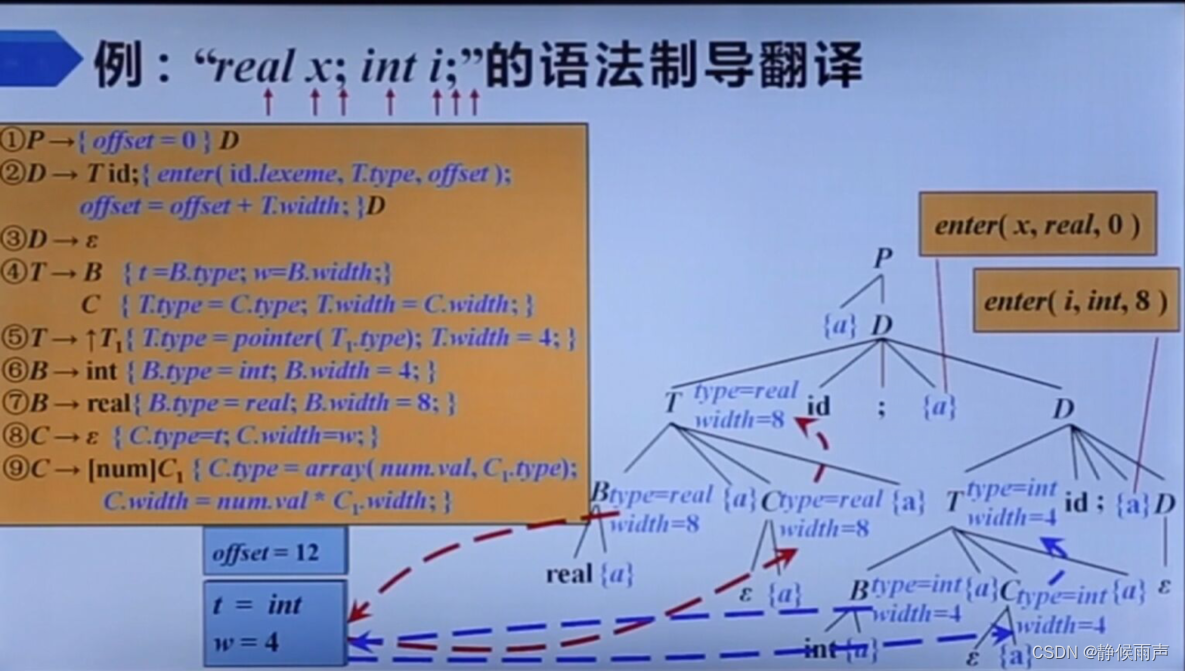
最后的offset=12,这代表分析器会为下一个变量赋值的相对地址。
注意enter代表的是这个变量在分析中的偏移量(相对地址)
再看一个:

