







目录
1. 请导入相应模块并获取数据。导入待处理数据tips.xls,并显示前5行。
5.分析小费金额和消费总额的关系,小费金额与消费总额是否存在正相关关系。画图观察。
6分析男女顾客哪个更慷慨,就是分组看看男性还是女性的小费平均水平更高
本实训主要对小费数据进行数据的分析与可视化,用到的数据放在文件中。
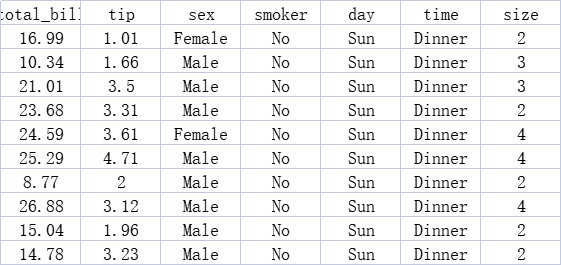
1. 请导入相应模块并获取数据。导入待处理数据tips.xls,并显示前5行。
# 导入相应模块
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据并显示前5行
tips_data = pd.read_excel('tips.xls')
print(tips_data.head())
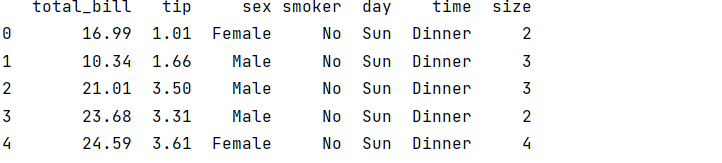
2、分析数据
1、查看数据的描述信息
2、修改列名为汉字(total_bill--消费总额,tip--小费,sex--性别,smoker--是否抽烟,day--星期,time--聚餐时间段,size--人数),并显示前5行数据。
# 导入数据并显示描述信息
print(tips_data.describe())
# 修改列名并显示前5行
tips_data.columns = ['消费总额', '小费', '性别', '是否抽烟', '星期', '聚餐时间段', '人数']
print(tips_data.head())
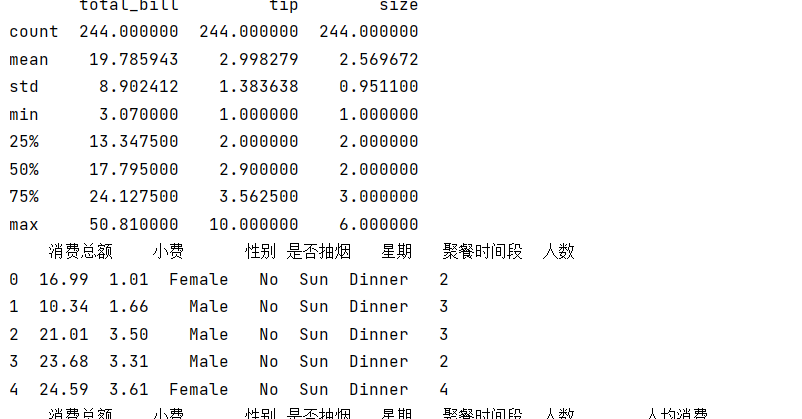
3.增加一列“人均消费”
# 导入数据并增加“人均消费”列
tips_data['人均消费'] = tips_data['消费总额'] / tips_data['人数']
print(tips_data.head())
4查询抽烟男性中人均消费大于5的数据
# 导入数据并查询抽烟男性中人均消费大于5的数据
smoking_male = tips_data[(tips_data['是否抽烟']=='Yes') & (tips_data['性别']=='Male')]
result = smoking_male[smoking_male['消费总额'] / smoking_male['人数'] > 5]
print(result)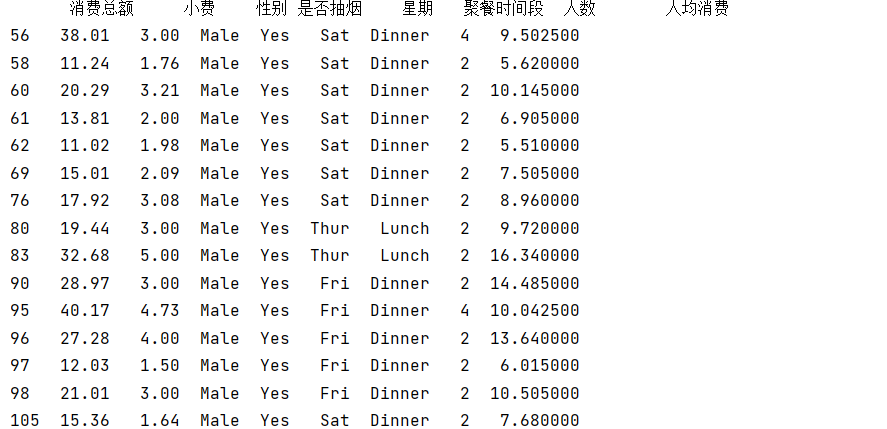
5.分析小费金额和消费总额的关系,小费金额与消费总额是否存在正相关关系。画图观察。
# 导入数据并绘制散点图
x = tips_data['消费总额']
