









论文地址:
http://dm.postech.ac.kr/~cartopy/ConvMF/
项目地址:
https://github.com/cartopy/ConvMF
博主最近看了一篇论文,题目是
Convolutional Matrix Factorization for Document Context-Aware Recommendation,
论文给了github地址,遂尝试着复现论文,中途遇到一些问题,并且记录下来。
Step1:下载项目
https://github.com/cartopy/ConvMF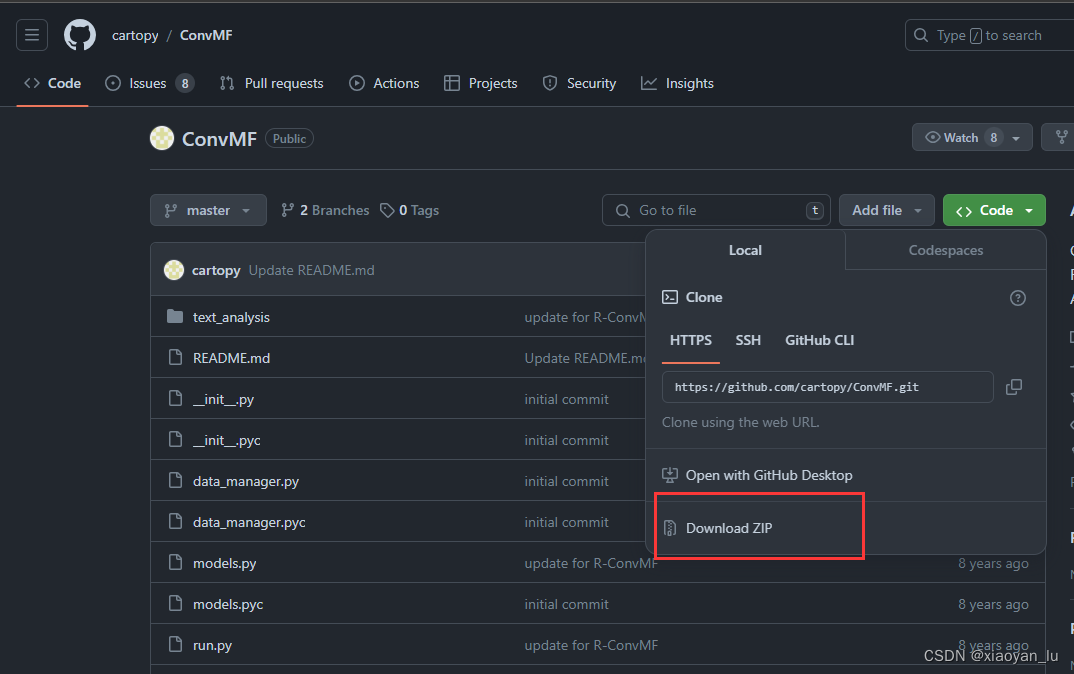
不会使用Git的小伙伴可以直接下载zip安装包,然后再Pycharm中打开。
Step2:解压安装包,使用Pycharm打开项目

Step3:阅读readme,按照要求配置项目环境
