







蚂蚁集团一面4.1记录
这些问题答案后续会尽量补充完整,大家要是知道的话也可以在评论区发表一下对于问题的见解~共同进步!
1.首先问了一些关于工作地点、教育背景、为什么不读研之类的问题
2.我看你用到了一个叫XXL-JOB的中间件,你了解过他的一些底层原理吗?
我:把它的任务执行流程说了一遍:他主要是分为两个模块,一个是调度中心,一个是任务执行器;首先是把任务注册到执行器里去,当达到任务触发条件之后,任务管理中心就回下发任务,把这些任务都存到任务执行队列里,由JobHandler取出来执行,并把结果写到任务日志文件里,由回调线程进行结果异步上报。
3.那它底层的数据结构是怎么样的?你刚刚说的这些任务下发什么的都还是比较上层嘛对吧,比如我现在设置一个定时任务是十分钟触发一次,那它是用的什么数据结构去存储的?
我:这个真不知道 瞎回答的
4.那我们刚刚说到优化,你这个布隆过滤器的作用是什么?
我:先把要用到数据存进去,为了防止缓存穿透,你如果这个数据在布隆过滤器里查不到就一定不存在,如果查得到再去查缓存,查数据库
5.这里面有两个问题啊,我们为什么不用redis呢,我感觉redis也可以实现这个功能呀?
然后我解释了下这个是在redis基础之上过滤的,redis也有用到的
6.你怎么保证后续插入的数据和这个里面的hash map是同步的呢
我说可以在数据插入的业务逻辑那里手动往布隆过滤器也插一份;其次呢,也可以把这个交给任务调度器去完成,让它定时去进行一个插入
7.它是基于什么实现的,这个变量都已经存进去了,它怎么动态支持它去更新的
我:它是基于哈希表实现的,后续肯定可以支持新增的吧
8.它是怎么插入,是比如调用他的api还是用消息这些完成的
我:调用api
9.刚刚你说到的热点课程,其实是比价类似于秒杀业务的时候,你怎么去保证很多人同时去抢课的时候数据的一致性的
我:加锁
10.那这个锁是加在课程上面的还是什么的?
我这里其实没太理解,糊弄着说的是的,加在课程存数据库的时候的
计算机基础了(我答的稀烂 直接贴答案吧)
1.线程和进程的区别
下图是 Java 内存区域,我们从 JVM 的角度来说一下线程和进程之间的关系吧!
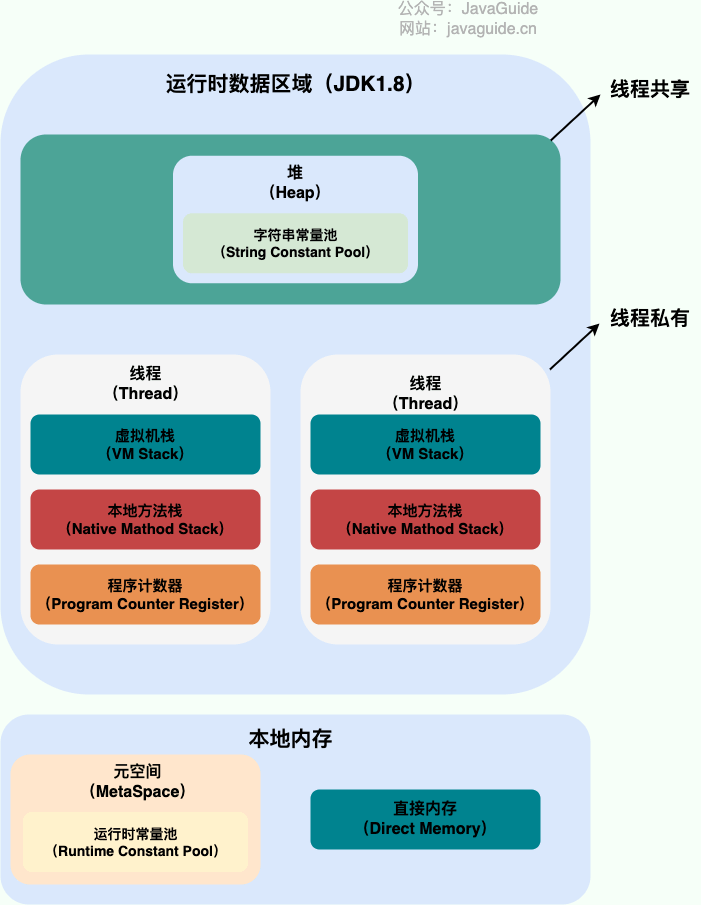
Java 运行时数据区域(JDK1.8 之后)
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的堆和**方法区 (JDK1.8 之后的元空间)*资源,但是每个线程有自己的*程序计数器、虚拟机栈 和 本地方法栈。
总结:
- 线程是进程划分成的更小的运行单位,一个进程在其执行的过程中可以产生多个线程。
- 线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。
- 线程执行开销小,但不利于资源的管理和保护;而进程正相反(著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/cs-basics/operating-system/operating-system-basic-questions-01.html)
2.这两个你分别举一个使用的场景
我:进程是打开了微信这个软件,线程就是你微信里面会有很多聊天框,都在拉取消息
3.说说java单例模式
我:在创建实例是会先判断一下这个实例是否已经存在,如果已经存在就不再创建了
4.java对于这个单例模式有几种实现方式 不知道 贴答案:
1.饿汉式(静态常量)【可用】
优点:这种写法比较简单,就是在类装载的时候就完成实例化。避免了线程同步问题。
缺点:在类装载的时候就完成实例化,没有达到Lazy Loading的效果。如果从始至终从未使用过这个实例,则会造成内存的浪费。
2.饿汉式(静态代码块)【可用】
这种方式和上面的方式其实类似,只不过将类实例化的过程放在了静态代码块中,也是在类装载的时候,就执行静态代码块中的代码,初始化类的实例。优缺点和上面是一样的。
3.懒汉式(线程不安全)【不可用】
这种写法起到了Lazy Loading的效果,但是只能在单线程下使用。如果在多线程下,一个线程进入了if (singleton == null)判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。所以在多线程环境下不可使用这种方式。
4.懒汉式(线程安全,同步方法)【不推荐用】
解决上面第三种实现方式的线程不安全问题,做个线程同步就可以了,于是就对getInstance()方法进行了线程同步。
缺点:效率太低了,每个线程在想获得类的实例时候,执行getInstance()方法都要进行同步。而其实这个方法只执行一次实例化代码就够了,后面的想获得该类实例,直接return就行了。方法进行同步效率太低要改进。
5.懒汉式(线程安全,同步代码块)【不可用】
由于第四种实现方式同步效率太低,所以摒弃同步方法,改为同步产生实例化的的代码块。但是这种同步并不能起到线程同步的作用。跟第3种实现方式遇到的情形一致,假如一个线程进入了if (singleton == null)判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。
