






缺失值处理

过程中出现以下报错
cannot import name ‘Imputer’ from ‘sklearn.preprocessing’
原因是由于python版本和sklearn版本不对等。
解决方法:
from sklearn.impute import SimpleImputer as Imputer
def im():
#缺失值处理
im=Imputer(missing_values=np.nan,strategy='mean')
#mean是平均值的意思
data=im.fit_transform([[2.0,3.0],[np.nan,6.0],[3.1,7.6]])
print(data)
im()
运行结果:
[[2. 3. ]
[2.55 6. ]
[3.1 7.6 ]]
注:missing_values后的参数不能为NaN,只能使用np.nan
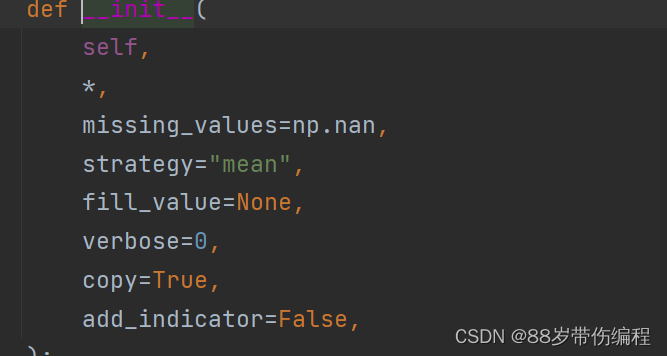
api参数列表:
数据降维之特征选择
特征选择的原因:

特征选择的三大方法:

过滤式:对方差进行过滤(方差var=0,表示某特征一列数据都一样,也就是说,这个特征对于预测没意义,所以通过方差来对特征进行一个选择)。
from sklearn.feature_selection import VarianceThreshold
def var():
#特征选择--删除低方差的特征
var=VarianceThreshold(threshold=0.0) #删除方差等于0的特征,也就是数据一样的特征
data=var.fit_transform([[0,2,3],[0,2,4],[0,1,6]])
print(data)
var()
运行结果:
[[2 3]
[2 4]
[1 6]]
其他特征过滤方法:神经网络。
PCA(主成分分析)

将高维的数据简化为低维的数据

from sklearn.decomposition import PCA
def pca():
#主成分分析
pca=PCA(n_components=0.9)
data=pca.fit_transform([[0,2,3,7],[0,2,4,8],[0,1,6,11]])
print(data)
pca()
运行结果:
[[-2.15470054]
[-0.78867513]
[ 2.94337567]]
#变成了一个特征
案例


