






目录
2‘’ 哲学家进餐问题(The Dinning Philosophers)问题
作业一: 前驱图
前趋图(Precedence Graph)是一个有向无环图,记为DAG(Directed Acyclic Graph),用于描述进程之间执行的前后关系。
题1.
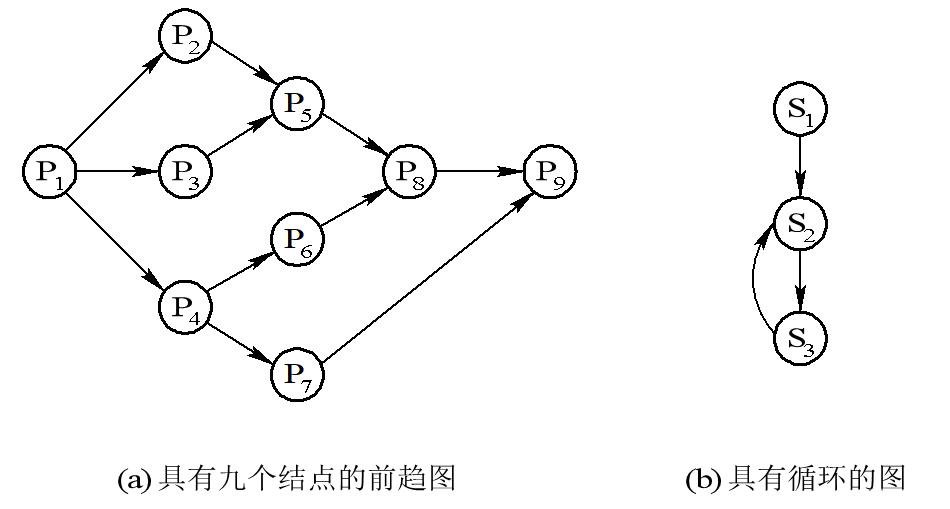
对于上图所示的前趋图,存在下述前趋关系:
P1→P2,P1→P3,P1→P4,P2→P5,P3→P5,P4→P6,P4→P7,P5→P8,P6→P8,P7→P9,P8→P9
或表示为: P={P1,P2,P3,P4,P5,P6,P7,P8,P9} →={(P1,P2),(P1,P3),(P1,P4),(P2,P5),(P3,P5),(P4,P6),(P4,P7),(P5,P8),(P6,P8),(P7,P9),(P8,P9)}
应当注意,前趋图中必须不存在循环,但在图(b)中却有着下述的前趋关系:S2→S3,S3→S2
题2:请画出下面语句的前趋关系(已知x,y,z是常量) S1:a=x+y+1 S2:b=a+z S3:c=1 S4:d=b+c S5:e=3*c S6:f=d++ S7:g= a+b+c+d+e+f
解:
(先找出初始结点,然后按结点下标从小到大画图)
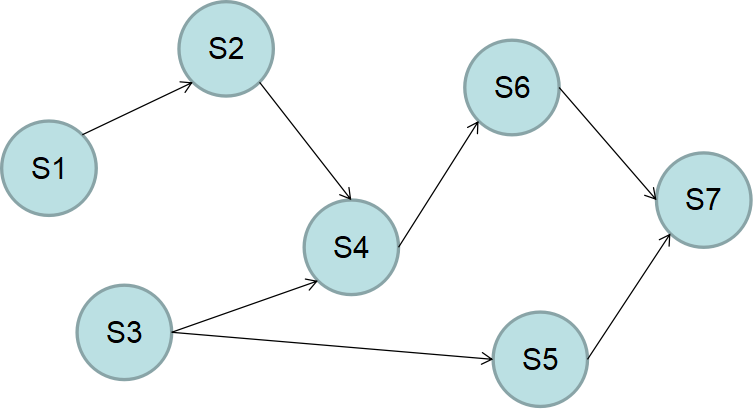
(为了避免遗漏,可按下标数字从小到大作为直接前趋,依次写出前趋关系)
描述:S={S1,S2,S3,S4,S5, S6 , S7} →={(S1,S2),(S2,S4),(S3,S4),(S3,S5),(S4,S6),(S5,S7),(S6,S7)}
作业二:信号量
同步:
信号量--同步(初始值为0)做法,v(s)与p(s)是成对出现的,v(s)出现在前驱事件,p(s)出现在后继
semaphore s=0;(作为同步的信号量)
p1(){
......
x;
v(s);
}
p2(){
p(s);
y;
}
1.找出前-后的同步关系,哪个事件要先发生(p1前,p2后)
2.设置同步信号量,初始值为0;
3.提供资源(信号)用v,释放使用资源(信号)用p;
互斥:
信号量--同步(初始值为1)
semaphore s=1;(作为异步的信号量)
p1(){
p(s);
我洗澡;
v(s);
}
p2(){
p(s)
哥哥洗澡;
v(s);
}
步骤:1,分析问题,确定临界区(写在p(s)-----v(s)的部分)
2.设置互斥信号量,初始值为1
3.临界区前后,p,v包围
题1:
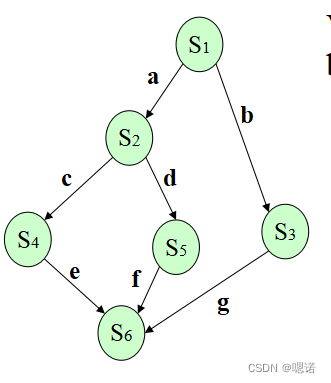
解法:
1)先给->标上字母,
2)开始写信号量
先赋值 Var 各个字母:semaphore:=初始值
再写begin pargin begin,记得对应的结束语句
begin+wait(有前趋结点才写)+结点+signal(后继结点)+end
Var a,b,c,d,e,f,g: semaphore=0,0,0,0,0,0,0;
begin
parbegin
begin S1; signal(a); signal(b); end;
begin wait(a); S2; signal(c); signal(d); end;
begin wait(b); S3; signal(g); end;
begin wait(c); S4; signal(e); end;
begin wait(d); S5; signal(f); end;
begin wait(e); wait(f); wait(g); S6; end;
parend
end
总体:

2、利用信号量实现作业1中画出的前趋图的前趋关系。
Var a,b,c,d,e,f,g,h,i,j: semaphore=0,0,0,0,0,0,0;
begin
parbegin
begin S1; signal(a); end;
begin S2; signal(b);signal(c); end;
begin wait(a); wait(b);S3; signal(d); end;
begin wait(c); S4; signal(e); end;
begin wait(e); S5; signal(f); end;
begin wait(d); wait(f); S6;signal(g);signal(h) end;
begin wait(g); S7; signal(i); end;
begin wait(h); S8; signal(j); end;
begin wait(i); wait(j); S9; end;
parend
end
作业三:同步算法
1‘’生产者消费者问题
例题:
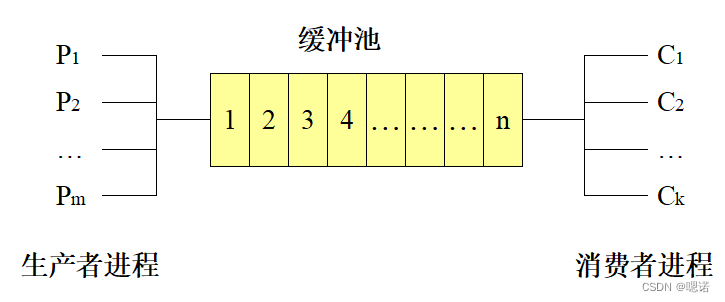
解1:

首先,定义了三个信号量:mutex(互斥量),empty,full。它们分别初始化为1,n,0。这里的mutex信号量用于保护对缓冲区的访问,empty信号量表示缓冲区中空闲的位置数量,full信号量表示缓冲区中已经存放的物品数量
接着定义了一个数组buffer,用于存放物品。in和out是用于跟踪添加到缓冲区或从缓冲区中移除物品的位置的变量。

在主程序中,使用parbegin和parend关键字定义了一个并行块。在这个并行块中有两个进程:producers和consumers。producers负责向缓冲区中添加物品,而consumers负责从缓冲区中移除物品。
生产者部分的代码意思如下:
- repeat:开始一个循环,表示生产者将一直执行以下操作。
- produce an item nextp:生产一个物品,并将其放入nextp中。
- wait(empty):等待缓冲区有空闲位置,如果没有则阻塞。
- wait(mutex):等待获取对缓冲区的互斥访问权。
- buffer(in) := nextp:将生产的物品放入缓冲区的in位置。
- in := (in+1) mod n:更新in的位置,循环利用缓冲区。
- signal(mutex):释放对缓冲区的互斥访问权。
- signal(full):通知消费者缓冲区中有物品可供消费。
- until false:由于使用了repeat,表示生产者将一直执行以上操作。
消费者部分的代码意思如下:
- repeat:开始一个循环,表示消费者将一直执行以下操作。
- wait(full):等待缓冲区中有物品可供消费,如果没有则阻塞。
- wait(mutex):等待获取对缓冲区的互斥访问权。
- nextc := buffer(out):从缓冲区的out位置取出一个物品。
- out := (out+1) mod n:更新out的位置,循环利用缓冲区。
