






# (2)模型的本地化
上次我们进行了前端界面的编写,并实现了前端对LLM的调用。
这次我们将服务器上已经微调好的模型下载到本地,并在本地运行推理,测试微调后模型的性能。
1.模型的下载
这里有一个大坑。实例一旦关闭,那么你上次微调后的模型output文件夹就会消失。因此一定要及时保存。
另外modelscope社区的notebook不支持下载文件夹,也不支持将文件夹压缩为压缩包。故我们需要点进checkpoint文件夹里,将里面的文件全部下载。
2.模型的加载
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType, get_default_template_type
)
from swift.tuners import Swift
ckpt_dir = 'deepseekAfterFineTune'
model_type = ModelType.deepseek_math_7b_instruct
template_type = get_default_template_type(model_type)
model, tokenizer = get_model_tokenizer(model_type, model_kwargs={'device_map': 'cpu'})
model = Swift.from_pretrained(model, ckpt_dir, inference_mode=True)
template = get_template(template_type, tokenizer)
query = '某超市销售某种玩具,进货价为20元.根据市场调查:在一段时间内,销售单价是30元时,销售量是400件,而销售单价每上涨1元,就会少售出10件玩具,超市要完成不少于300件的销售任务,又要获得最大利润,则销售单价应定为多少元?最大利润为多少元?\n请通过逐步推理来解答问题,并把最终答案放置于\boxed{}中。'
response, history = inference(model, template, query)
print(f'response: {response}')
print(f'history: {history}')需要注意的是通过ckpt_dir设置checkpoint(微调后的文件)的地址,model_type要改成deepseek_math_7b_instruct,query处放置上我们准备好的数学题。
3.模型输出与评价
微调后的DeepSeek输出如下。
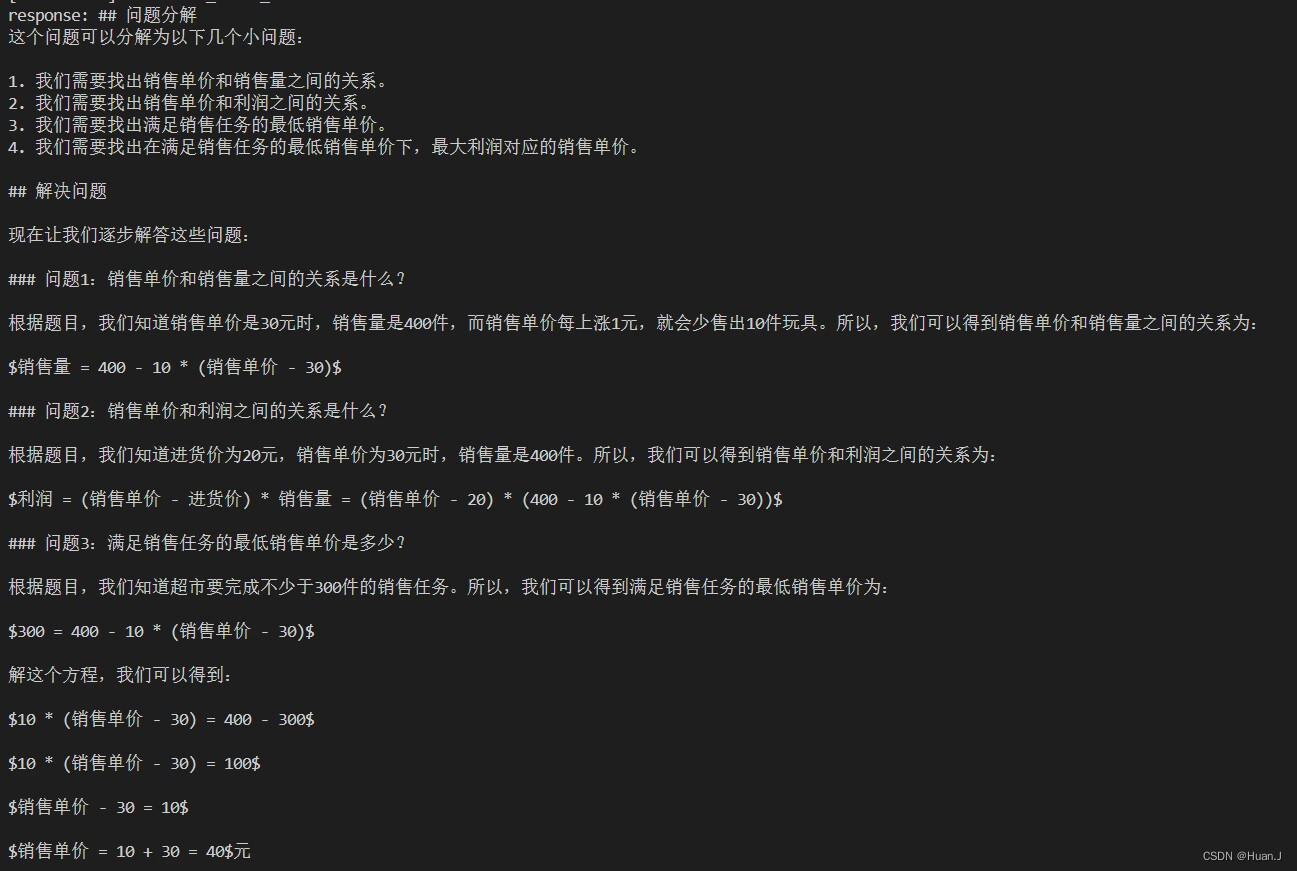

