







 C4.5是一种决策树算法,通过信息增益率选择划分属性,能处理离散和连续属性,且能处理缺失值。它改进了ID3算法的偏向性,采用自上而下的递归方法构建分类模型。文章通过案例分析展示了C4.5算法的决策树构建过程,并提供了Python代码示例。
C4.5是一种决策树算法,通过信息增益率选择划分属性,能处理离散和连续属性,且能处理缺失值。它改进了ID3算法的偏向性,采用自上而下的递归方法构建分类模型。文章通过案例分析展示了C4.5算法的决策树构建过程,并提供了Python代码示例。
一.C4.5算法的简介:
C4.5并不是单单一个算法而是一套算法,主要用于对机器学习和数据挖掘中的分类问题。它是一种有监督的学习,也就是说对于该算法我们需要先给它们提供一个数据集,这个数据集包含多个实例,每个实例都包含多个属性,该实例用这些属性描述,根据属性取值的不同被划分到不同的互斥类中。
C4.5算法就是从提供的数据集中学习到如何将不同属性值的实例划分到不同类的映射,当我们提供一套全新的属性值的时候,它能够通过学到的映射对新的属性进行分类。
C4.5是决策树算法的一种。决策树算法作为一种分类算法,目标就是将具有p维特征的n个样本分到c个类别中去。相当于做一个投影,c=f(n),将样本经过一种变换赋予一种类别标签。决策树为了达到这一目的,可以把分类的过程表示成一棵树,每次通过选择一个特征pi来进行分叉。
那么怎样选择分叉的特征呢?每一次分叉选择哪个特征对样本进行划分可以最快最准确的对样本分类呢?不同的决策树算法有着不同的特征选择方案。ID3用信息增益,C4.5用信息增益率,CART用gini系数。
下面主要针对C4.5算法,我们用一个例子来计算一下。
二.C4.5算法原理:
C4.5算法是一种经典的决策树学习算法,它是ID3算法的一种改进和优化。与ID3算法相比,C4.5算法具有以下几个改进:
-
用信息增益率代替信息增益作为选择划分属性的标准,解决了信息增益容易偏向取值比较多的属性的问题。
-
能够处理连续型属性数据,不需要对连续型属性进行离散化处理。
-
能够处理缺失属性值,利用缺失属性值的样本进行决策树的训练。
C4.5算法的基本思想是将数据集递归地划分为小的子集,直到子集中样本的所有特征属性均相同或无法继续划分为止。得到的决策树就是基于训练集构建的分类模型。
C4.5算法的具体步骤如下:
-
选择当前节点的最优划分属性,即使得信息增益率最大的属性,如果不存在则该节点为叶子节点。
-
对选择的最优属性的每个取值,分别构建一个子节点,并将样本点分配到这些子节点中。
-
对每个子节点,递归地执行步骤1-2,直至满足终止条件,即到达叶子节点或无法继续划分。
-
构建好决策树,用它进行测试数据的分类预测。
C4.5算法在构建决策树时,采用了自上而下递归的方法,每次选择最优划分属性进行划分,并在该属性的每个取值上递归地划分数据集。这样,就能得到一个覆盖了训练集所有样本的决策树模型,并可用来对新的测试样本进行分类预测。
三.C4.5案例分析:
例如,如图1,这组训练数据,属性值包括是否有房,婚姻状况,年收入,所有的实例被划分为两类,也就是 是否是拖欠贷款者。我们的目的就是从训练数据中学到一个映射,这个映射可以用于对于在图中未出现的实例属性取值情况进行有效分类。
也就是说,假如有一个有房、单身、年收入为50X的人(图中未出现),推测出这个人是否是拖欠贷款者
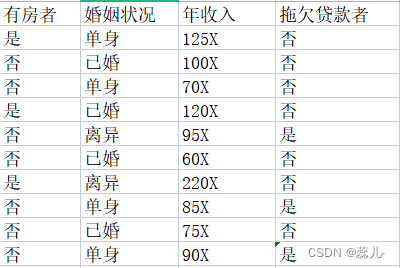
Figure 1
3.1决策树构建:
a.将所有训练数据集放在根节点上;
b.遍历每种属性的每种分割方式,找到最好的分割点;
c.根据2中找出的最好分割点将根节点分割成多个子节点(>=2);
d.对剩下的样本和属性重复执行步骤2/3,直到每个节点中的数据都属于同一类为止。
C4.5算法是采用信息增益率来进行节点的分裂
注意:C4.5算法并不直接选择增益率最大的候选划分属性,而是使用了一个启发式:
先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3.2信息增益率:
增益率是用前面的信息增益Gain(D, a)和属性a对应的"固有值"(intrinsic value)的比值来共同定义的。属性 a 的可能取值数目越多(即 V 越
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4264
4264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









