






摘要
本文简单介绍 HTML 文档结构,讲解爬虫原理,并以同济新闻网为例,借助 Jsoup 库,爬取网站上的新闻,并按一定格式存储到文件。
本文制作的爬虫采用多线程设计,性能较单线程爬虫有显著提升。代码使用 Kotlin 语言编写。
需求分析
想要对一个网站进行爬取,首先肯定需要知道自己想要什么。
本例中,我们希望爬取同济新闻网的尽量多的新闻数据,基于爬取到的内容对其构造搜索引擎。因此,我们的目标很明确:从同济新闻网首页进入,探索每一个可以点开的链接。如果探索到的页面是新闻页面,就将其内容提取并存储到文件。
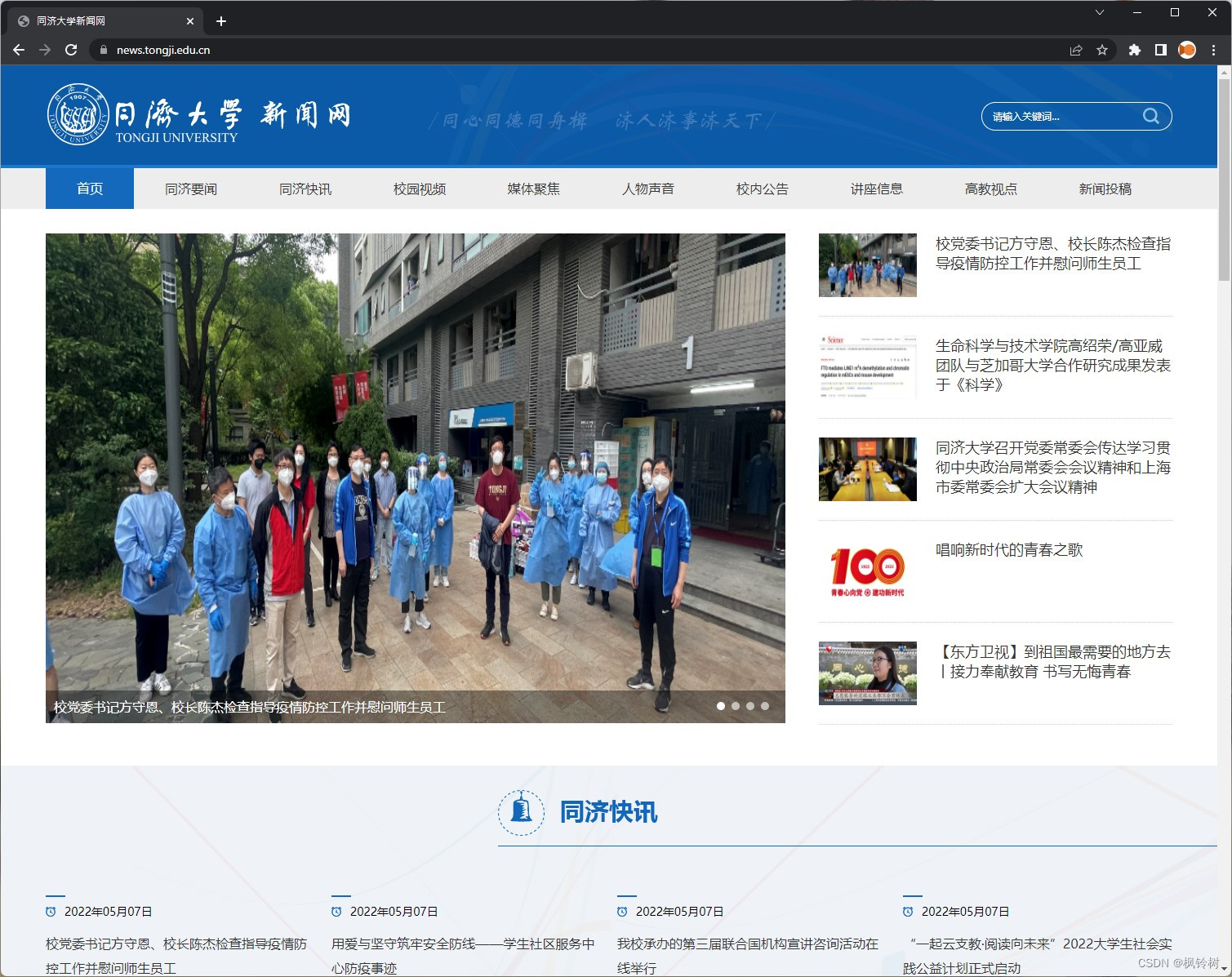
上图为同济新闻网首页。
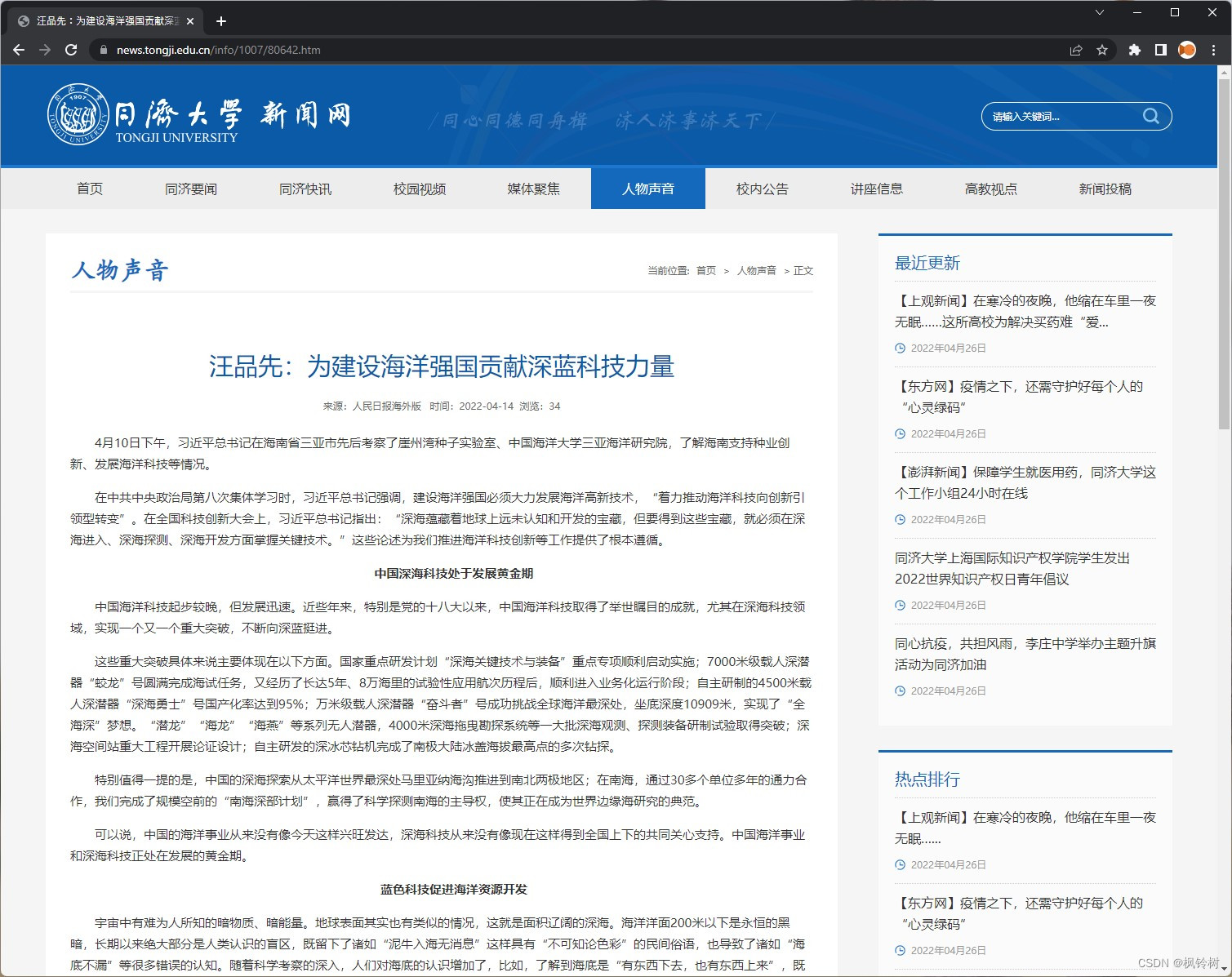
上图为一条新闻。这正是我们需要的内容。
语言、平台、库
正如标题所说,我们开发的爬虫运行于 JVM 平台。本文的爬虫使用 Kotlin 语言开发。由于 Kotlin 和 Java 有很高的兼容性,你可以很轻松地把它转换成 Java 代码。
众所周知,每个网页都是一个 HTML 文档。我们需要一个好用的分析工具来从中提取信息。此处,我们采用 Jsoup 完成 HTML 文档分析。
