







150. 逆波兰表达式求值
根据逆波兰表示法,求表达式的值。
有效的运算符包括 + , - , * , / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
整数除法只保留整数部分。 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
- 输入: ["2", "1", "+", "3", " * "]
- 输出: 9
- 解释: 该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
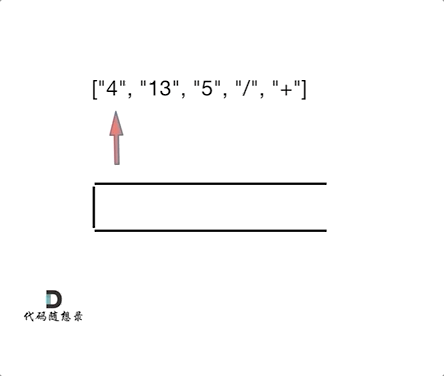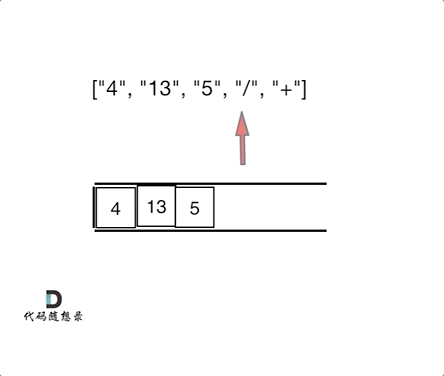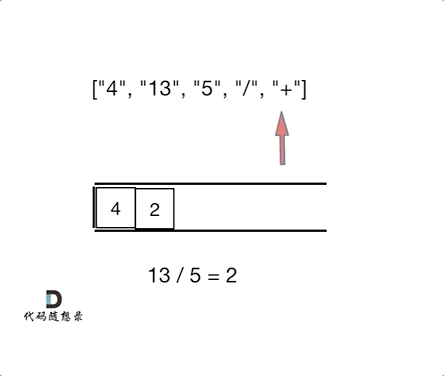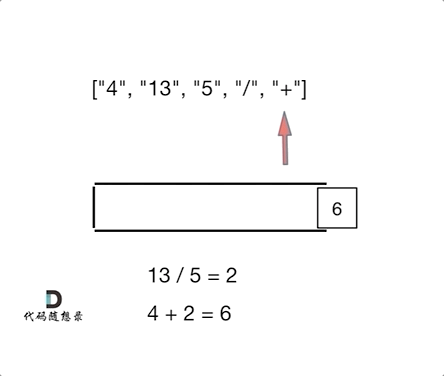
- 输入: ["4", "13", "5", "/", "+"]
- 输出: 6
- 解释: 该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入: ["10", "6", "9", "3", "+", "-11", " * ", "/", " * ", "17", "+", "5", "+"]
输出: 22
解释:该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5 = ((10 * (6 / (12 * -11))) + 17) + 5 = ((10 * (6 / -132)) + 17) + 5 = ((10 * 0) + 17) + 5 = (0 + 17) + 5 = 17 + 5 = 22逆波兰表达式:是一种后缀表达式,所谓后缀就是指运算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
适合用栈操作运算:遇到数字则入栈;遇到运算符则取出栈顶两个数字进行计算,并将结果压入栈中。
在上一篇文章中1047.删除字符串中的所有相邻重复项中提到了递归就是用栈来实现的。
代码随想录算法day09 | 栈与队列part01 | 232.用栈实现队列,225. 用队列实现栈,20. 有效的括号,1047. 删除字符串中的所有相邻重复项-CSDN博客
所以栈与递归之间在某种程度上是可以转换的! 这一点我们在后续讲解二叉树的时候,会更详细的讲解到。
那么来看一下本题,其实逆波兰表达式相当于是二叉树中的后序遍历。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。
但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后序遍历的方式把二叉树序列化了,就可以了。
在进一步看,本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么这岂不就是一个相邻字符串消除的过程,和1047.删除字符串中的所有相邻重复项中的对对碰游戏是不是就非常像了。
如动画所示:
相信看完动画大家应该知道,这和1047.删除字符串中的所有相邻重复项是差不多的,只不过本题不要相邻元素做消除了,而是做运算!
