






论文题目:OneRel: Joint Entity and Relation Extraction with One Module in One Step
论文来源:AAAI2022
论文链接:https://arxiv.org/pdf/2203.05412v2.pdf
代码链接:https://github.com/ssnvxia/OneRel
0 摘要
联合实体和关系提取是自然语言处理和知识图谱构建中的一项重要任务。现有的方法通常将联合提取任务分解为几个基本模块或处理步骤,以使其易于进行。然而,这样的范式忽略了一个事实,即三要素是相互依存和不可分割的。因此,以前的联合方法存在着连带错误和冗余信息的问题。为了解决这些问题,在本文中,我们提出了一个新的实体和关系联合提取模型,名为OneRel,它将联合提取作为一个细粒度的三重分类问题。具体来说,我们的模型由一个基于评分的分类器和一个针对关系的角标策略组成。前者评估一个token对和一个关系是否属于一个事实三元组。后者确保一个简单而有效的解码过程。在两个广泛使用的数据集上的广泛实验结果表明,所提出的方法比最先进的基线表现得更好,并在各种重叠模式和多个三元组的复杂场景中提供一致的性能增益。
1 引言
从非结构化文本中提取(head, relation, tail)或(h、r、t)形式的实体对及其关系是自然语言处理和知识图谱构建中的一项重要任务。传统的pipline方法将实体识别和关系分类视为两个独立的子任务。pipline方法虽然很灵活,但它忽略了两个子任务之间的相互作用,并且容易受到错误传播问题的影响。因此,最近的研究重点是建立联合模型,通过统一的体系结构获得实体及其关系。
为了使复杂的任务易于进行,现有的研究通常将联合提取分解为几个基本模块或处理步骤。如图1所示,根据三元组的提取过程,这些方法分为两类:多模块多步和多模块一步。
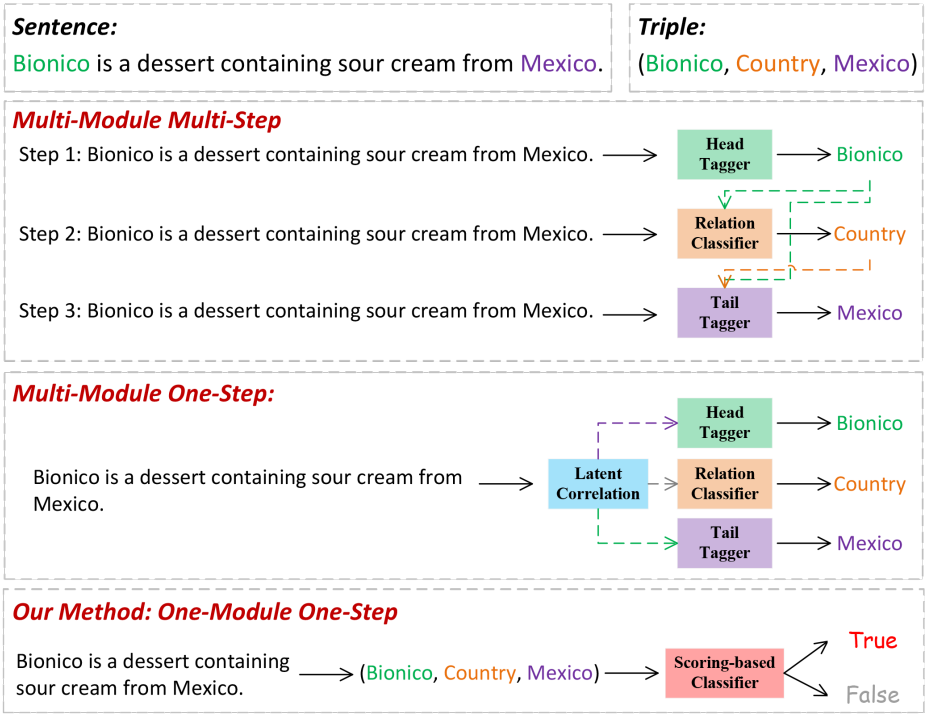
- 第一类是利用级联分类或文本生成框架中的不同模块来获取实体和关系。这种模型存在级联错误的问题,因为早期步骤中的错误可能会影响后续步骤的预测结果。
- 第二类试图分别识别实体和关系,然后根据它们的潜在相关性将它们组合成三元组。然而,由于在单独的识别过程中,实体之间和关系之间的相互约束不足,这些方法往往会产生冗余的信息,导致在组装三元组时出现错误。
事实上,造成上述问题的根本原因是,基于分解的范式忽略了三元组的一个重要属性--它的头实体、关系和尾实体是相互依赖和不可分割的。即,在不完全感知其他两个元素的信息的情况下,提取一个元素是不可靠的。为了填补这一空白,我们尝试从三元组分类的角度来完成联合提取任务。例如,如图1所示,“Bionico”和“Mexico”是句子中的两个单词,Country是一个预定义的关系,它们在训练数据中都可见。直观地说,这个三元组(Bionico,Country,Mexico)可以通过判断其正确性来直接识别。这个想法有以下三个优点。
- 首先,将头实体、关系实体和尾实体同时输入一个分类模块,从而能够充分捕获三元组元素之间的依赖关系,从而减少冗余信息。
- 其次,只采用一步分类,能够有效地避免级联错误。
- 第三,简单的单模块一步架构使网络直接和易于训练。
