






分布式训练是一种常见的多卡加速训练的一种策略,一般来说有两种方式可选择:DataParallel(DP)和DistributedDataParallel(DDP)。本文介绍的是最常使用的DDP。下面演示如何把一个单卡运行的程序修改成可以单卡也可以多卡的形式。
单卡程序如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc = nn.Linear(28 * 28, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.fc(x)
return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root='./', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# Adding the test dataset and loader
test_dataset = datasets.MNIST(root='./', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
model = SimpleNN().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Initializing the loss function outside of the loops
criterion = nn.CrossEntropyLoss()
# Training
for epoch in range(5):
train_sampler.set_epoch(epoch) # 设置随机种子
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target) # using the initialized loss function
loss.backward()
optimizer.step()
# Testing
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # using the initialized loss function
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.0f}%)\n')
可以看到是一个简单的分类任务。在展示多卡运行代码前先理解一些概念。
DDP我理解为每张卡各自执行同一个训练代码,但是进程号不同。训练过程也就是一个进程。拿单机四卡举例,进程号分别是0,1,2,3。
DDP包含单机多卡(常用)和多机多卡两种模式,这里只介绍单机多卡模式。
通常我们需要导入两个包
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
设置group
一般默认一个组
dist.init_process_group(backend='nccl')
world size
表示全局的进程总数
torch.distributed.get_world_size()
rank
当前进程的序号,用于进程间通讯。对于两台八卡服务器的world size来说,就是0,1,2,…,15。
注意:rank=0的进程就是master进程。
# 获取rank,每个进程都有自己的序号,各不相同
torch.distributed.get_rank()
local_rank
这是每台机子上的进程的序号。机器一上有0,1,2,3,4,5,6,7,机器二上也有0,1,2,3,4,5,6,7
torch.distributed.local_rank()
对于单机多卡模式来说,rank和local_rank没区别,因为只有一台机器。
下面贴代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import argparse
# ddp需要使用的包
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 设置local_rank,默认设置成-1。因为如果使用torch.distributed.launch启动ddp,则local_rank自动为每张卡分配。从0开始。要记住每张卡的程序的区别就是local_rank不同。因为我们要使用主进程测试和保存模型
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank',type=int,default=-1)
args = parser.parse_args()
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc = nn.Linear(28 * 28, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.fc(x)
return x
# 初始化ddp环境,为每个进程分配卡
if args.local_rank >= 0:
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend='nccl')
ddp = True
else:
ddp = False
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
criterion = nn.CrossEntropyLoss()
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root='./', train=True, download=False, transform=transform)
test_dataset = datasets.MNIST('./', train=False, download=False, transform=transform)
# train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 这里要注意,多卡训练需要使用ddp的方式设置sample。保证每张卡分配的批次是不同的
if ddp:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = DataLoader(train_dataset, batch_size=32, sampler=train_sampler)
else:
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 测试只需要在一张卡上进行,因为要使用一张卡在所有测试数据上进行测试
test_loader = DataLoader(test_dataset, batch_size=1000)
model = SimpleNN().to(device)
# 使用ddp封装模型,同时对学习率进行了放大。因为使用学习率*梯度更新参数。每张卡的模型参数是一致的,由于多卡训练导致有效批次增大。比如之前是单卡学习率0.01,反向传播的时候使用0.01*一个批次的梯度进行参数更新。现在是多卡,所以是0.01*gpu数目*gpu数目的批次的梯度更新参数
if ddp:
model = DDP(model, device_ids=[args.local_rank])
gpu_num = torch.distributed.get_world_size()
else:
gpu_num = 1
optimizer = optim.SGD(model.parameters(), lr=0.01*gpu_num)
# Training
for epoch in range(5):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 测试时仅使用主进程
if not ddp or (ddp and dist.get_rank() == 0):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.cuda(), target.cuda()
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(
f"\nTest set: Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset)}%)\n")
# ddp使用主进程保存模型,不然的话保存多次没必要。
if not ddp or (ddp and dist.get_rank() == 0):
torch.save(model.state_dict(), 'ddp_model.pth')
最后使用下列命令启动ddp
python -m torch.distributed.launch --nproc_per_node=2 ddp_code.py
下面是运行结果
单卡
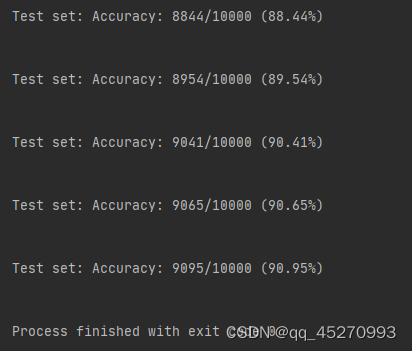
多卡
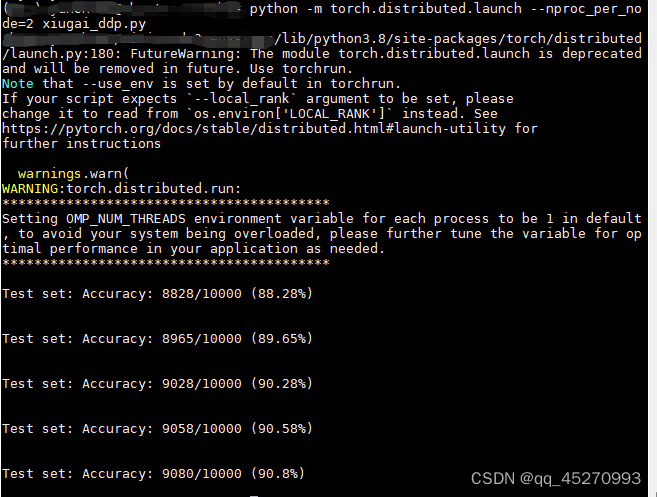
可以看到准确率基本持平
















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









