







消息队列概述
消息队列:对消息进行缓存,分类;先进先出,
作用:
缓冲/消峰:控制和优化数据流的速度,解决生产消息和消费消息速度不一致的情况;
解耦:节省复杂度,允许独立的扩展或修改两边的处理过程,只要确保遵守同样的接口约束。【大数据计算引擎和数据处理引擎】
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。【注册就响应,发送短信单独处理】
消息队列的两种模式:点对点模式和发布/订阅模式
点对点:一个消息只能被一个消费者接收;消费者确认收到,消息将从队列中删除【eg:打电话】
发布/订阅:组成(消息队列、发布者、订阅者、主题),多个主题,消费者消费数据后不删除数据,每个消费者相互独立都可以消费数据。【eg:微博】
分布式的概念
一、分布式(Distributed System)的定义与核心特征
分布式系统是指通过网络连接多个独立计算节点,协同完成同一目标的系统。这些节点可以是服务器、计算机、虚拟机甚至容器,它们通过消息传递或共享存储进行通信,共同对外提供服务。
分布式系统的核心特征
分散性
系统功能分散在多个节点上,没有集中式的控制节点。每个节点仅拥有部分数据和计算资源,但通过协作完成整体任务。
示例:分布式数据库(如 HBase、Cassandra)将数据分片存储在不同节点,每个节点负责处理部分读写请求。
并发性
多个节点可同时处理任务,通过并行计算提升系统吞吐量。
示例:分布式计算框架(如 MapReduce)将大规模数据处理任务拆解为多个子任务,分配到不同节点并行执行。
透明性
对用户和应用程序而言,分布式系统的内部节点通信、数据分布等细节被隐藏,呈现为一个统一的整体。
示例:用户访问分布式文件系统(如 HDFS)时,无需关心文件具体存储在哪个节点,系统自动处理数据的读写和复制。
扩展性
可通过增加节点数量横向扩展系统性能(计算、存储、网络带宽等),而非依赖单一节点的硬件升级(纵向扩展)。
优势:成本更低、灵活性更高,适合应对业务快速增长的场景。
二、基于分布式的扩展机制
扩展机制指通过调整分布式系统的节点数量或资源分配,动态应对负载变化的能力,分为横向扩展(Scale Out)和纵向扩展(Scale Up),但分布式系统更依赖前者。
1. 横向扩展(分布式扩展的核心方式)
定义:通过添加同类型节点(如服务器、容器),将负载均匀分配到更多节点上,提升系统整体处理能力。
实现方式:
负载均衡:通过负载均衡器(如 Nginx、F5)将请求均匀分发到多个节点,避免单个节点过载。
无状态设计:确保节点不依赖本地状态(如会话数据),以便随时添加或移除节点而不影响服务。
数据分片(Sharding):将数据按规则(如哈希、范围)拆分到不同节点,每个节点仅存储和处理部分数据。
示例:电商平台在促销期间新增服务器节点,通过负载均衡器分摊流量,避免系统崩溃。
2. 纵向扩展(辅助方式)
定义:提升单个节点的硬件性能(如 CPU、内存、存储),以增强其处理能力。
局限性:受硬件物理上限限制,且成本随性能提升呈指数增长,难以应对大规模负载。
适用场景:短期内无法快速增加节点时,作为临时优化手段。
三、基于分布式的容错机制
容错机制指分布式系统在部分节点故障(如硬件损坏、网络中断、软件崩溃)时,仍能保持服务可用性和数据一致性的能力。
1. 冗余(Redundancy)
数据冗余:通过复制(Replication)或纠删码(Erasure Coding)在多个节点存储相同数据的副本,确保单点故障不导致数据丢失。
示例:HDFS 将每个数据块默认复制 3 份存储在不同节点,当某个节点故障时,系统自动从其他副本读取数据。
服务冗余:部署多个相同功能的节点(如 Web 服务器、API 服务节点),通过负载均衡器实现故障切换(Failover)。
示例:当某个 API 节点故障时,负载均衡器自动将请求转发到其他健康节点,避免服务中断。
2. 故障检测与恢复
心跳机制:节点定期向其他节点或中心管理器发送 “心跳” 消息,若超时未收到则判定为故障。
技术实现:分布式协调工具(如 Zookeeper)通过心跳检测节点状态,维护可用节点列表。
自动恢复:
对于无状态服务,直接重启故障节点或替换为新节点;
对于有状态服务(如数据库),通过数据副本切换(如主从切换)快速恢复服务。
示例:MySQL 主从复制架构中,主节点故障时,系统自动将从节点提升为主节点,继续提供写服务。
3. 一致性协议
分布式系统中,节点间数据同步可能因故障导致不一致,需通过一致性协议(如 Paxos、Raft)确保数据最终一致。
核心逻辑:通过多数节点投票(Quorum)或日志复制(Log Replication),在部分节点故障时仍能达成共识。
应用场景:分布式数据库(如 etcd、CockroachDB)通过 Raft 协议保证跨节点数据一致性。
4. 降级与熔断
降级:当系统负载过高或部分功能故障时,主动关闭非核心功能,优先保障核心服务可用。
示例:电商平台在峰值期间暂时关闭用户评论功能,确保下单和支付流程正常。
熔断:当某个服务节点故障率超过阈值时,自动切断对该节点的请求,避免故障扩散(类似电路保险丝)。
技术实现:通过 Hystrix、Resilience4j 等框架实现服务熔断,防止级联故障。
四、分布式扩展与容错机制的协同作用
扩展为容错提供基础:冗余节点的存在(如多副本、多服务实例)是容错的前提,而扩展机制(如横向扩容)可增加冗余节点数量,提升系统容错能力。
容错保障扩展的有效性:若缺乏容错机制,扩展后的节点故障可能导致系统整体性能下降或服务中断,而可靠的容错机制能确保新增节点稳定运行,充分发挥扩展效果。
五、总结
分布式的本质:通过分散节点、协同工作突破单一节点的性能和可靠性瓶颈。
扩展机制的目标:以低成本、高弹性的方式应对负载增长,核心是横向扩展和无状态设计。
容错机制的目标:通过冗余、检测、恢复等手段,确保系统在故障面前 “不崩溃、数据不丢失、服务不中断”。
典型技术栈:分布式系统常结合负载均衡(如 Nginx)、服务注册与发现(如 Eureka)、分布式存储(如 Redis Cluster)、一致性协议(如 Raft)等技术实现扩展与容错。kafka概述