受上述思想的启发,本文提出了一种新的联合实体和关系提取模型OneRel,该模型能够一步内用一个模块从非结构化文本中提取所有三元组。考虑到一个实体可能由多个token组成,我们设计了一个基于评分的分类器,并将联合提取任务转换为一个细粒度的三元组分类问题。具体来说,对于标记对(wi、wj)和预定义的关系rk,基于评分的分类器度量组合(wi、rk、wj)的正确性,如果组合有效,将分配一个有意义的标记,否则为“-”。为此,对于一个输入句子,OneRel的输出是一个三维矩阵,每个条目对应于(wi、rk、wj)的分类结果。为了从输出矩阵中准确、有效地解码实体和关系,我们引入了一种新的关系特定角标记(简称Rel-Spec角标记)策略来确定头部实体和尾部实体的边界标记。在两个广泛使用的基准数据集上的实验结果表明,该方法优于以往的方法,并取得了最先进的性能。
综上所述,我们的贡献如下:
- 我们提供了一个新的视角,将联合提取转换为细粒度的三元组分类,使同时捕获头部实体、关系和尾部实体的信息成为可能。
- 根据我们的观点,我们引入了一种新的基于评分的分类器和Rel-spec角标记策略。前者负责并行标记,后者确保高效解码。
- 我们在两个公共数据集上评估了我们的模型,结果表明,我们的方法比最先进的基线性能更好,特别是对于重叠三元组的复杂场景。
2 相关工作
现有的联合方法根据其三元素的提取过程可大致分为两类:
第一类是多模块多步骤,它使用不同的模块和相互关联的处理步骤来串行地提取实体和关系。例如,首先识别一个句子中的所有实体,然后在每个实体对之间进行关系分类。然后检测一个句子所表达的关系,而不是保留所有的冗余关系;然后预测头部实体和尾部实体。最后,区分所有的头部实体,然后通过序列标记或回答问题回答来推断相应的关系和尾部实体。多模块多步骤方法虽然取得了成功,但仍存在级联错误的问题,因为早期步骤中的错误无法在以后的步骤中得到纠正。
第二类是多模块一步式,并行提取实体和关系,然后将它们组合成三元组。例如,将实体识别和关系分类视为一个表填充问题,其中每个条目表示两个单独单词之间的交互。 Sui et al. (2020)将联合提取任务表示为一个集合预测问题,避免考虑多个三元组的预测顺序。然而,由于在单独识别过程中实体与关系之间的相互约束不足,这种多模块一步式方法不能完全捕获预测实体与关系之间的依赖关系,导致在三元组构造过程中产生冗余信息。
与现有的方法不同,本文提出将联合提取任务作为一个细粒度的三重分类问题,它能够以单模块一步的方式从句子中提取三元组。因此,可以极大地解决上述的级联错误和冗余信息。此外,经典的模型新标记设计了一种复杂的标记策略来建立实体和关系之间的联系,还可以一步从句子中识别三元组。然而,这种技术不能处理重叠的情况,因为它假设每个实体对最多包含一个关系。
3 模型
在本节中,我们首先给出任务的定义和符号。然后,我们介绍了我们的边缘角标记策略及其解码算法。最后,我们提供了基于评分的分类器的详细形式化。
3.1 任务内容
给定一个句子![]() 与L标记和K预定义关系
与L标记和K预定义关系![]() 。联合实体和关系提取的目的是识别所有可能的三元组
。联合实体和关系提取的目的是识别所有可能的三元组![]() ,其中N是三元组的数量,
,其中N是三元组的数量,,
是由几个连续标记组成的头实体和尾实体。
![]() ,其中
,其中是指
与
的连接。请注意,不同的三元组可能共享重叠的实体,这给联合提取任务带来了很大的挑战.