y = tips_data['小费']
plt.scatter(x, y)
plt.xlabel('Total bill')
plt.ylabel('Tip')
plt.show()
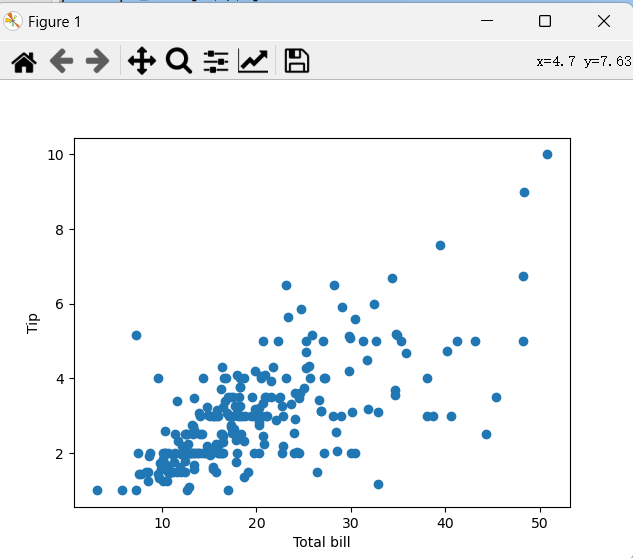
可以看出,小费金额似乎随着消费总额的增加而变大,这表明小费金额和消费总额存在一定程度的正相关关系,但不是非常强烈的正相关关系。
6分析男女顾客哪个更慷慨,就是分组看看男性还是女性的小费平均水平更高
# 导入数据并计算男女顾客的小费平均值
gender_tip_mean = tips_data.groupby('性别')['小费'].mean()
print(gender_tip_mean)
可以看出,在这个数据集中,男性顾客的小费平均水平略高于女性顾客。因此,从这份数据来看,男性顾客可能更慷慨一些。
7.分析日期和小费的关系,请绘制直方图。
# 导入数据并绘制直方图
grouped = tips_data.groupby('星期')['小费']
hist_data = [grouped.get_group(day) for day in grouped.groups]
plt.hist(hist_data, bins=10, histtype='bar', stacked=True)
plt.legend(grouped.groups.keys())
plt.xlabel('Tip amount')
plt.ylabel('Frequency')
plt.show() 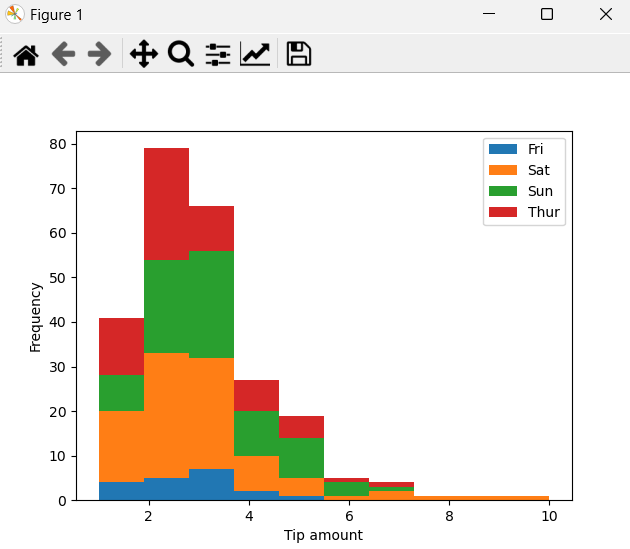
8、绘图分析性别+抽烟的组合对慷慨度的影响
# 导入数据并绘制箱线图
fig, ax = plt.subplots()
ax.boxplot([tips_data[tips_data['性别']=='Male'][tips_data['是否抽烟']=='Yes']['小费'],
tips_data[tips_data['性别']=='Male'][tips_data['是否抽烟']=='No']['小费'],
tips_data[tips_data['性别']=='Female'][tips_data['是否抽烟']=='Yes']['小费'],
tips_data[tips_data['性别']=='Female'][tips_data['是否抽烟']=='No']['小费']],
labels=['Male smoker', 'Male non-smoker', 'Female smoker', 'Female non-smoker'])
