







本系列是算法通关手册LeeCode的学习笔记
算法通关手册(LeetCode) | 算法通关手册(LeetCode) (itcharge.cn)
本系列为自用笔记,如有版权问题,请私聊我删除。
目录
一,队列(Queue)
一种线性表结构,只允许在表的一端进行插入操作,而在另一端进行删除操作的线性表。
把允许插入的一端叫 队尾 rear ,允许删除的一端叫 队头 front
队列有插入和删除两种基本操作。
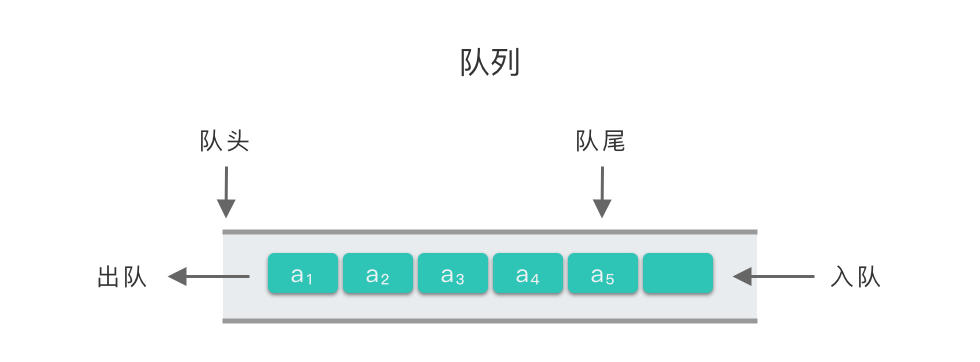
队列是一种【先进先出】的线性表(First In First Out, FIFO)
队列的顺序存储
在队列的顺序存储中,使用循环队列可以节省空间,因此本篇仅介绍循环队列的实现:
首先简单介绍队列

在上述实现中,如果队列中第 0 ~ size - 1位置均被队列元素占用时,此时队列已满,而由于出队总是删除队头元素,入队只在队尾插入,因此当队尾指针满足 self.rear == self.size - 1 条件时,此时再入队便会抛出队列已满的异常,而之前因为出队操作而产生的空余位置也没有利用上,这就造成了假溢出的问题。
循环队列
在进行插入操作时,如果队列的第 self.size - 1 个位置被占用之后,只要队列前面还有可用空间,新的元素加入队列时就可以从第 0 个位置开始继续插入。
我们约定: self.size 为循环队列的最大元素个数。队头指针 self.front 指向队头元素所在位置的前一个位置,而队尾指针 self.rear 指向队尾元素所在的位置。即
入队时,队尾指针循环前进一个位置,self.rear = (self.rear + 1) mod self.size
出队时,队头指针循环前进一个位置,self.front = (self.front + 1) mod self.size
注意,循环队列在一开始初始化,队列为空时,满足条件 self.front == self.rear
充满队列后,仍满足该 self.front == self.rear,此时无法判断队列为空还是队列为满。
基于以上情况,有多种处理方式:
方式1,增加队列中元素个数变量 self.count,用以区分队列已满还是队列为空,在入队出队时,更新 self.count 的值。
方式2,增加标记变量 self.tag,用来区分队列已满还是队列为空:
self.tag == 1 的情况下,因入队导致 self.front == self.rear,说明队列为满;
self.tag == 0 的情况下,因出队导致 self.front == self.rear,说明队列为空;
方式3,特意空出来一个位置,用于区分队列已满还是队列为空。入队时,少用一个队列单元,即约定以【队头指针在队尾的下一个位置】作为队满的标志。
队头指针在队尾指针的下一个位置 (self,rear + 1) mod self.size == self.front,队列已满
队头指针等于队尾指针,self.front == self.rear,队列为空。
以下用方式3 说明:

我们约定,self.size 为循环队列的最大元素个数。队头指针 self.front 指向队头元素所在位置的前一个位置,而队尾指针 self.rear 指向队尾元素所在位置。
初始化空队列:创建一个空队列,定义队列的大小为 self.size + 1。
令队头指针 self.front 和队尾指针 self.rear 都指向 0。self.front = self.rear = 0;
判断队列是否为空:根据 self.front 和 self.rear 的位置进行判断,根据约定,如果队头指针和队尾指针相等,则队列为空,否则队列不为空。
判断队列是否已满:队头指针在队尾指针的下一个位置,
即 ( self.rear + 1 ) mod self.size == self.front,则说明队列已满,否则队列未满。
入队:先判断队列是否已满,已满则抛出异常。不满则将队尾指针 self.rear 向右循环移动一位,并进行赋值操作。此时 self.rear 指向队尾元素。
出队:先判断队列是否为空,为空则抛出异常。不为空则将头指针 self.front 向右循环移动一位,将该位置的元素保存后,将该位置赋值为 None ,并返回先前保存的元素,此时 self.front 指向队头的元素的前一个位置。
获取队头元素:队列不为空,因为队头指针指向队头元素所在位置的前一个位置,所以返回
return self.queue[ (self.front + 1) mod self.size]
获取队尾元素:队列不为空,因为队尾指针指向队尾元素所在位置,所以直接返回
return self.queue[ self.rear]
代码实现:
class Queue:
# 初始化队列
def __init__(self, size = 100):
self.size = size + 1
self.queue = [None for _ in range(size + 1)]
self.front = 0
self.rear = 0
# 判断队列是否为空
def isEmpty(self):
return self.front == self.rear
# 判断队列是否已满
def isFull(self):
return (self.rear + 1) % self.size == self.front
# 入队
def enqueue(self, value):
if self.isFull():
raise Exception('Queue is full.')
else:
self.rear = (self.rear + 1) % self.size
self.queue[self.rear] = value
# 出队
def dequeue(self):
if self.isEmpty():
raise Exception('Queue is empty.')
else:
self.front = (self.front + 1) % self.size
res = self.queue[self.front]
self.queue[self.front] = None
return res
# 获取队头元素:
def frontValue(self):
if self.isEmpty():
raise Exception('Queue is empty.')
else:
value = self.queue[self.front + 1]
return value
# 获取队尾元素
def rearValue(self):
if self.isEmpty():
raise Exception('Queue is empty.')
else:
value = self.queue[self.rear]
return value
队列的链式存储
对于在使用过程中频繁进行插入删除的数据结构来说,采用链式存储更合适。
用一个线性链表来表示队列,队列中的每一个元素对应链表中的一个链节点。
把线性链表的第一个节点定义为队头指针 front,在链表最后的链节点建立指针 rear 作为队尾指针。
限定只能在链表的队头进行删除操作,在链表队尾进行插入操作。
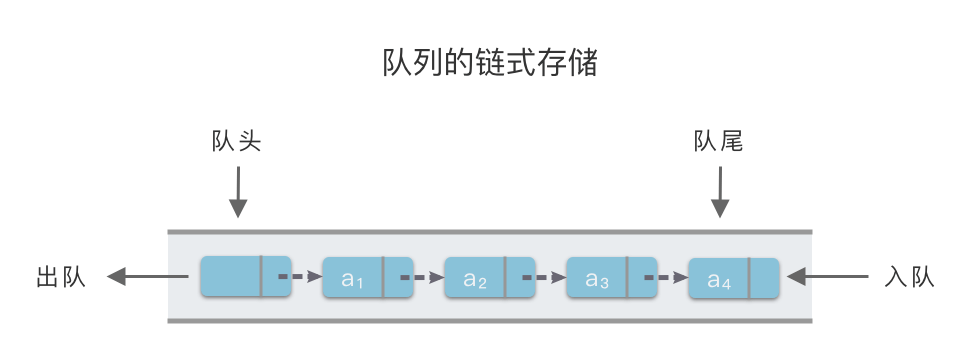
我们约定,队头指针 self.front 指向队头元素所在位置的前一个位置,而队尾指针 self.rear 指向队尾元数所在位置。
实现代码:
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
class Queue:
# 初始化空队列
def __init__(self):
head = Node()
self.front = head
self.rear = head
# 判断队列是否为空
def isEmpty(self):
return self.front == self.rear
# 入队
def enqueue(self, value):
node = Node(value)
self.rear.next = node
self.rear = node
# 出队
def dequeue(self):
if self.isEmpty():
raise Exception('Queue is empty.')
else:
node = self.front.next
self.front.next = node.next
if self.rear == node: # 如果队列中只有一个元素
# 此时 rear 指向的最后一个链节点已经删除,将队列恢复为初始情况
self.rear = self.front
value = node.value
del node
return value
# 获取队头元素
def frontValue(self):
if self.isEmpty():
raise Exception('Queue is empty.')
else:
return self.front.next.value
# 获取队尾元素
def rearValue(self):
if self.isEmpty():
raise Exception('Queue is empty.')
else:
return self.rear.value二,优先队列(Priority Queue)
一种特殊的队列,优先队列中,元素被赋予优先级,当访问队列元素是,具有最高优先级的元素最先删除。优先队列与普通队列最大的不同点在于出队顺序。
优先队列的出队顺序跟入队顺序无关,按照元素的优先级来决定出队顺序的。

