






一、什么是LlamaIndex
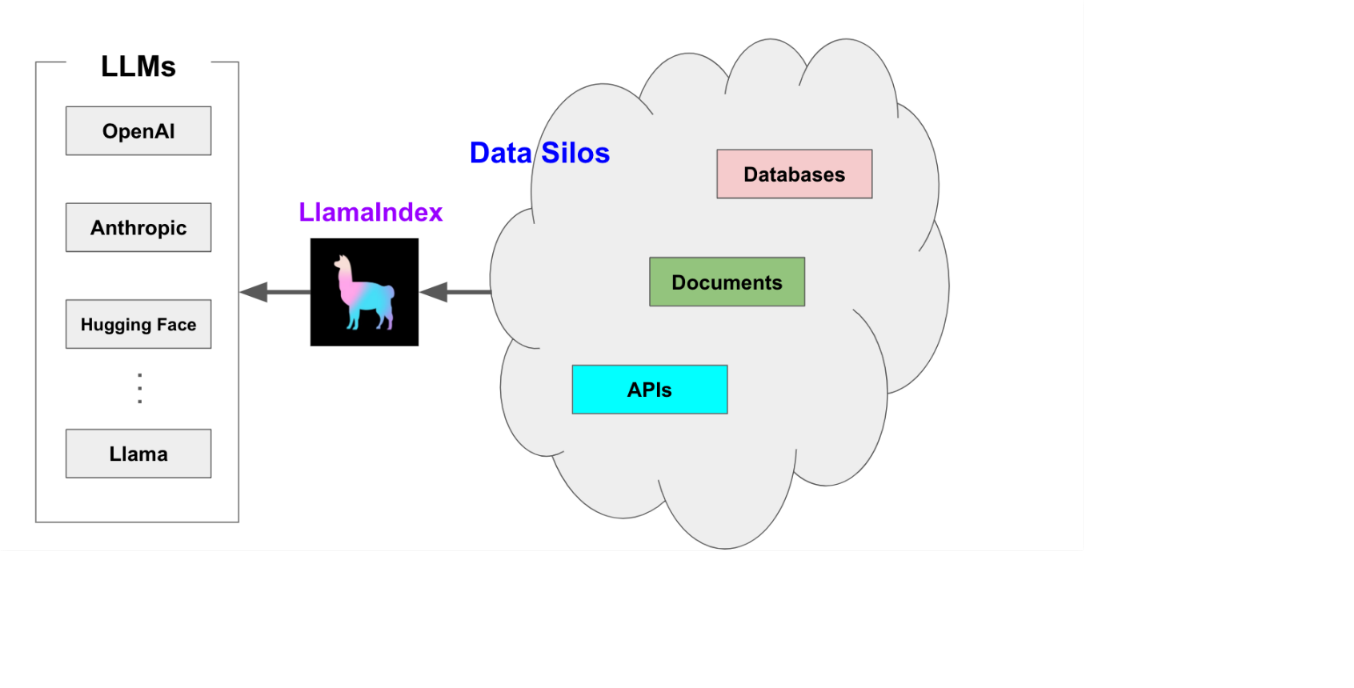
LlamaIndex(以前称为 GPT Index)是一个开源项目,它在 LLM 和外部数据源(如 API、PDF、SQL 等)之间提供一个简单的接口进行交互。它提了供结构化和非结构化数据的索引,有助于抽象出数据源之间的差异。它可以存储提示工程所需的上下文,处理当上下文窗口过大时的限制,并有助于在查询期间在成本和性能之间进行权衡。
LllamaIndex 以专用索引的形式提供独特的数据结构:
向量存储索引:最常用,允许您回答对大型数据集的查询。
树索引:对于总结文档集合很有用。
列表索引:对于合成一个结合了多个数据源信息的答案很有用。
关键字表索引:用于将查询路由到不同的数据源。
结构化存储索引:对于结构化数据(例如 SQL 查询)很有用。
知识图谱索引:对于构建知识图谱很有用。
LlamaIndex 还通过 LlamaHub 提供数据连接器,LlamaHub 是一个开源存储库,包含了各种数据加载器,如本地目录、Notion、Google Docs、Slack、Discord 等。
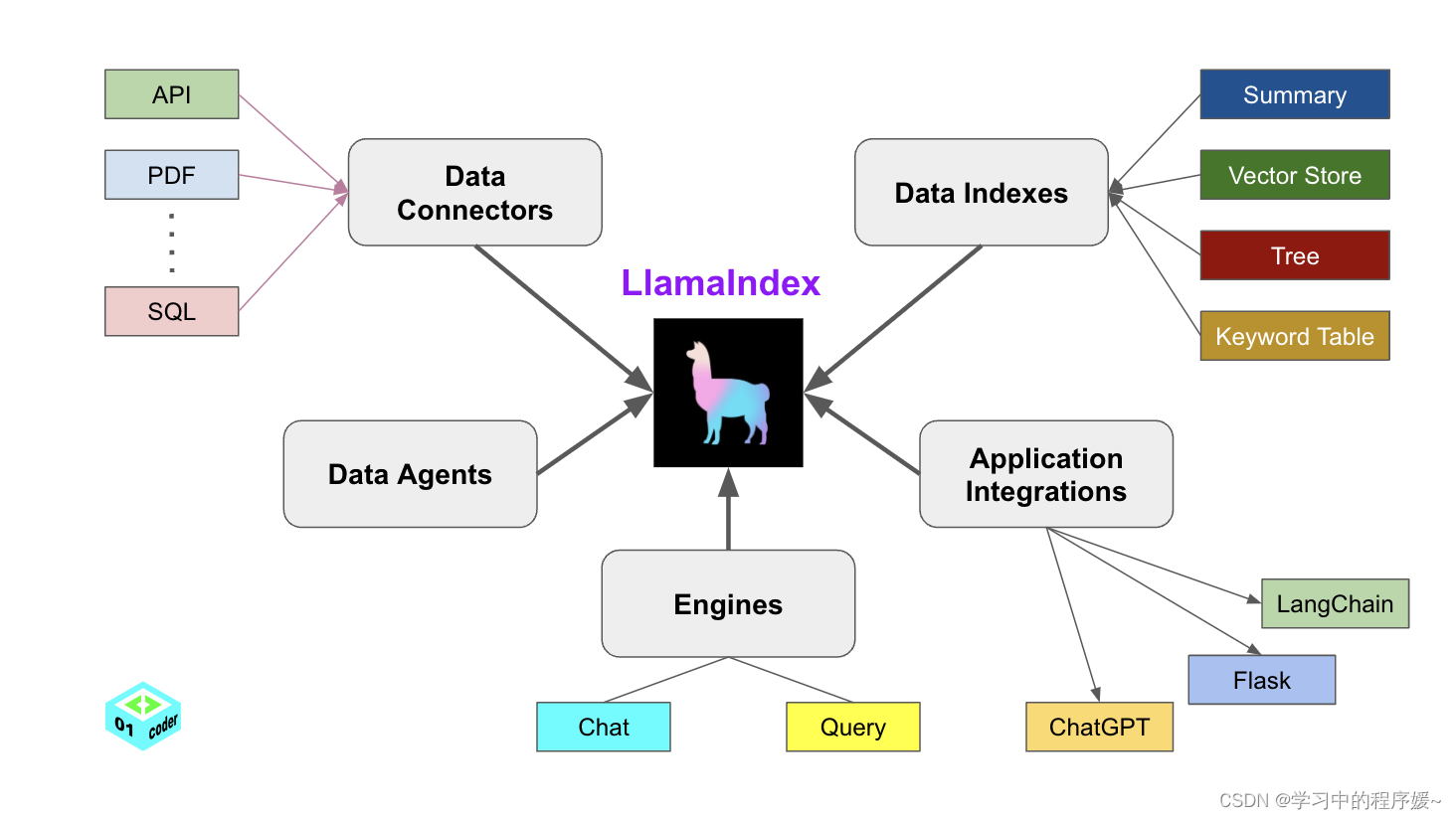
LlamaIndex 提供了5大核心工具:
- Data connectors
- Data indexes
- Engines
- Data agents
- Application integrations
二、核心概念
LlamaIndex 帮助构建 LLM 驱动的,基于个人或私域数据的应用。RAG(Retrieval Augmented Generation) 是 LlamaIndex 应用的核心概念。
RAG
RAG,也称为检索增强生成,是利用个人或私域数据增强 LLM 的一种范式。通常,它包含两个阶段:
-
索引
构建知识库。
-
查询
从知识库检索相关上下文信息,以辅助
LLM回答问题。
LlamaIndex 提供了工具包帮助开发者极其便捷地完成这两个阶段的工作。
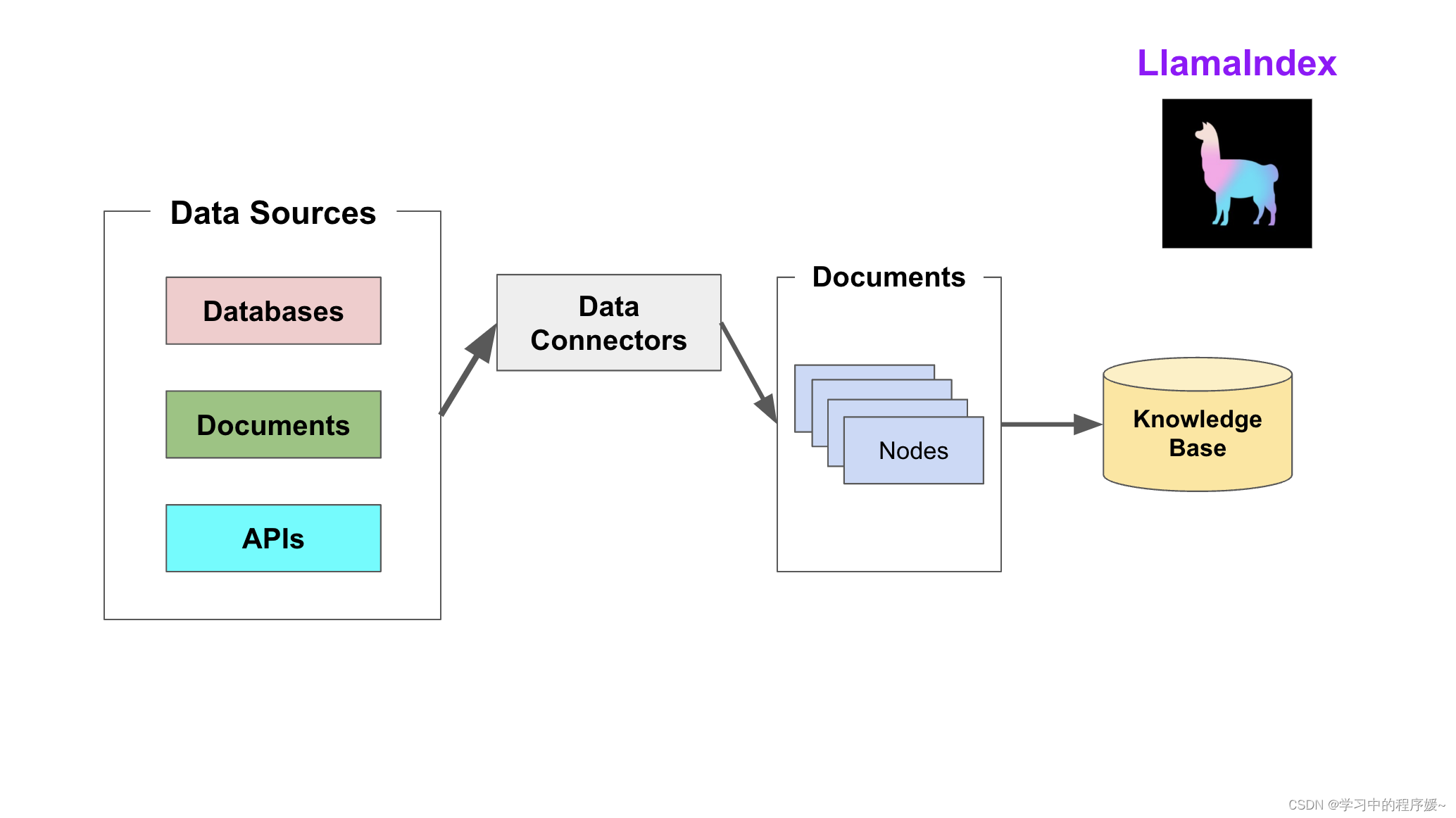
索引阶段
LlamaIndex 通过提供 Data connectors(数据连接器) 和 Indexes (索引) 帮助开发者构建知识库。
该阶段会用到如下工具或组件:
-
Data connectors
数据连接器。它负责将来自不同数据源的不同格式的数据注入,并转换为
LlamaIndex支持的文档(Document)表现形式,其中包含了文本和元数据。 -
Documents / Nodes
