







本文比较适宜于那种结构化数据的传统机器学习。但是深度学习的话,那也有很大概率会用到特征工程。因此在此做出总结,以资借鉴。
本文仅考虑结构化数据,不对使用图像、文本等非结构化数据进行表征、特征提取的工作进行介绍。
特征工程是玄学。本文仅作收集及按照本人理解做出讲解,具体的丹能不能炼出来还是要靠命。
文章目录
0. 通用内容
观察数据类型→检查数据分布
一个通用baseline代码:https://github.com/yzkang/My-Data-Competition-Experience/blob/master/general_baseline.py
(以后我也要写个我自己的)
一个用ChatGPT的解决方案:Harnessing ChatGPT for Automated Data Cleaning and Preprocessing - KDnuggets
感觉有点臃肿,毕竟很多代码如果你自己差不多就会写的话其实也不需要用ChatGPT倒来倒去的,而且ChatGPT还有幻觉问题……但是也可供参考,以后可以将LLM助手嵌入到编程过程中嘛。
1. 特征选择
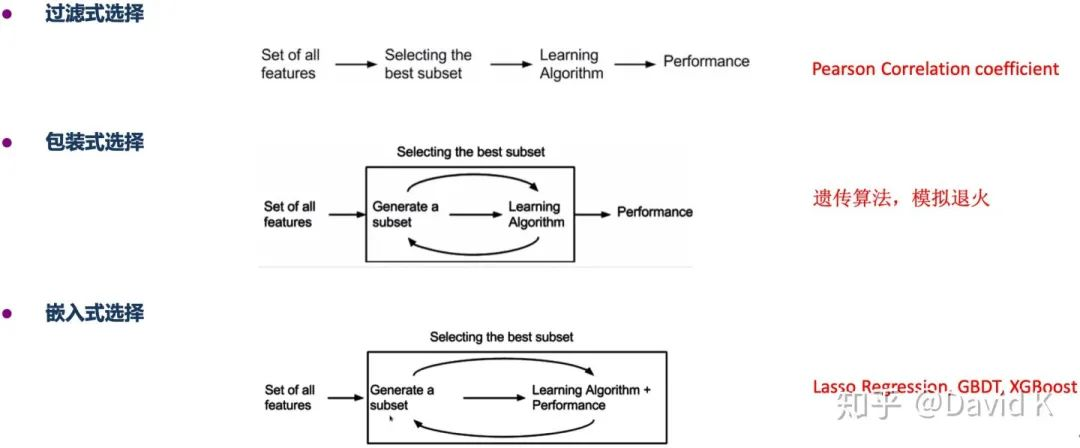
- 相关系数:分类变量-数值变量用斯皮尔曼系数,数值变量-数值变量用皮尔森系数
示例代码:s_ce=y.corr(x,method='spearman') #spearman coefficient p_ce=y.corr(x) #pearson coefficient - SelectKBest
示例代码:from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_regression K=20 bestfeatures = SelectKBest(score_func=f_regression, k=K) bestfeatures.fit(x,y) selected_feature_columns=list(bestfeatures.get_support(True)) - 基尼系数
- 信息增益
- stepwise
2. 数值型特征处理
1. 无量纲化/归一化/正则化
(这部分内容我在小红书上更新过一个更简单的初版:深度学习中的trick | 常见归一化维度和方法)
归一化的维度:
- 列归一化:传统机器学习常采用,为防止某些特征的量级远高于其他特征
- 行归一化:GNN中常用(从GCN到APPNP官方实现代码都会有),抹平在预测过程中节点之间特征值大小的量差(因为GNN是非欧数据,需要做MP,所以会有这个影响需要抹除,其他IID的任务这样做感觉一般不会产生什么影响的)
- 参数需要训练的归一化神经网络:Batch normalization(对batch的每一维特征进行归一化) VS. Layer normalization1(对时序数据每一个时间步的特征进行归一化):Z-Score归一化
归一化的方法:
- 最大最小归一化
MinMaxScalar - Z-Score归一化
StandardScalar - LP归一化:将特征等比例缩放到总和为特征向量的LP模长。可参考函数