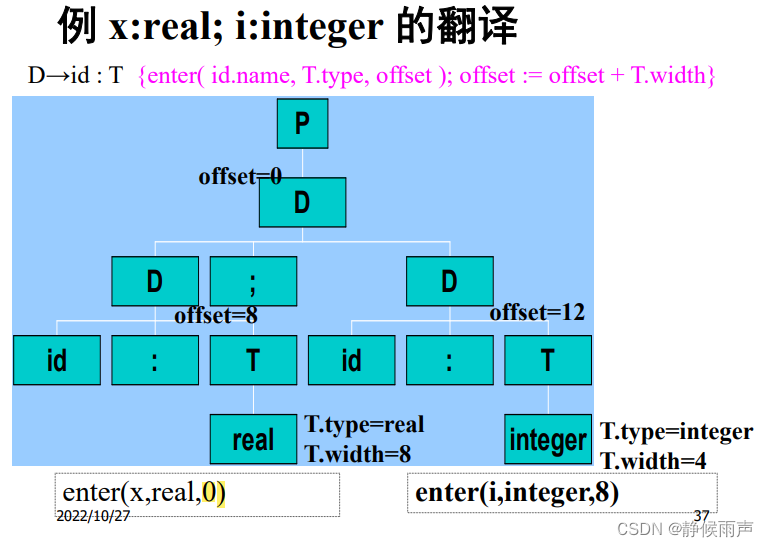

这里有一个有意思的地方,第一个例子引进了空产生式,这是因为两个例子对文法写的不一样(T推导为BC这里);特别是第一个例子使用了继承属性t、w来传参,第二个例子却没有。
经过我冥思苦想后发现,也是因为文法不同,第二个文法的格式是id:T,第一个是T:id,于是我发现第二个例子不够完整,它应该也要传参数,把id的词法值传给T,T最后传给D~( ****
嵌套过程中声明语句的翻译:
记录的翻译:
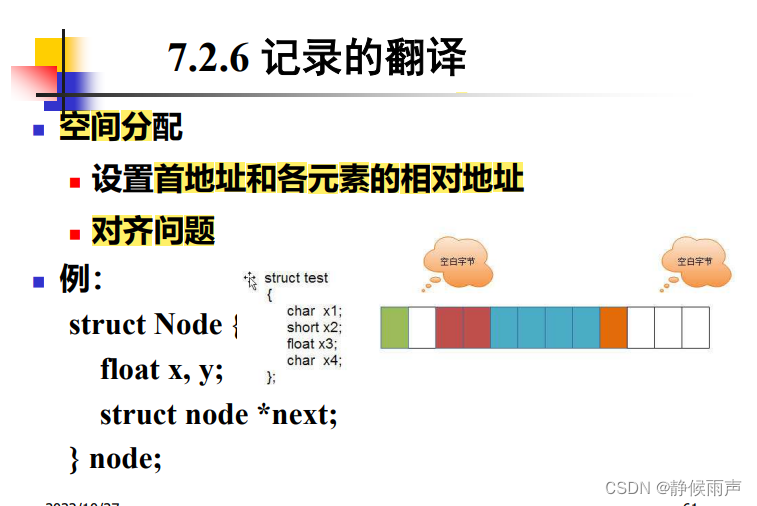

为每个记录类型单独构造符号表。


赋值语句的翻译:



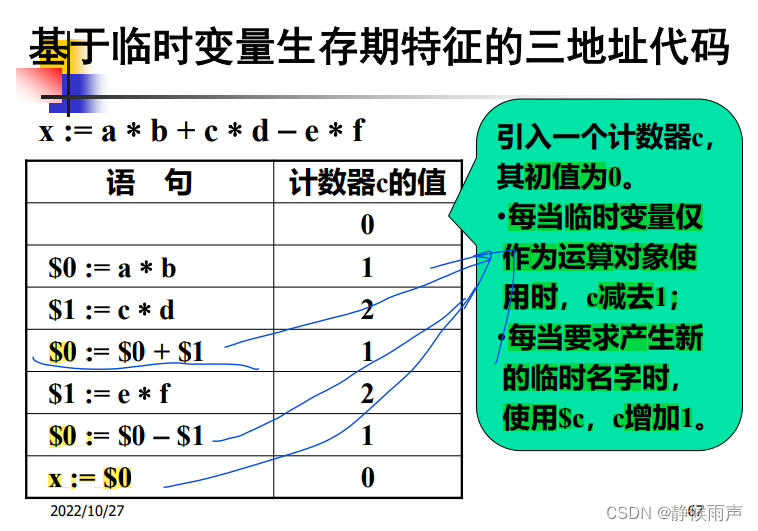
当c减一时也就是一个变量被释放之时。







 上图是数组定义的文法。
上图是数组定义的文法。
上图是和数组引用相关的赋值语句文法。
光看上上张图片(SDT)会很疑惑 我们能看出来这个文法是一个S属性文法 所以我们采用自底向上的分析顺序分析这个数组A。offset的目的是为了求整体数组值A[y,z]它在数组A的哪个位置(偏移量),为了最后能把值取出来,才要求偏移量。而addr这个综合属性就是为了自底向上计算出数组A在offset处的值。自底向上把属性传一遍就很清晰了。
我当时卡在这个例子的:
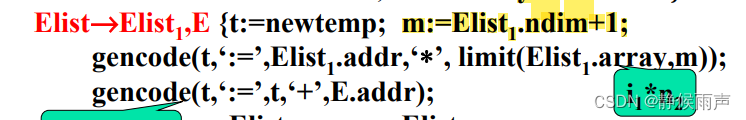
我当时觉得limit的参数不应该是Elist1,而是Elist,因为Elist1怎么会有m维呢?上面m就是用Elist1.ndim+1计算出来的呀!后来想明白了,Elist1还真有m维,这里Elist1的array属性是从底下传上来的,可以看出来其实Elist1也指向A,A的维数就是2,这里Elist1.ndim的值是1,其实是因为ndim表示的不是真的数组的维数,它表示的是目前识别出来的数组有几维~
完整分析过程:
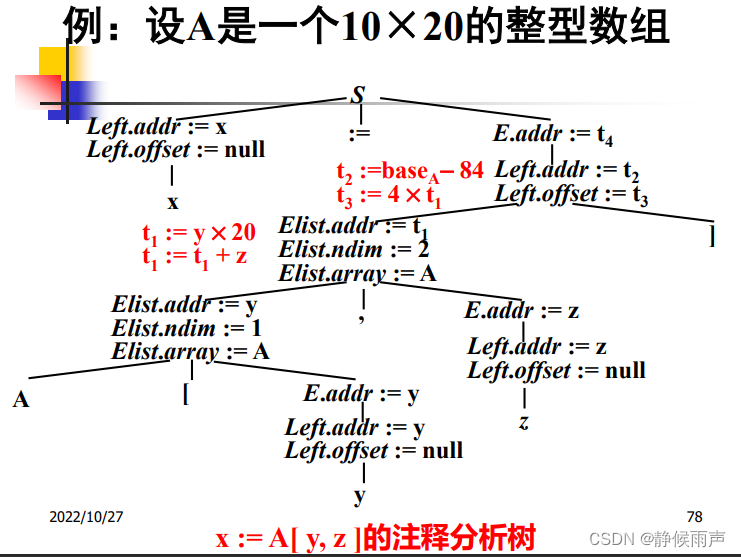
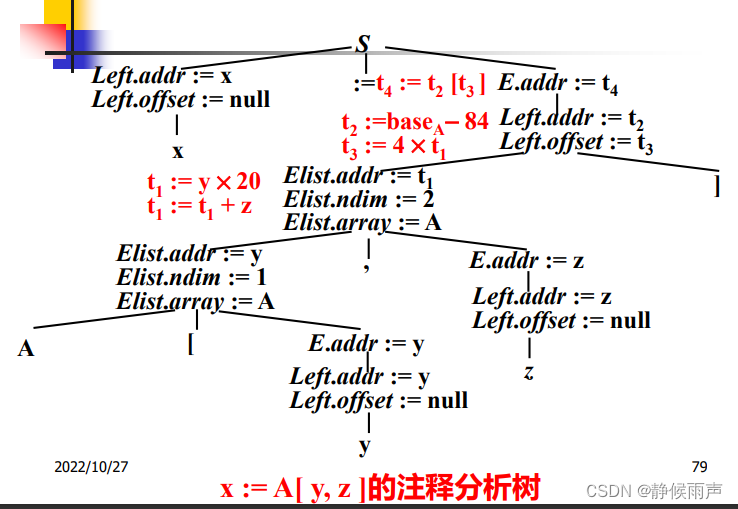



好理解 就是指针那块的知识 可以把a、a[i1]、a[i1][i2]……看做是数组的名字,后面跟着的就是这个数组的下标。

类型检查:



类型综合要求名字在引用之前必须先进行声明。

逆推。

强制类型转换呗

在创建一个新的变量来存储的时候需要新建newtemp。相当于分配存储空间。
控制结构的翻译:





优先级:非大于且大于或。


为什么是3:当前标号为0,nextquad=1,后面紧跟着三条三地址生成指令,所以goto的目的地就是标号为4,也即是B.addr=1。
注意addr是指针,所以在指向新东西时要设一个新的变量newtemp再赋值。

都是把表达式为假的情况放中间,跳转到为真的指令() 然后先算的所有表达式的值,最后再进行关系运算。
但是反过来放其实也无所谓啦 比如:

不过这里给的翻译方案确实是

常见控制语句翻译:





p1:

对比一下SDT:
p2:
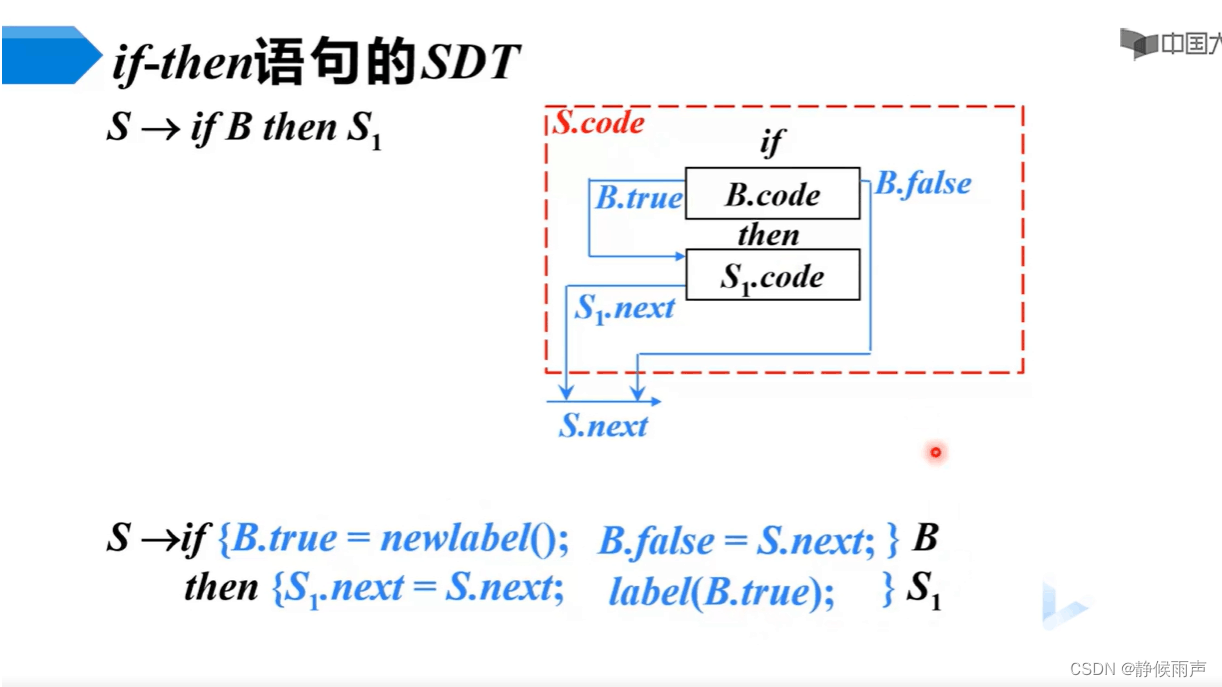
p1有一个地方要注意,就是S.code=B.code。怎么可以直接赋值呢?其实是这样,S代表的是整个大框内的三地址指令(见p2),在这个翻译过程中B是啥时候归约出现的我们管不着,它本身带有自己的三地址指令,直接存到S.code中去,然后后面的双竖线是指令的连接符号,这三个部分共同组成S.code。最后生成的三地址指令是B.true代表的语句标号+S1.code。
从p2这个SDT我们可以看到true和false啥的都是继承属性,label函数式是将后面语句的第一条赋给B.true的意思。
p1:

p2:
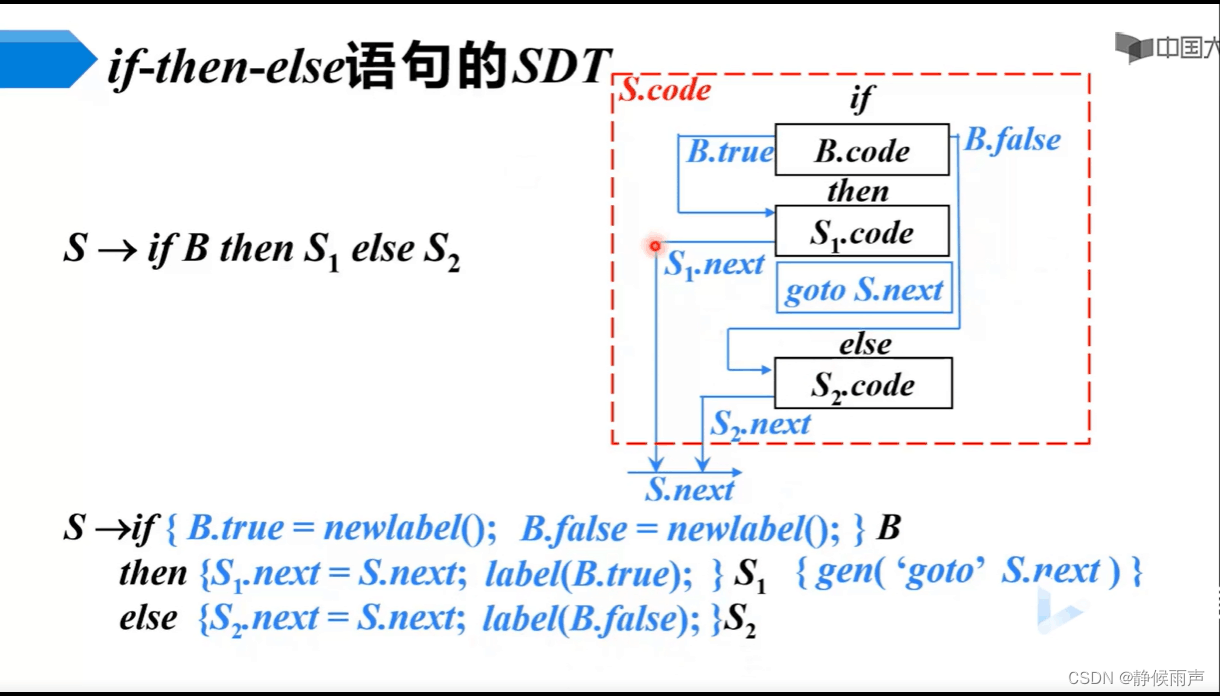
可以看出构造SDT时是自顶向下处理每一条表示属性指向的蓝线的。自己走一遍还是很好记的!


