






 本文对比了PyTorch中的DataParallel与DistributedDataParallel(DDP)在分布式训练中的优缺点,介绍了DDP的All-Reduce模式、多进程优势以及如何使用torch.distributed库进行高效训练。
本文对比了PyTorch中的DataParallel与DistributedDataParallel(DDP)在分布式训练中的优缺点,介绍了DDP的All-Reduce模式、多进程优势以及如何使用torch.distributed库进行高效训练。
一. 两种分布式训练的方式
1.DataParallel (DP):实现简单,代码量较少,启动速度快一点。但速度较慢,且存在负载不均衡的问题。单进程,多线程。主卡显存占用比其他卡会多很多。不支持 Apex 的混合精度训练。是Pytorch官方很久之前给的一种方案。受 Python GIL 的限制,DP的操作原理是将一个batchsize的输入数据均分到多个GPU上分别计算(此处注意,batchsize要大于GPU个数才能划分)。
2.DistributedDataParallel (DDP):All-Reduce模式,本意是用来分布式训练(多机多卡),但是也可用于单机多卡。配置稍复杂。多进程。数据分配较均衡。是新一代的多卡训练方法。使用 torch.distributed 库实现并行。torch.distributed 库提供分布式支持,包括 GPU 和 CPU 的分布式训练支持,该库提供了一种类似 MPI 的接口,用于跨多机器网络交换张量数据。它支持几种不同的后端和初始化方法。DDP通过Ring-Reduce的数据交换方法提高了通讯效率,并通过启动多个进程的方式减轻Python GIL的限制,从而提高训练速度。
二. DDP实现步骤
1.需要导入的包

其中dist负责多线程通信,DDP负责模型传递工作
2.通信进程初始化
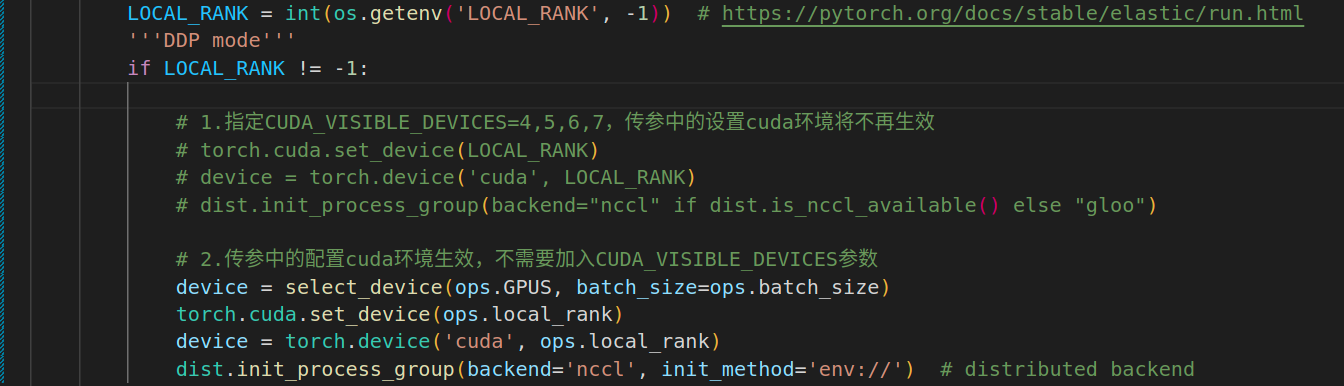
其中local_rank设置为-1即可
3.使用DistributedSampler封装数据

4.将模型放到cuda上封装

5.训练时,将数据放到device上
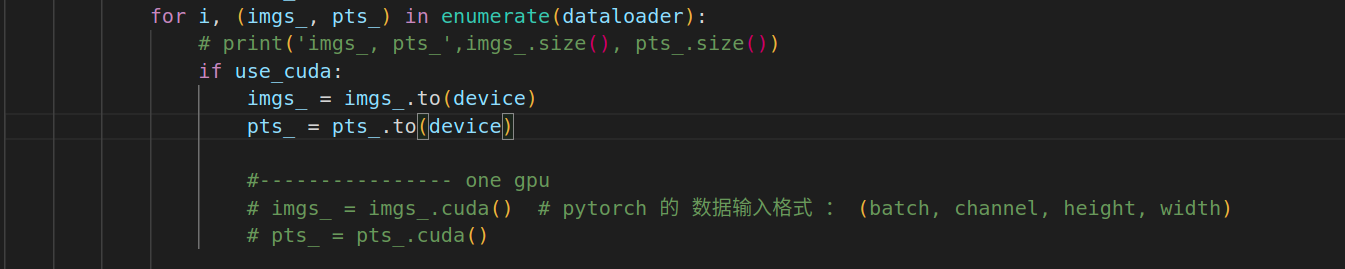
执行命令:
python3 -m torch.distributed.launch --nproc_per_node=4 --master_port=60055 train.py --GPUS 4,5,6,7

















 1541
1541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