torch.nn.functional.normalize的实现- GNN中常用的做法(L1归一化):将特征(或者减去最小值后的特征)等比例缩放到总和为1。可以保留原数据中的稀疏性(可以参考PyG实现NormalizeFeatures类的实现,或者我的GitHub项目PolarisRisingWar/rgb-experiment的实现)
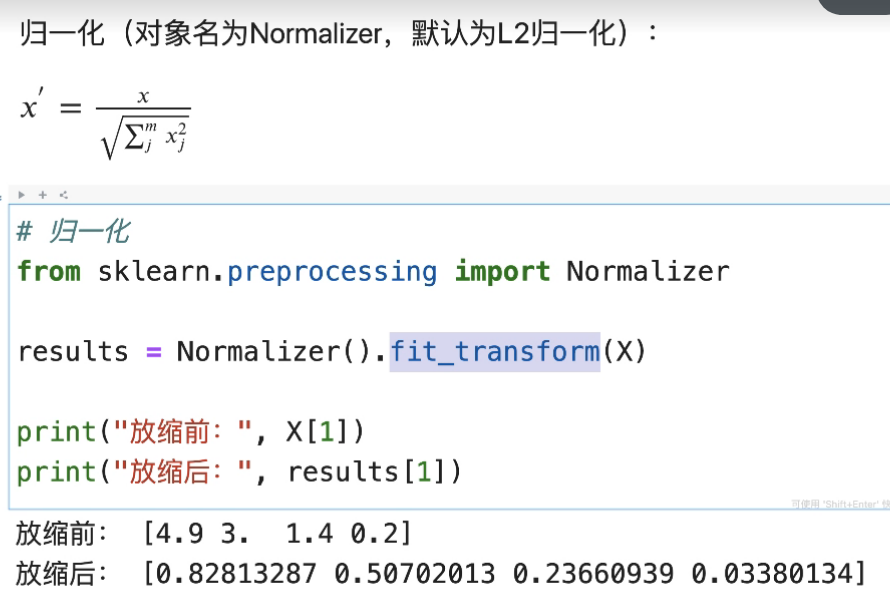
- L2归一化
sklearn.preprocessing.Normalizer的实现
lambda x:x / (torch.max(torch.norm(x, dim=1, keepdim=True), epsilon))(参考自HGB/GNN.py at master · THUDM/HGB,此处设置的epsilons是1e-12)- tf.math.l2_normalize的实现
- MaxAbs
- PCA whitening
由于图数据的特殊性,对图特征的归一化工作有更复杂的解释,以下是代码实践实例和来自各方的原因解释:
- PPNP项目
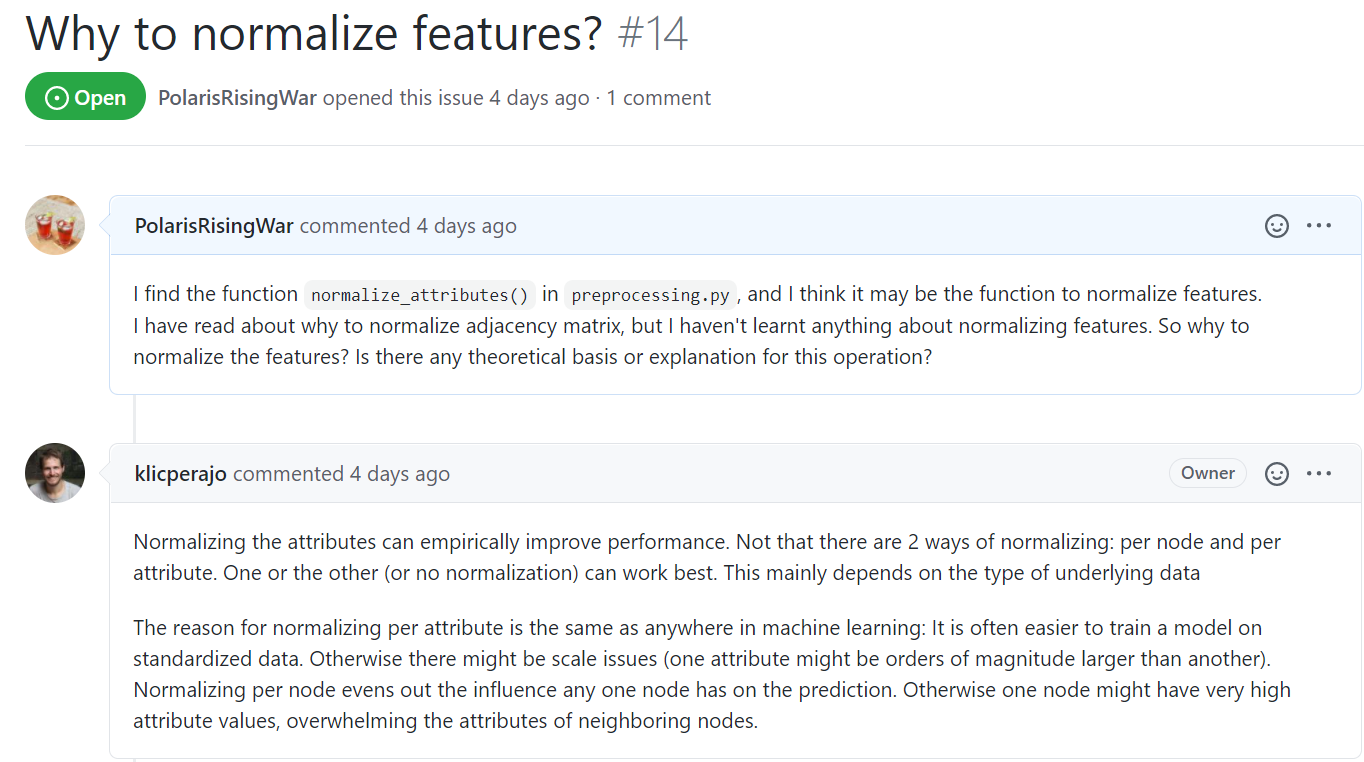
- PTA项目
Is code inutilsline 117-line 120 real? · Issue #1 · DongHande/PT_propagation_then_training:我问了一下为什么要做归一化,作者给出的解释是从GCN开始大家一以贯之 - GCN项目:反正他们也有
- 来自实验室学长:
一般做归一化就是均值方差或最大最小,但图数据因为很稀疏、又想归一化又想要保持0值,所以就会用这种方式来归一化。比如Cora数据集(one-hot有很多0)如果做了均值方差就会有很多不是0的就会出现过拟合,使效果变差
在实践上,有的数据集感觉做了行归一化之后效果确实会变好,但是大部分数据集在大部分模型上效果反而更差了呢……
感觉在具体的实验中,可以尝试行归一化/列归一化/不归一化三种操作,视最后对本项目最有益的结果而定。
我自己的实现可以参考我之前写的集成代码:https://github.com/PolarisRisingWar/rgb-experiment/blob/master/rgb_experiment/itexperiments.py#L261
图邻接矩阵的归一化不是这么回事,可参考我写的这篇博文:GNN邻接矩阵归一化
2. 分箱
3. 分类型特征处理
1. 哑编码/独热编码
2. rescaling
4. 特征创建
- 理解字段
抽取实体
分析实体关系
设计特征群
按特征群分别构造特征
考察特征群关系,进一步构造新特征 - 交叉衍生
5. 特征变换
连续变量离散化(分箱)
-
等频
-
等宽
-
聚类
离散变量编码
-
One-hot Encoding
-
Label Encoding
长尾分布
- Ln、Log
6. 降维
奇异值分解SVD
PCA
AHP
卷积
- 共线性分析
- IV值处理
7. 缺失值、异常值处理
缺失值插补
-
均值、中位数、众数插补
-
固定值插补
-
最近邻插补