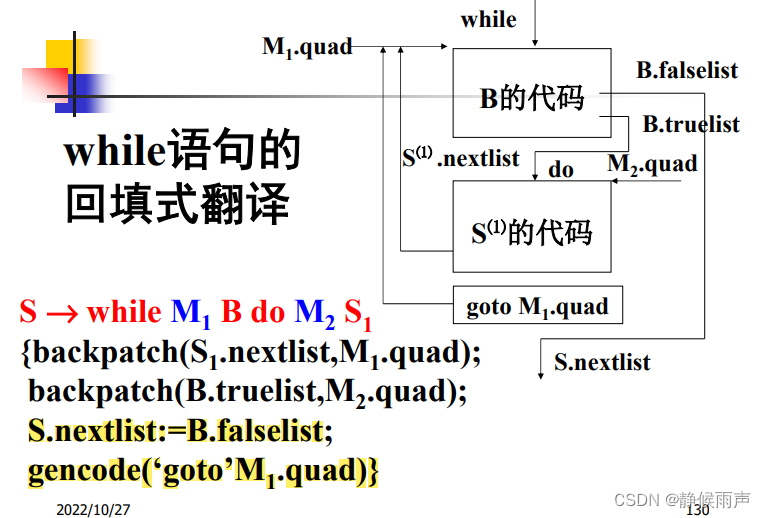
while语句在S1结束之后还需要跳回到B的第一条,所以需要建begin属性存第一条指令的标号。





根据优先级前面or是整体~


对比一下:


用数值翻译的时候还用了nextquad 这里直接用true和false来存储要跳转的标号了。
然后数值翻译在赋值1/0之前要先申请新的变量空间(使用newtemp),控制流翻译则要使用newlabel来申请新的标号。





回填:



其实严格意义上还是需要两遍 但是回填的第二遍都是知道位置的。


这里只回填B1falselist 因为分析完这一块之后也只知道它~
分析到M时 归约并且执行M.quad=nextquad 这里nextquad就是B1的第一条指令。