Document是
LlamaIndex中容器的概念,它可以包含任何数据源,包括,PDF文档,API响应,或来自数据库的数据。Node是
LlamaIndex中数据的最小单元,代表了一个 Document的分块。它还包含了元数据,以及与其他Node的关系信息。这使得更精确的检索操作成为可能。 -
Data Indexes
LlamaIndex提供便利的工具,帮助开发者为注入的数据建立索引,使得未来的检索简单而高效。最常用的索引是向量存储索引 -
VectorStoreIndex。
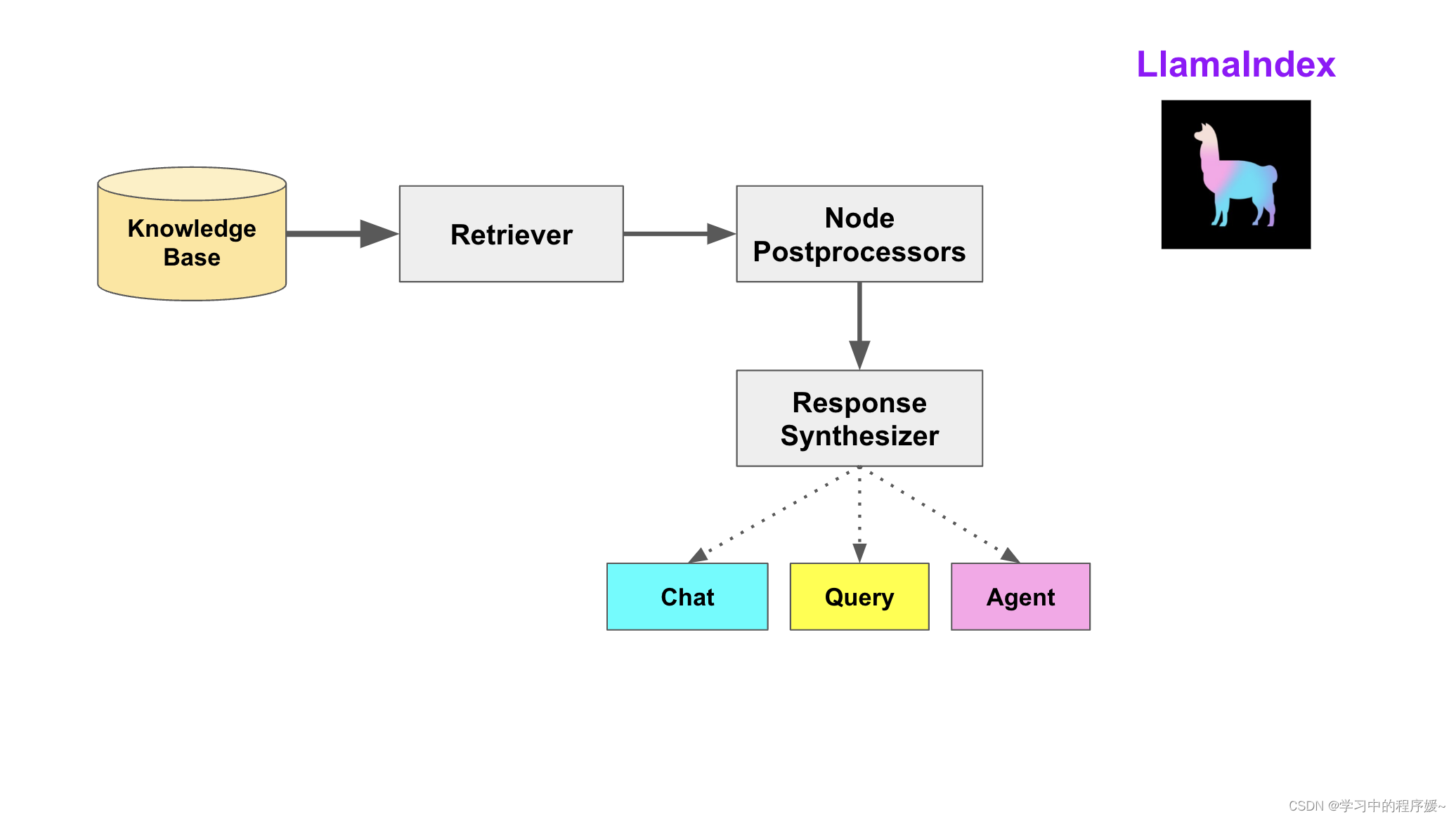
查询阶段
在查询阶段,RAG 管道根据的用户查询,检索最相关的上下文,并将其与查询一起,传递给 LLM,以合成响应。这使 LLM 能够获得不在其原始训练数据中的最新知识,同时也减少了虚构内容。该阶段的关键挑战在于检索、编排和基于知识库的推理。
LlamaIndex 提供可组合的模块,帮助开发者构建和集成 RAG 管道,用于问答、聊天机器人或作为代理的一部分。这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行推理。
该阶段的构建块包括:
-
Retrievers
检索器。它定义如何高效地从知识库,基于查询,检索相关上下文信息。
-
Node Postprocessors
Node后处理器。它对一系列文档节点(Node)实施转换,过滤,或排名。
-
Response Synthesizers
响应合成器。它基于用户的查询,和一组检索到的文本块(形成上下文),利用
LLM生成响应。
RAG管道包括:
-
Query Engines
查询引擎 - 端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下文。
-
Chat Engines
聊天引擎 - 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史)。
-
Agents
代理。它是一种由
LLM驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这为其提供了处理更复杂任务的额外灵活性。
三、个性化配置
LlamaIndex 对 RAG 过程提供了全面的配置支持,允许开发者对整个过程进行个性化设置。常见的配置场景包括:
- 自定义文档分块
- 自定义向量存储
- 自定义检索
- 指定
LLM - 指定响应模式
- 指定流式响应
注,个性化配置主要通过 LlamaIndex 提供的 ServiceContext 类实现。