3.2 关系特定的角标记(Relation Specifific Horns Tagging)
对于一个句子,我们设计了一个分类器来为所有可能的组合分配标签,其中
,
。我们维护一个三维矩阵
![]() 来存储分类结果(标记)。因此,在测试阶段,我们的任务是从矩阵M中解码实体和关系。
来存储分类结果(标记)。因此,在测试阶段,我们的任务是从矩阵M中解码实体和关系。
3.2.1 标记(Tagging)
我们使用“BIE”(Begin, Inside, End)符号来表示token在实体中的位置信息。例如,“HB”表示头部实体的开始token,“TE”表示尾部实体的结束token。如图2 (a)所示,对于一个表达三元组的句子(New York City, Located in, New York State),在关系特定的子矩阵的子矩阵中有9个特定的标签(蓝色标签)。
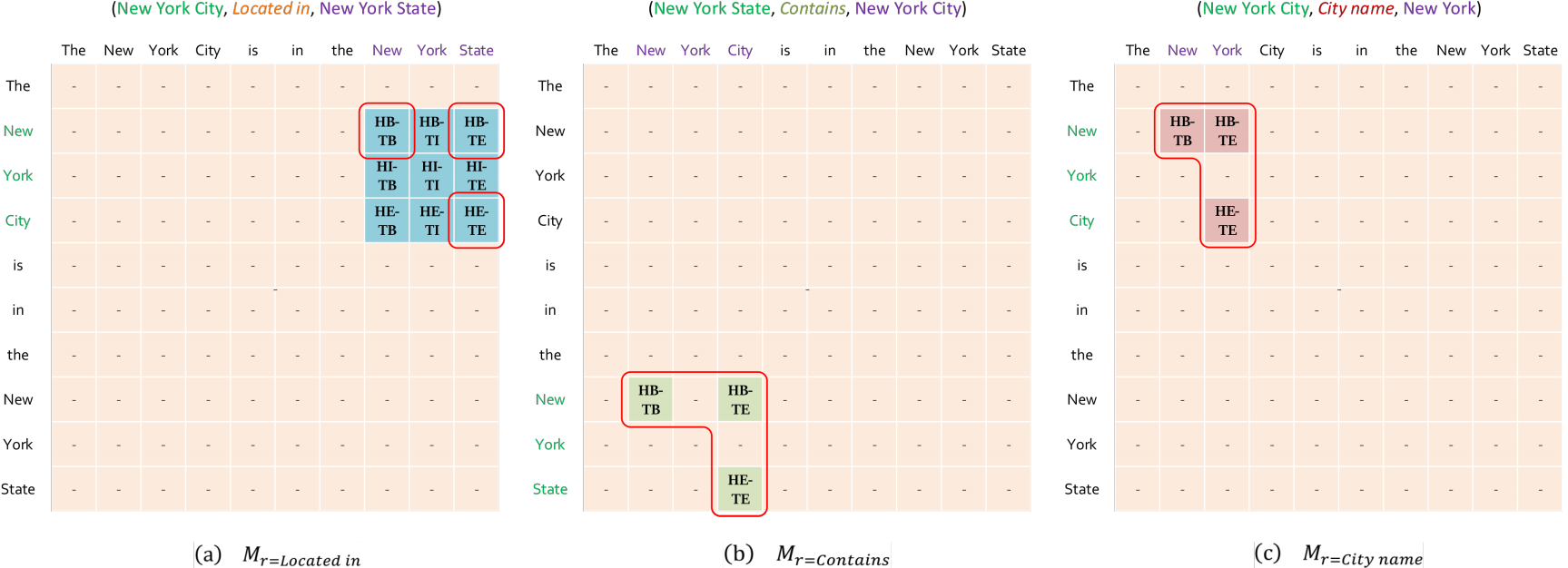
根据一个实体可以通过检测其边界标记来确定的见解,在我们的标记策略中使用了四种类型的标签:
- HB-TB:头实体开始token与尾实体开始token 进行连接。例如,在“New York City”和“New York State”两个实体之间存在一种关系,因此,组合的分类标签(“New”, Located in, “New”)被分配为“HB-TB”。
- HB-TE:头实体开始token与尾实体结束token 进行连接。例如,“New”是“New York City”的开始token,“State”是“New York State”的结束token,因此组合(“New”, Located in, “State”) 被指定为“HB-TE”。