由于我们的爬虫采用多线程设计,对很多关键变量的访问需要用锁保护(啥意思?如果我们有一个变量 a a a,表示已爬取的网页数。如果两个线程同时对 a a a 执行 + 1 +1 +1 的操作, a a a 有可能变成 a + 1 a+1 a+1,而不是我们预期的 a + 2 a+2 a+2)。对此,我们使用 Kotlinx Coroutines 库中的互斥锁和信号量满足相关需求。
在 pom.xml 文件中添加这两个库:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jetbrains.kotlinx/kotlinx-coroutines-core -->
<dependency>
<groupId>org.jetbrains.kotlinx</groupId>
<artifactId>kotlinx-coroutines-core</artifactId>
<version>1.6.1</version>
<type>pom</type>
</dependency>
注意,version 可以和我的不一样。我设置的版本是截至发文时的最新版。
爬虫原理
如果你没有做过爬虫,最好看一看这部分。
HTML 文档
首先,网页是由 HTML 文档组成的。HTML 文档清晰地描述了网页上每个元素的位置,以及某些元素关联的链接。
例如,当我们点击一个按钮时,它将我们导向另一个网页。那么,我们一般可以从 HTML 文档中直接找到对应的网址。
下面以谷歌首页为例,展示该页面的 HTML 文档结构。

打开谷歌首页,按下 F12 进入浏览器开发者工具,可以看到网页源代码:
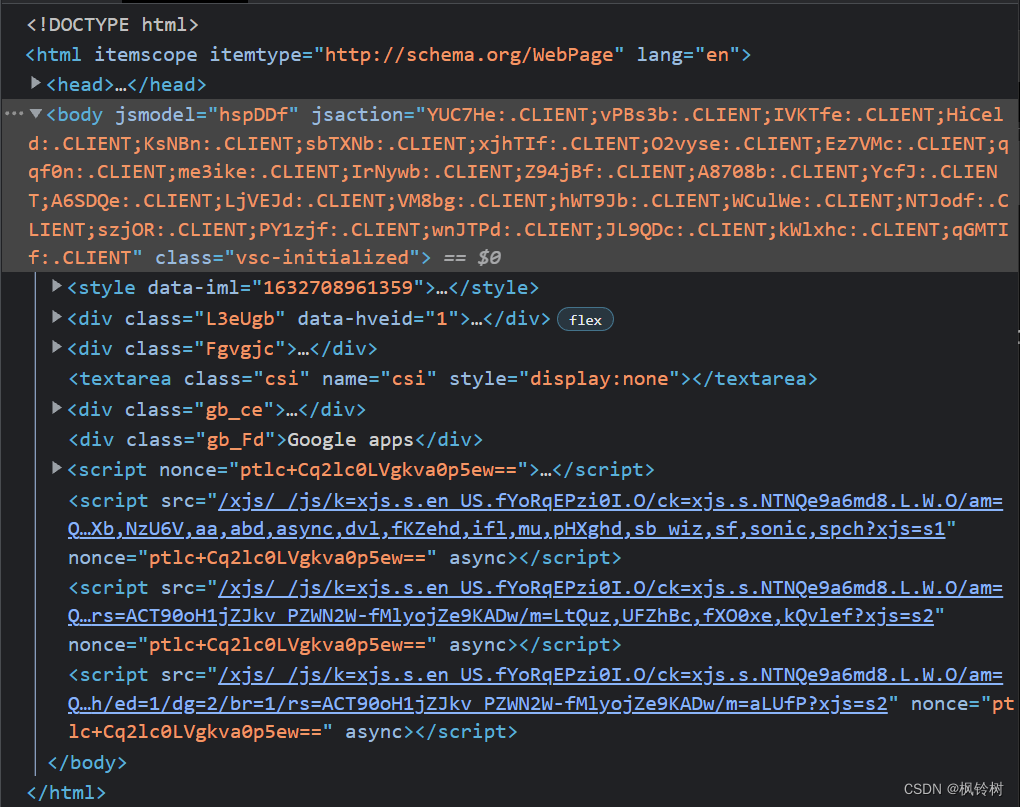
其中,网页页面在 body 标签下的第一个 div 内。展开,得到如下图所示:
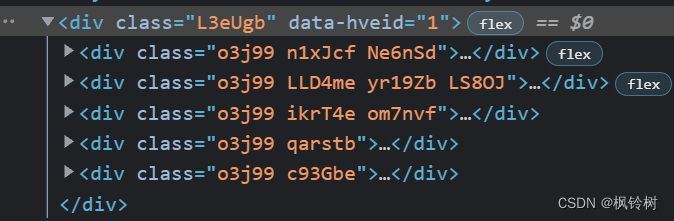
可看出页面结构如下:
用类似方式分析,可以得到谷歌的网页结构如下:
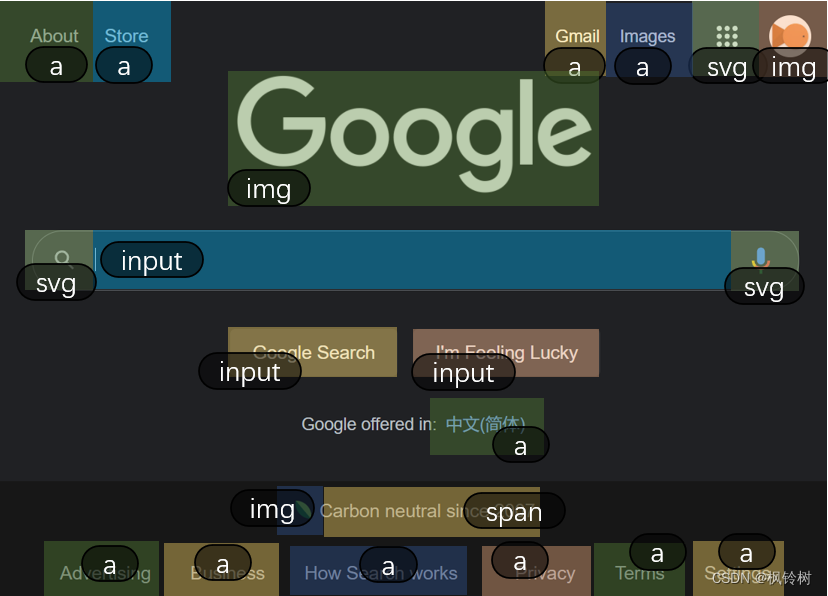
相信这些知识你已经掌握了。制作爬虫需要基于这些知识。
(呜呜呜如果你没有掌握的话还是去补一补为好。相信我,这些不难的)
人工爬虫
如果我们用人手来手动抓取新闻页的内容,应该怎么做?