离群值
-
直接删除
-
替换法
异常、冗余值
- 直接删除
小技巧:用训练集数据学习一个模型,然后用它预测训练集的标签,删除预测结果偏差较大的样本
8. 数据不平衡问题处理
- 调节权重
- 下采样
- 过采样
- 罚项
9. 聚类
10. 数据探索
对比,分组,频数,抓大放小和可视化
所谓对比,指的是在做数据探索时,考虑对比训练集不同样本之间的特征分布,还要考虑对比训练集和测试集中每一个特征的分布。
所谓分组,就是在做数据探索时,常常用到按类别标签、某个离散变量的不同取值groupby后的sum、unique。
所谓频数,就是要注意考察并自行计算某些变量的概率累积分布。诸如“事件发生次数”这样的的统计量需要自己计算;有时还要关注“同id下某个事件多次发生”的统计。
所谓抓大放小,就是对于那些特征重要性较高的变量,要做重点分析。因为这些变量对你模型预测能力的影响是较大的。
所谓可视化,就是建议大家在做数据探索的时候多画图(尤其是各种趋势图、分布图),图形给人的冲击力往往是要大于数字本身的。
多表数据整合
-
一对一
-
一对多
-
多对一
-
多对多
11. 数据重采样
滑窗法:
-
对于时间序列数据,选取不同的时间窗间隔,可以得到多份训练数据集
-
该方法可以增加训练样本,也方便做交叉验证实验
非平衡重采样:调整正负样本量
-
欠采样
-
过采样
-
组合采样
参考资料
- 使用sklearn做单机特征工程:还没补完
- 数据科学竞赛:你从未见过的究极进化秘笈!:这篇还讲了一些别的,调参经验、baseline等,值得参考
- Kaggle知识点:特征工程实施步骤:这篇很值得作为数据竞赛的入门资料。但是内容上有点太传统、太科班了,所以对老手来说参考价值不是很大。但是也有启发
- 数据竞赛中如何优化深度学习模型
- 待补
- Machine Learning — Singular Value Decomposition (SVD) & Principal Component Analysis (PCA) | by Jonathan Hui | Medium
- 使用sklearn做单机特征工程 - jasonfreak - 博客园
- Feature Engineering and Selection:这是一门2009年的课程(全课的官网:Computer Science 294: Practical Machine Learning)中的一部分,老而弥坚了属于是……
- 手把手教你用sklearn做特征工程_sklearn_features_fuqiuai的博客-CSDN博客
- 特征选择-机器学习_前向搜索策略_声声慢z的博客-CSDN博客
- fastai中的图像增强技术为什么相对比较好: https://oldpan.me/archives/fastai-1-0-quick-study
- 一文归纳Ai数据增强之法
- Python特征选择的总结
(2016) Layer Normalization ↩︎
















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