- signal(mutex):释放对缓冲区的互斥访问权。
- signal(empty):通知生产者缓冲区中有空闲位置可供生产。
- consume the item in nextc:消费者消费取出的物品。
- until false:由于使用了repeat,表示消费者将一直执行以上操作
这段代码中使用了信号量来确保producers和consumers可以安全地访问缓冲区,而不会相互干扰。mutex信号量用于保护临界区,empty和full信号量用于控制缓冲区中物品的数量。
在生产者—消费者问题中应注意:
首先,在每个程序中用于实现互斥的wait(mutex)和signal(mutex)必须成对地出现;
其次,对资源信号量empty和full的wait和signal操作,同样需要成对地出现,但它们分别处于不同的程序中。例如,wait(empty)在生产者进程中,而signal(empty)则在消费者进程中,生产者进程若因执行wait(empty)而阻塞,则以后将由消费者进程将它唤醒;
最后,在每个程序中的多个wait操作顺序不能颠倒,应先执行对资源信号量的wait操作,然后再执行对互斥信号量的wait操作,否则可能引起进程死锁。
解2:利用AND信号量解决生产者-消费者问题
对于生产者—消费者问题,也可利用AND信号量来解决,即
用Swait(empty,mutex)来代替wait(empty)和wait(mutex);
用Ssignal(mutex,full)来代替signal(mutex)和signal(full);
用Swait(full,mutex)来代替wait(full)和wait(mutex),
以及 用Ssignal(mutex,empty)代替Signal(mutex)和Signal(empty)。
利用AND信号量来解决生产者—消费者问题的算法描述如下:
Var mutex,empty,full: semaphore:=1,n,0;
buffer: array[0,…,n-1] of item;
in out: integer:=0,0;
begin
parbegin
producer: begin
repeat
produce an item in nextp;
Swait(empty,mutex);
buffer(in):=nextp;
in:=(in+1)mod n;
Ssignal(mutex,full);
until false;
end
consumer:begin
repeat
Swait(full,mutex);
nextc:=buffer(out);
out:=(out+1) mod n;
Ssignal(mutex,empty);
consume the item in nextc;
until false;
end
parend
end
解3. 利用管程解决生产者-消费者问题
在利用管程方法来解决生产者—消费者问题时,首先便是为它们建立一个管程,并命名为Producer-Consumer,或简称为PC。
其中包括两个过程: (1) put(item)过程。生产者利用该过程将自己生产的产品投放到缓冲池中,并用整型变量count来表示在缓冲池中已有的产品数目,当count≥n时,表示缓冲池已满,生产者须等待。 (2) get(item)过程。消费者利用该过程从缓冲池中取出一个产品,当count≤0时,表示缓冲池中已无可取用的产品,消费者应等待。
PC管程可描述如下:
type producer-consumer=monitor
Var in,out,count: integer;
buffer: array[0, …, n-1] of item;
notfull,notempty: condition;
procedure entry put(item)
begin
if count>=n then notfull.wait;
buffer(in):=item;
in:=(in+1) mod n;
count:=count+1;
if notempty.queue then notempty.signal;
end
procedure entry get(item)
begin
if count<=0 then notempty.wait;
item:=buffer(out);
out:=(out+1) mod n;
count:=count-1;
if notfull.queue then notfull.signal;
end
begin
in:=out:=0;
count:=0
end
这段代码是描述了一个生产者-消费者问题的管程(monitor)实现。
-
type producer-consumer=monitor:定义了一个名为producer-consumer的管程类型。
-
Var in, out, count: integer; buffer: array[0, …, n-1] of item;notfull, notempty: condition;:定义了管程中的共享变量和条件变量。其中in表示缓冲区的写指针位置,out表示缓冲区的读指针位置,count表示缓冲区中物品的数量,buffer是用于存储物品的数组,notfull和notempty是用于同步生产者和消费者的条件变量。
-
-
procedure entry put(item):定义了一个名为put的进入过程(entry),用于生产者向缓冲区中放入物品。
- if count>=n then notfull.wait;:如果缓冲区已满(物品数量达到上限n),则生产者等待条件变量notfull。
- buffer(in):=item;in:=(in+1) mod n;count:=count+1;:将物品放入缓冲区,更新写指针位置,并增加缓冲区中物品的数量。
- if notempty.queue then notempty.signal;:如果有消费者在等待条件变量notempty,则唤醒一个消费者。
-
procedure entry get(item):定义了一个名为get的进入过程(entry),用于消费者从缓冲区中取出物品。
- if count<=0 then notempty.wait;:如果缓冲区为空(物品数量为0),则消费者等待条件变量notempty。
- item:=buffer(out);out:=(out+1) mod n;count:=count-1;:从缓冲区中取出物品,更新读指针位置,并减少缓冲区中物品的数量。
- if notfull.queue then notfull.signal;:如果有生产者在等待条件变量notfull,则唤醒一个生产者。
-