首先,打开首页。之后,点击每一个我们能看到的链接。
对于新进入的页面,如果它对应的是条新闻,则记录其内容。
对于新页面上的所有可点链接,我们把它记下来,后续访问。
对于一个链接,如果我们已经访问过,就不要再访问了。
真的爬虫
我们只需要让电脑模拟这个过程就行。首先,通过网络请求获得新闻网首页的 HTML 文档。当然,我们不会将 HTML 文档呈现到页面上,而是直接分析其中的内容。
对于上述“点击链接”,不难发现,网页跳转链接一般设在元素标签的 href 值。因此,只需要获取所有元素的 href 值即可得到该网页上的所有链接。
如何识别一个页面是新闻页?由于我们针对同济新闻网做爬虫,简单浏览即可发现,当网页链接以 https://news.tongji.edu.cn/info/ 开头时,这个页面一定是新闻页。将其中内容取出即可。
我们采用广度优先搜索进行爬取,因此我们需要一个队列存储探索到的链接。每当我们爬取一个页面时,将探索到的所有链接放到队列尾部。分析完毕,从队列开头获取新的链接进行分析。
如何去重?我们可以在添加链接前,看一下这个链接是否在列表里。如果在,则不添加。但是这样需要对列表里的所有元素进行扫描。
我们可以用哈希集合来存储所有访问过的链接。添加链接时,检查一下这个链接是否在哈希集合内出现即可。由于哈希集合底层采用红黑树实现,可以提供非常好的性能。(想学习红黑树?看这里:红黑树详解)
多线程爬虫原理
多线程爬虫基于上述爬虫原理,只是引入更多爬取线程,并解决一些由于引入线程造成的问题。
为什么要多线程
不难发现,我们的爬虫涉及网络请求。在进行网络请求时,它无法进行页面分析(页面都没下下来呢,分析?),只能等待。因此,爬虫的很多时间消耗在等待网页反应。
对此,我们可以设计多个线程,大家交替请求,交替处理。虽然每个线程依旧需要等待网页响应,但是当这个线程等待时,那个线程在处理。另外,几个线程同时拿到自己的网页数据,同时处理完成,同一时间分析出的网页数也更多。
互斥变量和容器
首先,我们知道,两个线程同时对一个变量或容器进行修改时,可能会出现问题。因此,我们需要对关键内容做保护,要求同一时刻只能有至多一个线程在操作它们。
首先,对待爬取列表和前述哈希集合的读写显然是需要做互斥处理的。另外,我们需要统计当前已经爬取了多少个页面。这个变量也不允许多个线程同时修改。最后,我们每爬完一个页面,需要进行一次写文件。这个过程同一时刻也只能有一个线程在操作。
信号
你以为上面说的足够了?No!
如果我们用10个线程爬取100个页面,目前已爬取10个,有9个线程刚处理完手头的页面,有1个线程还在分析当前页面。此时,队列中已经没有待爬取链接了。那9个线程需要停下来,等待正在工作的线程找到新链接,然后开始处理。
学过操作系统的小伙伴一下就想到,这是个类似生产者消费者问题的情形。我们需要一个信号量完成这里的通信。信号量的值表示待爬取队列中的链接数量。
此外,10个线程有条不紊地工作,那么主线程呢?主线程此时正在等待10个线程的工作。因此,需要额外增加一个信号量,用于告知主线程已经完成100个页面的爬取这件事。
工具准备
为方便爬虫主要部分开发,我们需要制作一些小工具。
写文件工具
我们的文件可能是写入到本地,也可能写入到诸如 HDFS,也可能是 socket。因此,我们设计一个写文件工具。爬虫本体只需要调用工具提供的方法即可,并不需要关心文件具体在哪里。此外,工具内完成互斥保护。
/**
* 网页信息文件写入工具。
*/
private class PageFileWriter(filepath: String) {
private val file: File
private val fileMutex = Mutex()
private var printWriter: PrintWriter? = null
init {
file = File(filepath)
}
fun prepare() = apply {
if (printWriter == null) {
printWriter = file.printWriter()
}
}
fun close() {
printWriter?.close()
printWriter = null
}
fun writeLine(line: String, divider: String? = "\n") = runBlocking {
fileMutex.withLock {
printWriter?.write(line)
if (divider != null) {
printWriter?.write(divider)
}
printWriter?.flush() // 虽然看似可以不要,但如果爬虫半路卡住了,用它可以保证已爬取数据全都写入文件。
}
}
}
如上所示。爬虫主程序只需要在开始时构建文件写入器对象,并进行 prepare,结束前调用 close,当需要写入时通过 writeLine 完成。
代码十分简单,不再多解释。
链接仓库
前文已经提到,对于链接,我们需要一个队列和一个哈希集合。我们不如把它们合并在一起,制作一个类,在类内解决互斥的问题。
private class LinkStore {
/** 读写锁。 */
private val operationMutex = Mutex()
/** 待爬取链接。 */
private val linkQueue = ArrayList<String>()
/** 已探索链接。 */
private val linkDiscovered = HashSet<String>()
fun put(link: String) = runBlocking {
operationMutex.withLock {
if (!linkDiscovered.contains(link)) {
linkQueue.add(link)
linkDiscovered.add(link)
}
}
}
fun get(): String? = runBlocking {
val ret: String?