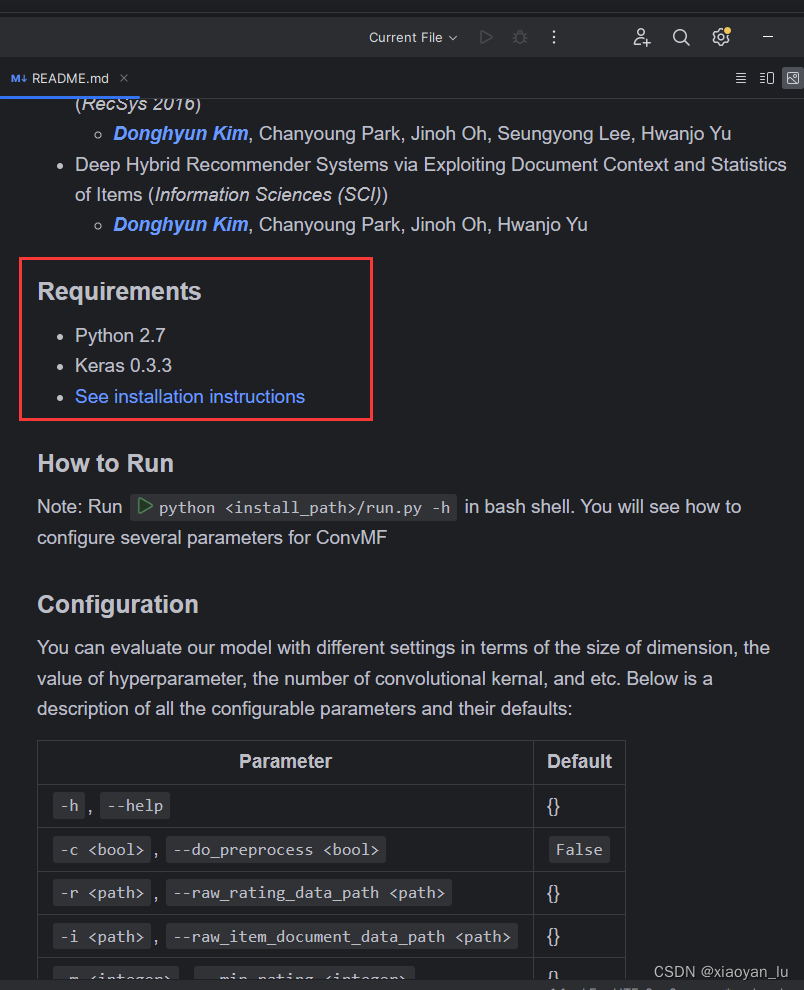
作者给了环境为python2.7和Kera0.3.3,由于python2.7在2020年就不在维护了,而且与主流的python3.x系列相差较大,因此,预感会有很多问题。
Step4:在anaconda中搭建虚拟环境
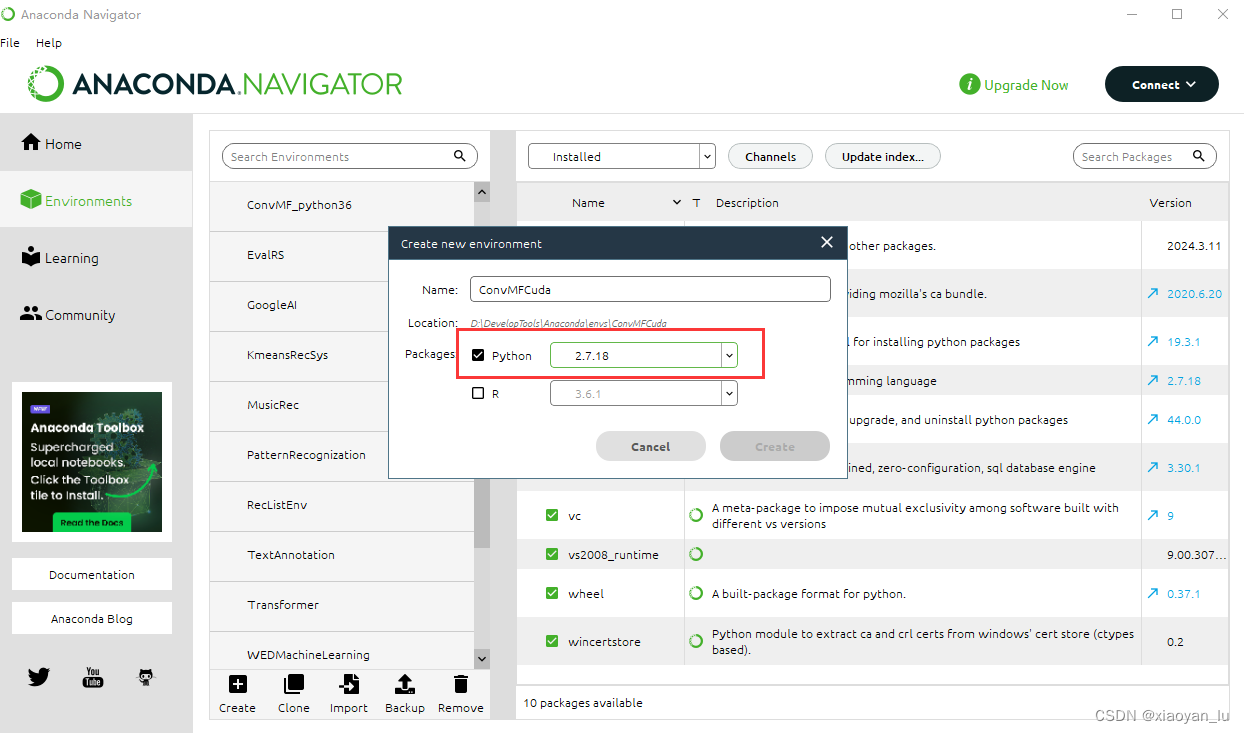
博主的anaconda版本中最低的python版本为2.7.18。
创建成功后,启动该虚拟环境。

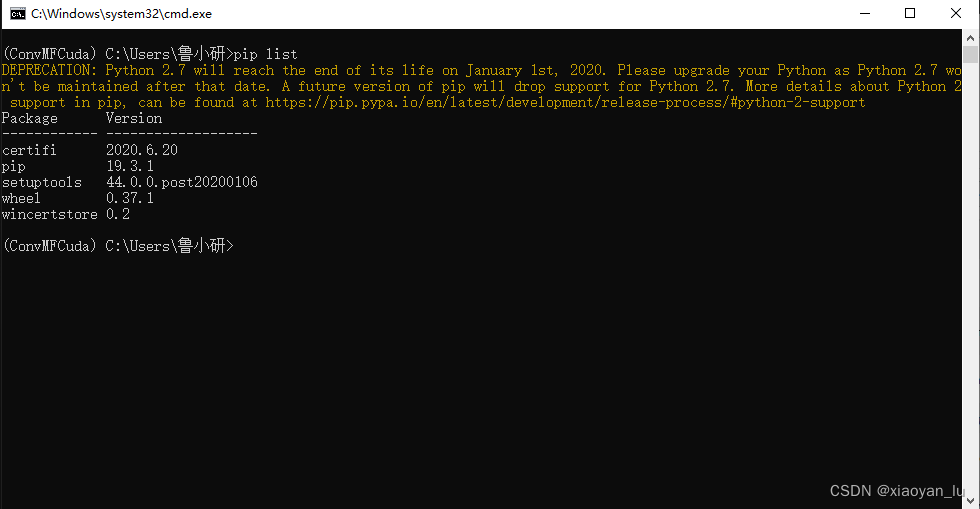
可以看到当前虚拟环境中没有什么包,开始安装Keras0.3.3。
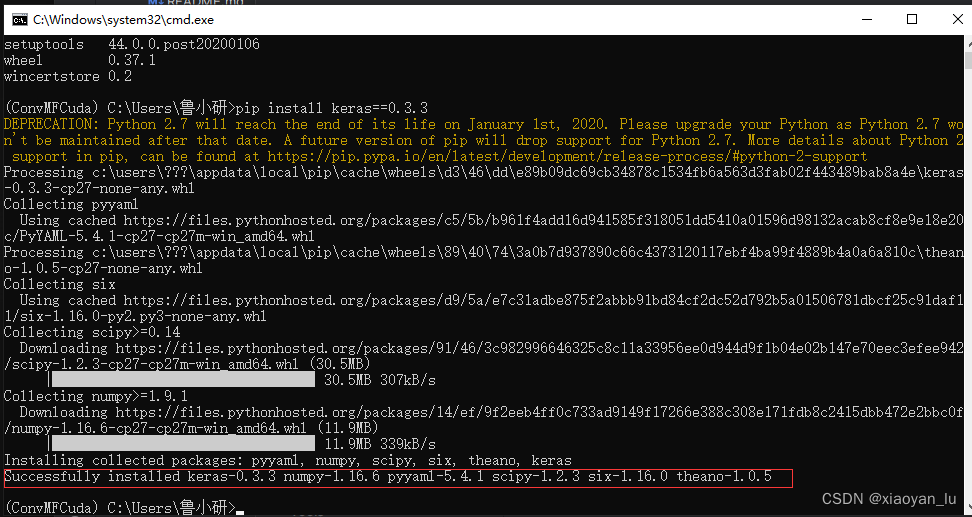
出现Successfully就说明安装keras成功。
Step5:配置ConvMF-master项目的运行环境为刚刚创建的虚拟环境