所以,销售单价应定为 $\\boxed{40}$ 元,最大利润 为 $\\boxed{6000}$ 元。']]
答案是正确的。
而我们微调前的模型给出的答案是:
销售单价应定为 $\boxed{40}$ 元,最大利润为 $\boxed{5000}$ 元。
销售单价计算正确,但最大利润计算错误。
从错误到正确,可见微调提升了DeepSeek解答数学题的能力。
这证明我们的工作是有效的,面向中小学数学题的大模型已经取得了不错的进展。
问题与解决方案
1.模型下载地址问题
问题说明:
下载模型一定要指定位置,否则默认下载到C盘!
解决方案:
下载模型的方法是下面这条:
model_dir = snapshot_download('modelscope/Llama2-Chinese-7b-Chat-ms',cache_dir='D:\Program_File\Pycharm_SourceFile\homework\projectTrain_LLM\LLM', revision='v1.0.0')cache_dir (str, Path, optional): Path to the folder where cached files are stored.这里的cache_dir就是下载到C盘的东西,要修改成你希望保存的地址。 不改的话默认下载至C:\Users\86198\.cache。
但是库里还有一些方法内部会调用snapshot_download()方法,且不传参数。一个一个改显然不现实。
建议直接进入snapshot_download()方法,将
if cache_dir is None:
cache_dir = get_cache_dir()改为
if cache_dir is None:
cache_dir = 'D:\Program_File\Pycharm_SourceFile\homework\projectTrain_LLM\LLM'这样,在外部调用snapshot_download()方法且未指定cache_dir时,就会默认下载在你自己指定的目录中了。
2.报错:query最大长度超出。
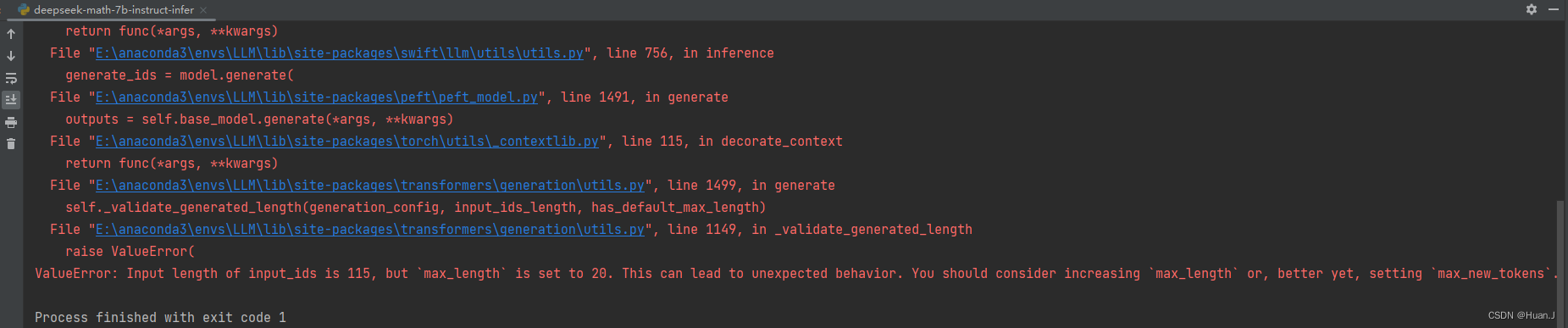
ValueError: Input length of input_ids is 115, but `max_length` is set to 20. This can lead to unexpected behavior. You should consider increasing `max_length` or, better yet, setting `max_new_tokens`.