配置场景示例
接下来通过简明示例代码段展示 LlamaIndex 对各种配置场景的支持。
自定义文档分块
from llama_index import ServiceContext service_context = ServiceContext.from_defaults(chunk_size=500)
自定义向量存储
import chromadb
from llama_index.vector_stores import ChromaVectorStore
from llama_index import StorageContext
chroma_client = chromadb.PersistentClient()
chroma_collection = chroma_client.create_collection("quickstart")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
自定义检索
自定义检索中,我们可以通过参数指定查询引擎(Query Engine)在检索时请求的相似文档数。
index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine(similarity_top_k=5)
指定 LLM
service_context = ServiceContext.from_defaults(llm=OpenAI())
指定响应模式
query_engine = index.as_query_engine(response_mode='tree_summarize')
指定流式响应
query_engine = index.as_query_engine(streaming=True)
完整实例
- 文档分块大小:500
- Chromadb作为向量存储
- 自定义检索文档数为5
- 指定大模型为OpenAI的模型
- 响应模式为
tree_summarize - 问答实现流式响应
Data Connectors (数据连接器)
在 RAG 的业务场景中,数据加载是非常重要的一个环节。LlamaIndex 定义了数据连接器接口,并提供了一系列实现来支持不同的数据源或数据格式的数据加载。它们包括,但不限于:
- Simple Directory Reader
- Psychic Reader
- DeepLake Reader
- Qdrant Reader
- Discord Reader
- MongoDB Reader
- Chroma Reader
- MyScale Reader