class Solution {
public int evalRPN(String[] tokens) {
Deque<Integer> stack = new LinkedList();
for (String s : tokens) {
if ("+".equals(s)) { // leetcode 内置jdk的问题,不能使用==判断字符串是否相等
stack.push(stack.pop() + stack.pop()); // 注意 - 和/ 需要特殊处理
} else if ("-".equals(s)) {
stack.push(-stack.pop() + stack.pop());
} else if ("*".equals(s)) {
stack.push(stack.pop() * stack.pop());
} else if ("/".equals(s)) {
int temp1 = stack.pop();
int temp2 = stack.pop();
stack.push(temp2 / temp1);
} else {
stack.push(Integer.valueOf(s));
}
}
return stack.pop();
}
}- 时间复杂度: O(n)
- 空间复杂度: O(n)
题外话
我们习惯看到的表达式都是中缀表达式,因为符合我们的习惯,但是中缀表达式对于计算机来说就不是很友好了。
例如:4 + 13 / 5,这就是中缀表达式,计算机从左到右去扫描的话,扫到13,还要判断13后面是什么运算符,还要比较一下优先级,然后13还和后面的5做运算,做完运算之后,还要向前回退到 4 的位置,继续做加法,你说麻不麻烦!
那么将中缀表达式,转化为后缀表达式之后:["4", "13", "5", "/", "+"] ,就不一样了,计算机可以利用栈来顺序处理,不需要考虑优先级了。也不用回退了, 所以后缀表达式对计算机来说是非常友好的。
可以说本题不仅仅是一道好题,也展现出计算机的思考方式。
在1970年代和1980年代,惠普在其所有台式和手持式计算器中都使用了RPN(后缀表达式),直到2020年代仍在某些模型中使用了RPN。
239. 滑动窗口最大值
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
进阶:
你能在线性时间复杂度内解决此题吗?
提示:
- 1 <= nums.length <= 10^5
- -10^4 <= nums[i] <= 10^4
- 1 <= k <= nums.length
这是使用单调队列的经典题目。
难点是如何求一个区间里的最大值呢? (这好像是废话),暴力一下不就得了。
暴力方法,遍历一遍的过程中每次从窗口中再找到最大的数值,这样很明显是O(n × k)的算法。
此时我们需要一个队列,这个队列呢,放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么。
每次窗口移动的时候,调用que.pop(滑动窗口中移除元素的数值),que.push(滑动窗口添加元素的数值),然后que.front()就返回我们要的最大值。
然后再分析一下,队列里的元素一定是要排序的,而且要最大值放在出队口,要不然怎么知道最大值呢。
但如果把窗口里的元素都放进队列里,窗口移动的时候,队列需要弹出元素。
那么问题来了,已经排序之后的队列 怎么能把窗口要移除的元素(这个元素可不一定是最大值)弹出呢。
大家此时应该陷入深思.....