operationMutex.withLock {
ret = linkQueue.removeFirstOrNull()
}
return@runBlocking ret
}
}
同样十分简单。
链接处理工具
链接处理?处理什么?
首先,网页元素的 href 值可能是相对链接。我们需要将其与其父级链接做拼接。例如:
当前页面:https://news.tongji.edu.cn/somedir1/subpage2
href 值: /subpage3
拼接结果:https://news.tongji.edu.cn/somedir1/subpage3
此外,href 值可能涉及 “…/”,这是很麻烦的,我们需要处理好。
另外,我们可以把“页面是否是新闻页面”这个判断放到链接处理工具内。
综上,我们制作链接处理工具如下:
/**
* 链接处理工具。
*/
private class LinkProcessor {
companion object {
/**
* 链接是否指向新闻页面。
*/
fun String.isNewsPage(): Boolean {
return this.startsWith("https://news.tongji.edu.cn/info/")
}
/**
* 合并双斜线。将 // 转换为 / (https:// 除外)。
*/
fun String.mergeDoubleSlashes(): String {
return this.replace("//", "/").replace("https:/", "https://")
}
/**
* 拼接链接。
* 如:https://tongji.edu.cn + info -> https://tongji.edu.cn/info
*
* 拼接过程会自动处理 ./ 和 ../ 这种怪怪的东西。
*/
fun String.concatUrl(url: String): String {
val parentSegments = this.substring("https://".length, this.length).split("/")
val parentBuilder = StringBuilder("https://")
var siteRootAttached = false
if (parentSegments.size == 1) { // 只有 news.tongji.edu.cn 一个元素
parentBuilder.append(parentSegments[0])
} else {
parentSegments.forEach { seg ->
if (seg == parentSegments.last()) {
return@forEach // 跳出后,循环会因到达结尾而结束。
} else if (!siteRootAttached) {
parentBuilder.append(seg)
siteRootAttached = true
} else {
parentBuilder.append("/$seg")
}
}
}
val realParent = parentBuilder.toString()
var pureUrl = "$realParent/$url".mergeDoubleSlashes()
pureUrl = pureUrl.substring("https://".length, pureUrl.length)
val sourceUrlSegments = pureUrl.split("/")
val resultUrlSegments = ArrayList<String>()
sourceUrlSegments.forEach { segment ->
if (segment == ".") {
return@forEach
} else if (segment == "..") {
if (resultUrlSegments.isNotEmpty()) {
resultUrlSegments.removeLast()
}
} else {
resultUrlSegments.add(segment)
}
}
val resultBuilder = StringBuilder("https://")
siteRootAttached = false
resultUrlSegments.forEach { seg ->
if (seg.isBlank()) {
return@forEach
} else if (!siteRootAttached) {
resultBuilder.append(seg)
siteRootAttached = true
} else {
resultBuilder.append("/$seg")
}
}
return resultBuilder.toString()
} // fun String.concatUrl(url: String): String
} // companion object
} // private class LinkProcessor
新闻信息数据类
我们设计一个数据类,用来描述一条新闻的信息,并在类内实现转字符串的方法。
/**
* 新闻信息。
*/
private data class NewsData(
var url: String = "",
var source: String = "",
var date: String = "",
var title: String = "",
var content: String = ""
) {
companion object {
private const val DIVIDER = MacroDefines.NEWS_DATA_DIVIDER
}
override fun toString(): String {
return "$url$DIVIDER$source$DIVIDER$date$DIVIDER$title$DIVIDER$content"
}
}
你可能好奇,这个 DIVIDER 是什么,为什么生成的字符串这么奇怪。
首先说明,本文举例的爬虫是同济课程《云计算与虚拟化技术》一次大作业的组成部分。该大作业需要对爬取结果做进一步分析。
我们希望,爬虫爬出的文件内,每行代表一条新闻信息,其中包含链接地址、新闻来源、新闻标题、发布时间及新闻内容信息。我们将这些信息并排排布,并用 \u0007 来分隔。后续程序将每行根据 \u0007 切分开,即可得到该新闻的所有信息。
至此,工具准备完毕,开始编写爬虫主程序。
爬虫主程序
首先,我们设置一些参数。
爬虫参数
/** 爬虫目标网页根路径。同样为进入点。 */
private const val SPIDER_WEB_ROOT = "https://news.tongji.edu.cn"
/** 并行爬虫线程数。 */
private const val THREAD_COUNT = 9 // io密集型程序一般设为 核心数×2+1.