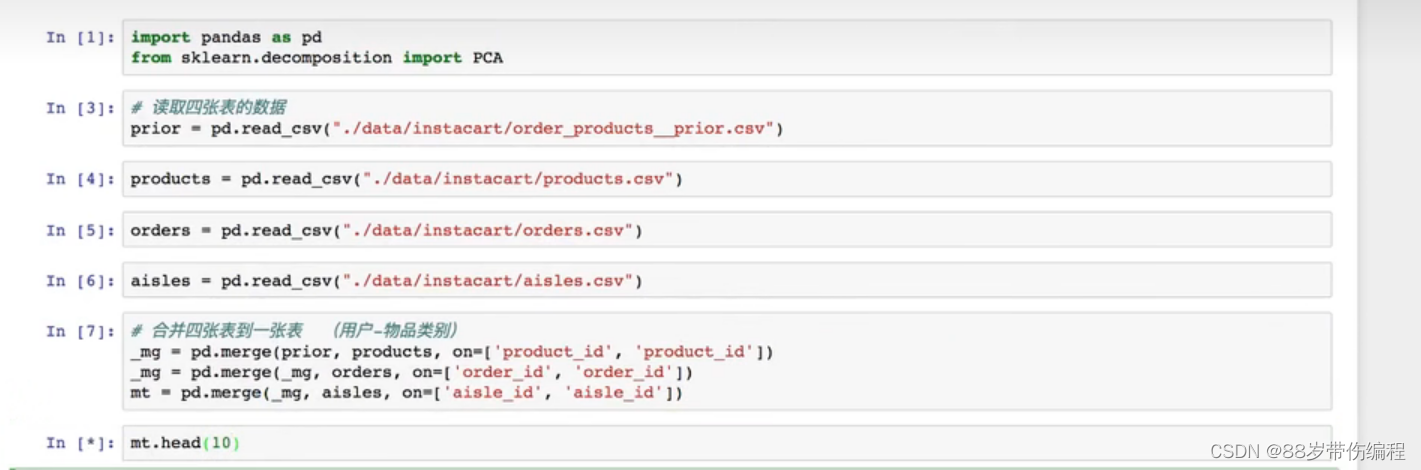
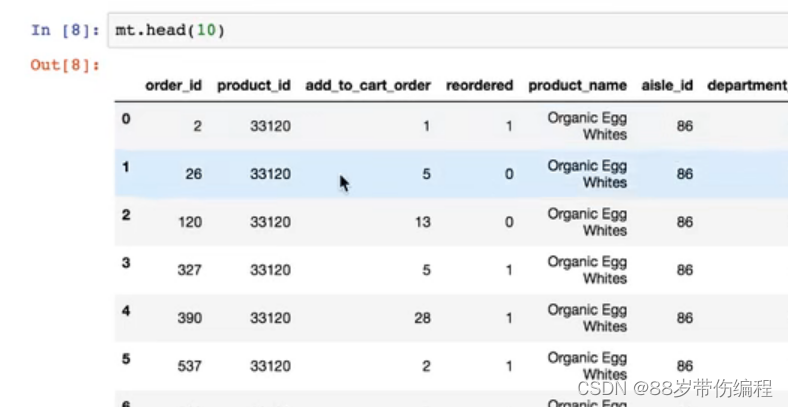
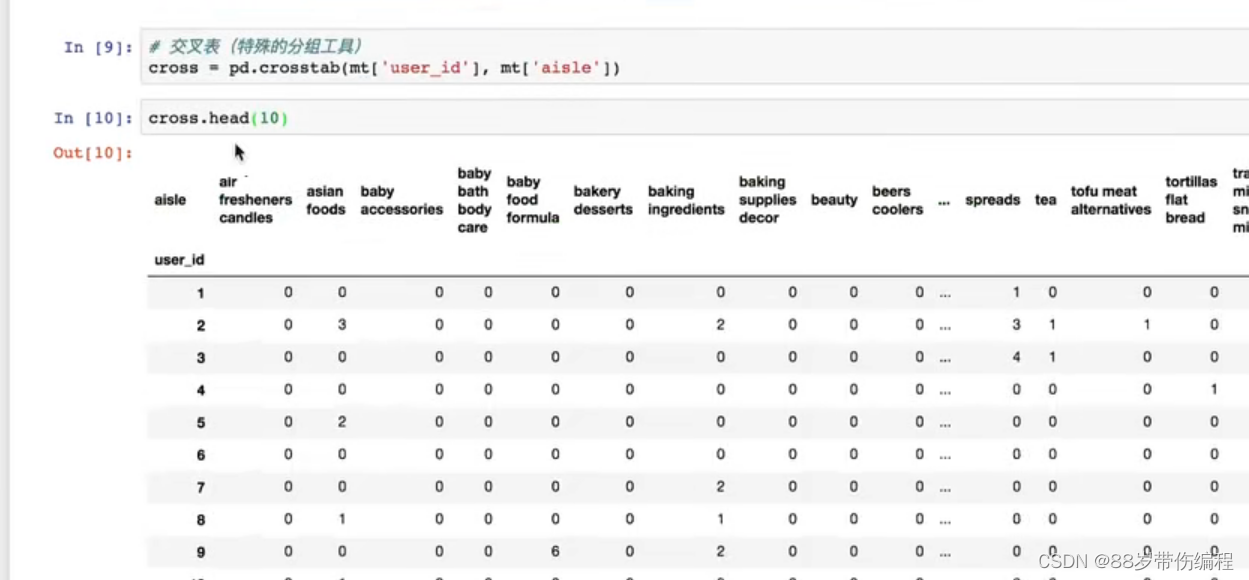
pd.merge() #合并表的数据
pd.crosstab() #传两个参数,指定行,指定列















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