问题分析:关键在于参数`max_length`或`max_new_tokens`。这两者是用来控制生成文本的长度的。并且更推荐使用后者去控制生成文本的长度。

UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.
进一步分析:根据报错信息,一层层点进去debug。
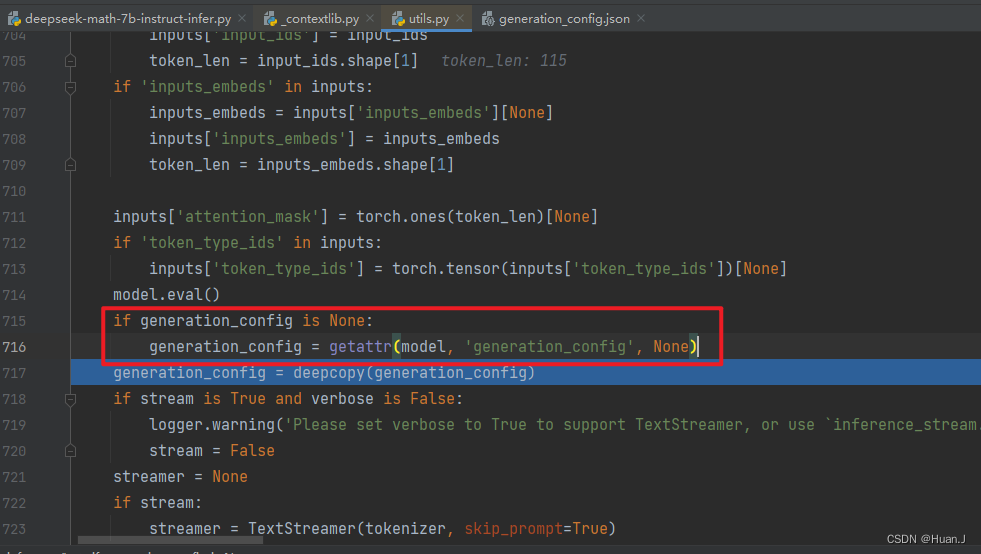
在E:\anaconda3\envs\LLM\Lib\site-packages\swift\llm\utils\utils.py中的第716行发现代码读取了generation_config来对生成进行配置。
在debug中我们发现,实例化的generation_config中确实将max_length设置为20。

这里还很模糊,不确定generation_config是怎么来的。但基本锁定问题出在这儿。
按照文档swift/docs/source/LLM/LLM推理文档.md at main · modelscope/swift (github.com),我们增加一句代码:
model.generation_config.max_new_tokens = 2048 问题解决。
问题解决。