- HE-TE:头实体结束token与尾实体结束token 进行连接。例如,(“City”, Located in, “State”) 被指定为“HE-TE”。
- - :不存在连接关系。从图2 (b)和(c)中我们可以看到,由于只需要对矩形的三个角进行标记,所以我们生动地将这种方法命名为Rel-Spec角标记。
显然,标记矩阵M是稀疏的,具有以下优点:首先,在进行分类时,使用3个标记而不是9个特殊标记可以有效地缩小潜在的搜索空间。其次,稀疏M表示在训练过程中存在足够的负样本。第三,M的稀疏性保证了三元解码的简单性和效率。
此外,我们的相对规范角标记可以自然地解决具有重叠模式的复杂场景。具体来说,对于实体对重叠(EPO)的情况,实体对将根据它们的关系在不同的子矩阵中进行标记。例如,在图2中,(a)和(b)(New York City, Located in, New York State) 和 (New York State, Contains, New York City)是两个EPO三元组,因此,这两个实体对分别标记在和
中。对于单实体重叠(SEO)场景,如果两个三元组包含相同的关系,则将两个实体对标记在
的不同部分,否则将根据它们的关系标记在不同的子矩阵中。对于最复杂的头尾重叠(HTO)模式,例如图2 (c)中的元组(New York City, City Name, New York),实体对(红色标签)位于
对角线附近,仍然可以很容易地解码。
3.2.2 解码(Decoding)
标签矩阵ML×K×L标志着成对的头实体和尾实体的边界标记,以及它们之间的关系。因此,从M中解码三元组变得简单和直接。也就是说,对于每个关系,头部实体的跨度从“HB-TE”拼接到“HE-TE”;尾部实体的跨度从“HBTB”拼接到“HB-TE”;两个成对的实体共享相同的“HB-TE”。
3.3 基于评分的分类器(Scoring-based Classififier )
