







Hadoop简介
Hadoop是一种分析和处理大数据的软件平台,是一个用Java语言实现的Apache的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。其主要采用MapReduce分布式计算框架,包括根据GFS原理开发的分布式文件系统HDFS、根据BigTable原理开发的数据存储系统HBase以及资源管理系统YARN。
Hadoop MapReduce原理
MapReduce最早由Google于2004年在一篇名为《MapReduce: Simplified Data Processing on Large Clusters》的论文中提出,把分布式数据处理的过程拆分为Map和Reduce两个操作函数,随后被Apache Hadoop参考并提供开源版本。
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象到了两个函数:Map和Reduce,并极大地方便了分布式编程工作,其主要包含以下过程:
- Map(映射):对一些独立元素组成的列表的每一个元素进行制定的操作,可以高度并行。
- Shuffle(重组):对Map输出的数据会经过分区、排序、分组等动作进行重组,使得key相同的分在同一个分区,同一个分区被同一个reduce处理。
- Reduce(归约):归约过程,把若干组映射结果进行汇总并输出。
用户编写的程序分成三个部分:Mapper, Reducer, Driver(提交运行程序的客户端驱动)。需要注意的是,整个MapReduce程序中,数据都是以<key,value>键值对的形式流转的。

Hadoop HDFS原理
HDFS最初是模仿GFS开发的开源系统,适合存储大文件并提供高吞吐量的顺序读/写访问。其整体架构如图所示,其由NameNode, DataNode, Secondary NameNode以及客户端构成。
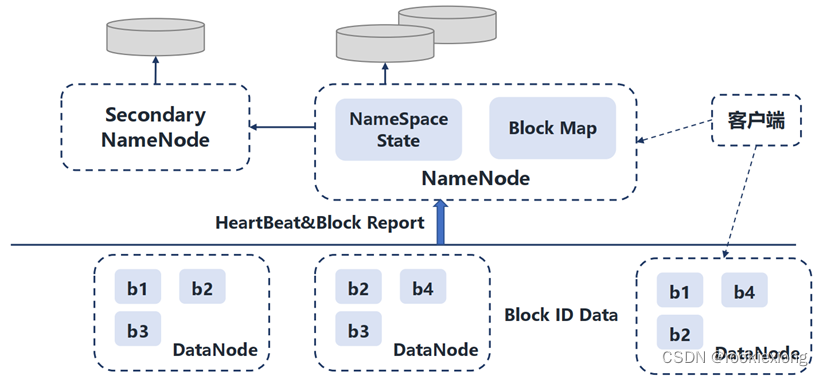
NameNode负责管理整个分布式文件系统的元数据,包括文件目录树结构、文件到数据块Block的映射关系、Block副本及其存储位置等各种管理数据。其磁盘保存两个元数据管理文件fsimage和editlog:
- fsimage是内存命名空间元数据在外存的镜像文件;
- editlog是各种元数据操作的write-ahead-log文件。
Secondary NameNode提供检查点功能服务,职责是定期从NameNode拉取fsimage和editlog文件进行合并,形成新的fsimage文件并传回给NameNode;
DataNode负责数据块的实际存储和读/写工作,为保证数据可用性,每个Block以多备份的形式存储。
同时,NameNode与DataNode通过短时间间隔的心跳来传递管理信息和数据信息,从而实现DataNode的状态监控。如果某个DataNode发生故障,NameNode会将其负责的Block在其他DataNode机器增加相应备份以维护数据可用性。
Hadoop的优点与局限性
Hadoop 是一个基础框架,具有低成本、高可靠、高扩展、高有效、高容错等特性,能够进行海量数据的离线处理。
Hadoop允许用简单的编程模型在计算机集群上对大型数据集进行分布式处理。用户可以在不了解分布式底层细节的情况下,轻松地在 Hadoop 上开发和运行处理海量数据的应用程序。
同时其计算能力可以随节点数目增长保持近似于线性的增长,它的设计规模从单一服务器到数千台机器,每个服务器都能提供本地计算和存储功能,框架本身提供的是计算机集群高可用的服务,不依靠硬件来提供高可用性。
但MapReduce主要应用于离线作业,无法作到秒级或者是亚秒级得数据响应。且主要是针对静态数据集,不能进行流式计算。















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