/** 需要爬取的新闻数量。 */
private const val TARGET_NEWS_COUNT = 20000 // 这个数写死下来不太好,但懒得改了。
如果你能把第三个参数做成命令行控制,当然更好。
多线程工作流程设计及基本变量设计
主线程创建多个子线程,子线程爬取网页数据。之后,主线程停下来等待已爬取网页数达到预期。
对于子线程,我们需要让它主动结束。然而,有可能结束的不是那么及时。因此,主线程需要等待每一个子线程退出,然后关闭文件写入工具,之后整个程序结束。
对此,我们设计如下流程:
/**
* 程序进入点。
*/
@JvmStatic
fun main(args: Array<String>) {
/** 爬虫线程队列。 */
val threads = ArrayList<Thread>()
/** 文件写入器。创建后立即准备。 */
val fileWriter = PageFileWriter("./result.txt").prepare() // 输出目标不宜写死。但懒得改了...
/** 链接管理器。 */
val linkStore = LinkStore()
/** 已爬取的新闻数(所谓“已爬取”,实际是从拿到链接就算)。 */
val newsFetchedCounter = AtomicInteger()
/** 爬取结束信号。 */
val newsTargetReachedSemaphore = Semaphore(THREAD_COUNT, THREAD_COUNT)
/** 待爬取队列非空信号。 */
val linkQueueAvailableSemaphore = Semaphore(Int.MAX_VALUE, Int.MAX_VALUE)
/* 将首页加入进去。 */
linkStore.put(SPIDER_WEB_ROOT)
/* 放出一个信号。 */
linkQueueAvailableSemaphore.release()
/* 创建并启动爬虫线程。 */
for (i in 0 until THREAD_COUNT) {
val thread = Thread {
/* ---------------- 爬虫爬取线程内容 开始 --------------- */
//
// do something
//
/* ---------------- 爬虫爬取线程内容 结束 --------------- */
}
thread.start()
threads.add(thread)
}
runBlocking {
newsTargetReachedSemaphore.acquire()
}
/* 等待所有爬虫工作完毕。 */
threads.forEach { thread ->
thread.join()
}
/* 关闭文件输出流。 */