对于输入句子,我们使用预先训练好的BERT作为句子编码器来捕获每个标记的二维标记嵌入ei:
![]()
其中,xi是每个token的输入表示。它是对相应的标记嵌入和位置嵌入的总和。然后,我们枚举所有可能的![]() 组合,并设计一个分类器来分配高置信度标签,其中rk是随机初始化的关系表示。直观地说,我们可以使用一个简单的分类网络,其输入为
组合,并设计一个分类器来分配高置信度标签,其中rk是随机初始化的关系表示。直观地说,我们可以使用一个简单的分类网络,其输入为![]() 来实现这个目标。然而,这种直觉有两个缺陷:一方面,一个简单的分类器不仅不能充分探索实体和关系之间的相互作用,而且很难对三元组的固有结构信息进行建模。另一方面,使用
来实现这个目标。然而,这种直觉有两个缺陷:一方面,一个简单的分类器不仅不能充分探索实体和关系之间的相互作用,而且很难对三元组的固有结构信息进行建模。另一方面,使用![]() 作为输入意味着模型至少需要进行L×K×L计算来对所有组合进行分类,这在时间上是不可接受的。
作为输入意味着模型至少需要进行L×K×L计算来对所有组合进行分类,这在时间上是不可接受的。
受知识图谱嵌入技术的启发,我们借鉴了HOLE的思想,其分数函数定义为:
![]()
其中h,t分别是头表示和尾表示。* 指循环相关,用于挖掘两个实体之间的潜在依赖关系。在这里,我们重新定义了这个问题 * 作为非线性连接投影:
![]()
其中,![]() ,b为可训练的权重和偏差,de表示实体对表示的维数。[;]是连接操作,φ(·)是ReLU激活函数。新的定义带来了以下好处:首先,我们的分类器的得分函数可以与句子编码器的输出无缝连接。其次,通过矩阵W可以自适应地学习从实体特征到实体对表示的映射函数。第三,两个实体之间的连接不是可交换的,即
