






目录
轻量级锁
“轻量级” 是相对于使用操作系统互斥量来实现的传统锁而言的,因此传统的锁机制就被称为“重量级”锁,它的设计初衷是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
首先我们要了解JVM(这里值HotSpot JVM) 中对象头的内存布局。JVM 把对象头分为两部分,第一部分是Mark Word,存储了哈希码(HashCode)、GC分代年龄等。另一部分用于存储指向方法区对象数据类型的指针。Mark Word他是实现轻量级锁和偏向锁的关键。
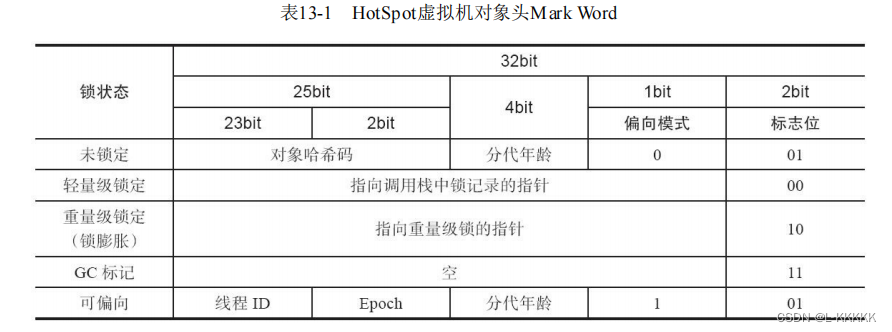
轻量级锁的工作流程
在代码即将进入同步块的时候,如果此同步对象没有被锁定(锁标志位为“01”状态),虚拟机首先在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象的Mark Word的拷贝。
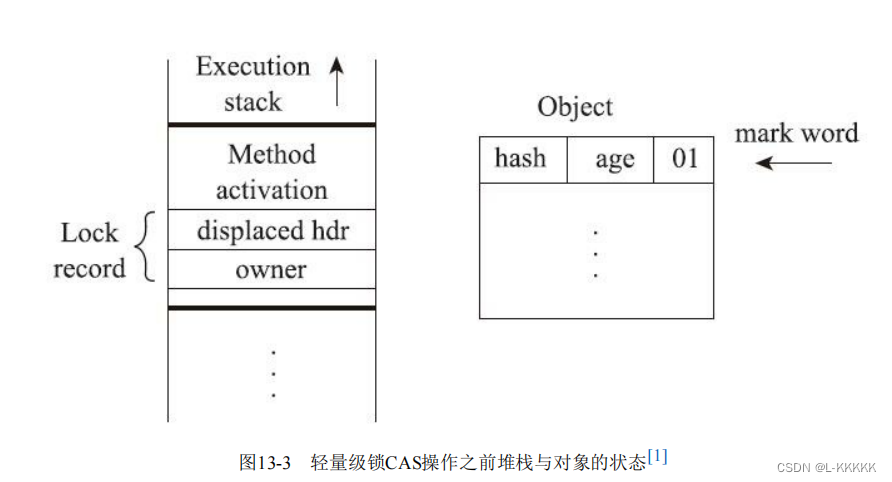
然后,虚拟机将使用CAS操作尝试把对象的Mark Word更新为指向Lock Record的指针。如果CAS成功,那么表示该线程拥有了这个对象的锁,并且将Mark Word 的锁标志位转变为“00”,表示此对象处于轻量级锁定状态。
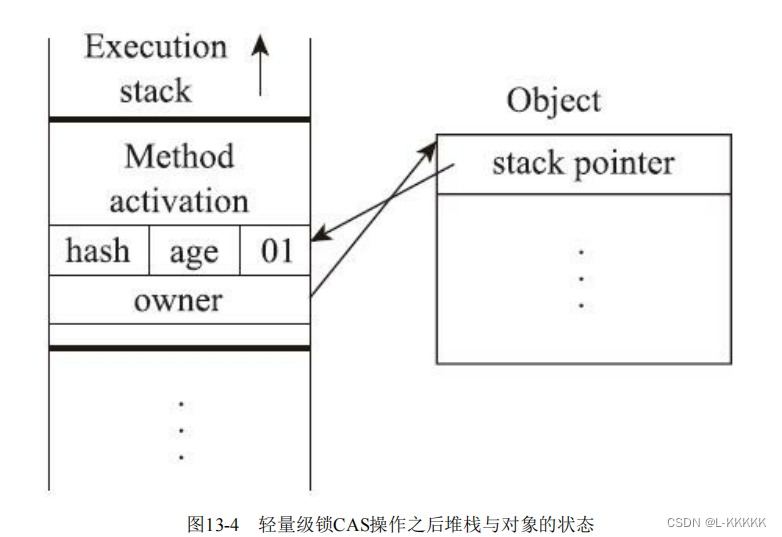
如果CAS失败,Mark Word 中已经有了指向锁记录的指针,有两种情况:
一:Mark Word中的指针指向的是当前线程的锁记录,表示发生了轻量级锁重入。这时JVM就会再创建一个锁记录,只不过这个所记录不会记录Mark Word的拷贝,会指向null,表示一次锁重入计数。
二:Mark Word中的指针指向的不是当前线程的锁记录,这时说明发生了锁竞争,那轻量级锁就不再有效,必须要膨胀为重量级锁,锁标志转变为“10”,此时Mark Word 就不再存储锁记录的指针了,而是存储重量级锁互斥量(monitor对象)的指针了。
轻量级锁的解锁
同样是用CAS来实现的,用锁记录中保存的原Mark Word的值来替换(恢复)当前Mark Word中的值。
轻量级锁能提升同步性能的依据是“对于绝大多数的锁,在整个同步周期内都是不存在竞争的”这一经验法则。如果没有竞争,那么轻量级锁就避免了使用互斥量的开销;但如果存在锁竞争,那么除了互斥量的开销外,还额外发生了CAS的开销。因此再有竞争的情况下,轻量级锁反而回避重量级锁更慢。
偏向锁
顾名思义,他的意思是这个锁会偏向与第一个获得他的线程。
偏向锁的流程
若JVM 启用了偏向锁,那么当锁对象第一次被线程获取的时候,JVM 将会把对象头的标志位设为“01”,并把偏向模式设置为“1”,表示进入偏向模式。同时使用CAS把获得这个锁的线程ID记录再Mark Word(Mark Word的hashCode位置)中。如果成功,那么持有偏向锁的线程每次进入的这个锁的同步块的时候,将不再进行任何操作(例如锁重入、解锁、更新Mark Word等)
注意:当一个对象已经计算过一致性哈希码后,那么它就再也无法进入偏向锁状态了;而当一个对象当前正处于偏向锁状态,又收到计算哈希码的请求之后,偏向锁会立即膨胀为重量级锁。因为在重量级锁的ObjectMonitor类中有字段可以记录原来的(非加锁)Mark Word,其中自然可以存储原来的哈希码。
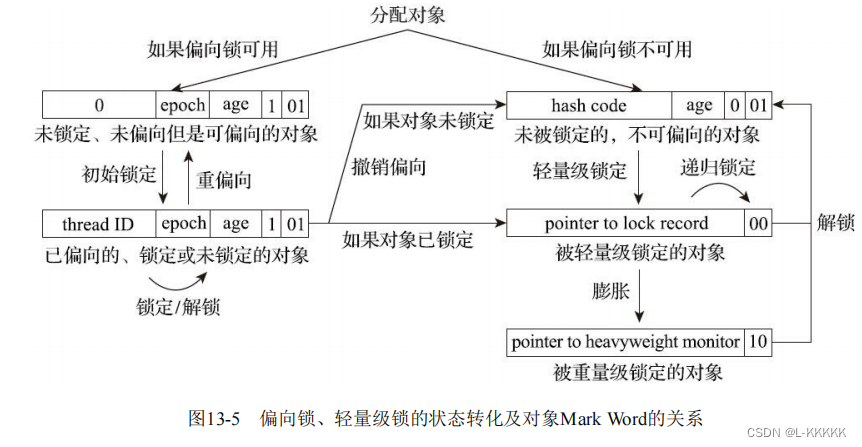
偏向锁和轻量级锁机区别