fileWriter.close()
}
如上所述。关于信号量的最大值,由于每个线程之多释放一次爬取结束信号,该信号量最大值与线程数一致即可。
由于不知道待爬取链接队列中最多有多少个链接,信号量最大值设为 Int 的上限罢了。
其他变量及对象,你应该很熟悉(如果你有认真阅读前文)。
使用正则表达式获取 href 内容
前面提到,我们需要获取每个元素的 href 信息。如果我们对元素做遍历,似乎难度比较大。
不要忘了,HTML 文档本质是个文档。我们直接在文档里提取 href 关键字就可以了。对此,我们可以采用正则表达式来提取。
/** 用于识别 href 的正则表达式。 */
val hrefRegex = "href=\".*?\"".toRegex() // href="...". 需要手动去除引号及外面的部分。
关于正则表达式的知识,请自行学习 qwq…
爬虫线程工作流程
我们已经把外围程序和工具做好了。现在,我们只需要关心每个爬虫如何工作就行。
对于一个爬虫线程,它需要按照这个流程这样工作:
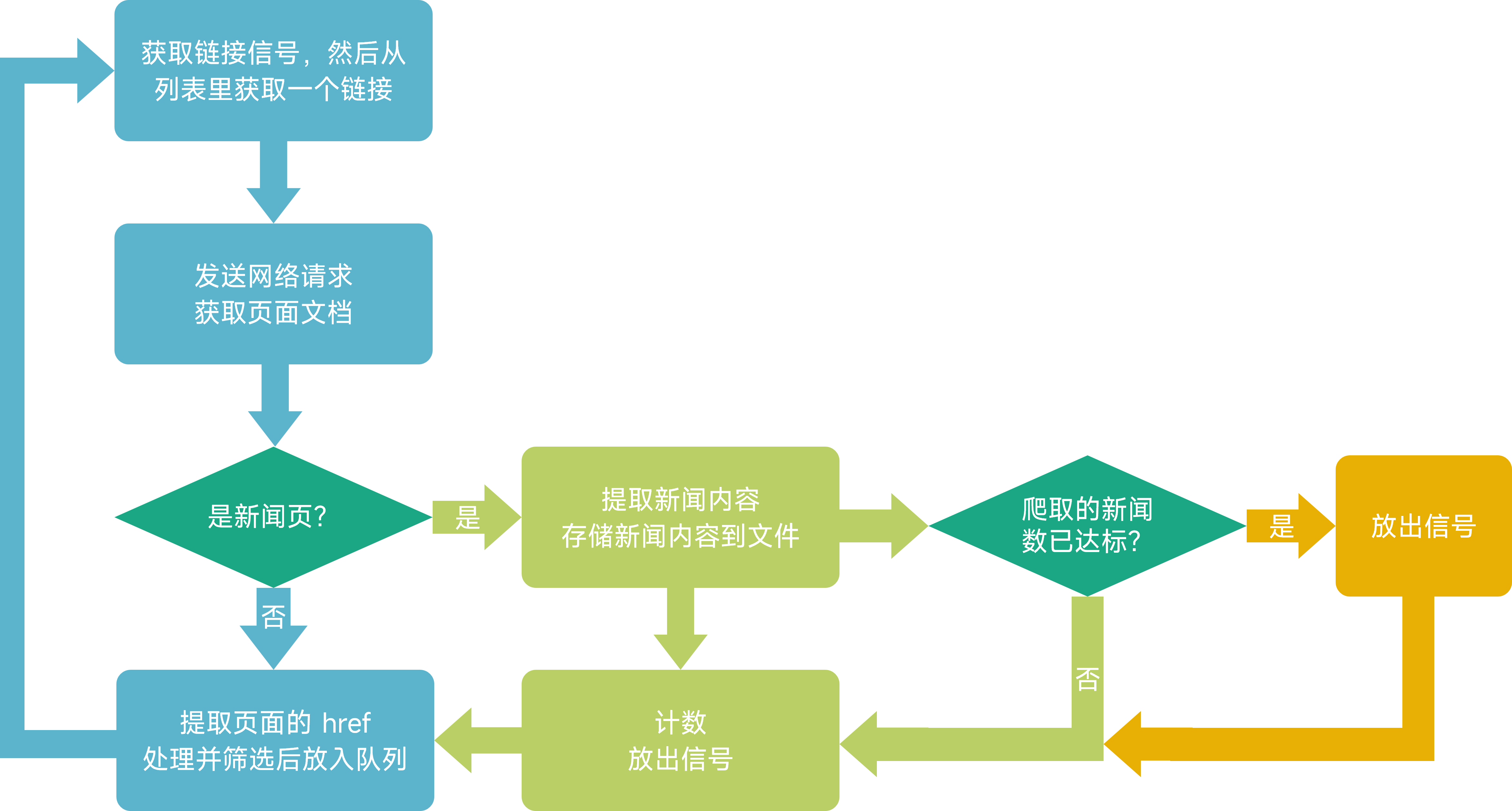
聪明的你一定发现,上述流程没有出口。对此,我们将出口设计在“获取链接”后,“发送网络请求”前。在这之间检查计数器的值。如果已爬取新闻数量已经达到预期,则结束线程。
那么另一个问题。如果已经达到爬取目标了,但此时链接队列为空,线程将会空等。这事怎么办?
解决方案很简单,让主线程放出几个信号即可。放出信号数量不小于线程数量。当线程接收到信号准备继续时,发现整个程序已经达到爬取目标了,则会退出。
爬虫流程代码
了解流程,即可编写代码。
/* ---------------- 爬虫爬取线程内容 开始 --------------- */
while (true) {
runBlocking {
linkQueueAvailableSemaphore.acquire() // 获取信号。
}
if (newsFetchedCounter.get() >= TARGET_NEWS_COUNT) { // 如果已经达到目标,就结束。
break
}
val link = linkStore.get() ?: continue // 拿链接。
println("${Thread.currentThread().id}: fetching $link")
/* 连接网站。 */
val response: Response
try {
response = Jsoup.connect(link)
.followRedirects(false)
.execute()
} catch (e: Exception) {
println("${Thread.currentThread().id}: exception while fetching $link.")