- Faiss Reader
- Obsidian Reader
- Slack Reader
- Web Page Reader
- Pinecone Reader
- Mbox Reader
- MilvusReader
- Notion Reader
- Github Repo Reader
- Google Docs Reader
- Database Reader
- Twitter Reader
- Weaviate Reader
- Make Reader
LlamaHub
LlamaIndex 的数据连接器通过 LlamaHub 提供。LlamaHub 是一个开源仓库,包含可轻松集成到任何 LlamaIndex 应用。

使用示例
使用LlamaIndex框架内置的数据连接器
LlamaIndex 框架提供了一系列内置的数据连接器。开发者不需要从 LlamaHub 加载就可以直接使用。
以下代码演示了如何读取网页数据。
from llama_index import SummaryIndex, SimpleWebPageReader
documents = SimpleWebPageReader(html_to_text=True).load_data(
["http://paulgraham.com/worked.html"]
)
从LlamaHub加载数据连接器
以下示例代码从 LlamaHub 加载 Markdown 文档数据连接器。关于该数据连接器的细节,请参考https://llamahub.ai/l/file-markdown
from pathlib import Path
from llama_index import download_loader
MarkdownReader = download_loader("MarkdownReader")
loader = MarkdownReader()
documents = loader.load_data(file=Path('./README.md'))
Documents & Nodes (文档与节点)
在 LlamaIndex 中,Document 和 Node 是最核心的数据抽象。
Document
Document 是任何数据源的容器:
- API响应
- 数据库
- ...
Document 存储:
- 文本数据
- 属性数据
- 元数据 (metadata)
- 关系数据 (relationships)
示例:
from llama_index import Document text_list = ["hello", "world"] documents = [Document(text=t) for t in text_list]
自定义Document
自定义Document可以实现元数据和文档ID的设置。
元数据可以在文档构建时指定,也可以在文档对象上修改,还可以在 SimpleDirectoryReader 的使用中设置。
-
构建时指定
from llama_index import Document document = Document( text='Hello World', metadata={ 'filename': 'hello_world.pdf', 'category': 'science' } ) -
在文档对象上修改
document.metadata = {'filename': 'hello_world_v2.pdf'} -
在
SimpleDirectoryReader的使用中设置当使用
SimpleDirectoryReader加载文档时,利用file_metadata回调进行设置from llama_index import SimpleDirectoryReader filenama_hook = lambda filename: {'file_name': filename} documents = SimpleDirectoryReader('./data', file_metadata=filenama_hook).load_data()注,请参阅simple-directory-reader了解
SimpleDirectoryReader的接口定义。
文档ID可以在 Document 创建后设置
from llama_index import Document document = Document(text='Hello World') document.doc_id = "xxxx-yyyy"
Node
Node 是 LlamaIndex 中的一等公民。Node 也包含了 Document 中相同类型的数据和属性。
Node 通常有两种构建方式:
- 基于API直接构建
- 基于
Document,利用节点解析器(NodeParser)生成。
注,基于 Document 衍生出来的 Node 也继承了 Document 上的属性。
示例:
# 基于API直接构建节点 from llama_index.schema import TextNode node = TextNode(text="hello world", id_="1234-5678")# 利用节点解析器生成节点 from llama_index import Document from llama_index.node_parser import SimpleNodeParser text_list = ["hello", "world"] documents = [Document(text=t) for t in text_list] parser = SimpleNodeParser.from_defaults() nodes = parser.get_nodes_from_documents(documents)
自定义Node
通常开发者可以通过自定义Node来:
- 定义节点间的关系 (relationship)
- 自定义节点ID
定义节点间的关系
RelatedNodeInfo被用来建立关系。RelatedNodeInfo支持在构造时传递参数设置元数据。from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo hello_node = TextNode(text="Hello", id_="1111-1111") world_node = TextNode(text="World", id_="2222-2222") hello_node.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(node_id=world_node.node_id, metadata={"created_by": "VerySmallWoods"}) world_node.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(node_id=hello_node.node_id) nodes = [hello_node, world_node]
自定义节点ID
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo hello_node = TextNode(text="Hello", id_="1111-1111") hello_node.id_ = "3333-3333"
本文来自 LlamaIndex-Tutorials/05_Documents_Nodes at main · sugarforever/LlamaIndex-Tutorials · GitHub
















 3085
3085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









