






1. 实验目的
通过构建前馈神经网络结构、复现基于神经网络的依存分析模型,复习理论课内容,加强对神经网络用于文本特征编码的理解与应用。
2. 实验平台
操作系统:Windows 2000/ XP/7/8/10/11 或者 Linux
深度学习框架:pytorch、tensorflow、keras等
3. 实验内容
(1) 描述以下代码内容,并解释为什么不需要写backward()
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
(2)使用Python中的stanfordcorenlp库,对句子“Summer is often favored for its long, sunny days”,进行依存分析。
【1】给出导入stanfordcorenlp和测试的代码截图,
【2】以及控制台输出结果截图。并对分析结果进行评价。
(3)参考A Fast and Accurate Dependency Parser using Neural Networks,使用包含2个隐藏层的神经网络,实现transition-based依存解析中每一步transition在unlabeled设置下的预测。输入层使用的特征见课件P60-61的词语特征和词性特征。隐藏层可以使用Relu或者立方激活函数,即h=Relu(Wx+b)或者h=(Wx +b)3。输出层选择softmax单元,即y
=softmax(Uh’+b)。权重和偏置参数使用随机初始化。损失函数选择交叉熵。
- 实验数据:中文依存语义测评数据(见群文件)。
- 词向量:预训练的300维词向量(见群文件),如果语料中出现找不到的词语使用随机向量代替。词性向量和依存关系标签向量随机初始化300维。
- 参考代码:GitHub - akjindal53244/dependency_parsing_tf: Tensorflow implementation of "A Fast and Accurate Dependency Parser using Neural Networks"(tensorflow)
【1】分析模型每一层结构、参数设置。
【2】给出训练过程截图。
【3】给出测试集的准确率统计,并随机抽取2个测试集样本,展示模型预测结果,按照课件P64给出每一步骤的对比。
4. 要求
(1)独立完成,严禁抄袭(抄袭和被抄袭均判为0分)。
(2)实验报告排版合理,内容详实,必要时配过程截图。
(3)在规定时间范围内提交,否则判为0分。
一、实验环境
操作系统:Windows 2000/ XP/7/8/10/11 或者 Linux
深度学习框架:pytorch
二、实验内容及详细的完成情况
2.1 实验一
(1)
- class NeuralNetwork(nn.Module): #继承父类nn.Module
- def __init__(self):
- super().__init__() #调用了父类的构造函数
- #创建了一个用于将输入张量展平的模块(n维变1维)
- self.flatten = nn.Flatten()
- self.linear_relu_stack = nn.Sequential( #顺序执行以下操作
- nn.Linear(28*28, 512), #线性全连接
- nn.ReLU(), #Relu激活函数
- nn.Linear(512, 512),
- nn.ReLU(),
- nn.Linear(512, 10),
- )
- def forward(self, x): #前向传播
- x = self.flatten(x) #将输入张量展平
- logits = self.linear_relu_stack(x)
- return logits
(2)因为该代码使用了PyTorch框架,并且继承了 nn.Module 类。PyTorch框架提供了自动求导(autograd)的功能,因此在定义了模型结构和前向传播过程后,PyTorch可以自动计算梯度并执行反向传播,无需手动编写 backward() 方法。
2.2 实验二
(1)下载stanford-corenlp-full 和 对应的中文包,放置同一根目录下。
(2)安装stanfordcorenlp库
(3)测试代码

