







ElasticSearch基础及面经
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
一、ElasticSearch vs Solr
es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式
4、Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
- ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、Solr 比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch 相对开发维护者较少,更新太快,学习使用成本较高。
所以如果我们在做技术选型的时候,具体选择哪一项技术,还需要根据不同的场景来进行结合选择。
二、基础概念
1.倒排索引
-
正向索引
那么什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:
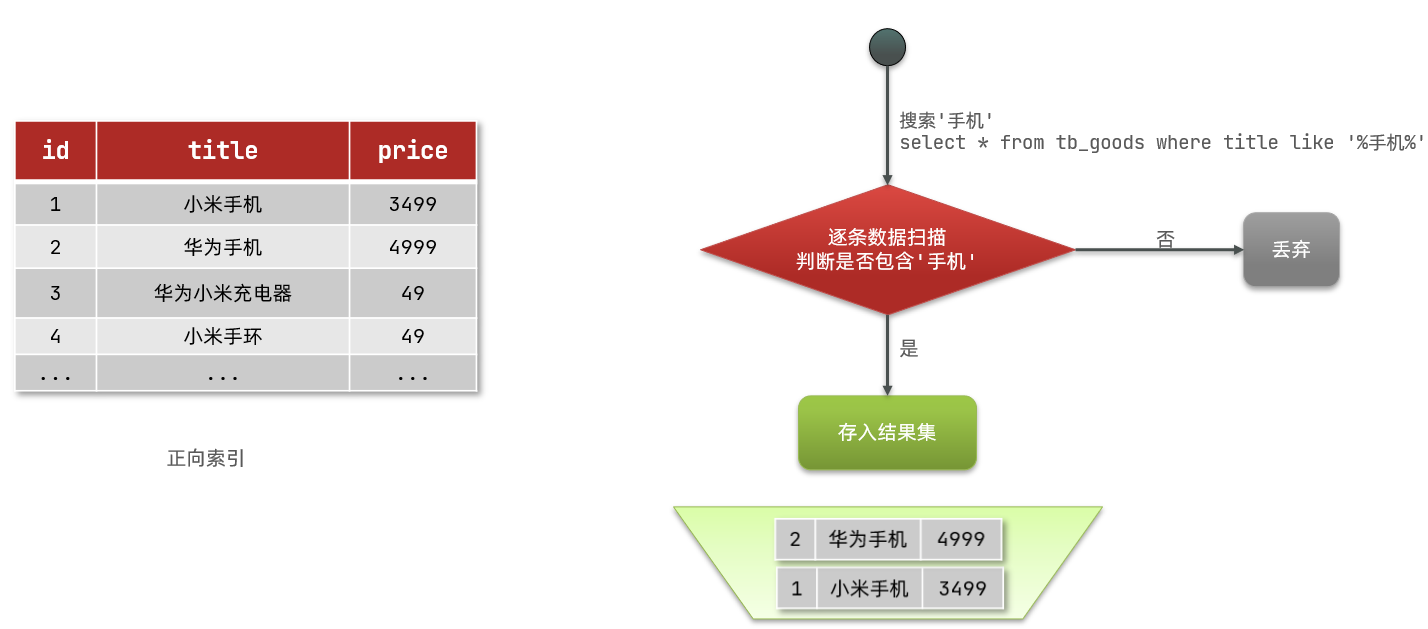
如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合
"%手机%"2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
-
倒排索引
elasticsearch 使用的是一种称为
倒排索引的结构,采用Lucene倒排索引作为底层。这种结构适用于快速的全文搜索, 一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:

倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件
"华为手机"进行搜索。2)对用户输入内容分词,得到词条:
华为、手机。3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图:
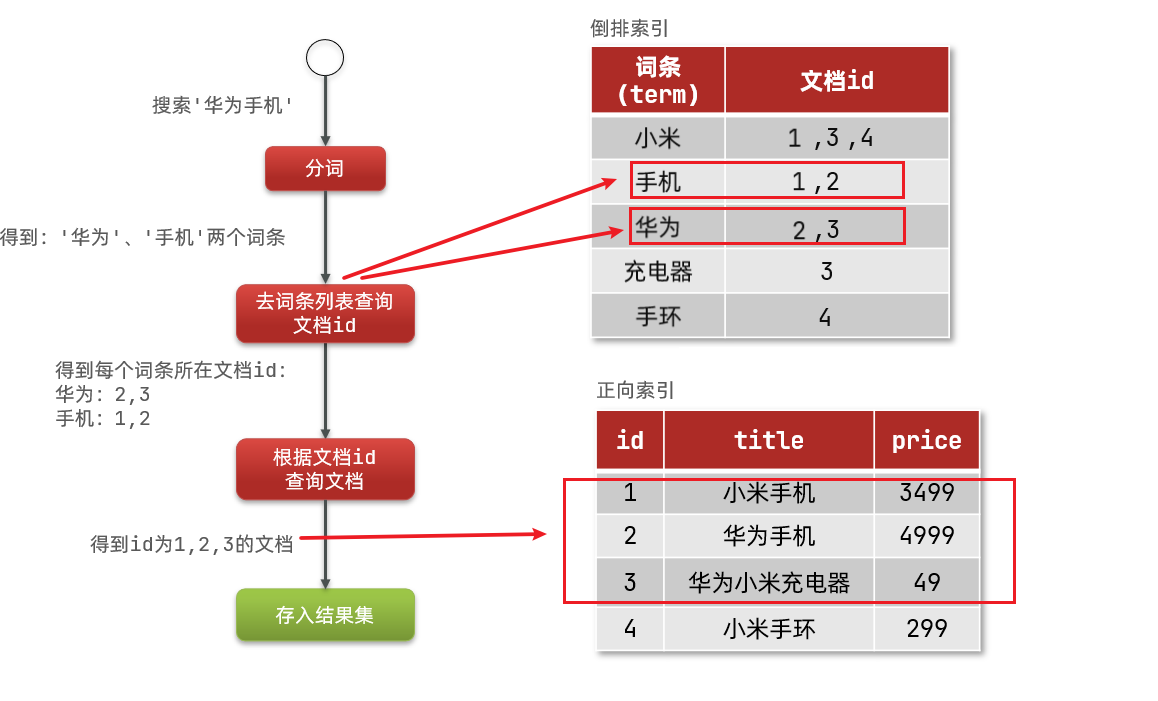
虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
- 文档(
-
正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
-
2.基础概念
| ES | 关系型数据库 |
|---|---|
| 索引(Index) | 数据库(DataBase) |
| 类型(Type) | 表(Table) |
| 映射(mapping) | 表结构(Schema) |
| 文档(Document) | 行(Row) |
| 字段(Field) | 列(Column) |
| 反向索引 | 正向索引 |
| DSL查询 | SQL查询 |
是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
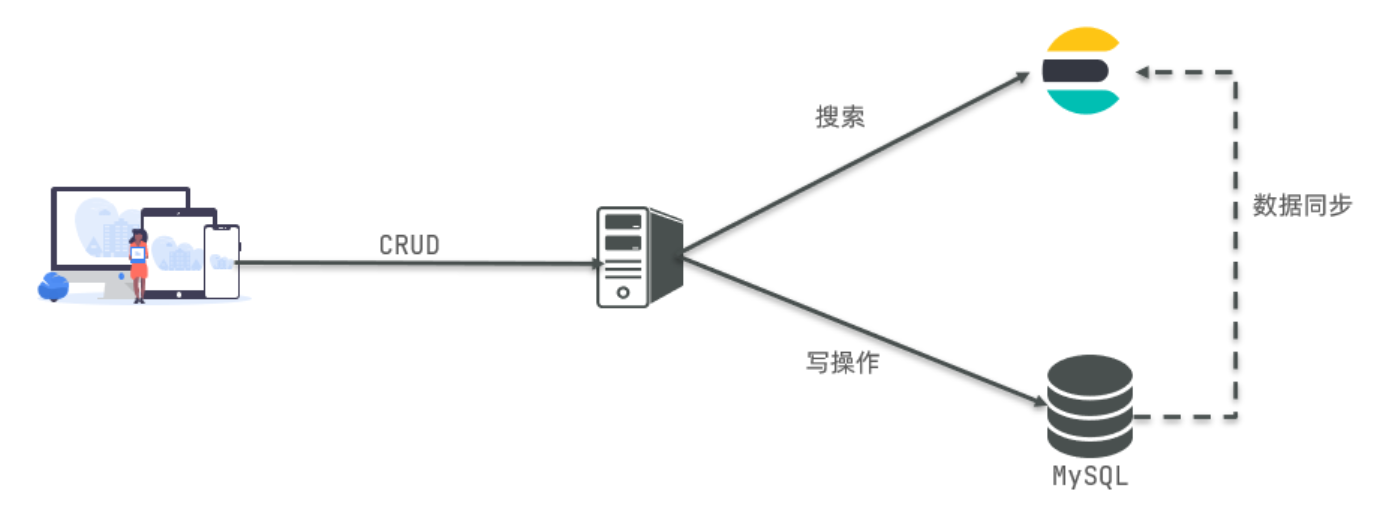
因此在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性
3.字段类型
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
4.基础操作
-
索引库操作
-
创建索引库:PUT /索引库名
-
查询索引库:GET /索引库名
-
删除索引库:DELETE /索引库名
-
添加字段:PUT /索引库名/_mapping
-
-
文档操作