begin in:=out:=0; count:=0 end:初始化缓冲区的写指针、读指针和物品数量为0。
这段代码描述了一个使用管程实现的生产者-消费者问题的解决方案,通过共享变量和条件变量来实现生产者和消费者之间的同步和互斥访问。
利用管程解决生产者—消费者问题时,生产者和消费者可描述为:
producer: begin
repeat
produce an item in nextp;
PC.put(nextp);
until false;
end
consumer: begin
repeat
PC.get(nextc);
consume the item in nextc;
until false;
end
2‘’ 哲学家进餐问题(The Dinning Philosophers)问题
五个哲学家共用一张圆桌,分别作在周围的五张椅子上,在圆桌上有五个碗和五个筷子,他们的生活方式是交替地进行思考和进餐。平时,一个哲学家进行思考,饥饿时试图取其左右的筷子,只有拿到两只筷子时才能进餐,进餐完毕,放下筷子继续思考。
1. 利用记录型信号量解决
哲学家进餐问题 经分析可知,放在桌子上的筷子是临界资源,在一段时间内只允许一位哲学家使用。为了实现对筷子的互斥使用,可以用一个信号量表示一只筷子,由这五个信号量构成信号量数组。其描述如下: Var chopstick: array[0,…,4] of semaphore;
所有信号量均被初始化为1,第i位哲学家的活动可描述为:
repeat
think;
wait(chopstick[i]);
wait(chopstick[(i+1) mod 5]);
eat;
signal(chopstick[i]);
signal(chopstick[(i+1) mod 5]);
until false;
在以上描述中,当哲学家饥饿时,总是先去拿他左边的筷子,即执行wait(chopstick[i]); 成功后,再去拿他右边的筷子,即执行wait(chopstick[(i+1) mod 5]);又成功后便可进餐。进餐完毕,又先放下他左边的筷子,然后再放右边的筷子。虽然,上述解法可保证不会有两个相邻的哲学家同时进餐,但有可能引起死锁。假如五位哲学家同时饥饿而各自拿起左边的筷子时,就会使五个信号量chopstick均为0; 当他们再试图去拿右边的筷子时,都将因无筷子可拿而无限期地等待。对于这样的死锁问题,可采取以下几种解决方法:
题目:
1.在测量控制系统中的数据采集任务DataCollection()时,把所有采集的数据送到一个单缓冲区,计算任务DataCompute()从该缓冲区取出数据进行计算。试写出利用信号量机制实现两任务共享缓冲区Buffer的同步算法。
解1:
from threading import Semaphore
# 初始化信号量
empty = Semaphore(1) # 缓冲区空闲
full = Semaphore(0) # 缓冲区满
# 缓冲区
Buffer = []
# 数据采集任务
def DataCollection(data):
empty.acquire() # 等待缓冲区空闲
Buffer.append(data) # 将数据添加到缓冲区
full.release() # 发送信号,表示缓冲区已满
# 数据计算任务
def DataCompute():
full.acquire() # 等待缓冲区满
data = Buffer.pop(0) # 从缓冲区取出数据进行计算
empty.release() # 发送信号,表示缓冲区已空
# 进行数据计算操作
解2:
Var empty,full :Semaphore =1,0;
buffer:data
DataCollection(){
begin
repeat
采集数据GF;
wait(empty);
buffer=GF;
signal(full);
until false
}
DataCompute(){
begin
repeat
wait(full);
BF=buffer;
signal(empty);
取出数据BF
until false
}
2.在公共汽车.上,司机driver和售 票员conductor各司其职。
driver:
启动驾驶
驾驶中
在车站停车
conductor:
关门
售票
开门
司机和售票员应密切配合,协调一致,确保行车安全。请使用信号量同步driver和conductor。
解:
在这个问题中没有资源的抢夺,所以无互斥信号量。
司机和售票员是同步关系,司机需要接收门是否关好的信号量,而售票员需要接收车是否到站的信号量。
活动顺序:关车门->启动车辆->售票->到站停车->开车门
初始状态为:停车且门未关。
流程:售票员给司机关门的信号,司机收到后开始正常行驶车辆,到站时由司机给售票员停车的信号。
解:设关门信号量为door=0,停车信号量为stop=0。
void Driver(){
while(1){
wait(door);//司机等待关门信号,一旦获取信号,则启动车辆
启动车辆;
正常行车;
到站停车;
signal(stop); //司机给售票员停车的信号
}
}
void Busman(){
while(1){
关车门;
signal(door); //售票员给司机已经关门的信号
售票;
wait(stop); //等待停车信号,一旦停车,则开门
开车门;
}
3.有若干个小和尚和老和尚,小和尚要挑水给老和尚喝,已知道水桶(full)有12个,水井(mutex_well)有1个,水缸(vat)有4个,小和尚倒水的时候,老和尚不能喝水,一个井口只能放下一个水桶。请用信号量表示喝水和挑水。
小和尚:拿桶--去水井提水--放入水缸--放桶
老和尚:拿桶--喝水--放桶
Semaphore mutex_well=1;mutex_vat=1;
Semaphore pail=4;empty=12;full=0;
xiao(){
while(1){//多个人就循环
wait(empty);
wait(pail);
wait(mutex_well);
从水中取水;
signal(mutex_well);
signal(pail);
signal(full);
}
}
lao (){
whlie(1){
wait(full);
wait(pail);
wait(mutex-vat);
从水中取出一桶水;
signal(mutex_vat);
喝水;
signal(pail);
signal(empty);
}
}
4幼儿园里进行篮球游戏,老师往能装下20个篮球的筐子中不断放入篮球,小朋友可以从筐子中拿出篮球完成投篮。规定每次只能有一人往筐中放置或取出篮球,每次只允许一位小朋友投篮。试着用记录型信号量实现老师和小朋友进程之间的.