在pycharm中找到python interpreter配置位置。
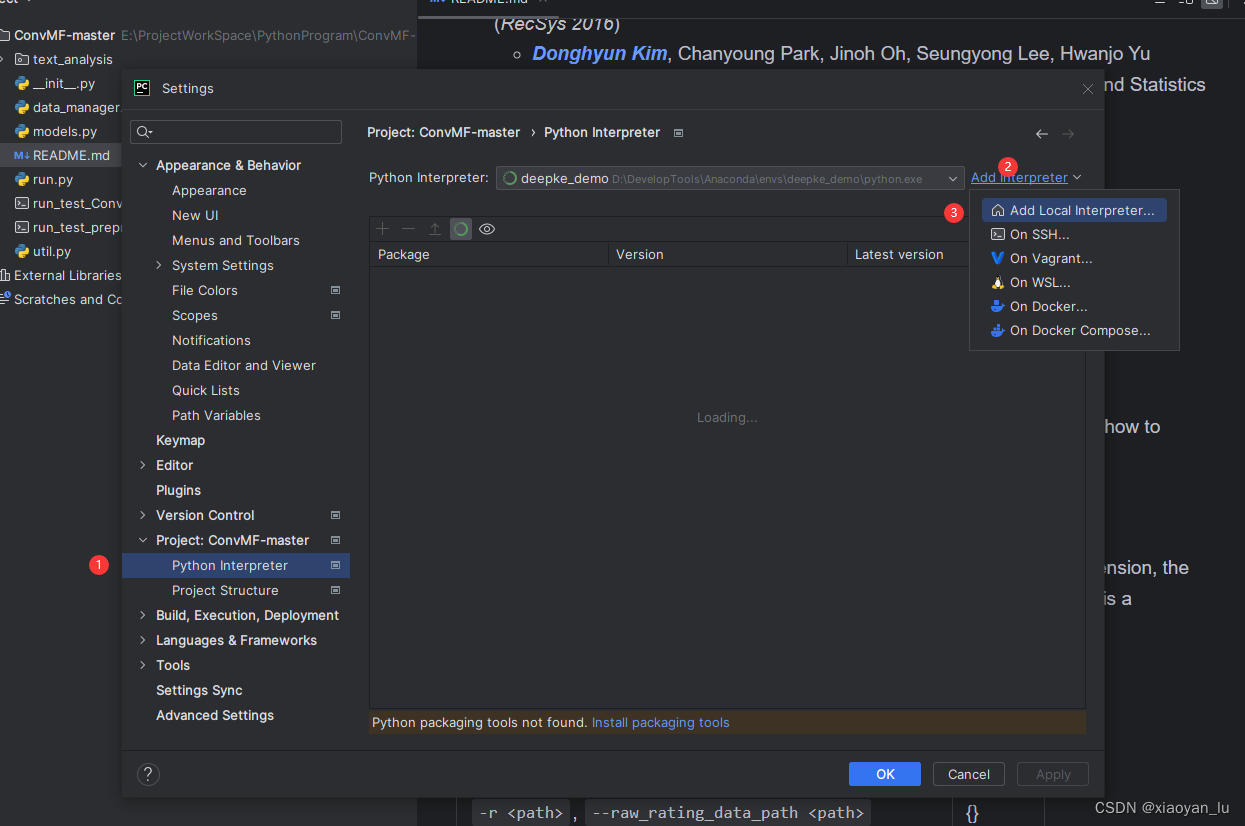

Step6:运行ConvMF-master项目
找到run.py文件,开始运行项目。
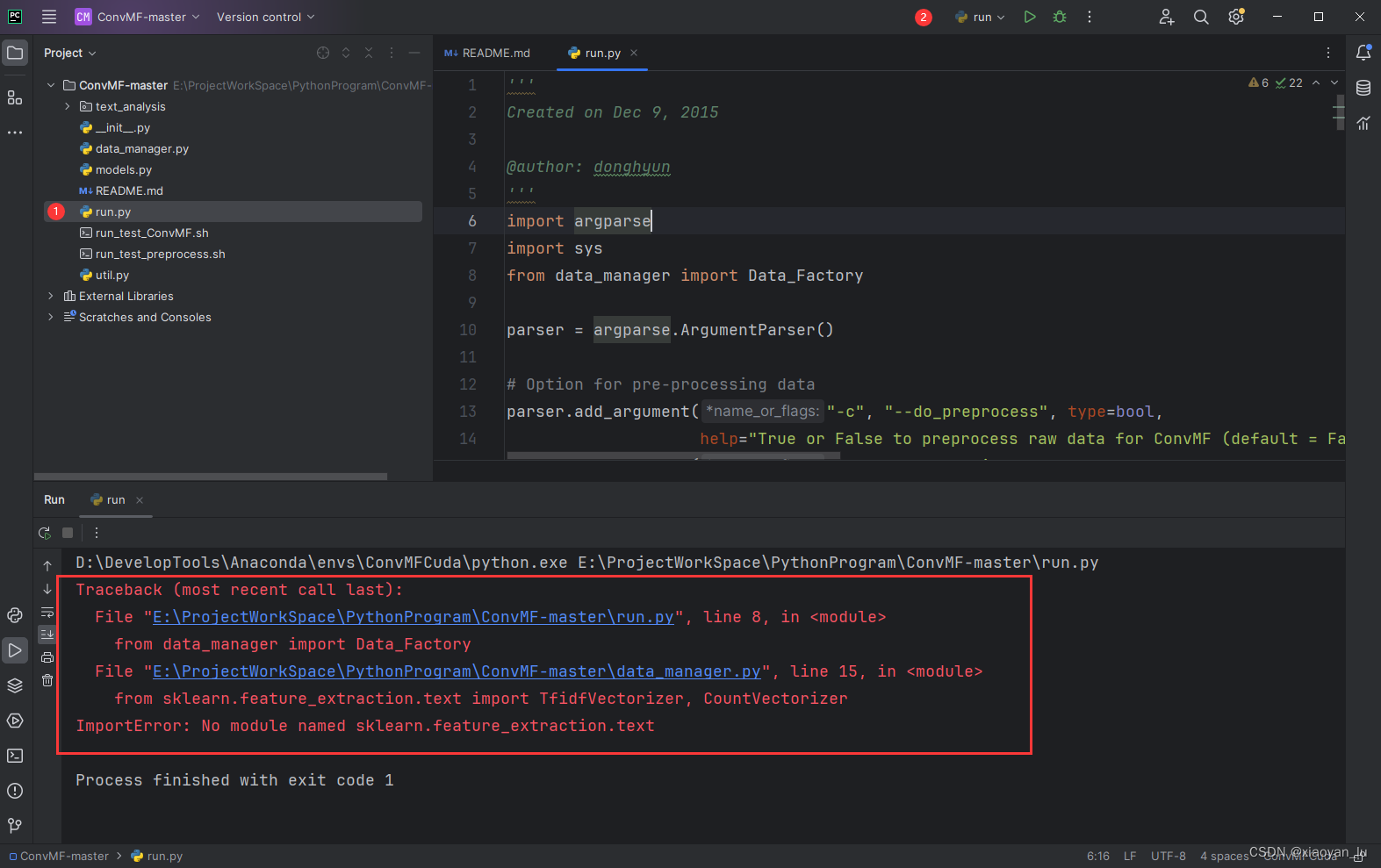
发现报错,提示缺少sklearn包。
开始安装sklearn包。
进入我们当前项目的虚拟环境中,安装缺少的包。
输入指令 pip install scikit-learn
开始安装sklearn包。
ps:这里我们暂时不用考虑对应的版本,pip会自动选择适合当前环境的版本。
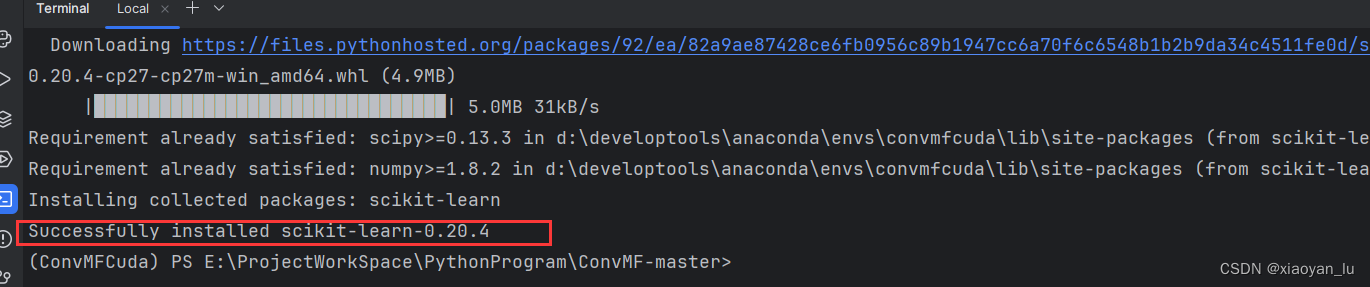
sklearn安装成功!
继续运行run.py

出现错误提示,缺少data_path参数,这是什么?