,b为可训练的权重和偏差,de表示实体对表示的维数。[;]是连接操作,φ(·)是ReLU激活函数。新的定义带来了以下好处:首先,我们的分类器的得分函数可以与句子编码器的输出无缝连接。其次,通过矩阵W可以自适应地学习从实体特征到实体对表示的映射函数。第三,两个实体之间的连接不是可交换的,即,这对于建模非对称关系是不可或缺的。
接下来,我们使用所有关系表示![]() 同时计算一个标记对(wi,wj)的
同时计算一个标记对(wi,wj)的![]() 的显著性,其中4是分类标签的数量。因此,我们的方法的最终评分函数定义为:
的显著性,其中4是分类标签的数量。因此,我们的方法的最终评分函数定义为:
![]()
其中v为得分向量,drop(·)表示用于防止过拟合的退出策略。 因此,我们只用两层全连接网络就实现了并行评分(矩阵R也可视为可训练的权重),并将实际执行的处理步骤减少到L×1×L,甚至优于TPLinker。此外,评分函数符合HOLE的思想,能够捕获各项关系之间的相关性和互斥性,这将在实验中得到验证。
最后,我们将(wi、rk、wj)的分数向量输入一个softmax函数,以预测相应的标签:
![]()
OneRel的目标函数定义为:
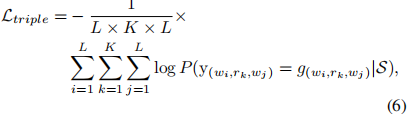
其中,g(wi、rk、wj)表示从注释中获得的gold tag。
4 实验
在本节中,我们进行了广泛的实验来验证所提出的OneRel的有效性,并分析了其性质。
4.1 实验设置
4.1.1数据集和评估指标
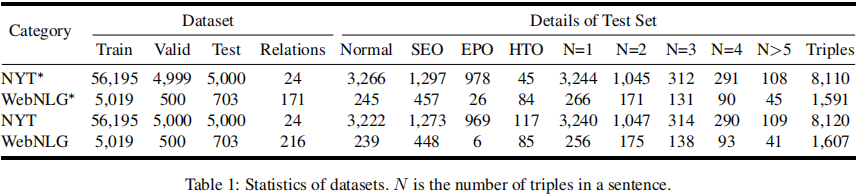
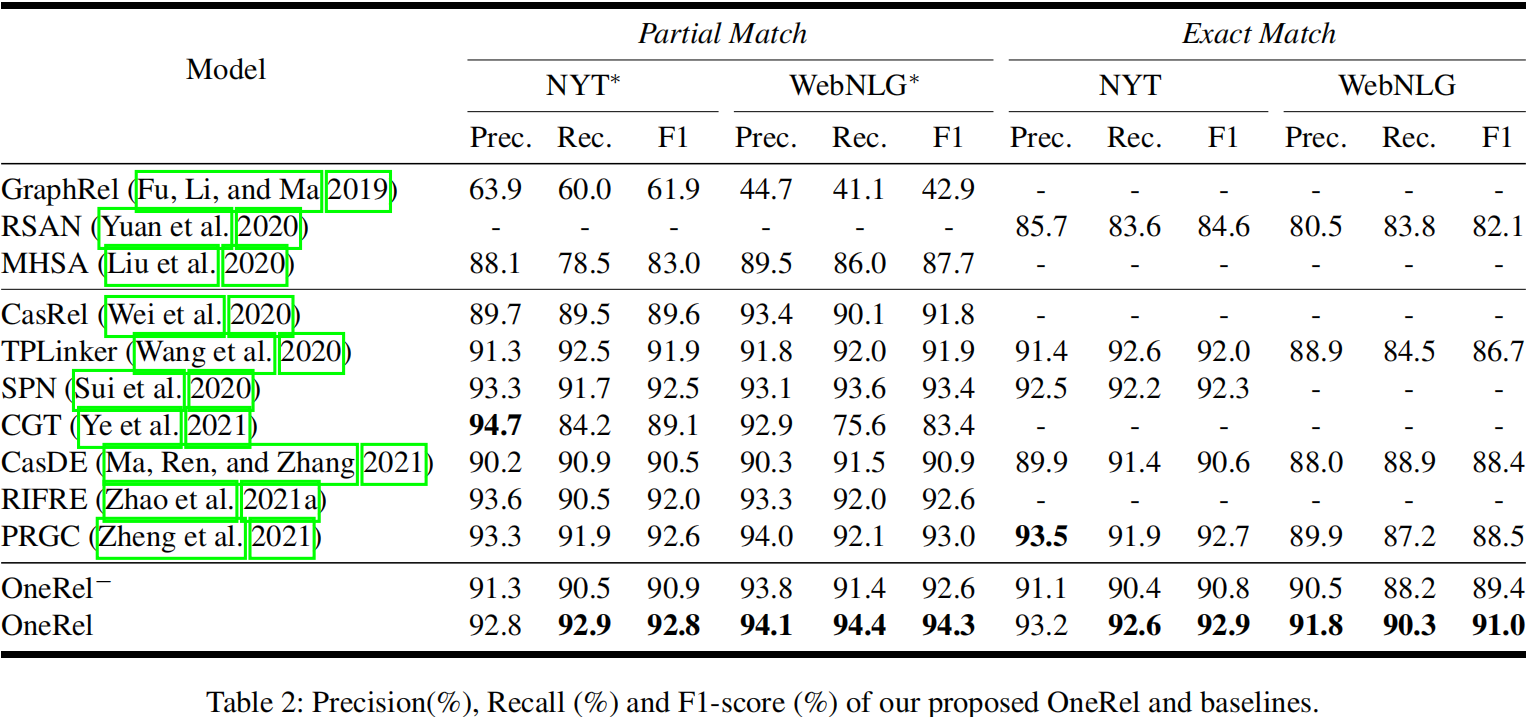