semaphore empty=20,full=0,mutex1=1,mutex2=1;
void teacher(){
void child(){while(1){ wait(ful);
while(1){
wait(mutex1); ball = get();
wait(empty);
signal(mutex1); signal(empty);
wait(mutex1);
wait(mutex2); shoot at the
put(ball);
basket; signal(mutex2);}}
signal(mutex1);
signal(ful)}}
作业四:调度算法
开始执行时间:max(上一进程结束完成时间,该进程到达时间)
完成时间:开始执行时间+服务时间
周转时间:完成时间-到达时间
带权周转时间:周转时间/服务时间
1、列表:进程名、到达时间、服务时间、开始执行时间、完成时间、周转时间、带权周转时间
2、先填写到达时间、服务时间、开始执行时间、完成时间、再填写周转时间
先来先服务:
| 进程名 | 到达时间 | 服务时间 | 开始执行时间 | 完成 时间 | 周转 时间 | 带权周转时间 |
| A | 0 | 1 | 0 | 1 | 1 | 1 |
| B | 1 | 100 | 1 | 101 | 100 | 1 |
| C | 2 | 1 | 101 | 102 | 100 | 100 |
| D | 3 | 100 | 102 | 202 | 199 | 1.99 |
短作业:
| 进程名 | 到达 时间 | 服务 时间 | 开始执行时间 | 完成 时间 | 周转 时间 | 带权周转时间 |
| A | 0 | 3 | 0 | 3 | 3 | 1 |
| B | 1 | 4 | 5 | 9 | 8 | 2 |
| C | 2 | 2 | 3 | 5 | 3 | 1.5 |
| D | 3 | 5 | 9 | 14 | 11 | 2.2 |
先来先服务(FCFS)和短作业优先(SJF)调度算法:
| 算法 | 进程名 | A | B | C | D | E | 平 均 |
| 到达时间 | 0 | 1 | 2 | 3 | 4 | ||
| 服务时间 | 4 | 3 | 5 | 2 | 4 | ||
| FCFS | 完成时间 | 4 | 7 | 12 | 14 | 18 | |
| 周转时间 | 4 | 6 | 10 | 11 | 14 | 9 | |
| 带权周转时间 | 1 | 2 | 2 | 5.5 | 3.5 | 2.8 | |
| SJF | 完成时间 | 4 | 9 | 18 | 6 | 13 | |
| 周转时间 | 4 | 8 | 16 | 3 | 9 | 8 | |
| 带权周转时间 | 1 | 2.67 | 3.1 | 1.5 | 2.25 | 2.1 |
| 算法 | 进程名 | A | B | C | D | E | 平 均 |
| 到达时间 | 0 | 1 | 3 | 4 | 6 | ||
| 服务时间 | 5 | 7 | 3 | 8 | 2 | ||
| FCFS | 完成时间 | 5 | 12 | 15 | 23 | 25 | |
| 周转时间 | 5 | 11 | 12 | 19 | 19 | 13。2 | |
