







 本文介绍了如何通过查找网页开发者使用的字体文件,利用FontCreator分析XML文件中的cmap映射,使用Python库fontTools解析字体,实现对包含字体反爬技术的网页内容进行解码,以获取实际的文本信息。
本文介绍了如何通过查找网页开发者使用的字体文件,利用FontCreator分析XML文件中的cmap映射,使用Python库fontTools解析字体,实现对包含字体反爬技术的网页内容进行解码,以获取实际的文本信息。
目录
4 使用python的第三方库fontTools读取字体文件
5 观察xml文件里面的cmap映射关系以及FontCreator得出规律并替换源码
1 什么是字体反爬
网页开发者自己创造一种字体,因为在字体中每个文字都有其代号,那么以后在网页中不会直接显示这个文字的最终的效果,而是显示他的代号,因此即使获取到了网页中的文本内容,也只是获取到文字的代号,而不是文字本身。
简单的说,字体反爬指的就是浏览器页面上的字符和调试窗口或者源码中的内容,显示的不一样,这就是字体反爬。

![]()
2 如何找到网页开发者创造的字体
(1)直接源码搜索@font-face
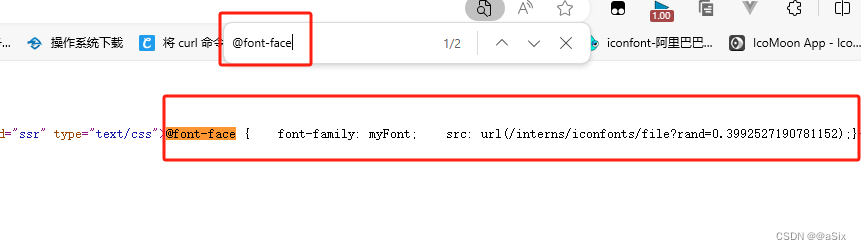
(2)打开调试窗口,点击要获取的数据,查看css引用的字体,去源码搜索

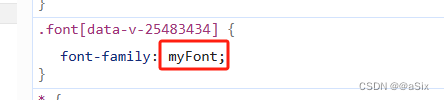
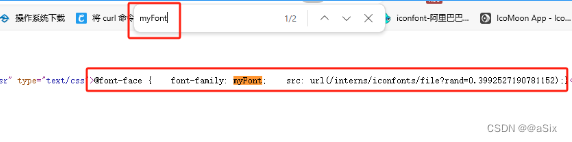
(3)抓包获取获取字体文件请求的接口
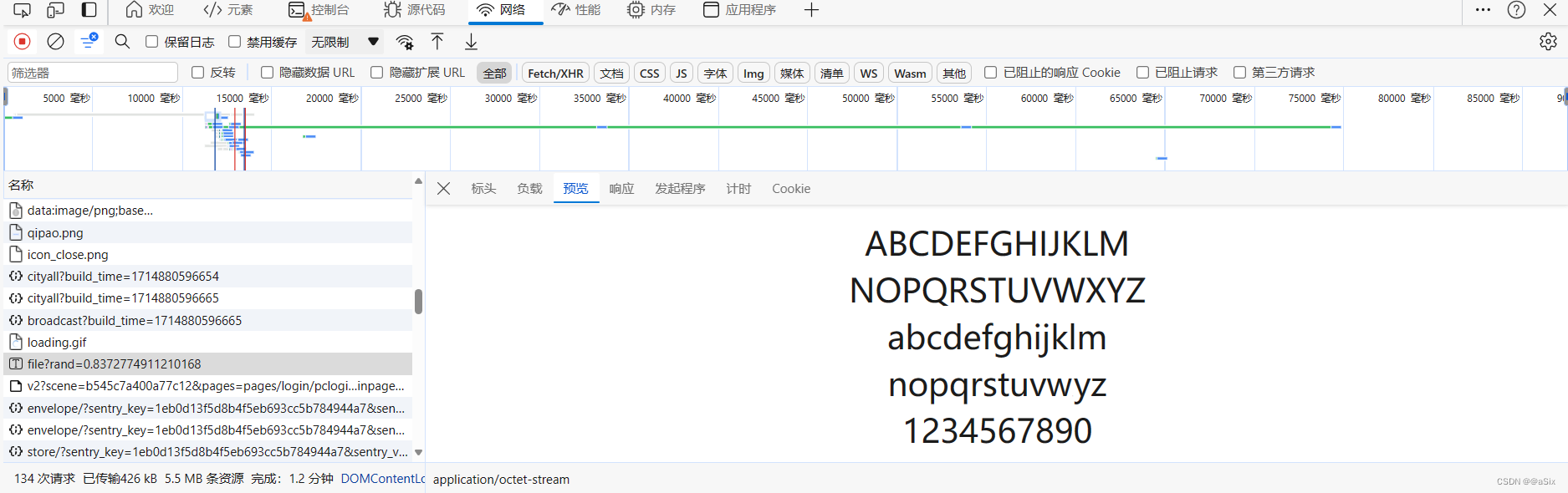
3 使用FontCreator查看字体文件

4 使用python的第三方库fontTools读取字体文件
使用pip install fontTools安装fontTools库
from fontTools.ttLib import TTFont
# TTFont()用来打开woff文件的
font = TTFont('font.woff')
# 使用save()将拿到的文件数据保存为XML格式的文件
font.saveXML('font.xml')
5 观察xml文件里面的cmap映射关系以及FontCreator得出规律并替换源码
font = open('font.xml','r').read()
cmap = re.findall('<map code="(.*?)" name="(.*?)"/>', font)
result = {}
for item in cmap:
if item[1] == 'x':
continue
result['&#'+item[0][1:]] = chr(eval('0x'+item[1][3:]))
# 目标url
url = 'https://www.shixiseng.com/interns?keyword=python&city=%E5%85%A8%E5%9B%BD&type=intern'
res = requests.get(url,headers=headers).text
# 替换响应回来的html源码
for item in result:
res = res.replace(item,result[item])
6 实习僧案例完整代码
import requests
import re
from bs4 import BeautifulSoup
from fontTools.ttLib import TTFont
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
# 找到字体的文件或者url发起请求
url = 'https://www.shixiseng.com/interns/iconfonts/file?rand=0.3992527190781152'
font_res = requests.get(url, headers=headers)
with open('font.woff', 'wb') as fp:
fp.write(font_res.content)
# TTFont() 用来打开woff文件的
font = TTFont('font.woff')
# 使用save()将拿到的文件数据保存为XML格式的文件
font.saveXML('font.xml')
# 使用FontCreator打开文件以及观察xml里面的cmap映射规则得出规律
font = open('font.xml', 'r').read()
cmap = re.findall('<map code="(.*?)" name="(.*?)"/>', font)
result = {}
for item in cmap:
if item[1] == 'x':
continue
result['&#' + item[0][1:]] = chr(eval('0x' + item[1][3:]))
# 目标url
url = 'https://www.shixiseng.com/interns?keyword=python&city=%E5%85%A8%E5%9B%BD&type=intern'
res = requests.get(url, headers=headers).text
# 替换响应回来的html源码
for item in result:
res = res.replace(item, result[item])
bs4 = BeautifulSoup(res, 'html.parser')
offers = bs4.select('.intern-wrap.interns-point.intern-item')
for offer in offers:
title = offer.select('.f-l.intern-detail__job p a')[0].text
company = offer.select('.f-r.intern-detail__company p a')[0].text
job_money = offer.select('.f-l.intern-detail__job p .day.font')[0].text
print(title, company, job_money)














 2802
2802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









