






2.4.1 什么事特征预处理
为什么要进行归一化、标准化
无量纲化
2.4.2归一化:对于归一化来说,如果出现异常点,影响了最大值和最小值,那么结果显然是会发生改变的
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
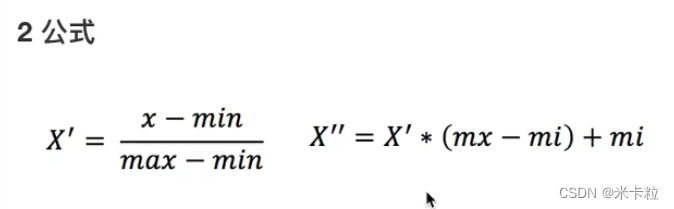
异常值:最大值 最小值
2.4.3 标准化:对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点,对于平均值的影响并不大,从而方差改变较小

(x - mean)/ std
标准差:集中程度
def minmax_demo():
"""
归一化
:return:
"""
# 1 获取数据
data = pd.read_csv("lizi")
data = data.iloc[:, :3]
print("data:\n", data)
# 2 实例化一个转换器类
# transfer = MinMaxScaler()
transfer = MinMaxScaler(feature_range=[2,3])
# 3 调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
def stand_demo():
"""
标准化
:return:
"""
# 1 获取数据
data = pd.read_csv("lizi")
data = data.iloc[:, :3]
print("data:\n", data)
# 2 实例化一个转换器类
transfer = StandardScaler
# 3 使用fit_transfer
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None由于 factor_returns.csv 没有找到,所以不知道可不可以运行
def variance_demo():
"""
过滤低方差特征
:return:
"""
# 1、获取数据
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
print("data:\n", data)
# 2、实例化一个转化器
transfer = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new, data_new.shape)
return None2.5.1 降维 - 降低维度
ndarray
维数 : 嵌套的层数
二维数组
此处的降维:降低特征的个数
效果: 特征与特征之间不相关
2.5.1 降维
特征选择
Filter过滤式
方差选择法:低方差特征过滤
相关系数 - 特征与特征之间的相关程度
取值范围: -1 ~1
特征与特征之间的相关性很高:
1)选取其中一个
2)加权求和
3)主成分分析
Embeded嵌入式
def variance_demo():
"""
过滤低方差特征
:return:
"""
# 1、获取数据
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
print("data:\n", data)
# 2、实例化一个转化器
transfer = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new, data_new.shape)
# 计算两个变量之间的相关系数
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\n", r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print("revenue与total_expense之间的相关性:\n", r2)
return None决策树 正则化 深度学习
主成分分析:
2.6.1 什么是主成分分析(PCA)
sklearn.decomposition.PCA(n_compinents=None)
n_components
def pca_demo():
"""
PCA
:return:
"""
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 1 实例化一个转换器类
transfer = PCA(n_components=2)
# 调用fit_transform(data)
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None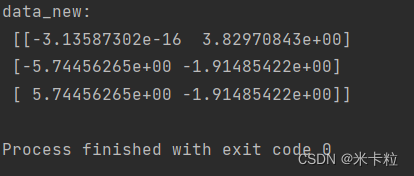
小数 表示保留百分之多少的信息量
整数 减少到多少特征
2.6.2案例探究用户对物品类别的喜好细分
用户 物品类别
1)需要将user_id和aisle放在同一个表中 —— 合并
2)找到user_id和aisle —— 交叉表和透视表
3)特征冗余过多 ——> PCA降维














 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