| 带权周转时间 | 1 | 1.57 | 4 | 2.375 | 9.5 | 3.688 | |
| SJF | 完成时间 | 5 | 17 | 8 | 25 | 10 | |
| 周转时间 | 5 | 16 | 5 | 21 | 4 | 10.2 | |
| 带权周转时间 | 1 | 2.26 | 1.67 | 2.63 | 2 | 1.912 |
高响应比:
优先级 (响应比)= 作业周转时间/要求服务时间=(等待时间+要求服务时间)/要求服务时间=1+等待时间/要求服务时间
以下例题摘自:例题:最高响应比优先调度算法_最高响应比例题-CSDN博客
优先级调度算法和高响应比优先调度算法
1.先执行的是第一个提交作业,然后其余的作业再用响应比来判断执行顺序
2.计算每一个 响应比,选择响应比最高的一个作为下一个调度的作业,然后更新完成时间,重新计算,周而复始,直至所有作业调度完毕
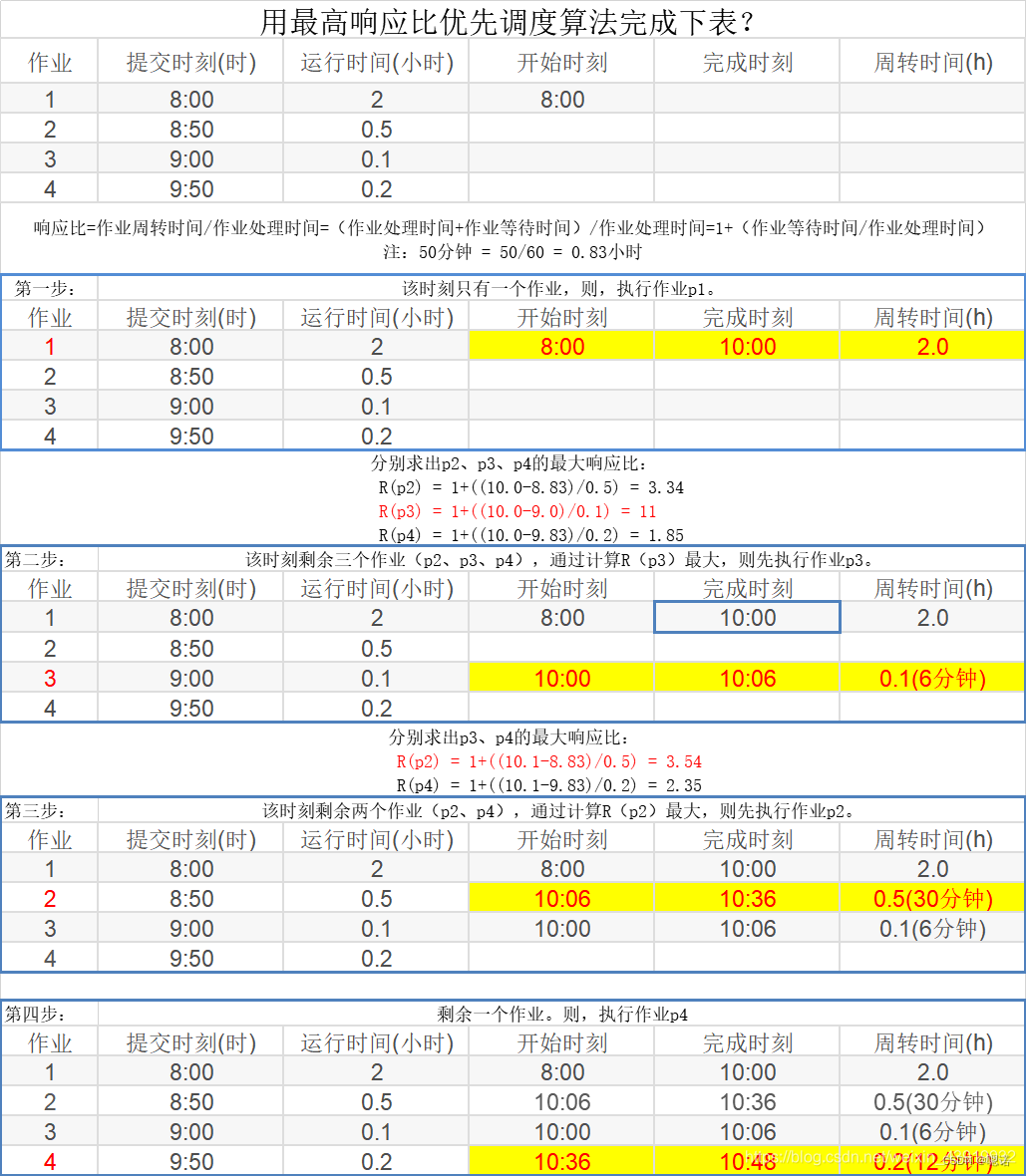
轮转法
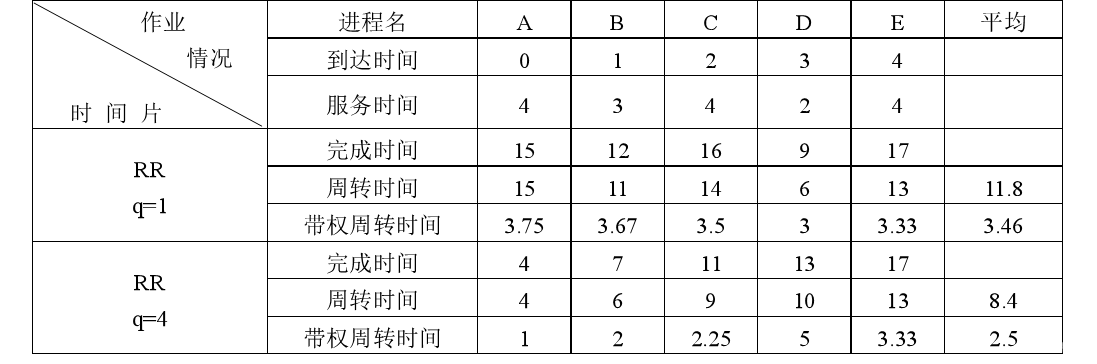
| 算法 | 进程名 | A | B | C | D | E | 平 均 |
| 到达时间 | 0 | 1 | 2 | 3 | 4 | ||
| 服务时间 | 4 | 3 | 5 | 2 | 4 | ||
| RR q=1 | 完成时间 | 12 | 10 | 18 | 11 | 17 | |
| 周转时间 | 12 | 9 | 16 | 8 | 13 | 11.6 | |
| 带权周转时间 | 3 | 3 | 3.2 | 4 | 3.25 | 3.29 | |
| RR q=4 | 完成时间 | 4 | 7 | 18 | 13 | 17 | |
| 周转时间 | 4 | 6 | 16 | 10 | 13 | 9.8 | |
| 带权周转时间 | 1 | 2 | 3.2 | 5 | 3.25 |
| 算法 | 进程名 | A | B | C | D | E | 平 均 |
| 到达时间 | 0 | 1 | 2 | 3 | 4 | ||
| 服务时间 | 6 | 2 | 5 | 9 | 8 | ||
| RR q=2 | 完成时间 | 16 | 4 | 21 | 30 | 29 | |
| 周转时间 | 16 | 3 | 19 | 27 | 25 | 18 | |
| 带权周转时间 | 2.67 | 1.5 | 3.8 | 3 | 3.13 | 2.82 | |
| RR q=4 | 完成时间 | 20 | 6 | 21 | 30 | 29 | |
| 周转时间 | 20 | 5 | 19 | 27 | 25 | 19.2 | |
| 带权周转时间 | 3.33 | 2.5 | 3.8 | 3 | 3.13 | 3.15 |
作业五:银行家算法
1.在银行家算法中,出现如下资源分配情况:
问:(1)该状态是否安全,如果不安全说明理由,如果安全给出安全序列;
(2)若进程P3提出请求Request(1,2,1)后,系统是否安全,如果不安全
说明理由,如果安全给出分配后的安全序列。
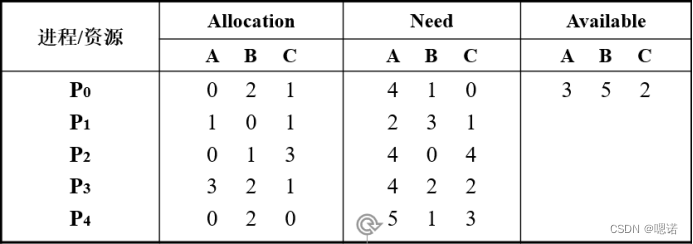
解:
1)