偏向锁在轻量级锁的基础上进一步提升了性能。轻量级锁在无竞争的情况下对于每次的加锁请求都使用CAS来避免了互斥量的使用,而偏向锁就是在无竞争的情况下连CAS都不用做了(只是在线程第一次获取偏向锁的时候使用了CAS),通过判断Mark Word中的ThreadID是不是当前线程即可,如不是,则进行重偏向即可。
其他优化
自旋锁和自适应自旋锁
使用互斥同步来解决线程安全问题时,其中对性能产生很大影响的就是线程阻塞带来的线程上下文文切换,挂起线程和恢复线程都要转入内核态来完成。所以就有了自旋锁的优化:如果物理机器上有多个处理器或处理器多个核心的话,若当前线程第一次获取锁失败,并不会立马进入阻塞,而是会再尝试获取锁几次,我们会让线程执行一个忙循环(自旋)。自适应自选也就是不固定自旋的时间。
锁消除
锁消除的判断依据主要来源于数据的逃逸分析,如果判断到一段代码中,在堆上的数据都不会逃逸出去被其他线程访问到,那么这些数据就可以当作栈上的数据对待,认为他们是线程私有的,这时就没有必要再加锁了。
锁粗化
我们通常加锁的时候尽量让同步块中的代码尽可能的少,在存在锁竞争的情况下,可以尽快的拿到锁。但锁的粒度过小的话,有可能出现对同一个对象反复加锁和解锁,甚至加锁操作是在循环体中,这样就导致了很大的性能消耗。类似于这种情况,JVM 就会扩展(粗化)锁的范围。
一些看起来没有加锁的代码,其实隐式的加了很多锁:
public static String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
}javap 生成字节码
public static java.lang.String concatString(java.lang.String, java.lang.String, java.lang.String);
descriptor: (Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=3
0: new #2 // class java/lang/StringBuilder
3: dup
4: invokespecial #3 // Method java/lang/StringBuilder."<init>":()V
7: aload_0
8: invokevirtual #4 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
11: aload_1
12: invokevirtual #4 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
15: aload_2
16: invokevirtual #4 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
19: invokevirtual #5 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
22: areturnString 是一个不可变的类,编译器会对 String 的拼接自动优化。在 JDK 1.5 之前,转化为 StringBuffer 对象的连续 append() 操作,每个 append() 方法中都有一个同步块。反编译后如下:
public static String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}扩展到第一个 append() 操作之前直至最后一个 append() 操作之后,只需要加锁一次就可以。















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









