






 本文介绍了作者在项目中的工作,包括阅读技术综述,尝试GitHub开源项目LIDA,使用ModelScope社区的GPU资源进行LLM推理,以及遇到的问题和解决方案,如`tokenizer`错误处理和社区资源使用限制。
本文介绍了作者在项目中的工作,包括阅读技术综述,尝试GitHub开源项目LIDA,使用ModelScope社区的GPU资源进行LLM推理,以及遇到的问题和解决方案,如`tokenizer`错误处理和社区资源使用限制。
本次我们组确定了项目的基本目标与路线;四个人完成了分工。我读了1篇LLM主题综述,2篇CoT主题综述。我还尝试了github上的开源大模型项目(LIDA)来练手。
本次我主要体验了ModelScope社区的GPU使用,并尝试了使用社区模型库中的LLM进行推理。我还调研了数学类乃至教育领域的数据集,以供后续任务使用。
1.ModelScope社区试用
登录魔搭社区网站:概览 · 魔搭社区 (modelscope.cn) ,熟悉环境。
注册魔搭社区账号并绑定阿里云账号,获得100小时免费GPU。

试运行实例,走通推理流程。
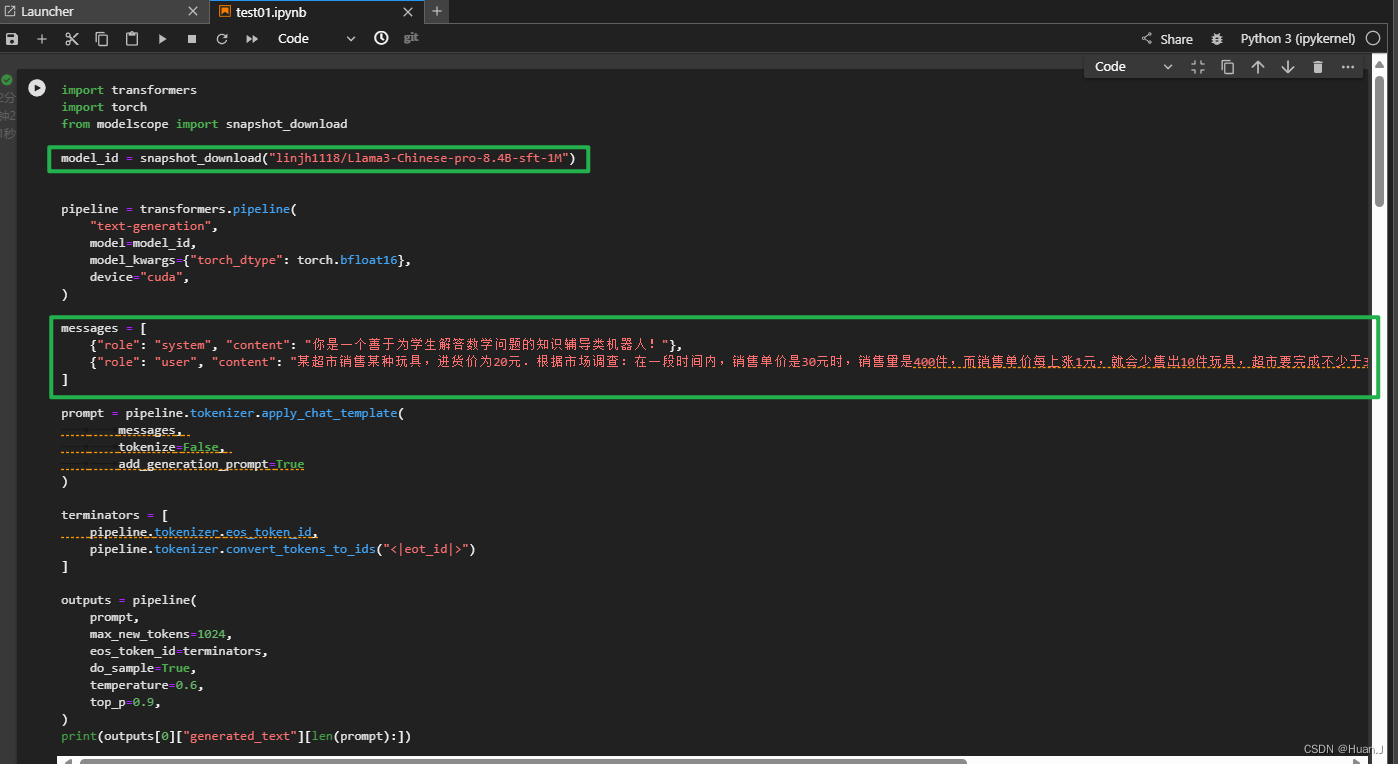
两绿框分别框出模型的地址与需要大模型解答的数学题。
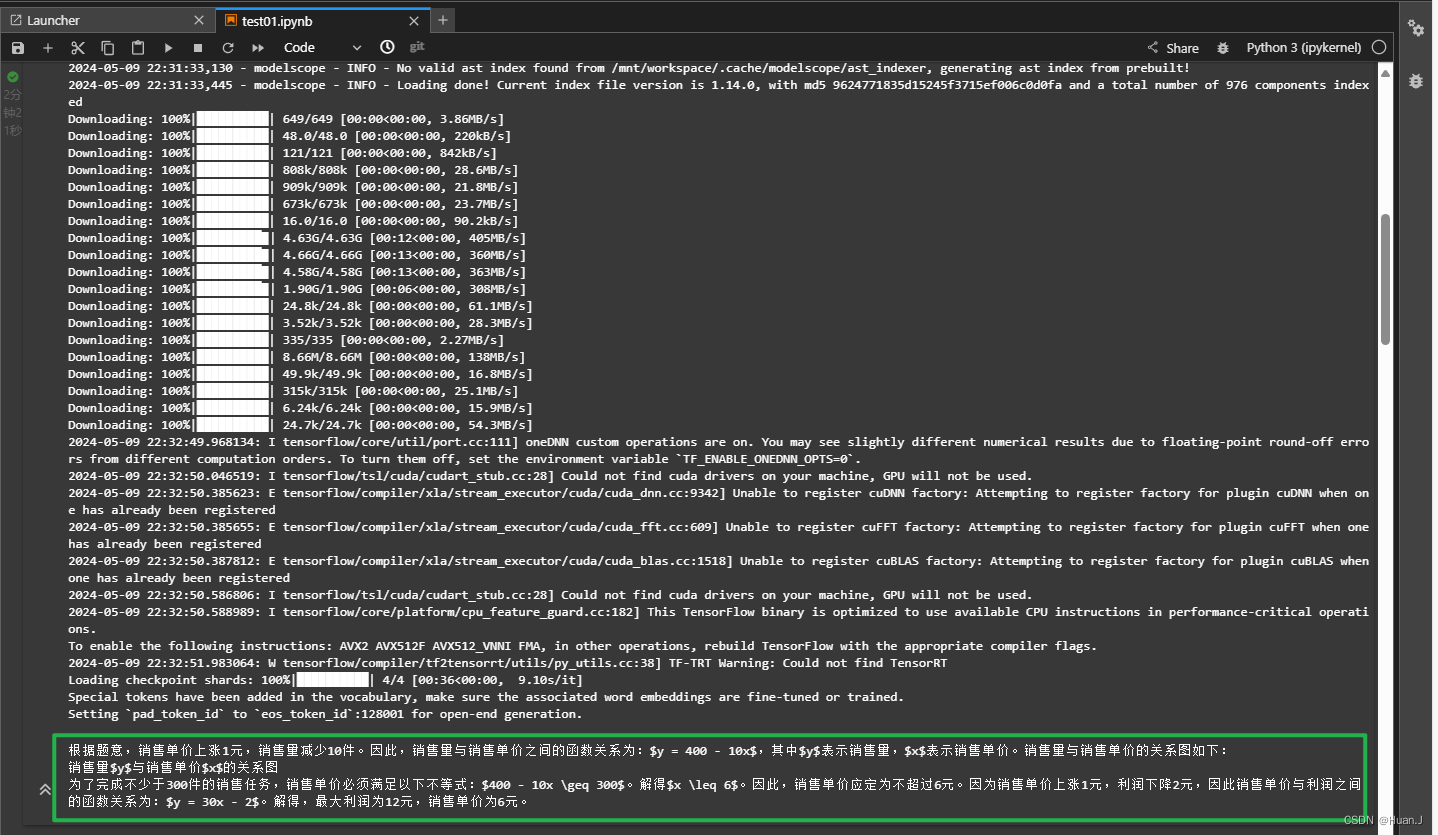
绿框中为大模型针对数学题给出的回答。推理流程跑通。
2.数学题乃至教育领域数据集
项目任务为教育类大模型,主要科目为数学。当前任务为找到合适的数学题数据集。
这里我建议了2个数学相关的数据集:
1.Math23K 是为解决数学单词问题而创建的数据集,包含从互联网上爬取的 23、162 个中文问题。数据集-OpenDataLab
示例:

2.Ape210K是一个大规模的、模板丰富的数学单词问题(MWP)数据集。Ape210K包含210488个问题和56532个模板。https://github.com/Chenny0808/ape210k
示例:

此外,还有一教育类数据集的一个汇总,除包含上面两个数学类数据集以外,还含历史、生物学、地理、哲学、语文以及公务员考试、母婴护理问题对答等各个领域的数据集。该数据集可用于将大模型的教育性由数学学科继续向更广泛领域发展。
参考收藏丨20个中文语料数据集,含数学考试、公务员考题、医患对话等 - 知乎 (zhihu.com)
问题与解决方案
1.报错:name 'tokenizer' is not defined

问题分析:在运行Llama3时会报以上错误。这是因为Intro里的示例程序本身就是错的。
示例程序:

解决方案:
修改为

2.出现实例无法启动的现象
![]()
问题分析:服务器资源有限,使用者达到一定值时其他人就不能使用了。
解决方案:换个时间再尝试,比如凌晨、清晨等时间段(避免可能存在的多人使用、资源紧张现象)。
3.ModelScope社区文档与现实不一致
问题分析:按照文档库中所说,每个项目都有齐全的资料;但实际情况并不符合文档库中理论的情况。
解决方案:文档仅作参考,要根据项目的Intro去实验,去琢磨。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