a.先画出表格,列名分别为work(现存的可控支配的各类资源的数量),need(各类个进程还需要至少各类资源多少才能结束进程),allocation(各个进程所需的各类资源的总数),work+Allocation,(注意need,allocation,跟原表交换位置了)
b.按照下标从小到大找到第一个现存资源(work,也是表中的Available)
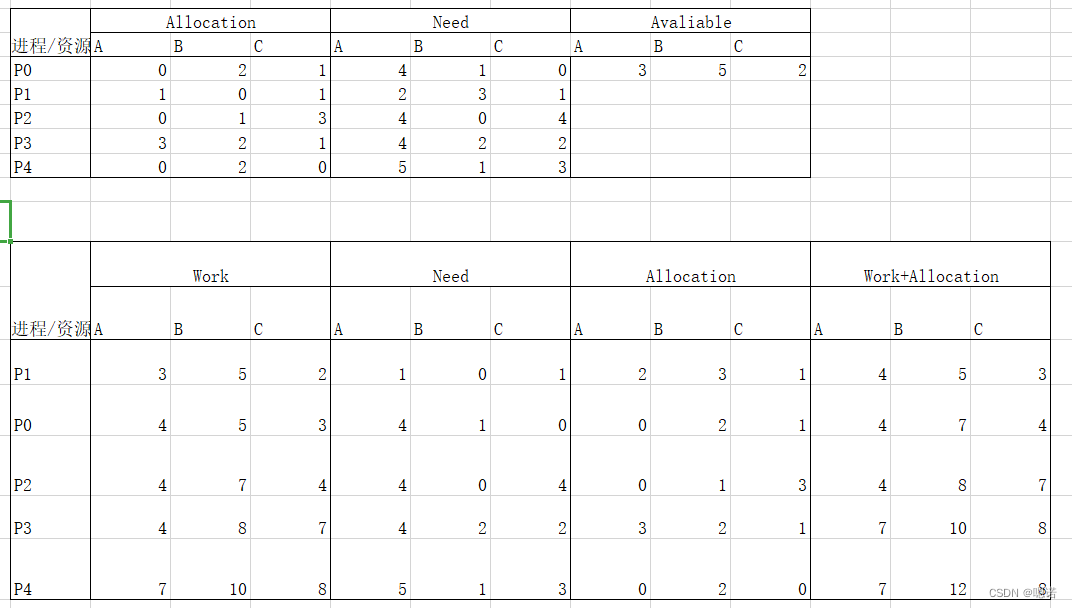
(表二p1的need和location位置反了,但除此之外答案无误)
2)
a.进程P3提出请求Request(1,2,1)后,更改原表P3的need,Allocation与剩余资源
b.重新按照1)做题
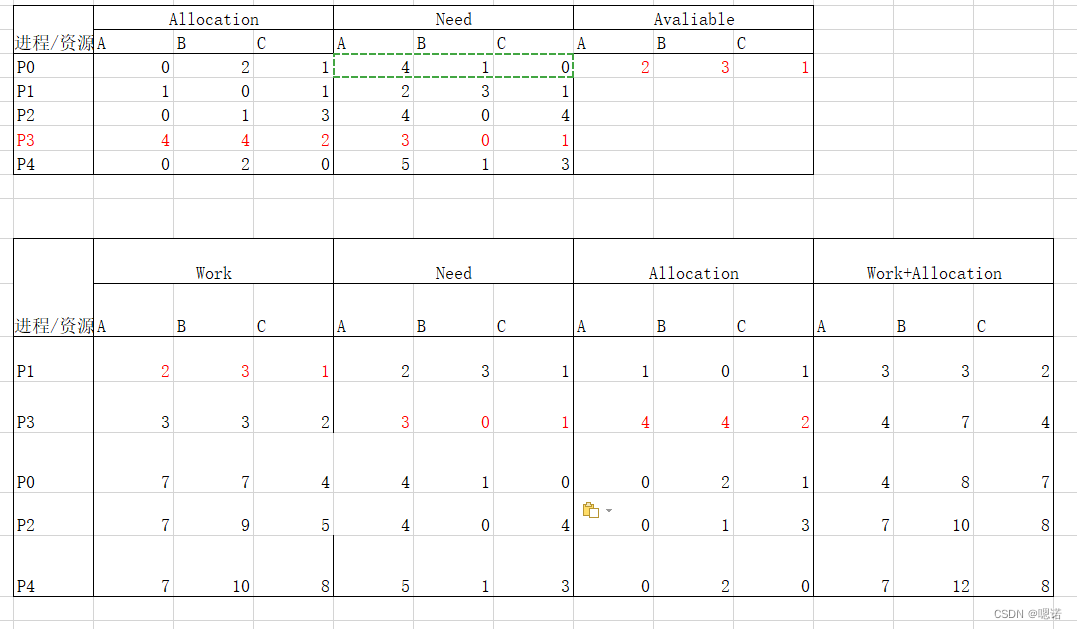
2.
问题: 在银行家算法中,若出现下述资源分配情况,试问:
Process Allocation Need Available
P0 003 0012 1622
P1 1000 1750
P2 1354 2356
P3 0332 0652
P4 0014 0656
(1)该状态是否安全?
(2)若进程P2提出请求Request(1,2,2,2)后,系统能否将资源分配给它?
解
(1)对该状态进行安全性检查:
Process Work Need Allocation Work+Allocation Finish
A B C D A B C D A B C D A B C D
P0 1 6 2 2 0 0 1 2 0 0 3 2 1 6 5 4 true
P3 1 6 5 4 0 6 5 2 0 3 3 2 1 9 8 6 true
P1 1 9 8 6 1 7 5 0 1 0 0 0 2 9 8 6 true
P2 2 9 8 6 2 3 5 6 1 3 5 4 3 12 13 10 true
P4 3 12 13 10 0 6 5 6 0 0 1 4 3 12 14 14 true
由安全性检查得知,可以找到一个安全序列{P0、P3、P1、P2、P4},因此系统是安全的。
(2)P2提出Request(1,2,2,2),系统按银行家算法进行检查:Request(1,2,2,2) ≤ Need(2,3,5,6),P2请求是合理的;Request(1,2,2,2)≤Available(1,6,2,2),P2请求是可以满足的;系统暂时先为进程P2试行分配资源,并修改有关的确数据,如下图所示:
Process Allocation Need Available
P0 0032 0012 0400
P1 1000 1750
P2 2576 1134
P3 0332 0652
P4 0014 0656
再利用安全性算法检查系统是否安全,可利用资源Available(0,4,0,0)已不能满足任何进程的需要,故系统进入不安全状态,此时系统不能将资源分配给P2。
作业六: 分区分配算法
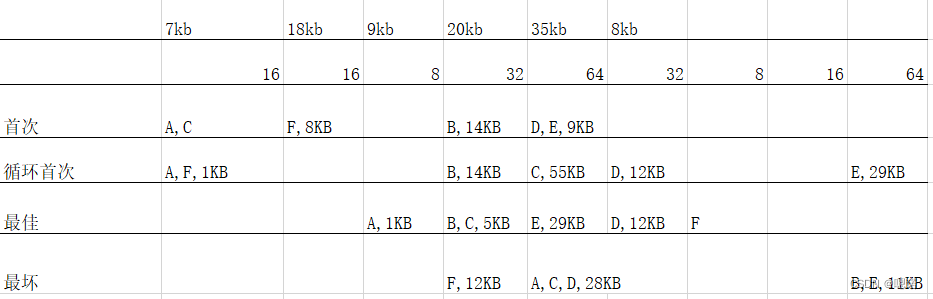
1、假设有一批作业A、B、C、D、E、F,它们的大小分别为7KB、18KB、9KB、20KB、35KB、8KB,根据不同的算法把它们分配到如下空闲分区表中。
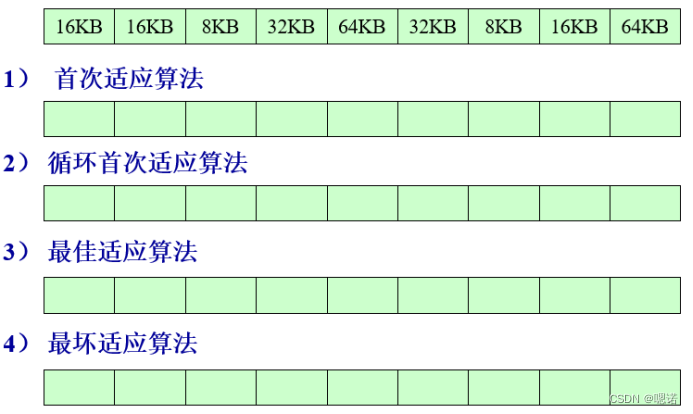
最先(首次)适应算法(FF):