continue
}
/* 检查状态码。 */
val statusCode = response.statusCode()
if (statusCode != 200) {
println("${Thread.currentThread().id}: error while fetching $link. code is $statusCode")
continue
}
/* 获取网页文本。 */
val document = response.parse()
if (link.isNewsPage()) {
/* ---------------- 新闻页面:读取内容 --------------- */
val newsData = document.toNewsData() // 提取内容。后续描述。
if (newsData != null) {
val newsCount = newsFetchedCounter.incrementAndGet()
println("${Thread.currentThread().id}: news $newsCount: $link")
if (newsCount <= TARGET_NEWS_COUNT) {
newsData.url = link
fileWriter.writeLine(newsData.toString()) // 将爬取结果写入文件。
}
if (newsCount >= TARGET_NEWS_COUNT) {
newsTargetReachedSemaphore.release() // 释放“爬取新闻数达到预期”信号。
}
}
}
/* ---------------- 所有页面:读取并处理所有 href --------------- */
val regexResults = hrefRegex.findAll(document.toString())
regexResults.forEach regexResult@{
val href = it.value.substring("href=\"".length, it.value.length - 1)
/* 不看含不感兴趣的关键字的。 */
pageContentIgnoreKeywords.forEach { keyword ->
if (href.contains(keyword)) {
return@regexResult
}
}
/* 不看前缀不对的。如:mailto: */
pagePrefixIgnoreList.forEach { prefix ->
if (href.startsWith(prefix)) {
return@regexResult
}
}
/* 不看后缀不对的。例如:.jpg */
pageExtensionIgnoreList.forEach { extension ->
if (href.endsWith(extension)) {
return@regexResult
}
}
linkStore.put(link.concatUrl(href))
linkQueueAvailableSemaphore.release() // 放出信号。
}
}
/* ---------------- 爬虫爬取线程内容 结束 --------------- */
关于 Jsoup 库的部分不做过多描述。由于 Jsoup 本身具有发起网络请求功能,就不再使用其他方式进行
但是要注意,当遇到 404 等错误时,Jsoup 会抛出异常,因此需要进行捕获,而不是让整个线程挂掉。
仔细读处理过程的代码,不难发现,我们对部分内容进行过滤。由于我们只对 news.tongji.edu.cn 下的页面感兴趣,如果 href 的值指向其他网站,忽略即可。
另外,有些下载内容我们也不感兴趣。
因此,我们补充几个过滤列表:
/** 不感兴趣的链接后缀。 */
val pageExtensionIgnoreList = listOf(
".png", ".jpg", ".mp4", ".css"
)
/** 不感兴趣的 href 前缀。 */
val pagePrefixIgnoreList = listOf(
"https://", "http://", "mailto:", "ftp://", "#"
)
/** 不感兴趣的 href 内容关键字。 */
val pageContentIgnoreKeywords = listOf(
"https://", "mailto:", "ftp://", "http://", "download.jsp", "javascript:"
)
提取新闻内容
最后,我们还剩新闻内容的提取部分没有做。这部分比较简单。只需要对新闻页面的 HTML 文档做一些简单分析即可。
private fun Document.toNewsData(): NewsData? {
val ret = NewsData()
val content = this.getElementsByClass("content").first() ?: return null
/* 获取标题。 */
val titleElement = content.getElementsByTag("h3").first() ?: return null
ret.title = titleElement.text()
/* 获取来源和时间。 */
val sourceAndDateContainer = content.getElementsByTag("i").first() ?: return null
val sourceAndDateSegments = sourceAndDateContainer.text()
.split(" 浏览").first()
.split(" 时间:")
try { // 下面两行可能出错。万一没填这些信息,就完蛋...所以要用try保护一下。
ret.source = sourceAndDateSegments[0].split(":")[1]
ret.date = sourceAndDateSegments[1]
} catch (_: Exception) {
}
/* 获取内容。 */
val newsContentContainer = content.getElementsByClass("v_news_content").first() ?: return null
ret.content = newsContentContainer.text()
.replace("\n", " ")
.replace("\r", " ") // 不能忘掉这个!你永远不知道什么阴间地方会出现它...
return if (ret.title.isNotBlank() && ret.content.isNotBlank() && ret.date.isNotBlank())
{
ret
} else {
null
}
}
爬取结果
运行爬虫程序。该爬虫在内网环境运行,耗时5分钟,成功取得20000条新闻数据。结果文件如下图所示,很壮观。

踩坑记录
至此,你已经学会如何开发多线程爬虫了。但是,这个过程其实包含很多坑。
302 跳转
部分页面会返回一个 302 跳转。其中包含 href 信息。如果将它与普通网页一起处理,则会得到很多奇怪的链接。
404 异常
Jsoup 在遇到 404 问题时会抛出异常,需要做捕获。
文件的 flush
有可能因为网络等问题,爬虫爬取到一半出现故障。对此,应该在每次写文件后都调用一下 flush,如此可以保证已经得到的数据都在文件里。
换行
由于我们要求每个页面用一行存储在文件,需要将原文中的换行进行替换。这时一定要记住,行分隔符不仅有 \n,还有 \r。
改进方向
通用性
本爬虫针对同济新闻网。事实上,做一些简单修改即可将它改为通用爬虫。
存储目标
本例将爬虫结果写入到本地文件。事实上,可以将爬取结果写入到 HDFS 等分布式文件系统,以便后续处理。
达不到预期时的死锁
如果我们希望爬取1000条新闻,但对方网站只有500条,那么爬虫会停下来无休止等待。
总结
至此,你已经学会开发多线程爬虫了。快去实践一下吧!
当你成功爬取一个网站的一定量网页,便可对它们进行一些有趣的分析。例如,你可以基于这些网页数据构建一个搜索引擎。多么令人激动!
当然,这个爬虫还有很多待改进的地方。这些任务交给聪明的读者完成。感谢你越读到这里,希望本文对你的学习工作有所帮助。















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