注意这条产生式的顺序! 回填式翻译时要用子模块的list一起merge作父亲的list;
而控制流跳转时子模块跳转时要走整体的true or false通道。


在有现成指针的时候不需要用makelist新建一个列表~这里的backpatch和merge函数也承担了创立指针的活儿
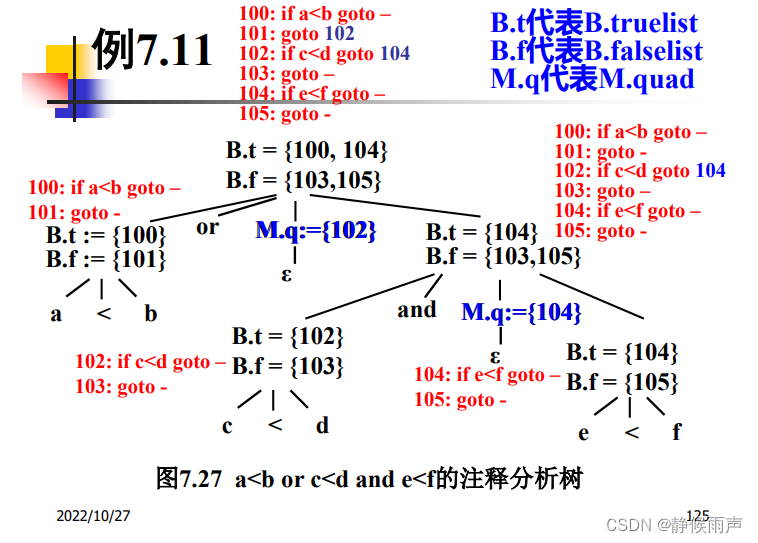
S属性文法采用自底向上分析,
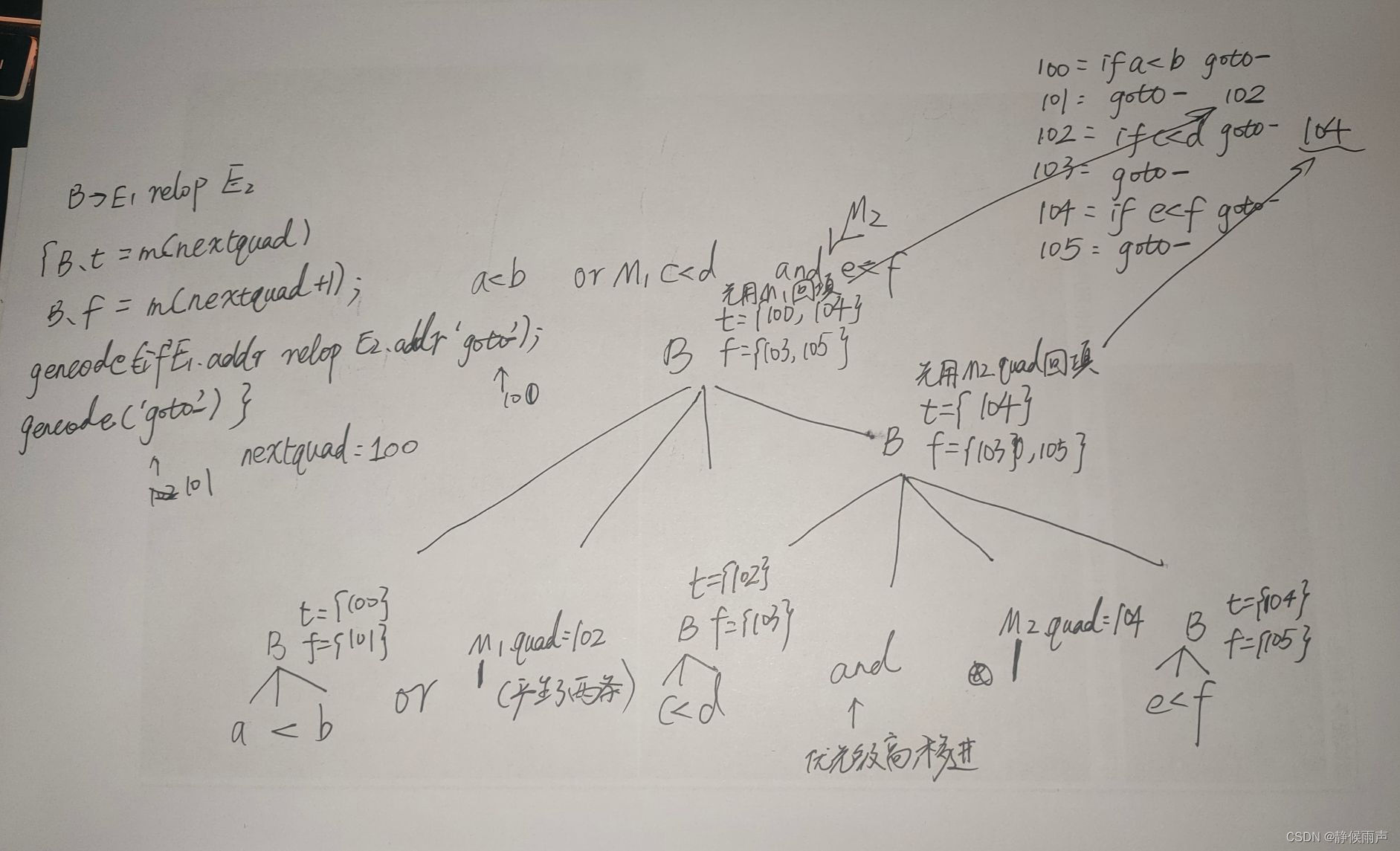
自己走一遍吧 也就是普通的SDD而已。这里加入了标记性非终结符 但是和L属性定义的自底向上翻译那里并不一样 并没有用到产生式之外的东西来计算产生式本身的值 而且本身也是S属性定义。
常见控制结构的回填式翻译:

N.nextlist:

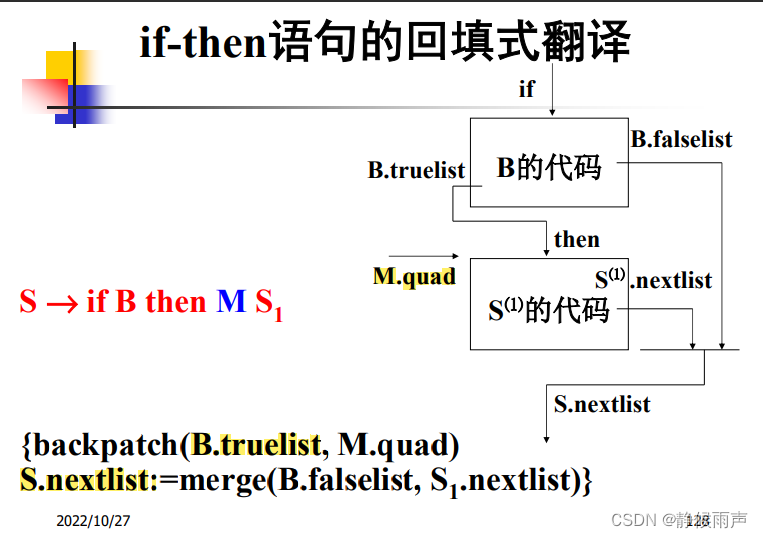
这里S不是布尔表达式了喵 是代码块 不需要真假出口了 只需要用nextlist存储接下来跳转的指令标号。
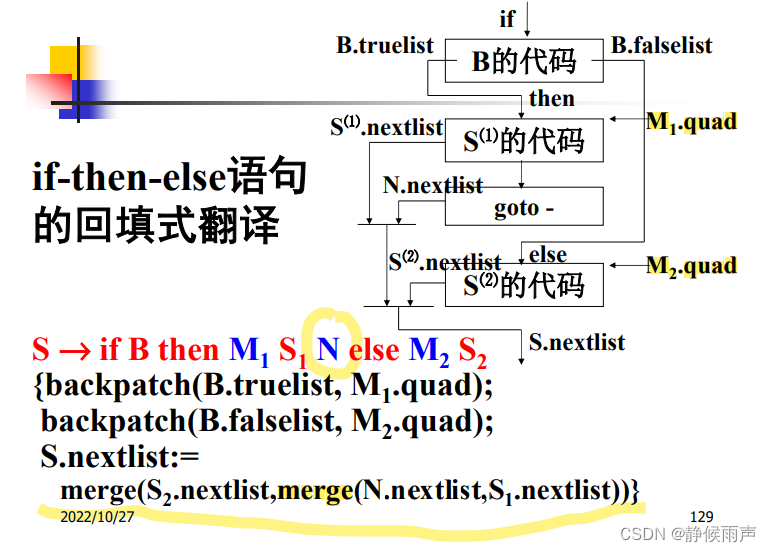
上图中N的推导没有写出来,实际上还是: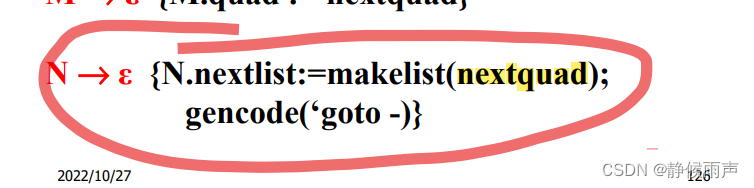
N的nextlist里保存的就是即将生成的goto语句的标号~
一旦确定N.next的标号 就回填goto语句
上面的标记性非终结符有的承担了goto的生成,这和他们所处的位置有关系。折下来这个就有点特殊:
有一个问题:这里也可以做一个N放到S1后面,承担生成goto的工作,为什么没有这样做呢?
因为没必要~之前的是不知道下一条该去的指令的标号,while循环是知道的 运行完S之后返回判断条件。所以这里只需要用M1.quad回填S1.nextlist并且生成一下goto语句就行了。