我们可以仔细阅读readme文件,里面给出了项目参数配置提示。
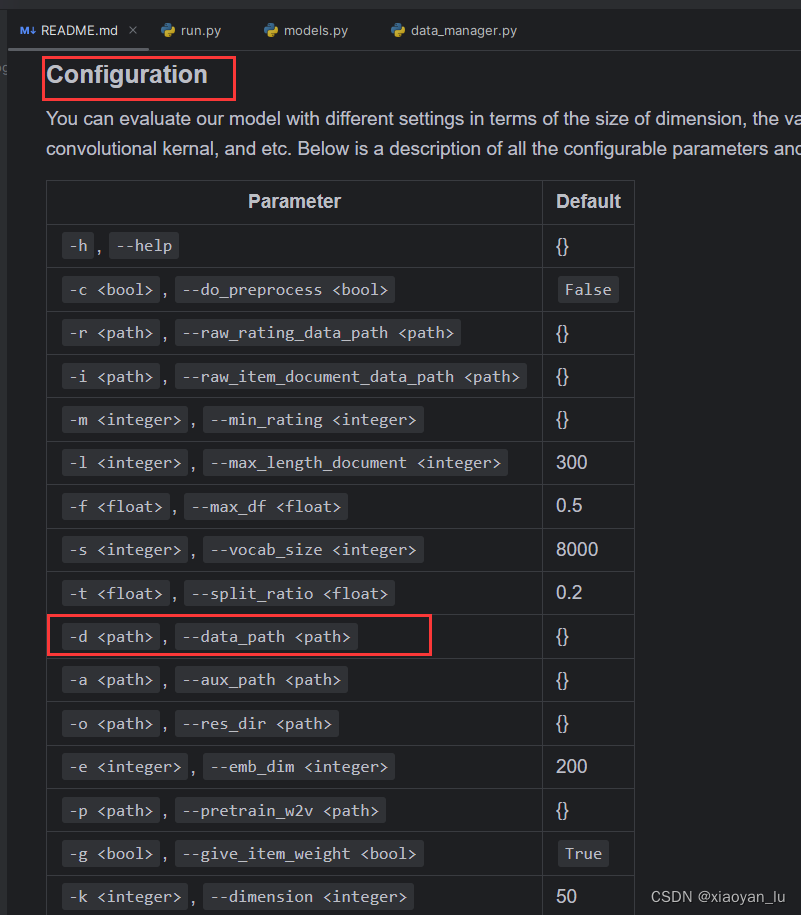
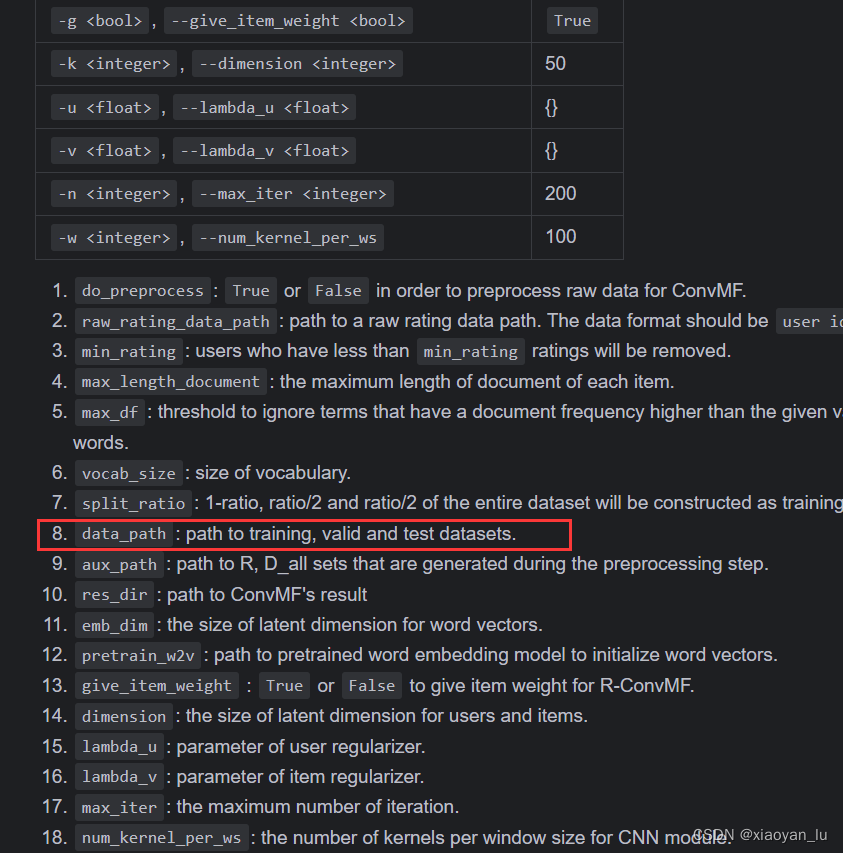
原来data_path是数据集的路径,那问题来了,数据集在哪里?
Step7:下载数据集
通过阅读原论文,可以发现,作者给出了数据集的链接。
数据集:http://dm.postech.ac.kr/ConvMF

在Experiments这块儿,作者给出了实验所用的数据集。

翻到最底下,我们找到了数据集的地址

这里我们以MovieLens数据集为例,开始下载。
下载完成后,我们开始使用数据集。
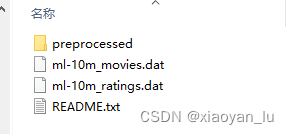
数据集中有4个文件,第一个表示已经处理过的数据集,而第二三个表示是原始的10m大小的数据集。
这里博主的小电脑计算量更不上,选择已经处理过的1m大小的数据集
然后,readme.txt中告诉我们数据集的一些信息
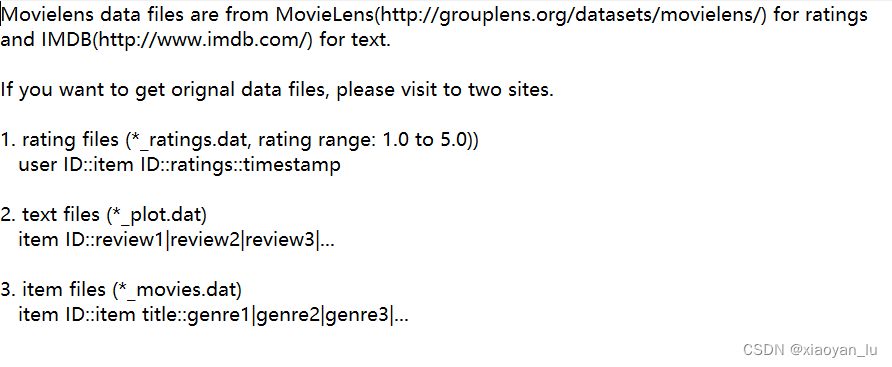