思想:把进程尽量往低地址空闲区域放,放不下的话在更加地址慢慢升高
(每次从头找,找到空闲)
循环首次适应算法(NF):
与FF算法区别就是,不是每次都从首次开始,而是从上次找到的空闲分区的下一个空闲分区开始。(第一次查找的话也是从首页开始)。
(每次接上一次分的下一个区开始)
最佳适应算法(BF)
该算法和FF算法相似,每当进程申请空间的时候,系统都是从头部开始查找。
空闲区域是从小到大记录的,每次查找都从最小的开始,直到查找的满足要求的最小空闲
(每次找到能放下的且是最小的)
最坏适应算法(WF)
该算法与BF算法相反,BF是用最小的空闲区域来存储东西,而WF是用最大的空闲区域来存储。
(放置碎片的产生,每次都找到最大的)
2.已知某分页系统,主存容量为64K,页面大小为1K,对一个4页大的作业,其0,1,2,3页分别被分配到主存的2,4,6,7块中。
1)将十进制的逻辑地址 1023、2500、3500、4500转换成物理地址。
解:
①逻辑地址1023:1023/1k,得到页号为0,页内地址为1023,查页表找到对应的物理块号为2,故物理地址为2×1K+1023=3071。
A=1023,L=1024
p=INT[A/L]=INT[1023/1024]=0,d=[A]mod L=1023 mod 1024 =1023
物理地址=2*1024+1023=3071
②逻辑地址2500:2500/1K,得到页号为2,页内地址为452,查页表找到对应的物理块号为6,故物理地址为6×1K+452=6596。
A=12500,L=1024
p=INT[A/L]=INT[2500/1024]=2,d=[A]mod L=2500 mod 1024 =452
物理地址=6*1024+452=6596
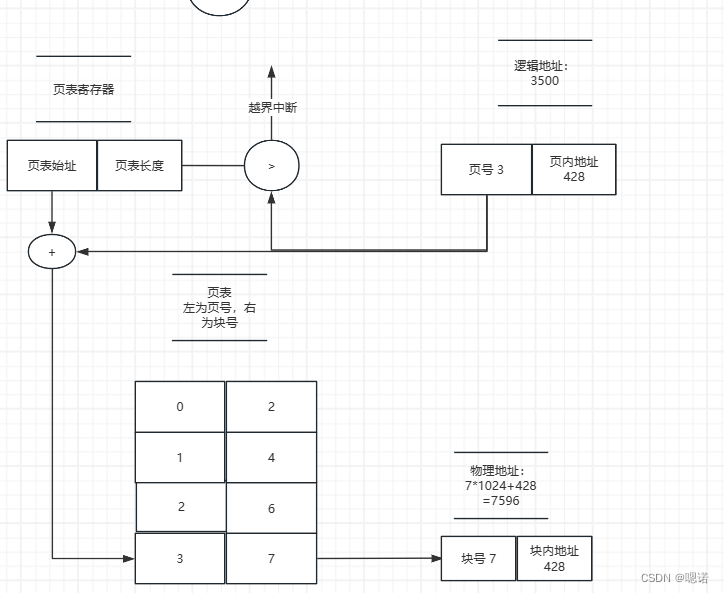
③逻辑地址3500:3500/1K,得到页号为3,:页内地址为428,查页表找到对应的物理块号为7,故物理地址为7×1K+428=7596。
A=3500,L=1024
p=INT[A/L]=INT[3500/1024]=3,d=[A]mod L=3500 mod 1024 =428
物理地址=7*1024+428=7596
④逻辑地址4500:4500/1K,得到页号为4,页内地址为404,因页号不小于页表长度,故产生越界中断
A=1023,L=1024
p=INT[A/L]=INT[1023/1024]=4>3
页号不小于页表长度,故而发生越界中断
2)以十进制逻辑地址3500为例画出地址变换过程图。
3,请根据下表将逻辑地址(0,137),(1,4000),(2,3600),(5,230)转换为物理地址

答: (1)段号0小于段表长5,故段号合法:由段表的第0项可获得段的内存始址为50K,段长为10K:由于段内地址137,小于段长l0K,故段内地址也是合法的,因此可得出对应的物理地址为50K+137=51337.
(2)段号1小于段表长,故段号合法:由段表的第1项可获得段的内存始址为60K,段长为3K:经检查,段内地址4000超过段长3K,因此产生越界中断。
(3)段号2小于段表长,故段号合法:由段表的第2项可获得段的内存始址为70K,段长为5K;故段内地址3600也合法。因此,可得出对应的物理地址为70K+3600-75280.