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 增量修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}
-
RestAPI
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxIndexRequest。XXX是Create、Get、Delete
- 准备DSL( Create时需要,其它是无参)
- 发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
-
RestClient
文档操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxRequest。XXX是Index、Get、Update、Delete、Bulk
- 准备参数(Index、Update、Bulk时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 解析结果(Get时需要)
三、原理
1. Lucence存储和检索
这部分主要对Lucence的存储和查询过程进行简要的描述。针对Lucence的存储和查询过程如下图所示。
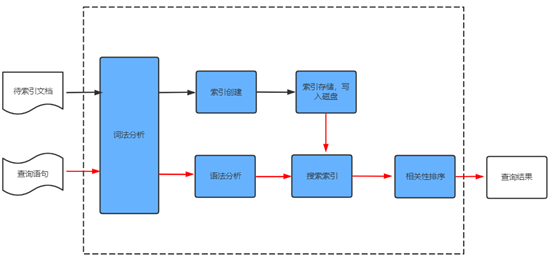
ES简要原理
存储过程:
- 存储文档经过词法分析得到一系列的词(Term)
- 通过一系列词来创建形成词典和反向索引表
- 将索引进行存储并写入硬盘。
查询过程:
a) 用户输入查询语句。
b) 对查询语句经过词法分析得到一系列词(Term) 。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term) 的文档链表,对文档链表进行交、差、并得到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。
2.ES写数据
ES写数据包含两种情况,分别为写入一个新的文档和在原有文档的基础上进行数据的追加(覆盖原有的文档)。两者基本上没有什么区别,后者是把原来的文档进行删除,再重新写入。
ES写数据流程:
(1) 客户端选择一个ES节点发送写请求,ES节点接收请求变为协调节点。
(2) 协调节点判断写请求中如果没有指定文档id,则自动生成一个doc_id。协调节点对doc_id进行哈希取值,判断出文档应存储在哪个切片中。协调节点找到存储切片的对应节点位置,将请求转发给对应的node节点。
(3) Node节点的primary shard处理请求,并将数据同步到replica shard
(4) 协调节点发现所有的primary shard和所有的replica shard都处理完之后,就返回结果给客户端。
ES写数据底层原理:
(1) 数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到操作系统缓存(os cache),生成新的segment。(os cache 中存储的数据能被搜索到)
(2) 写入 os cache 中的translog数据,默认每隔 5 秒刷一次到磁盘中去,如果translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
3.ES读数据
ES读数据是通过doc_id来进行查询,先根据doc_id判断出文档存储在哪个切片上,再从切片上把数据读取过来。
ES读数据流程:
(1) 客户端给任意一个节点发送请求,该节点变为协调节点
(2) 协调节点根据doc_id,进行哈希取值,判断出文档存储在哪个切片上。
(3) 协调节点将请求转发到对应的节点上,然后使用随机轮询算法(round-robin),在切片和副本切片中随机选择一个,以使读请求负载均衡
(4) 接收请求的节点返回文档数据给协调节点,协调节点再返回数据给客户端。
4.ES检索关键词