这个数据集是关于电影评分的数据集,是推荐系统领域中最经典的数据集之一。
rating 文件中记录的是用户对电影的评分数据,数据结构为
用户id::项目(电影)id::评分::时间戳
这里评分是从1.0-5.0之间
text 文件是记录电影评论的信息。数据结构为
电影id::评论1|评论2|评论3....
item文件记录的是电影的信息。数据结构为
电影id::电影标题::电影的体裁...
Step8:配置数据集到项目中
开始安装数据集
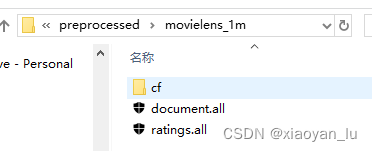
将这里的文件放到项目的data中,格式如下,并且创建res_fir文件夹和data文件夹。
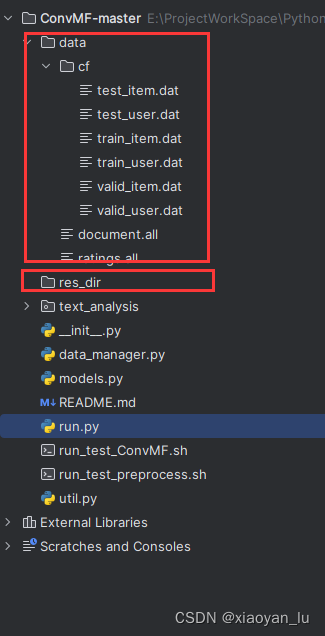
在run.py文件下对应的位置添加default参数,参数具体含义需要阅读原论文和readme文件,这里就不再详细阐述。
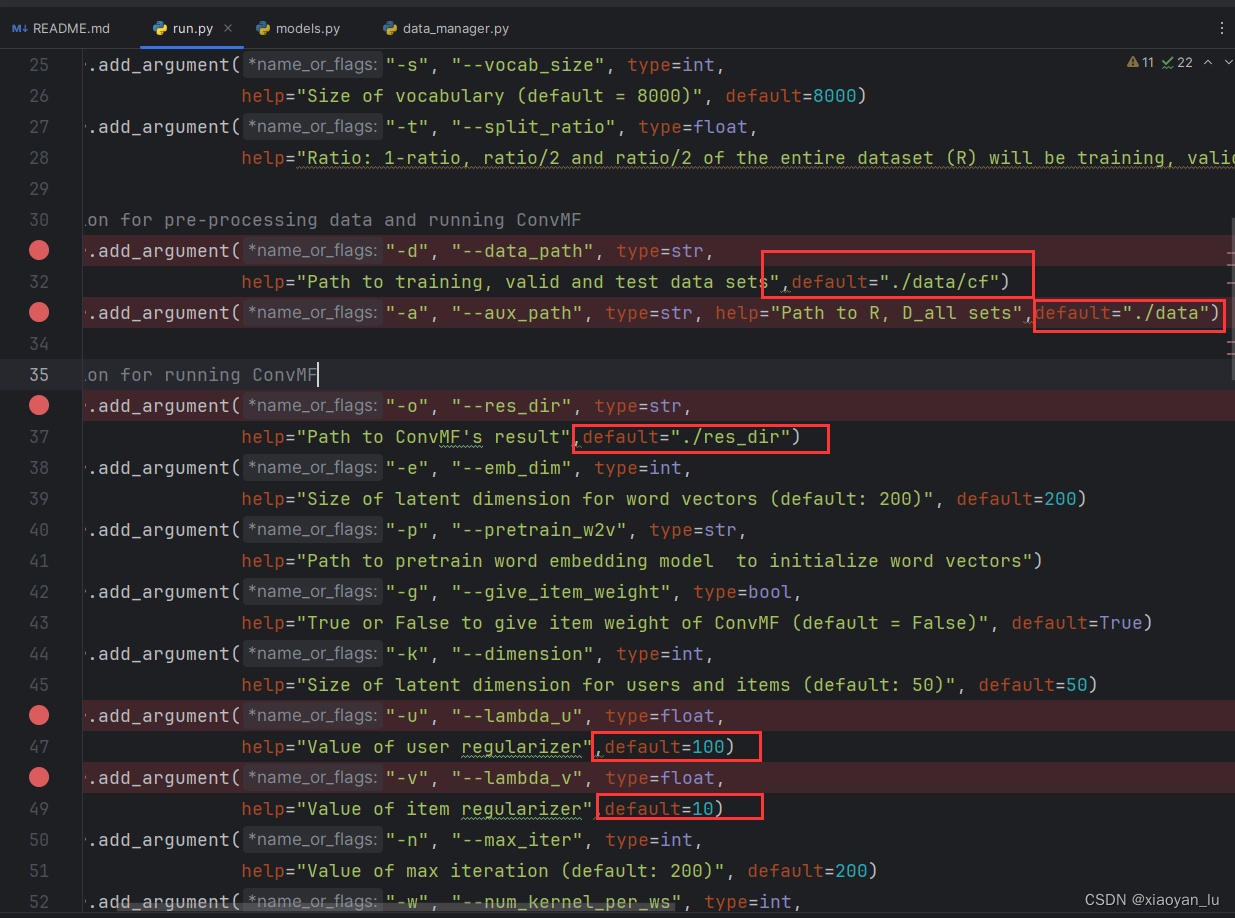
重新运行run.py文件。
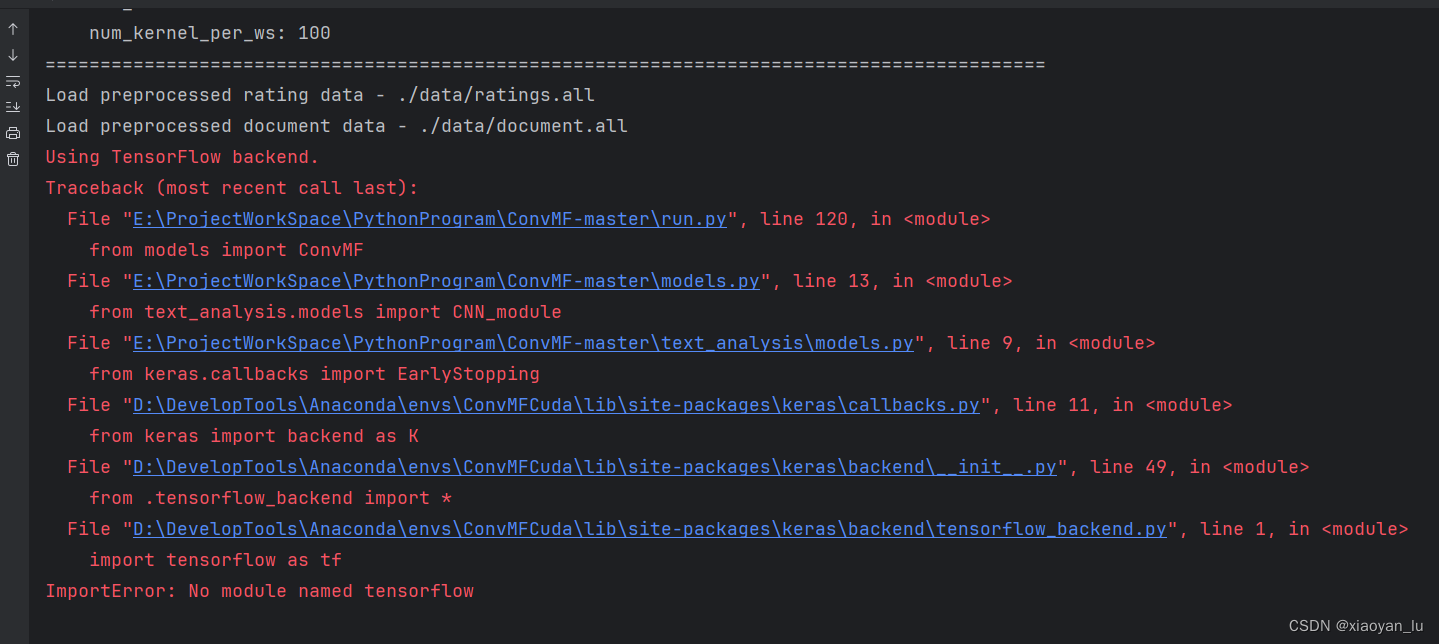
这里报错提示我们缺少tensorflow包。