其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。
不要以为实现的单调队列就是对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。
来看一下单调队列如何维护队列里的元素。
动画如下:
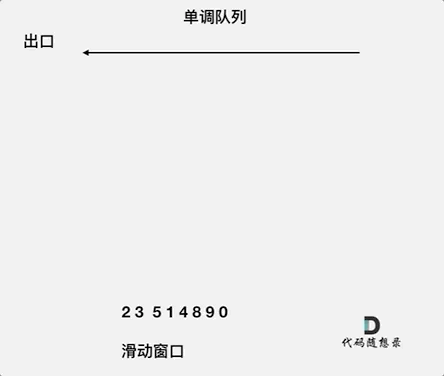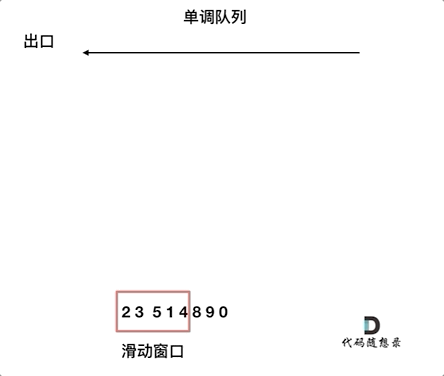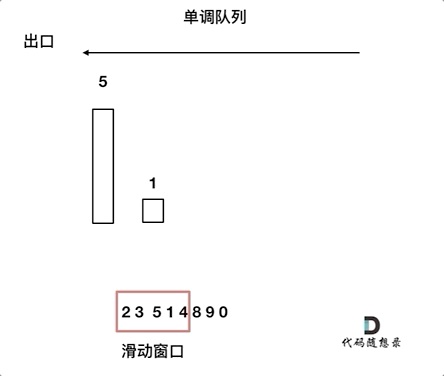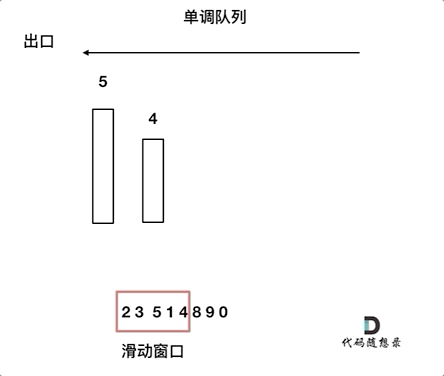
对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。
此时大家应该怀疑单调队列里维护着{5, 4} 怎么配合窗口进行滑动呢?
设计单调队列的时候,pop,和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
翻译一下就是:
想进队可以,那你要先跟我最小的队尾比一比,你比队尾大,那队尾出去,你再和下一个队尾比,直到你比队尾小,那你就变成我最小的队尾
谁从窗口被踹出去了我其实不在意,但是如果时队头被窗口踹出去了,那我队里也得换个队头了
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
为了更直观的感受到单调队列的工作过程,以题目示例为例,输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3,动画如下:
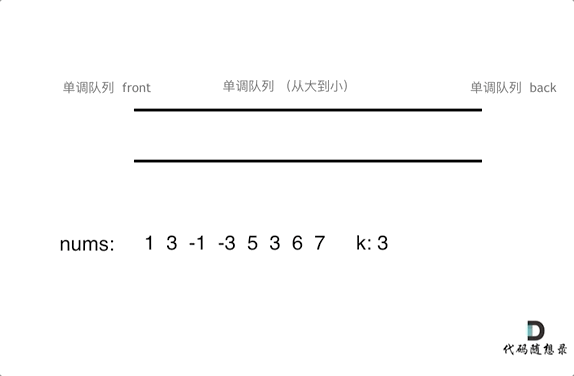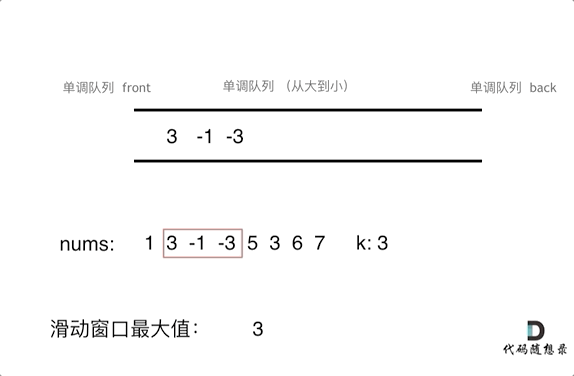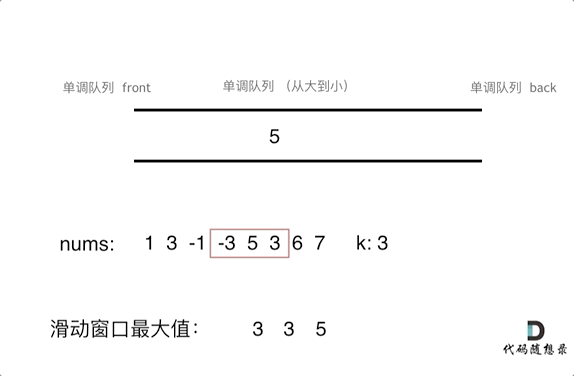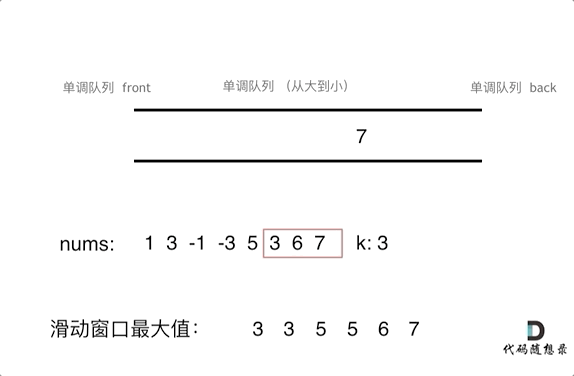
基于刚刚说过的单调队列pop和push的规则,代码不难实现,如下:
class MyQueue {
Deque<Integer> deque = new LinkedList<>();
//弹出元素时,比较当前要弹出的数值是否等于队列出口的数值,如果相等则弹出
//同时判断队列当前是否为空
void poll(int val) {
if (!deque.isEmpty() && val == deque.peek()) {
deque.poll();
}
}
//添加元素时,如果要添加的元素大于入口处的元素,就将入口元素弹出
//保证队列元素单调递减
//比如此时队列元素3,1,2将要入队,比1大,所以1弹出,此时队列:3,2
void add(int val) {
while (!deque.isEmpty() && val > deque.getLast()) {
deque.removeLast();
}
deque.add(val);
}