plt.xlabel('Gender and smoking')
plt.ylabel('Tip amount')
plt.title('Effect of gender and smoking on tipping behavior')
plt.show()
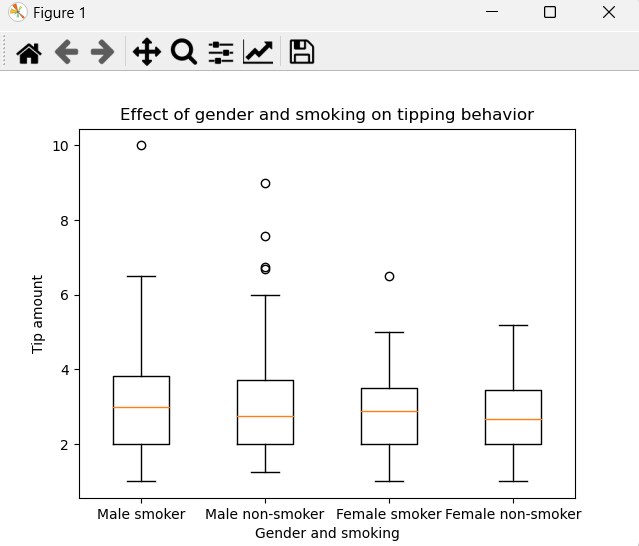
可以看出,男性吸烟者给出的小费位于所有组合中的最高水平,而女性非吸烟者给出的小费位于所有组合中的最低水平。因此,在这个数据集中,男性吸烟者可能更加慷慨,而女性非吸烟者可能不太慷慨。
9.绘图分析聚餐时间段与小费数额的关系
# 导入数据并绘制散点图
colors = ['blue', 'green', 'red', 'purple']
grouped = tips_data.groupby('聚餐时间段')
for i, (key, group) in enumerate(grouped):
plt.scatter(group['消费总额'], group['小费'], label=key, color=colors[i])
plt.xlabel('Total bill amount')
plt.ylabel('Tip amount')
plt.title('Relationship between meal time and tipping behavior')
plt.legend()
plt.show()
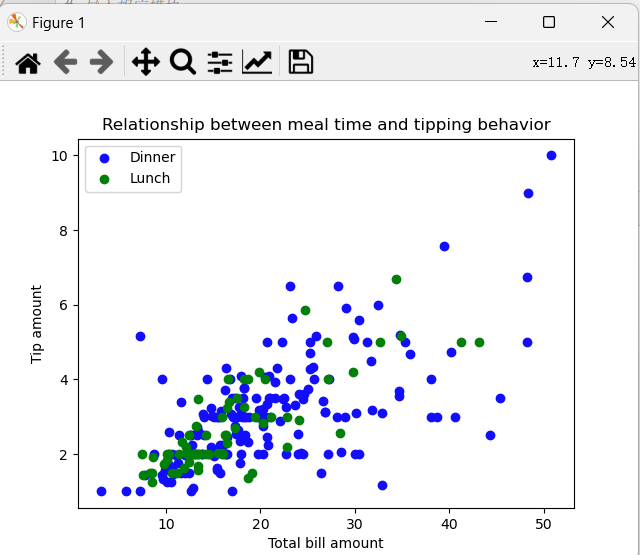
可以看出,午餐和晚餐的小费数额大致呈正相关,而早餐和夜宵的小费数额较为稀疏,无明显的相关性。因此,从这份数据来看,午餐和晚餐似乎更有可能得到较高的小费水平。
总结
这是一个数据分析和可视化的过程,其主要步骤如下:
导入所需的模块,包括Pandas和Matplotlib。
使用Pandas读取并处理数据集,包括修改列名、计算人均消费、查询特定条件下的数据等等。
利用Matplotlib绘制各种类型的图表,包括散点图、直方图、箱线图等等,从中发现顾客的一些特征与小费数额之间的关系。
对绘制的图表进行美化和定制,包括添加标签、标题、轴标签、图例等等。
考虑实际情况和边界条件,确保代码能够稳定、高效地工作。
这个过程涉及到多种数据分析和可视化技术,能够帮助我们更好地理解数据,发现其中的规律和趋势,为进一步的研究和决策提供参考。同时也需要注意数据质量和代码效率,避免出现意想不到的问题。
源代码下载:

















 4138
4138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