(4)段号5等于段表长,故段号不合法,产生越界中断。
作业七:页面置换
1.例题:在一个请求分页系统中,采用各种算法时,假如一个作业的页面走向为4、3、2、1、4、3、5、4、3、2、1、5,当分配给该作业的物理块数M为3(或4)时,试计算在访问过程中所发生的缺页次数和缺页率。请给出分析过程。
物理块为3时
最佳页面置换:
其核心思想是选择被淘汰页面将是以后永不使用的,或在最长(未来)时间内不再被访问的页面。
(步骤:先重写一遍页面序列,命中时底下那列不写,未命中时,若物理块未满,则直接补在下面,满了就考虑置换,置换时,若物理块里所有的页面在后面均被再次访问,则置换的是最晚重新访问的页面,若有多个页面再也没被访问过,则被置换的页面是这些再也未被访问的页面中,最早被访问的)

缺页次数为7次(有几列是有数字的),缺页率为(有几列是有数字的/总列数)f = 7/12
发生了4次缺页中断(有几列是没有数字的)
置换次数为4次(有几列物理块是全满的,然后总数减去1)
先入先出置换算法(FIFO):
其核心思想是淘汰最先进入的页面

缺页次数为9次,缺页率为9/12
置换次数为6次
最近最久未使用算法(LRU)
其核心思想为选择最近(的过去)最久未使用的页面予以淘汰

缺页次数为10次,缺页率为10/12
置换次数为7次
2. 假设物理块数M=3,有一个作业的页面走向为
4、3、2、1、4、3、5、4、3、2、1、5、6、2、3、7、1、2、6、1
1) 采用先进先出FIFO页面置换算法,计算访问过程中所发生的缺页次数和缺页率;
缺页次数为15次,缺页率为15/20=75%
置换次数为12次

2) 采用最佳页面Optimal置换算法,计算访问过程中所发生的缺页次数和缺页率;
(最佳置换算法(OPT)
缺页次数为11次,缺页率为11/20=85%
置换次数为8次

3) 采用最近最久未使用LRU置换算法,计算访问过程中所发生的缺页次数和缺页率。

缺页次数为17次,缺页率为17/20=85%
置换次数为14次
作业八:磁盘访问
1.顺序存储方式组织文件,每个块大小是100字节,FCB中的起始块号是37,当前的文件读位置是265,则真正读的磁盘块是哪一块?(C)
A.第37块 B.第43块 C.第39块 D.第7块
Blocknr = start_blocknr + pos/ BLOCK_SIZE
Blocknr:磁盘块
start_blocknr:起始块号
pos:当前的位置
BLOCK_SIZE:每块的大小(字节)
37 + 265/100 = 37 + 2
2.索引存储方式组织文件,FCB中共有4个索引项,3个项指向数据块,1个项指向一阶索引项,每个块(数据块和索引块)的大小是100个字节,表示一个块号需要2个字节,问最大的文件长度是?(A)
A.5300字节 B.500字节 C.5000字节 D.600字节
(100 / 2)* 100 + 3 * 100 =5300
3.有一f页式系统,其页表存放在主存中:
①如果对主存的一次存取需要1.5 μs,试问实现一次页面访问的存取时间是多少?
②如果系统具有快表平均命中率为85%,当页表项在快表中时,其查找时间忽略为0,试问此时的存取时间是多少?
解:
1)1.5+1.5=3μs
2)1.5*85%+(1.5+1.5)*(1-85%)=1.725
4.假设有11个进程先后提出磁盘IO请求,当前磁头正在110号磁道处,并预向磁道序号增加的方向移动。请求队列的顺序为30,145,120,78,82,140,20,42,165,55,65,分别用FCFS调度算法和SCAN调度算法完成上述请求,写出磁道访问顺序和每次磁头移动的距离,并计算移动磁道数。对于SCAN和CSCAN算法)向磁道号增加方向移动
FCFS:
写出访问顺序:110,30,145,120,78,82,140,20,42,165,55,65
写出每一步的移动距离:80,115,25,42,4,58,120,22,123,110,10
算出总移动距离:80+115+25+42+4+58+120+22+123+110+10=709
最后一步:
SCAN:
先按从小到大排序:20,30,42,55,65,78,82, 120,140,145,165
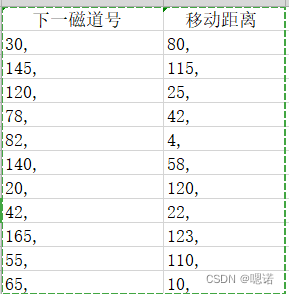
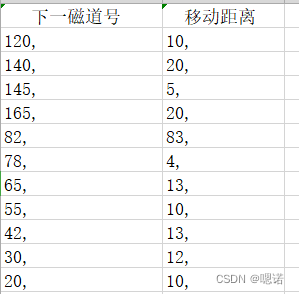
写出访问顺序(注意磁头位置,):110,120,140,145,165,82,78,65,55,42,30,20
写出每一步的移动距离:10,20,5,20,83,4,13,10,13,12,10
算出总移动距离:200
最后一步:
5.假设有10个进程先后提出了磁盘I/O请求,它们要访问的磁道号分别是:78,30,9,15,102,140,156,54,45,127,试用先来先服务FCFS、最短寻道时间优先SSTF算法、 SCAN和循环扫描CSCAN算法,分别给出访问过程中每次移动的距离,计算两种算法的平均寻道长度。
注:假设磁头从100号磁道开始,(对于SCAN和CSCAN算法)向磁道号增加方向移动。
FCFS:
写出访问顺序:100,78,30,9,15,102,140,156,54,45,127
写出每一步的移动距离:22,48,21,6,87,38,16,102,9,82
算出总移动距离:431
平均寻道长度:43.1
最后一步:列表
SSTF(访问:距离当前磁头最近的磁道号):
先按从小到大排序:9,15,30,45,54,78,102,127,140,156
写出访问顺序:100,102,78,54,45,30,15,9,127,140,156
写出每一步的移动距离:2,24,24,9,15,15,6,118,13,16
算出总移动距离:203
平均寻道长度:20.3
最后一步:列表
SCAN:
先按从小到大排序:9,15,30,45,54,78,102,127,140,156
写出访问顺序:100,102,127,140,156,78,54,45,30,15,9
写出每一步的移动距离:2,25,13,16,78,24,9,15,15,6
算出总移动距离:203
平均寻道长度:20.3
最后一步:列表
CSCAN:
先按从小到大排序:9,15,30,45,54,78,102,127,140,156
写出访问顺序:100,102,127,140,156,9,15,30,45,54,78
写出每一步的移动距离:2,25,13,16,147,6,15,15,9,24
算出总移动距离:272
平均寻道长度:27.2
最后一步:列表
6.假定磁盘有 200 个柱面,编号 0~199 , 当前存取臂的位置在 143 号柱面上,并刚刚完成了 125 号柱面的服务请求, 如果请求队列的先后顺序是: 86 ,147,91,177,94,150,102,175,130 ; 试问: 为完成上述请求, 下列算法存取臂移动(移动距离)的总量是多少?并算出存取臂移动的顺 序。 (1) 先来先服务算法 FCFS ; (2) 最短查找时间优先算法 SSTF ; (3) 扫描算法 SCAN ( 电 梯调度,先向地址大的方向)。
(补充:柱面数就是磁道数)
先来先服务算法 FCFS 为 565 , 依次为 143-86-147-91-177-94-150-102-175-130
最短查找时间优先算法 SSTF 为 162 依次为 143-147-150-130-102-94-91-86-175-177 。
电梯调度为 125, 依次为 143-147-150-175-177-130-102-94-91-86















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