//队列队顶元素始终为最大值
int peek() {
return deque.peek();
}
}
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if (nums.length == 1) {
return nums;
}
int len = nums.length - k + 1;
//存放结果元素的数组
int[] res = new int[len];
int num = 0;
//自定义队列
MyQueue myQueue = new MyQueue();
//先将前k的元素放入队列
for (int i = 0; i < k; i++) {
myQueue.add(nums[i]);
}
res[num++] = myQueue.peek();
for (int i = k; i < nums.length; i++) {
//滑动窗口移除最前面的元素,移除是判断该元素是否放入队列
myQueue.poll(nums[i - k]);
//滑动窗口加入最后面的元素
myQueue.add(nums[i]);
//记录对应的最大值
res[num++] = myQueue.peek();
}
return res;
}
}347.前 K 个高频元素
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
- 输入: nums = [1,1,1,2,2,3], k = 2
- 输出: [1,2]
示例 2:
- 输入: nums = [1], k = 1
- 输出: [1]
提示:
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
- 你的算法的时间复杂度必须优于 $O(n \log n)$ , n 是数组的大小。
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
- 你可以按任意顺序返回答案。
这道题目主要涉及到如下三块内容:
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
然后是对频率进行排序,这里我们可以使用一种容器适配器就是优先级队列。
什么是优先级队列呢?
其实就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priorityQueue利用maxHeap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priorityQueue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
本题我们就要使用优先级队列来对部分频率进行排序。
为什么不用快排呢, 使用快排要将map转换为数组的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
此时要思考一下,是使用小顶堆呢,还是大顶堆?
