






全链条开源,与社区生态无缝连接
数据
书生·万卷
首个精细处理的开源多模态语料库
Miner U
一站式开源高质量数据提取工具,支持多格式(PDF/网页/电子书),智能萃取,生成高质量预训练/微调语料。
- 复杂版面/公式精准识别
- 性能超过商业软件
Label LLM
专业致力于LLM对话标注,通过灵活多变的工具配置与多种数据模态的广泛兼容,为大模型量身打造高质量的标注数据。
- 支持指令采集、偏好收集、对话评估…
- 多人协作、任务管理、源码开放可修改
Label U
一款轻量级开源标注工具,自由组合多样工具,无缝兼容多格式数据,同时支持载入预标注,加载数据标注效率。
- 支持图片、视频、音频多种数据标注
- 小巧灵活,AI标注导入二次人工精修
预训练
InternEvo
性能超过国际主流训练框架DeepSpeed
模型训练
InternLM、LLAMA、LLAVA、MoE
分布式训练系统
- 分布式训练数据并行、流水并行、张量并行、序列并行、权重并行、自动并行
- 仿真器求最优解并行配置
- 通信优化集合/p2p通信
- 显存优化
- 计算加速、高性能算子库、算子融合、混合精度训练
训练支撑系统
- 异常恢复
- 可视化
- 跨集群任务调度
- 日志系统
- 监控系统
- 告警系统
基础设施
- 跨硬件平台:
CPU/GPU/NPU - 存储:分布式文件存储/OSS
- 网络:训练/数据网络
大模型训练
支持千卡以上模型训练,千卡加速比可达92%
极致性能优化
4D并行+Ring Attention最高支持1M长文训练
软硬件生态
兼容HuggingFace生态
支持NV与910B筹集群
全场景训练
预训练+微调+RLHF
全场景覆盖
微调
XTuner
- 适配多种生态
- 多种微调算法
多种微调&偏好对齐算法,覆盖各类应用场景 - 适配多种开源生态
支持加载HuggingFace、ModelScope模型或数据集 - 自动优化加速
开发者无需关注复杂的显存优化与计算加速细节
支持千亿参数+百万上下文训练
- 适配多种硬件
- 训练方案覆盖NVIDIA 20系以上所有显卡
- 最低只需 8GB 显存即可微调 7B模型
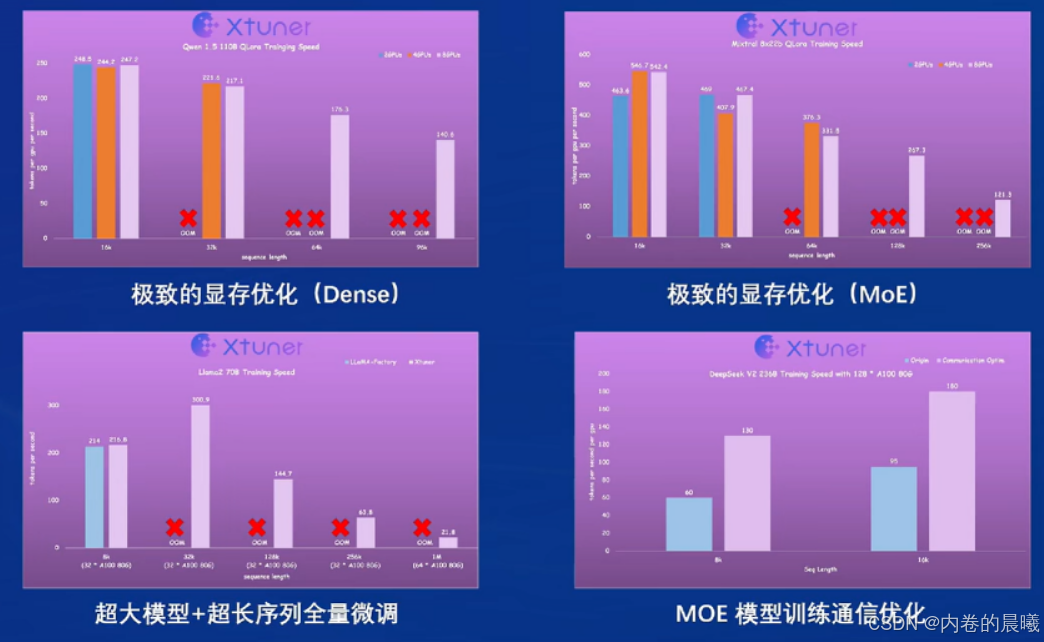
部署
LMDeploy
整体架构

评测
OpenComass评测体系
获得 Meta 官方推荐唯一国产大模型评测体系
开源社区最完善的评测体系之一超过100+评测集50万+题目
三位一体
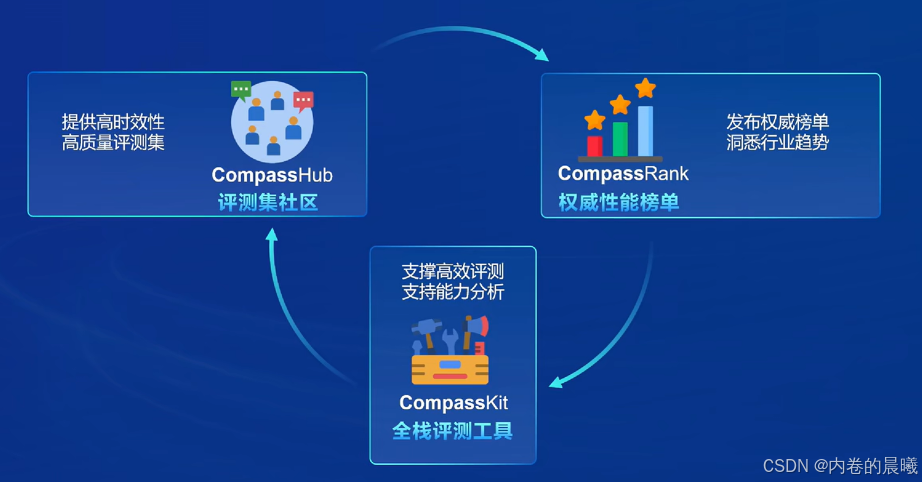
工具-基准-榜单
应用
智能体 Lagent
轻量级智能体框架
- 支持多种类型的智能体能力
- 灵活支持多种大语言模型
- 简单易扩展,支持丰富的工具
HuixiangDou 企业级知识库构建工具
介绍:HuixiangDou是群聊场景LLM知识助手,为即时通讯群聊场景设计。
场景特点:无关问题不吭声、明确回答的直接回复、不违背核心价值观
特性:
- 开源:BSD-3-Clasue免费商用
- 实战派:应用RAG和KG,1500+知识库,500+用户群,业务数据实测精度
- 领域知识:7中文档格式,更新立即生效
- 安全:支持私有化部署,数据不上传
- 简单便宜:最低仅2G显存,支持现有客户群
- 扩展性强:2类IM软件,9个LLM接口
社区生态
- Hugging Face
- LLM
- LLaMA
- TensorRT-LLM
- LM Studio
- LLaMA-Factory
- LIamaIndex
- LangChain
- ollama
- MLX
- llamafile
- Swift


















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