(4)结果展示

(5)依存分析
在依存分析中,三元组中的每个元素表示的含义如下:
第一个元素:依存关系类型
表示当前词语与其依赖词语之间的语法关系类型,比如主谓关系、修饰关系等。
第二个元素:依赖词语的索引
表示当前词语依赖的词语在句子中的索引位置,通常从1开始计数。
第三个元素:当前词语的索引
表示当前词语在句子中的索引位置,通常从1开始计数。
在自然语言处理中,依存分析可以产生多种语法关系类型,常见的一些语法关系类型包括但不限于以下几种:
主谓关系(nsubj):表示主语与动词之间的关系,主语是动作的执行者。
宾语关系(dobj):表示动词的直接宾语,接受动作的影响。
间接宾语关系(iobj):表示动词的间接宾语,通常是动作的受益者或者受影响的对象。
定语关系(amod):表示修饰词与被修饰词之间的关系,通常是形容词修饰名词。
名词修饰关系(nn):表示名词与被修饰名词之间的关系,通常是名词作为另一个名词的修饰语。
状语关系(advmod):表示副词修饰动词或形容词的关系,用来表示时间、地点、方式等。
介词修饰关系(prep):表示介词短语修饰名词或动词的关系,通常表示位置、方向、目的等。
从属关系(dep):表示一个词语依赖于另一个词语,但具体的依存关系类型不明确。
主题关系(topic):表示句子的主题或者焦点。
根节点(ROOT):表示句子的核心动词或状态,是整个句子的根节点。
('ROOT', 0, 4):根节点是句子的核心动词 "favored"。
('nsubjpass', 4, 1):主语被动式关系,表示 "Summer" 是动词 "favored" 的主语。
('auxpass', 4, 2):被动语态助动词 "is",帮助构成被动语态。
('advmod', 4, 3):副词修饰关系,表示 "often" 是动词 "favored" 的副词修饰语。
('case', 10, 5):介词短语 "for its long, sunny days" 与动词 "favored" 之间的关系。
('nmod:poss', 10, 6):名词修饰关系,表示 "its" 修饰 "days"。
('amod', 10, 7):形容词修饰关系,表示 "long" 修饰 "days"。
('punct', 10, 8):标点符号 "," 与其前面的词之间的关系。
('amod', 10, 9):形容词修饰关系,表示 "sunny" 修饰 "days"。
('nmod', 4, 10):名词修饰关系,表示介词短语 "for its long, sunny days" 是动词 "favored" 的修饰语。
2.3实验三
(1) 模型结构
- def add_prediction_op(self):
- x = self.add_embedding()
- init = xavier_weight_init()
- with tf.variable_scope("transformation"):
- b1 = tf.Variable(tf.zeros([self.config.hidden_size]))
- b2 = tf.Variable(tf.zeros([self.config.hidden_size])) # 与隐藏层输出维度相同
- self.W1 = init([self.config.n_features * self.config.embed_size, self.config.hidden_size])
- self.W2 = init([self.config.hidden_size, self.config.hidden_size]) # 新增的隐藏层权重
- U = init([self.config.hidden_size, self.config.n_classes])
- h1 = tf.nn.relu(tf.matmul(x, self.W1) + b1)
- h1_drop = tf.nn.dropout(h1, 1 - self.dropout_placeholder)
- # 新增的隐藏层
- h2 = tf.nn.relu(tf.matmul(h1_drop, self.W2) + b2)
- h2_drop = tf.nn.dropout(h2, 1 - self.dropout_placeholder)
- pred = tf.matmul(h2_drop, U)
- return pred
- def add_loss_op(self, pred):
- loss = tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=self.labels_placeholder)
- # 添加新隐藏层的权重参数到 L2 正则化项
- l2_loss = self.config.l2_rate * (tf.nn.l2_loss(self.W1) + tf.nn.l2_loss(self.W2))
- # 总损失为交叉熵损失加上 L2 正则化项
- total_loss = tf.reduce_mean(loss + l2_loss)
- return total_loss
1.add_prediction_op 函数:
首先,通过调用 add_embedding 方法添加了嵌入层。
使用 xavier_weight_init 初始化器初始化权重。
在变量作用域 "transformation" 下定义了两个偏置项 b1 和 b2,维度与隐藏层输出的维度相同。
定义了两个权重矩阵 self.W1 和 self.W2,分别表示第一个隐藏层和新增的第二个隐藏层的权重。这里的隐藏层维度由配置文件中的 hidden_size 决定。
使用 ReLU 激活函数对隐藏层进行非线性变换,并通过 dropout 机制进行正则化。
最后通过矩阵乘法将最后一个隐藏层的输出与输出层的权重 U 相乘得到预测结果 pred。
2.add_loss_op 函数:
使用 softmax_cross_entropy_with_logits 函数计算预测值 pred 和真实标签 labels_placeholder 之间的交叉熵损失。
添加了 L2 正则化项,将隐藏层的权重参数 self.W1 和 self.W2 的 L2 范数加入到总损失中,并乘以配置文件中的 l2_rate 控制正则化的强度。
最终的总损失为交叉熵损失加上 L2 正则化项的均值。
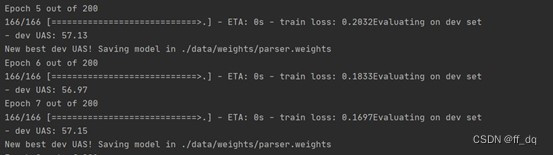
(2)训练过程截图
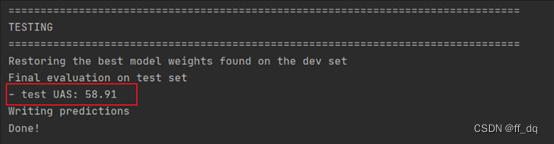
(3)测试集的准确率统计
(4)随机抽取2个测试集样本,展示模型预测结果,按照课件P64给出每一步骤的对比。
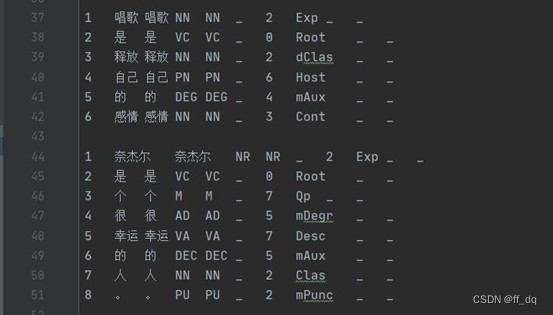
图 1 真实依存关系(测试集)

图 2 预测依存关系
第一个测试样本,4个依存关系正确,正确率4/6 = 67%
第二个测试样本,8个依存关系均正确,正确率100%
三、实验总结
(可以总结实验中出现的问题以及解决的思路,也可以列出没有解决的问题)
1.在安装stanford-corenlp时出现了很多问题
正常分词是可以使用的,但当我尝试中文分词时,总是报错:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
经查询了解,stanford-corenlp文件需要和pycharm中安装的stanfordcorenlp库版本相同,且中文包需要和full文件版本一样,最后可以成功运行
2.一开始添加隐藏层后正确率只有50%左右,与没加隐藏层之前没什么区别。后来发现添加隐藏层后损失函数也要做对应修改,使得两个隐藏层的参数都能够及时更新。















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