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
寻找前k个最大元素流程如图所示:(图中的频率只有三个,所以正好构成一个大小为3的小顶堆,如果频率更多一些,则用这个小顶堆进行扫描)
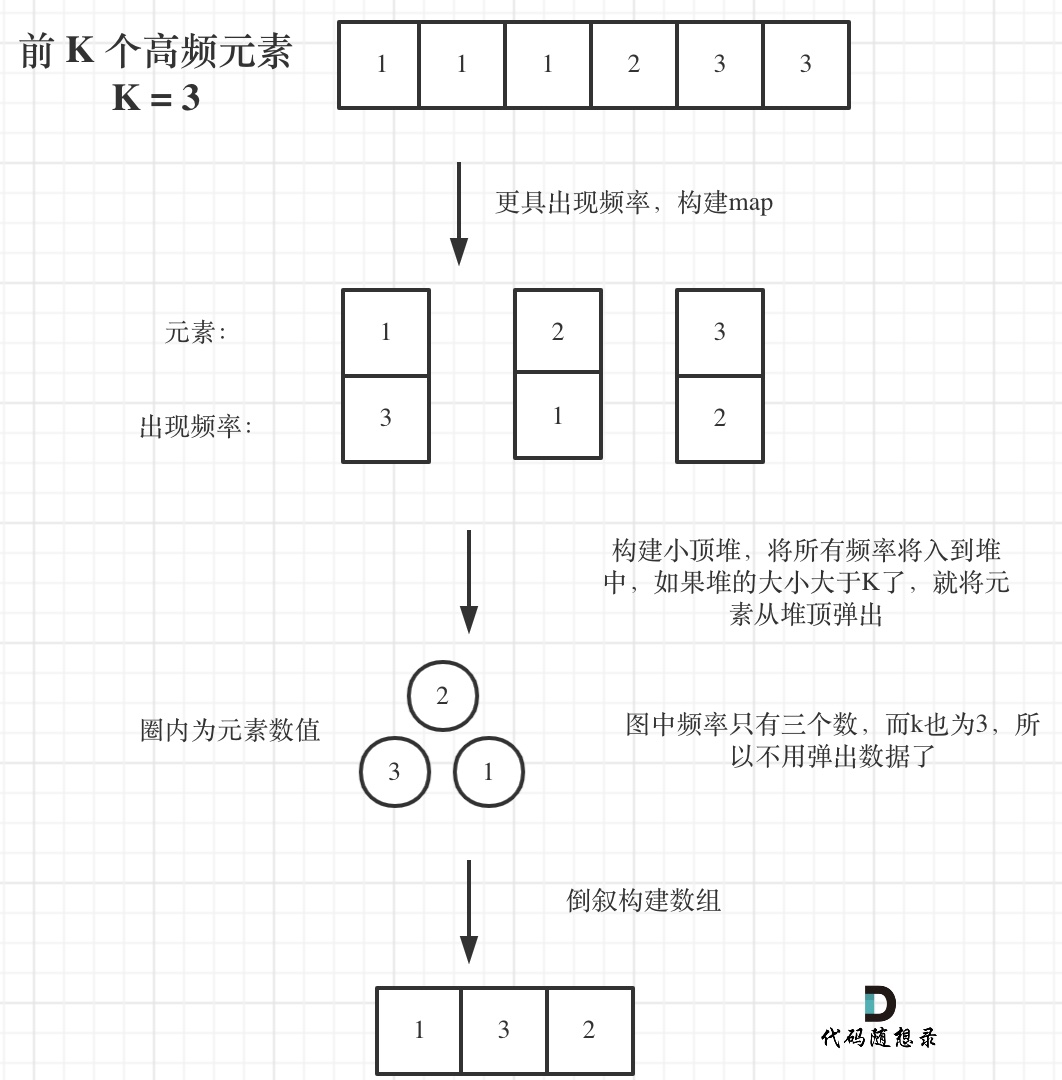
/*Comparator接口说明:
* 返回负数,形参中第一个参数排在前面;返回正数,形参中第二个参数排在前面
* 对于队列:排在前面意味着往队头靠
* 对于堆(使用PriorityQueue实现):从队头到队尾按从小到大排就是最小堆(小顶堆),
* 从队头到队尾按从大到小排就是最大堆(大顶堆)--->队头元素相当于堆的根节点
* */
class Solution {
//解法1:基于大顶堆实现
public int[] topKFrequent1(int[] nums, int k) {
Map<Integer,Integer> map = new HashMap<>(); //key为数组元素值,val为对应出现次数
for (int num : nums) {
map.put(num, map.getOrDefault(num,0) + 1);
}
//在优先队列中存储二元组(num, cnt),cnt表示元素值num在数组中的出现次数
//出现次数按从队头到队尾的顺序是从大到小排,出现次数最多的在队头(相当于大顶堆)
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2) -> pair2[1] - pair1[1]);
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {//大顶堆需要对所有元素进行排序
pq.add(new int[]{entry.getKey(), entry.getValue()});
}
int[] ans = new int[k];
for (int i = 0; i < k; i++) { //依次从队头弹出k个,就是出现频率前k高的元素
ans[i] = pq.poll()[0];
}
return ans;
}
//解法2:基于小顶堆实现
public int[] topKFrequent2(int[] nums, int k) {
Map<Integer,Integer> map = new HashMap<>(); //key为数组元素值,val为对应出现次数
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
//在优先队列中存储二元组(num, cnt),cnt表示元素值num在数组中的出现次数
//出现次数按从队头到队尾的顺序是从小到大排,出现次数最低的在队头(相当于小顶堆)
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2) -> pair1[1] - pair2[1]);
for (Map.Entry<Integer, Integer> entry : map.entrySet()) { //小顶堆只需要维持k个元素有序
if (pq.size() < k) { //小顶堆元素个数小于k个时直接加