- 分布式的发布/订阅消息系统,后成为apache的顶级项目。
- 主要用于处理活跃的数据,如登录、浏览、点击、分享、喜欢等用户行为产生的数据。
特点
高吞吐量:可满足每秒百万级别消息的生产和消费;
持久化:有一套完善的消息存储机制,确保数据的高效安全和持久化。
分布式:基于分布式的扩展和容错机制。
kafka集群主要组成
主题:topic
分区:partition
副本:replication
节点:broker
数据:leader
备份:follower
主题:对消息进行分类,包含生产者生产的一部分消息
分区:对每个进行分区,将主题分布式存储在不同节点
每个分区都对应一个主数据和一个备份数据,保证数据高可用
kafka集群数据存储原理
通过producer【生产者】生产的消息,同一个topic【主题】可以有多个broker【节点】进行分布式存储,并且将主题进行复制为leader和follower,实现数据的高可用,即使某个节点宕机,数据也不会丢失;消费数据时只会找leader不会找follewer,follewer只是作为一个备份而已,只有当leader的设备挂机,follower才会被提升为leader然后对数据提供服务。
消费者消费消息
消费者组A:consumer group
组成员1:可以直接消费某一个topic主题某个partition【分区】的消息
组成员2:不能再次消费成员1所消费的主题中的同一个分区;可以再次消费同一个主题的不同分区{提高消费者的消费能力}
同一个组的成员不能重复消费同一个topic主题中的同一个partition分区
消费效率最高:有多少个主题,一个组就有多少个消费者
zookeeper注册消息
记录消费者消费消息的偏移量,记录上一次消费的位置【元数据】;但是2.80版本以后存储在kafka集群中;将zookeeper删除
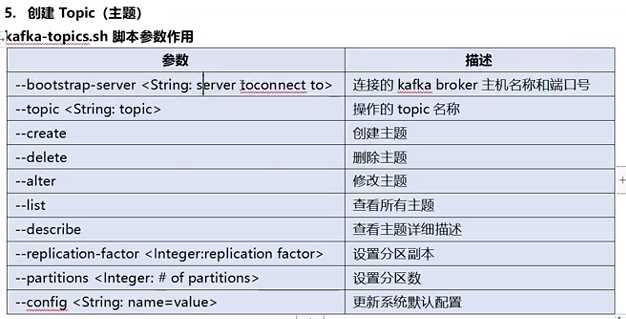
kafka单机安装
使用自带的zk管理元数据
##基础环境
[root@rs2 ~]# hostnamectl set-hostname kafka
[root@kafka ~]# ll
total 300416
-rw-------. 1 root root 1454 Feb 7 20:40 anaconda-ks.cfg
-rw-r--r--. 1 root root 194151339 Jun 5 15:14 jdk-8u231-linux-x64.tar.gz
-rw-r--r--. 1 root root 113466638 Jun 5 15:13 kafka_2.13-3.6.1.tgz
[root@kafka ~]# cd /usr/local/
[root@kafka local]# ln -s /usr/local/jdk1.8.0_231/ /usr/local/java
[root@kafka local]# cat > /etc/profile.d/my_env.sh <<EOF
#!/bin/bash
JAVA_HOME=/usr/local/java/
export PATH=$PATH:$JAVA_HOME/bin
EOF
[root@kafka local]# cat /etc/profile.d/my_env.sh
#!/bin/bash
JAVA_HOME=/usr/local/java/
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin:/bin:/usr/local/java//bin
[root@kafka local]# source /etc/profile
[root@kafka local]# java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
##安装kafka
[root@kafka ~]# tar -xvf kafka_2.13-3.6.1.tgz -C /usr/local
[root@kafka ~]# cd /usr/local/kafka_2.13-3.6.1/
##查看相关脚本
[root@kafka kafka_2.13-3.6.1]# ls bin/
[root@kafka kafka_2.13-3.6.1]# ln -s /usr/local/kafka_2.13-3.6.1/ /usr/local/kafka
[root@kafka kafka_2.13-3.6.1]# vim /etc/profile.d/my_env.sh
[root@kafka kafka_2.13-3.6.1]# source /etc/profile
[root@kafka kafka_2.13-3.6.1]# cat /etc/profile.d/my_env.sh
#!/bin/bash
JAVA_HOME=/usr/local/java/
KAFKA_HOME=/usr/local/kafka/
export PATH=$PATH:$JAVA_HOME/bin:$KAFKA_HOME/bin/
[root@kafka kafka_2.13-3.6.1]# cd config/
[root@kafka config]# vim server.properties
##每个节点都有一个唯一的编号
broker.id=1
##日志位置
log.dirs=/usr/local/kafka_2.13-3.6.1/data/kafka
[root@kafka kafka_2.13-3.6.1]# vim ./config/zookeeper.properties
##修改日志位置
dataDir=/usr/local/kafka_2.13-3.6.1/data/zookeeper
##使用内置zk启动,先启动zk
[root@kafka ka 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8325
8325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