根据之前的工作,我们在两个广泛使用的数据集上评估我们的模型和所有基线:NYT和WebNLG。前者是用于远距离监督关系的提取。后者最初是为自然语言生成(NLG)而创建的。NYT和WebNLG都有两个版本:一个版本只注释实体的最后一个字,而另一个版本只注释实体的整个跨度。我们将第一个版本的数据集表示为NYT∗和WebNLG∗,将第二个版本表示为NYT和WebNLG。为了进一步研究所提出的OneRel处理复杂场景的能力,我们将重叠模式和三重数分割测试集。表1描述了这两个数据集的详细统计数据表。
在我们的实验中使用了三个标准的评价指标,即精度(Prec.),Recall (Rec.) 和F1分数(F1)。在评估过程中,我们对NYT∗和WebNLG∗采用部分匹配:只有当关系和头尾字都正确时,才认为提取的三元组(head, relation, tail)是正确的;对NYT和WebNLG使用精确匹配:只有当两个实体和关系的整个跨度都完全匹配时,预测的三元组才被认为是正确的。
4.1.2 实施细节
在我们的实验中,所有的训练过程都是在一个工作站上完成的,该工作站有一个AMD 7742 2.25G CPU,256G内存,一个RTX 3090 GPU和Ubuntu 20.04。对于预训练的BERT,我们重新使用由Huggingface发布的基础案例英语模型,其中包含12个Transformer块,隐藏大小d为768。我们在有效集合上调整我们的模型,并使用网格搜索来调整重要的超参数。具体来说,在NYT/WebNLG上,批次大小被设置为8/6,所有的参数都由亚当算法优化,学习率为1e-5。隐层de维度被设置为3×d,方程(4)中的dropout为0.1,最大序列长度被设置为100。
4.1.3 baselines