pq.add(new int[]{entry.getKey(), entry.getValue()});
} else {
if (entry.getValue() > pq.peek()[1]) { //当前元素出现次数大于小顶堆的根结点(这k个元素中出现次数最少的那个)
pq.poll(); //弹出队头(小顶堆的根结点),即把堆里出现次数最少的那个删除,留下的就是出现次数多的了
pq.add(new int[]{entry.getKey(), entry.getValue()});
}
}
}
int[] ans = new int[k];
for (int i = k - 1; i >= 0; i--) { //依次弹出小顶堆,先弹出的是堆的根,出现次数少,后面弹出的出现次数多
ans[i] = pq.poll()[0];
}
return ans;
}
}简化版代码:
class Solution {
public int[] topKFrequent(int[] nums, int k) {
// 优先级队列,为了避免复杂 api 操作,pq 存储数组
// lambda 表达式设置优先级队列从大到小存储 o1 - o2 为从小到大,o2 - o1 反之
PriorityQueue<int[]> pq = new PriorityQueue<>((o1, o2) -> o1[1] - o2[1]);
int[] res = new int[k]; // 答案数组为 k 个元素
Map<Integer, Integer> map = new HashMap<>(); // 记录元素出现次数
for (int num : nums) map.put(num, map.getOrDefault(num, 0) + 1);
for (var x : map.entrySet()) { // entrySet 获取 k-v Set 集合
// 将 kv 转化成数组
int[] tmp = new int[2];
tmp[0] = x.getKey();
tmp[1] = x.getValue();
pq.offer(tmp);
// 下面的代码是根据小根堆实现的,我只保留优先队列的最后的k个,只要超出了k我就将最小的弹出,剩余的k个就是答案
if(pq.size() > k) {
pq.poll();
}
}
for (int i = 0; i < k; i++) {
res[i] = pq.poll()[0]; // 获取优先队列里的元素
}
return res;
}
}- 时间复杂度: O(nlogk)
- 空间复杂度: O(n)
拓展
大家对这个比较运算在建堆时是如何应用的,为什么左大于右就会建立小顶堆,反而建立大顶堆比较困惑。
确实 例如我们在写快排的cmp函数的时候,return left>right 就是从大到小,return left<right 就是从小到大。
优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关。















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