Step9:安装tensorflow

由于该项目使用的是上古python2.7,因此pip找不到与之对应的tensorflow版本。
通过博主一番查阅资料,我们需要去手动下载对应的tensorflow。
https://github.com/fo40225/tensorflow-windows-wheel
这里给出了tensorflow不同版本对应使用python版本。我们找到适合python2.7的tensorflow1.5。

由于GPU版本的tensorflow需要对应电脑有cuda,这里为了简便,我们就下载CPU版本的tensorflow。
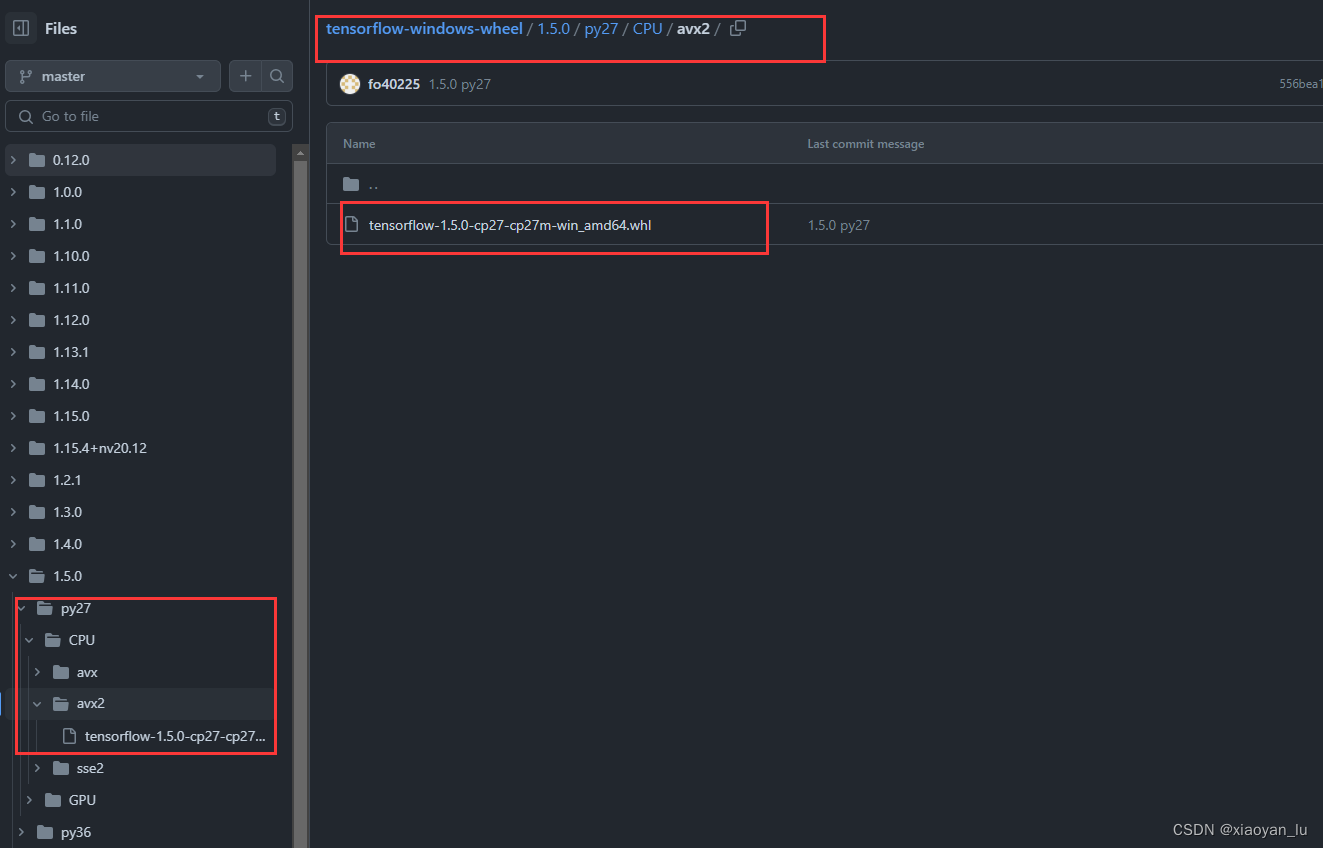
下载完成,我们进入tensorflow所在的目录。
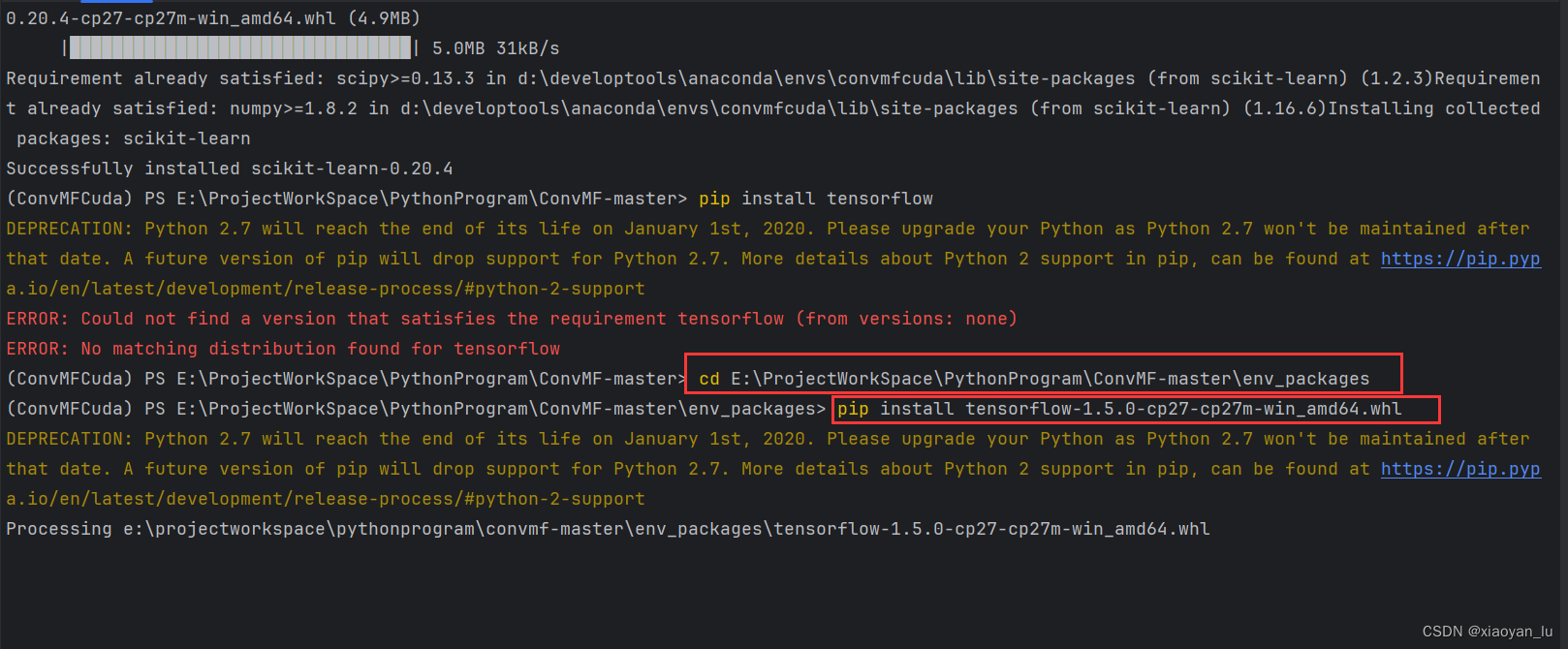
开始安装tensorflow
pip install tensorflow-1.5.0-cp27-cp27m-win_amd64.whl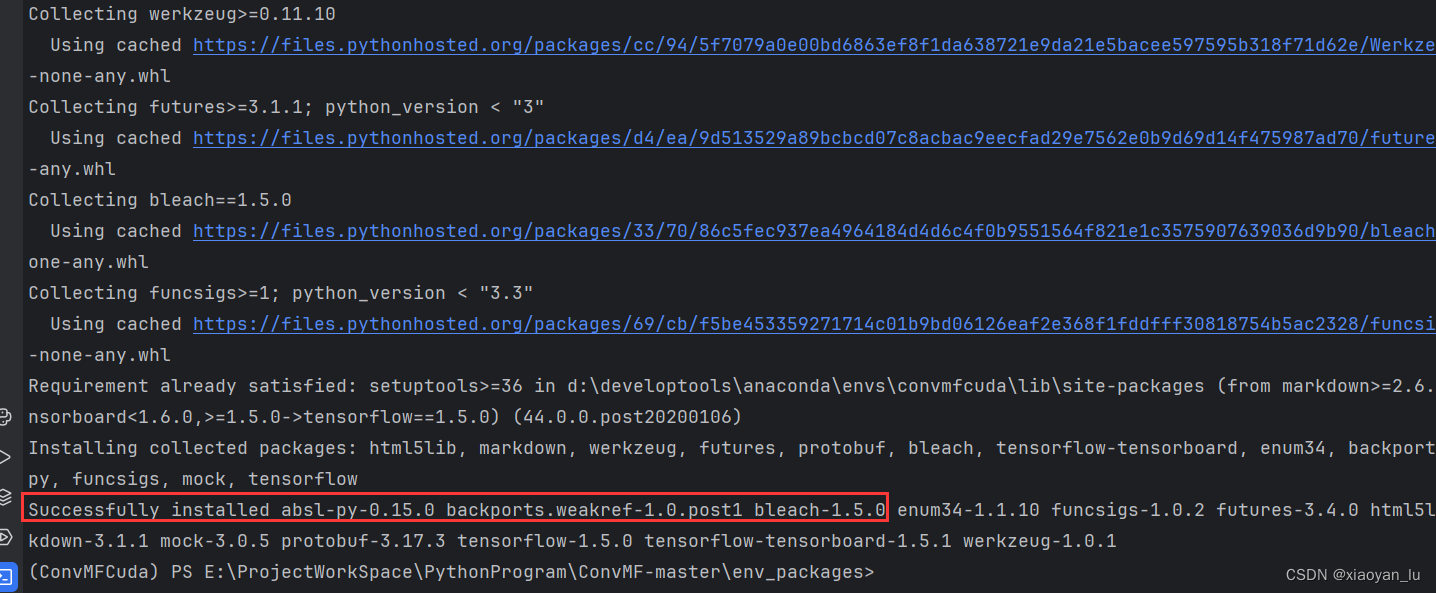
安装成功!