优先队列的实现方式
构建一个二叉堆结构,二叉堆结构按照优先级进行排序。入队操作就是将元素插入到二叉堆中合适位置。出队操作取出优先级最高的元素。
先前在堆排序中使用二叉堆,简单来说,二叉堆是符合以下两个条件之一的完全二叉树:
大顶堆:根节点值 >= 子节点值
小顶堆:根节点值 <= 子节点值
二叉树主要涉及两个基本操作,即【堆的调整方法】和【将数组构建为二叉堆方法】
堆调整方法 heapAdjust :把移走了最大值元素以后的剩余元素组成的序列再构造为一
个新的堆积:
1,从根节点开始,自上而下地调整节点的位置,使其称为堆积,即把序号为 i 的节点与
其左子树节点( 2 * i )、右子树节点( 2 * i + 1 )中值最大的节点交换位置;
2,因为交换了位置,使得当前节点的左右子树原有的堆积特征被破坏。于是从当前节点
的左右子树节点开始,自上而下继续进行类似调整;
3,如此下去直到整棵完全二叉树成为一个大顶堆。
将数组构建为二叉堆方法 heapify:
1,如果原始序列对应的完全二叉树的深度为 d,则从 d - 1 层最右侧分支节点(序列号
为 n / 2 )开始,初始时令 i = n / 2 调用堆调整算法。
2,每调用以此堆调整算法,执行一次 i = i - 1,直到 i == 1,再调用一次,就把原始数组
构建成为了一个二叉堆。
优先队列的基本操作主要是入队操作和出队操作。
入队操作 heappush:
先将待插入元素 value 插入到数组 nums 末尾;
如果完全二叉树的深度为 d,则从 d - 1层开始最右侧分支节点开始,从下向上依次
寻找插入位置;
如果找到插入位置或者到达根位置,将 value 插入该位置。
出队操作 heappop:
交换数组 nums 首尾元素,此时 nums 尾部就是优先级最高的元素,将其从 nums
中弹出,并保存起来。
弹出后,对 nums 剩余元素调用堆调整算法,将其调整为大顶堆。
代码实现:
class Heapq:
# 堆调整方法,调整为大根堆
def heapAdjust(self, nums: [int], index: int, end: int):
left = index * 2 + 1
right = left + 1
while left <= end:
# left = index * 2 + 1 仍小于end,说明当前节点为非叶子节点
max_index = index
if nums[left] > nums[max_index]:
max_index = left
if right <= end and nums[right] > nums[max_index]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 将数组构建为二叉堆
def heapify(self, nums: [int]):
size = len(nums)
# (size - 2) // 2 是最后一个非叶子节点,叶子节点不用调整
for i in range((size - 2) // 2, -1, -1):
# 调用调整堆函数
self.heapAdjust(nums, i, size - 1)
# 入队操作
def heappush(self, nums: list, value):
nums.append(value)
size = len(nums)
i = size - 1
# 寻找插入位置
while (i - 1) // 2 > 0:
# 找到 i 节点的根节点
cur_root = (i - 1) // 2
if nums[cur_root] > value:
# value 小于当前根节点,则插入当前位置
break
# 继续向上查找
nums[i] = nums[cur_root]
i = cur_root
# 找到了插入位置或者到达根节点位置,将其插入
nums[i] = value
# 出队操作
def heappop(self, nums: list):
size = len(nums)
nums[0], nums[-1] = nums[-1], nums[0]
# 得到优先值最大的元素,然后调整堆
top = nums.pop()
if size > 0:
self.heapAdjust(nums, 0, size - 2)
return top
# 升序堆排序
def heapSort(self, nums: [int]):
self.heapify(nums)
size = len(nums)
for i in range(size):
nums[0], nums[size - i - 1] = nums[size - i - 1], nums[0]
self.heapAdjust(nums, 0, size - i - 2)
return nums使用 heapq 模块实现优先队列
heapq.heappush() 用于在队列 queue 上插入一个元素;
heapq.heappop() 用于在队列 queue 上删除一个元素,注意总是返回最小元素,将优先级设置为负数,以获取优先级最高的元素。
代码实现:
import heapq
class PriorityQueue:
def __init__(self):
self.queue = []
self.index = 0
def push(self, item, priority):
heapq.heappush(self.queue, (-priority, self.index, item))
self.index += 1
def pop(self):
return heapq.heappop(self.queue)[-1]
题目:
703. 数据流中的第 K 大元素 - 力扣(LeetCode)
使用小根堆,因为在 1 2 3 4 5中,如果寻找第 3 小的元素,则将1, 2出队后,队列长度为 3,再将堆顶出栈即可。
class KthLargest:
def __init__(self, k: int, nums: List[int]):
self.k = k
self.que = nums
heapq.heapify(self.que)
def add(self, val: int) -> int:
heapq.heappush(self.que, val)
while len(self.que) > self.k:
heapq.heappop(self.que)
return self.que[0]
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
m = dict()
for i in nums:
if i in m:
m[i] += 1
else:
m[i] = 1
res = []
ans = []
for key in m:
heapq.heappush(res, (-m[key], key)) # 将频率和元素一起存入堆中
for _ in range(k):
ans.append(heapq.heappop(res)[1]) # 取出堆中的元素
return ans973. 最接近原点的 K 个点 - 力扣(LeetCode)
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
res = []
ans = []
for point in points:
ans.append(point[0] ** 2 + point[1] ** 2)
lst = []
for i in range(len(ans)):
heapq.heappush(lst, (ans[i], i))
for i in range(k):
res.append(points[heapq.heappop(lst)[1]])
return resclass Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
size = len(nums)
q = [(-nums[i], i) for i in range(k)]
heapq.heapify(q)
res = [-q[0][0]]
for i in range(k, size):
heapq.heappush(q, (-nums[i], i))
while q[0][1] <= i - k:
heapq.heappop(q)
res.append(-q[0][0])
return res
算法通关手册(LeetCode) | 算法通关手册(LeetCode)
原文内容在这里,如有侵权,请联系我删除。















 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