6.双重检查【推荐使用】
Double-Check概念对于多线程开发者来说不会陌生,如代码中所示,我们进行了两次if (singleton == null)检查,这样就可以保证线程安全了。这样,实例化代码只用执行一次,后面再次访问时,判断if (singleton == null),直接return实例化对象。
优点:线程安全;延迟加载;效率较高。
7.静态内部类【推荐使用】
这种方式跟饿汉式方式采用的机制类似,但又有不同。两者都是采用了类装载的机制来保证初始化实例时只有一个线程。不同的地方在饿汉式方式是只要Singleton类被装载就会实例化,没有Lazy-Loading的作用,而静态内部类方式在Singleton类被装载时并不会立即实例化,而是在需要实例化时,调用getInstance方法,才会装载SingletonInstance类,从而完成Singleton的实例化。
类的静态属性只会在第一次加载类的时候初始化,所以在这里,JVM帮助我们保证了线程的安全性,在类进行初始化时,别的线程是无法进入的。
优点:避免了线程不安全,延迟加载,效率高。
8.枚举【推荐使用】
借助JDK1.5中添加的枚举来实现单例模式。不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象。(原文链接:https://blog.csdn.net/qq_41458550/article/details/109243456)
5.说说TCP和UDP的区别(贴的答案)
- 是否面向连接:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
- 是否是可靠传输:远地主机在收到 UDP 报文后,不需要给出任何确认,并且不保证数据不丢失,不保证是否顺序到达。TCP 提供可靠的传输服务,TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制。通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。
- 是否有状态:这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(这很渣男!)。
- 传输效率:由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
- 传输形式:TCP 是面向字节流的,UDP 是面向报文的。
- 首部开销:TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
- 是否提供广播或多播服务:TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
- ……
我把上面总结的内容通过表格形式展示出来了!确定不点个赞嘛?
| TCP | UDP | |
|---|---|---|
| 是否面向连接 | 是 | 否 |
| 是否可靠 | 是 | 否 |
| 是否有状态 | 是 | 否 |
| 传输效率 | 较慢 | 较快 |
| 传输形式 | 字节流 | 数据报文段 |
| 首部开销 | 20 ~ 60 bytes | 8 bytes |
| 是否提供广播或多播服务 | 否 | 是 |
著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/cs-basics/network/other-network-questions2.html
6.再回到你刚刚这个项目,你这个里面的数据量有多大啊 估计没上线也就几百上千条吧,你觉得你这个项目如果上线之后,数据访问量突然从几千变到了上亿级别,你觉得可能会出现哪些问题
真不知道 就说了几个比如可能接口插入数据报错之类的 可能数据库宕机
7.怎么解决这个因为数据太大把数据库打爆的情况
不知道 说了几个 比如读写分离 分库分表 把热点数据再挪一部分引入缓存
8.数据插入不成功怎么解决
啊啊不知道 说了几个:首先是给用户一个友好的反馈;然后把这些没成功的记录下来,之后再结合任务调度进行第二次的插入重试的操作
9.你觉得这个项目你遇到的最大的难点是什么 怎么解决的
栓q 都忘了啊啊啊
反问环节:问的面试官对我之后的学习有没有什么建议
指出了一些问题 软件工程科班的计算机基础这块儿再多看看;对于技术中间件的使用要多看看实现原理 多看看源码,要知道为什么用,为什么用它而不用别的
.你觉得这个项目你遇到的最大的难点是什么 怎么解决的
栓q 都忘了啊啊啊
反问环节:问的面试官对我之后的学习有没有什么建议
指出了一些问题 软件工程科班的计算机基础这块儿再多看看;对于技术中间件的使用要多看看实现原理 多看看源码,要知道为什么用,为什么用它而不用别的
投的晚,这是暑期实习的第一次面试,好紧张,面试官人很好,给的建议很中肯,确实还有很多要背的,算法加油啊啊啊

















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