ES检索关键词流程:
ES检索关键词是ES最常使用的做法,通过关键词,将包含关键词的文档全部搜索出来。
(1) 客户端向任意一个节点发送请求,该节点变为协调节点
(2) 协调节点将搜索请求转到所有的shard上
(3) 每个shard将自身的检索结果(搜索到的doc_id和分数),返回给协调节点。
(4) 协调节点根据检索结果进行相关性排序,产出最终的结果。再把doc_id发送给各个节点,拉取文档数据,最终返回给客户端。
5.ES删数据
删除数据底层原理:
删除操作,是在commit 的时候会生成一个.del文件,里面将doc标识为deleted状态,搜索的时候根据.del文件就知道这个 doc 是否被删除了。
四、面试题分享
1.Elasticsearch是如何实现Master选举的?
Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;
对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
补充:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
2.Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
当集群master候选数量不小于3个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
当候选数量为两个时,只能修改为唯一的一个master候选,其他作为data节点,避免脑裂问题。
3.详细描述一下Elasticsearch索引文档的过程。
协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片。
shard = hash(document_id) % (num_of_primary_shards)
当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh;
当然在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush;
在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。
flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时;
4.详细描述一下Elasticsearch更新和删除文档的过程
删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更;
磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段。
在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
5.详细描述一下Elasticsearch搜索的过程
搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
补充:Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
6..Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关 .
7.在并发情况下,Elasticsearch如果保证读写一致?
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
与你配置的精确度相关 .
7.在并发情况下,Elasticsearch如果保证读写一致?
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