再次运行run.py
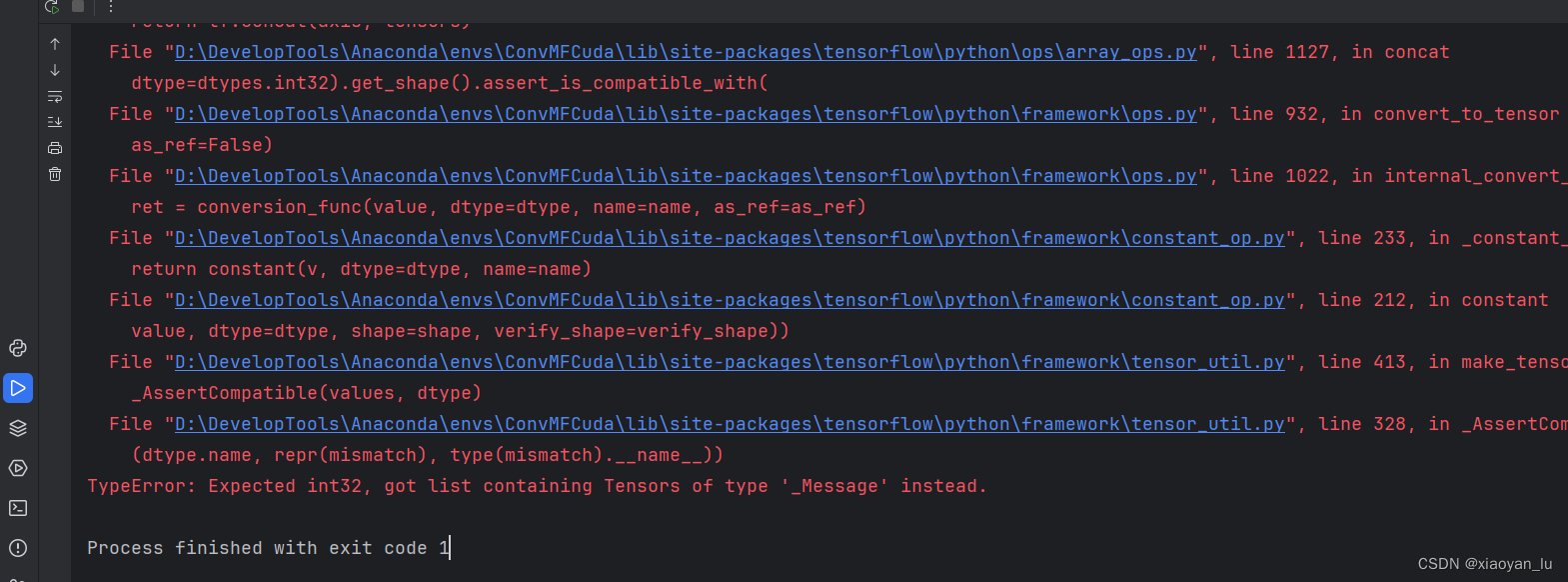
啊啊啊啊啊啊啊!!!!!又是满屏红!!!!(抓狂)
经过一系列查找资料,找到了解决办法:

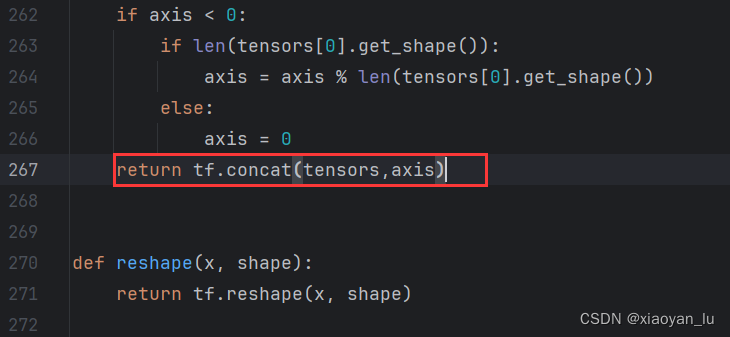
由于我们使用的是1.x版本,与0.x版本的tensorflow不同,需要调整参数位置。
也就是下图中的函数参数位置调换以下就行。
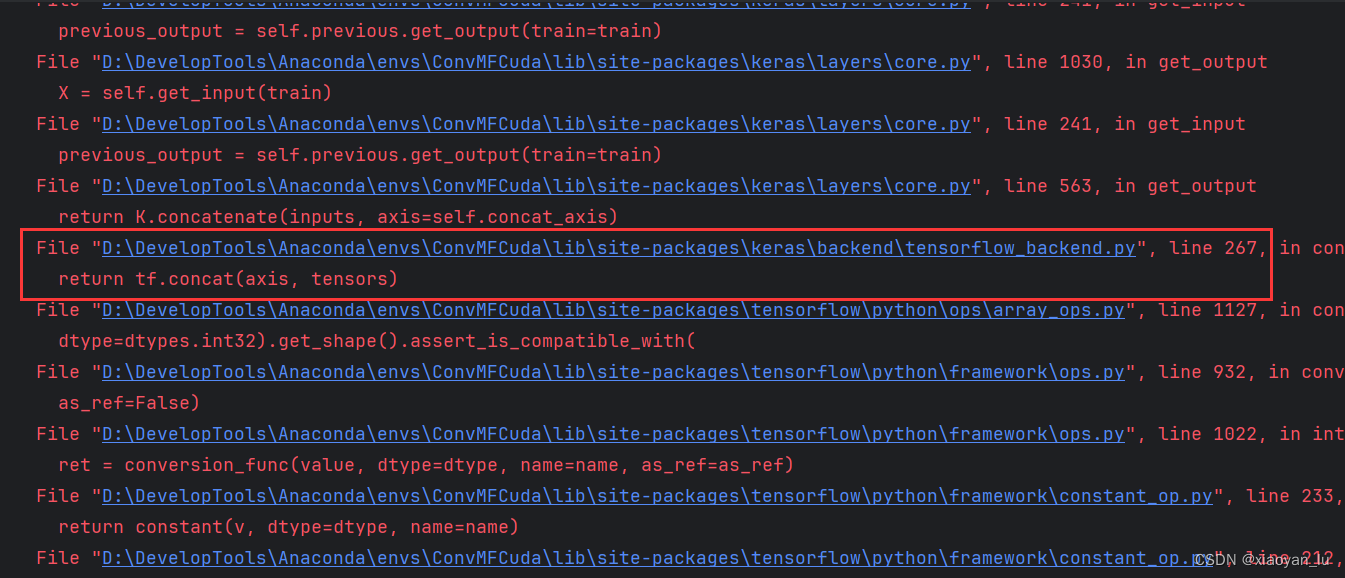
结果如下:
重新运行run.py
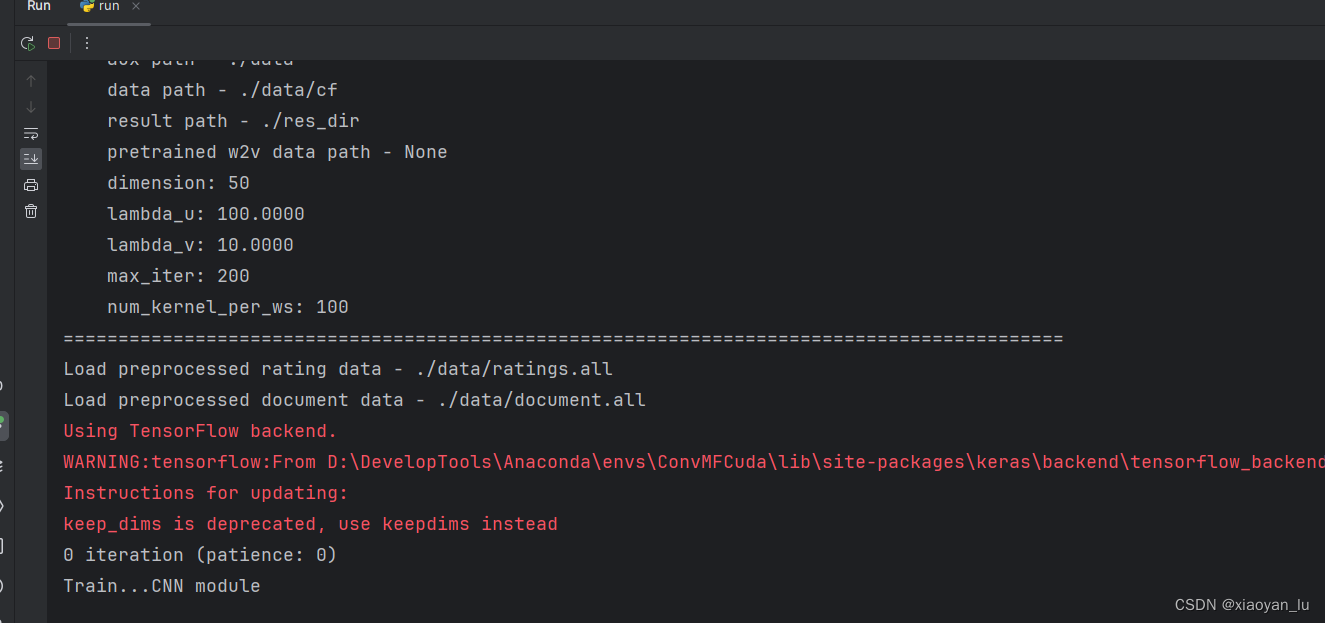
可恶!!!