GraphRel (Fu, Li, and Ma 2019)RSAN (Yuan et al. 2020)MHSA (Liu et al. 2020)CasRel (Wei et al. 2020)TPLinker (Wang et al. 2020)SPN (Sui et al. 2020)CGT (Ye et al. 2021)CasDE (Ma, Ren, and Zhang 2021)RIFRE (Zhao et al. 2021a)PRGC (Zheng et al. 2021)
请注意,在GraphRel、RSAN和MHSA中使用的句子编码器是LSTM网络,而其他基线使用预训练过的BERT来获得特征表示。为了进行公平的比较,所有基线的报告结果都直接来自原始文献。我们还进行了消融测试:OneRel−是用![]() 替代其分类器的模型。
替代其分类器的模型。
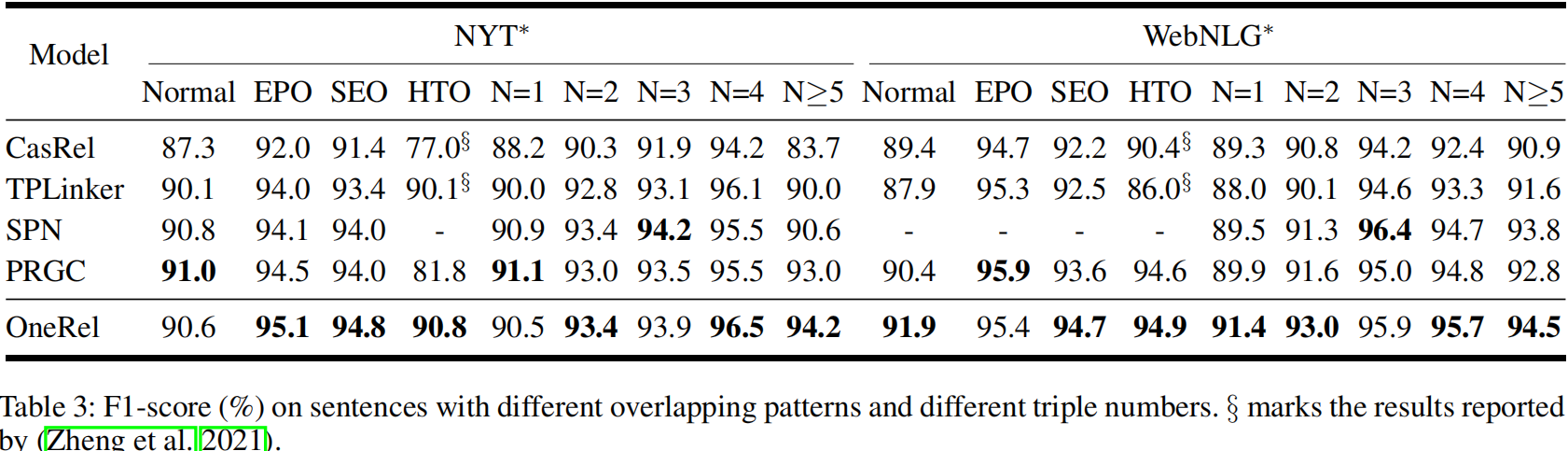
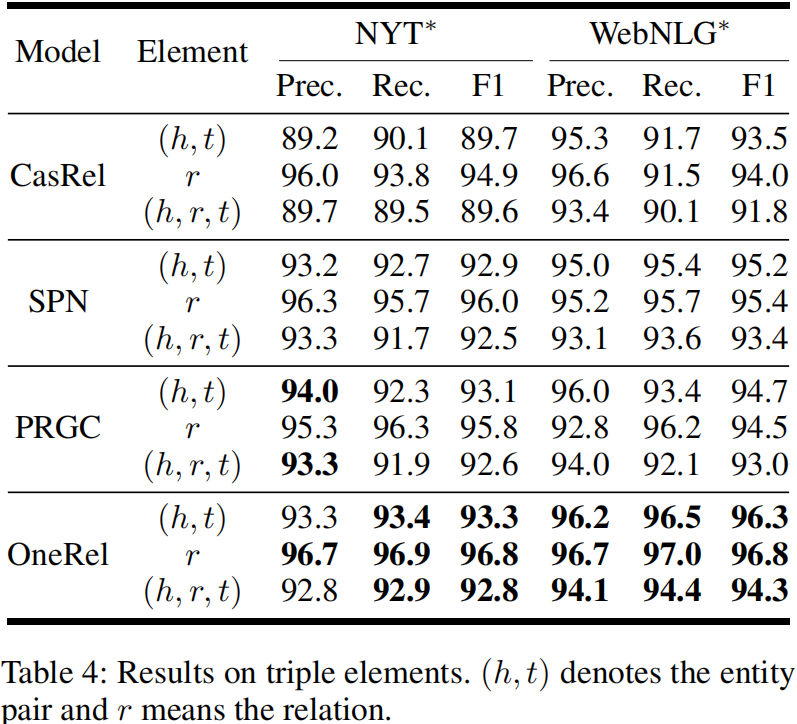
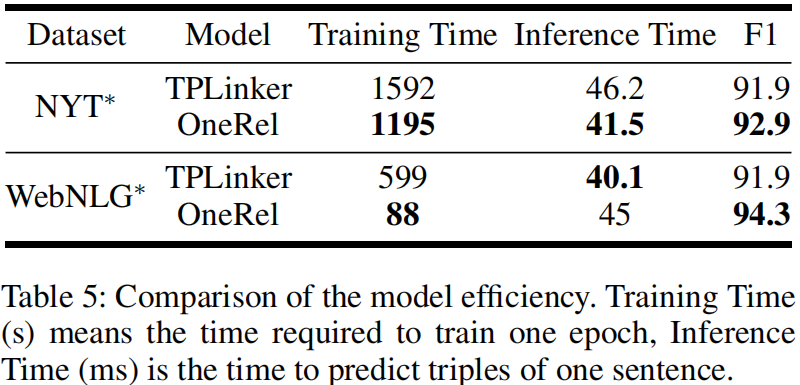
4.2 结果与分析
5 结论
在本文中,我们提供了一个新的角度将联合提取任务转换为一个细粒度三元组分类问题,并提出一个新的联合模型基于评分分类器和Rel-Spec角标记策略获得三元组一步一个模块,这大大减轻了级联错误和冗余信息的问题。在公共数据集上的实验表明,我们的模型在不同场景下的性能优于最先进的方法。
今后,我们将探讨以下发展方向:
- 为了提高模型的效率,我们设计了一个简化版本的HOLE作为分数函数。接下来,我们将尝试设计一个更有效和更强大的评分函数,以进一步加强其捕获实体和关系之间的联系的能力。
- 我们想在其他信息提取问题中探索三元组分类的想法,如事件抽取。

















 3039
3039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