注意走进while循环说明什么?当前标号不是B1.false 而是B1.true!
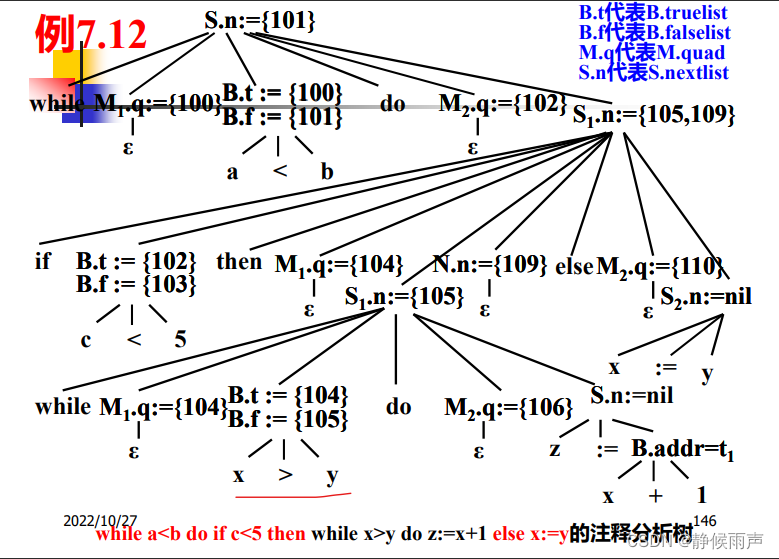

有一个值得注意的地方:109根本就是冗余的。
109是if-then-else语句生成的 是“N”生成出来的 和上面的105号指令一块走的:

S.nextlist:=B.falselist;
在这里没用上是因为if里面嵌套while这种特殊情况 每次while语句判定+执行完又回去了 直到while条件失效 但是while失效后就走了false这条道 轮不上S.nextlist了。if嵌套if就不一样了。
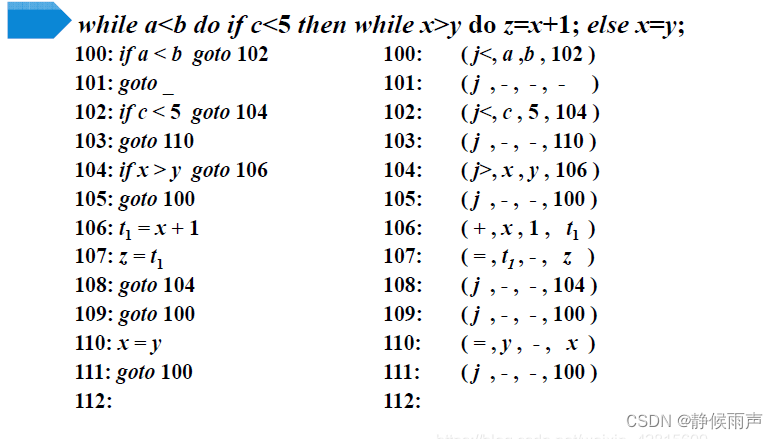
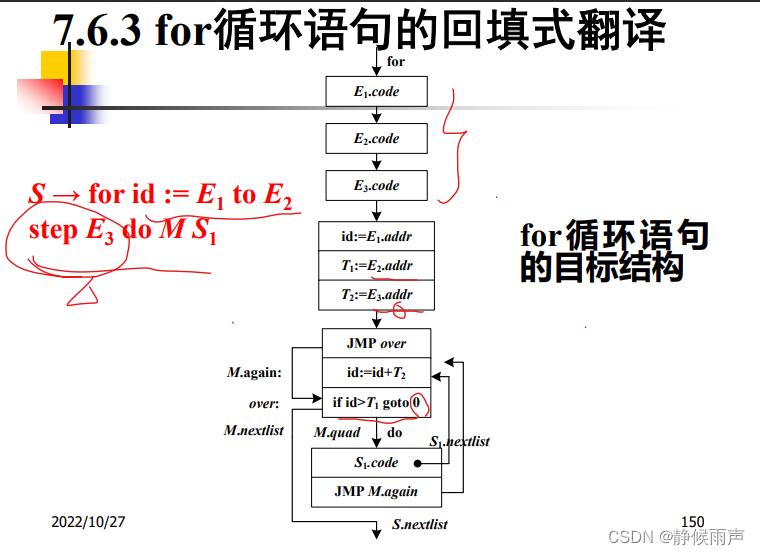
小结:



回填技术是解决单遍扫描的语义分析中转移 目标并不总是有效的问题
这句话说的太晦涩……其实就是解决第一遍扫描时要引用目前并不知晓的指令标号 子节点挖个坑等父亲节点填上罢了~
回填可以看看:http://t.csdnimg.cn/CVurM














 8508
8508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