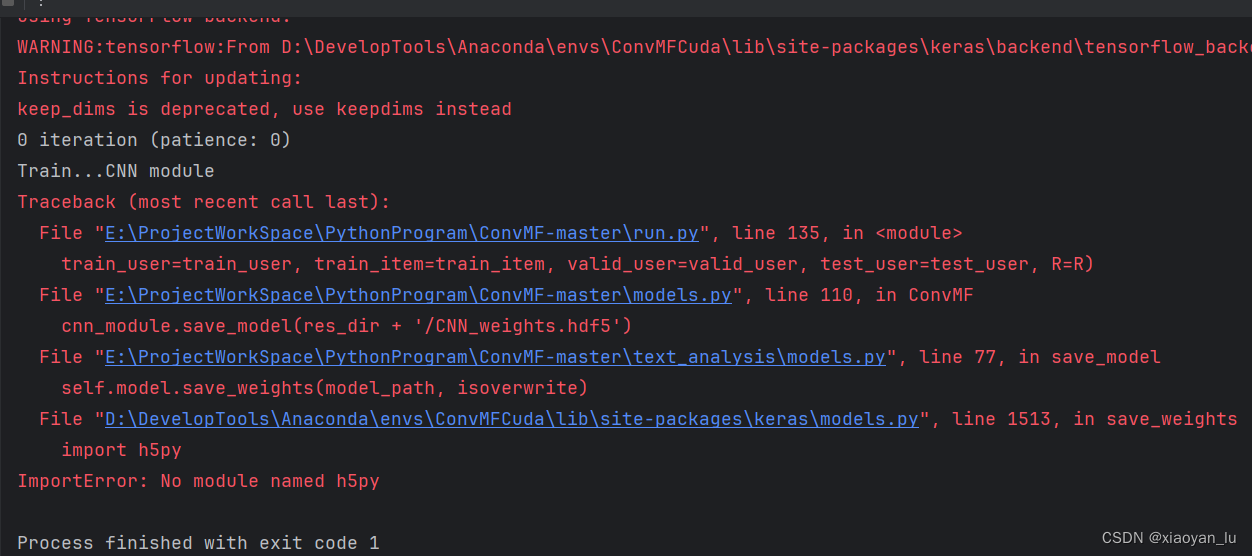
又缺少了h5py包。
安装就完了!!!

又又又又又又又又又又重新run!!!
芜湖!!!!成功开始训练了!!!!
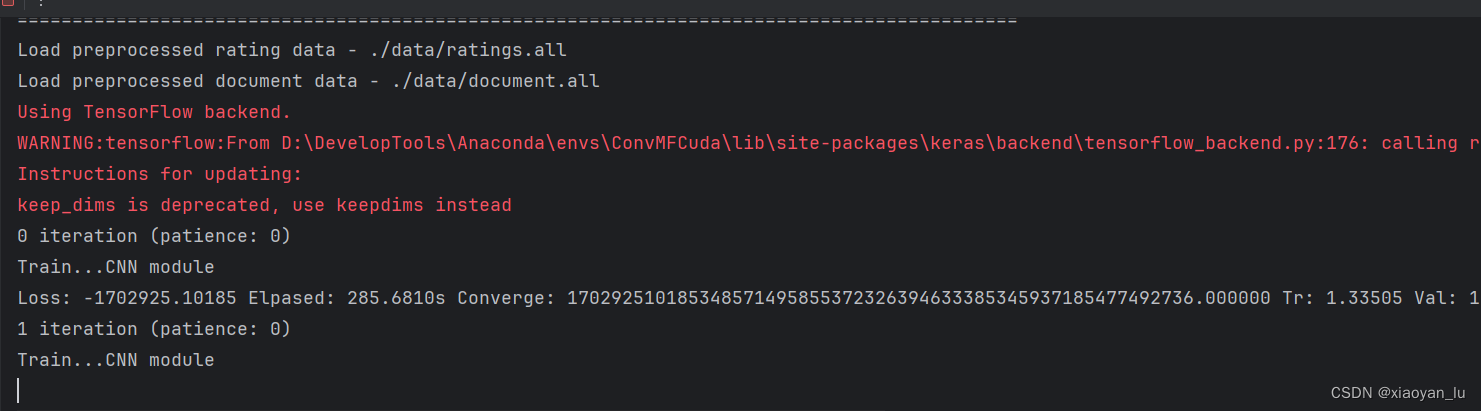
之后的具体代码阅读和参数微调,有机会后续更新。。。
总结:
总结一下本次ConvMF的配置过程,主要的难点在于
-
数据集找不到=》通过论文找打了
-
不懂如何配置超参数=》阅读readme和论文中的实验部分
-
上古环境的搭建=》chat-gpt,github,CSDN等广大前人的经验
对于复现论文的项目,我们首先要找到数据集,没有数据,一切白搭。同时,也要明白数据集的信息,以及各个文件的作用以及内容表达的含义,以便快速对整体项目的理解。此外,配合论文中实验部分的理解,我们可以对整个项目有个宏观上的认知。而对于具体的代码细节,各个部分功能是如何起作用,作者如何融合CNN和PMF的还需要进一步阅读论文和debug代码。
整体项目的环境:
| 包 | 版本 |
|---|---|
| python | 2.7 |
| keras | 0.3.3 |
| tensorflow | 1.5,cpu版本 |
| numpy | 1.16.6 |
| scikit-learn | 0.20.4 |
参考文献:
https://blog.csdn.net/piupiu78/article/details/124658637
https://blog.csdn.net/qq_34638161/article/details/80729101
https://blog.csdn.net/zcf1784266476/article/details/71248799















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