3.报错:ValueError: The current `device_map` had weights offloaded to the disk. Please provide an `offload_folder` for them. Alternatively, make sure you have `safetensors` installed if the model you are using offers the weights in this format.

问题分析:第一次见这个报错,先查资料。【大模型部署实践-2】本地模型参数调用踩坑记录_you can't move a model that has some modules offlo-CSDN博客
推测为显存不足。但是我调用的方法与博客里不完全一样,添加参数后也没有解决报错。
对device_map的补充:
![]()
尝试将device_map设为cpu,又出现新的报错:
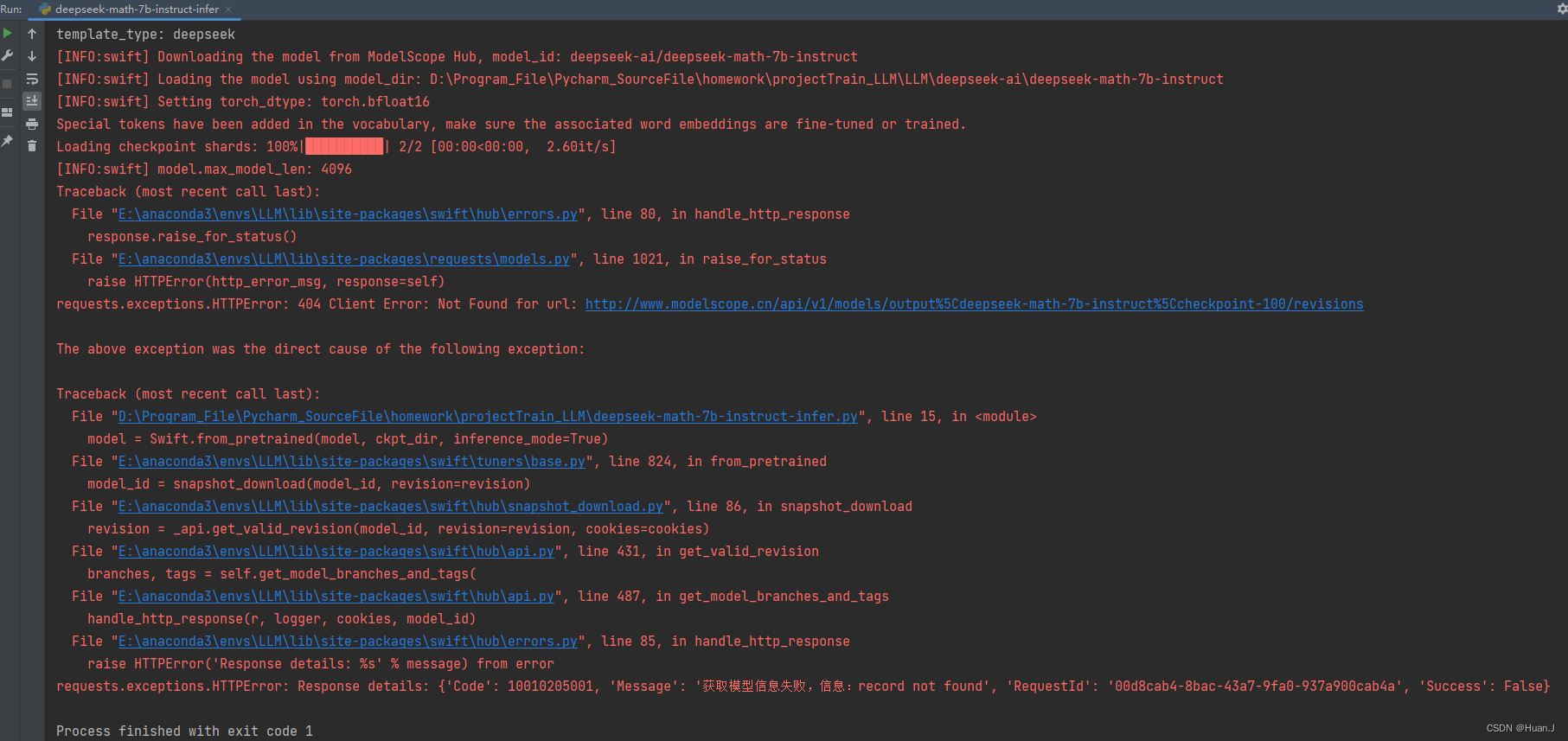
尝试将device_map设为cuda:0,出现了下一个报错。
4.报错:Torch not compiled with CUDA enabled
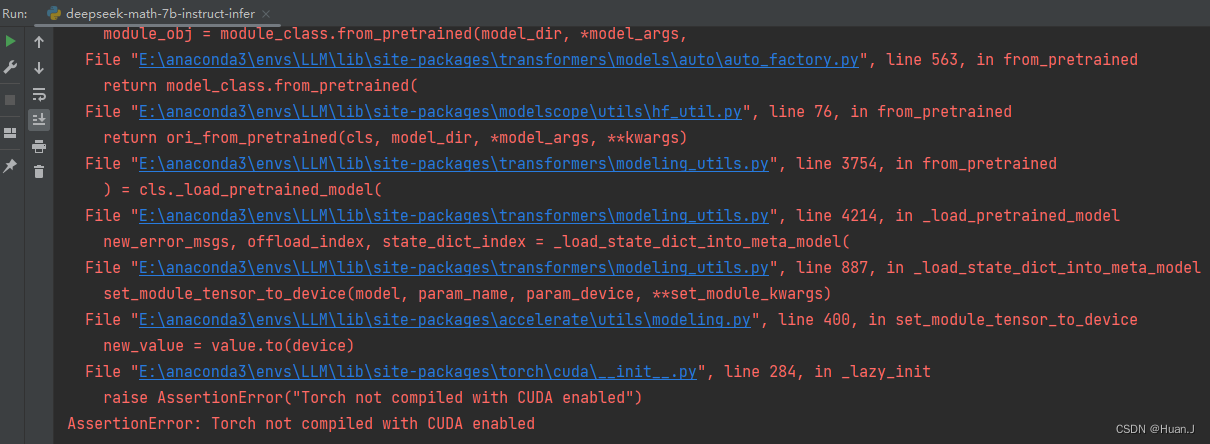
问题分析:看样子是gpu的问题。后来经检查发现该虚拟环境没有安装Pytorch。
解决方案:执行
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
安装Pytorch即可。
5.报错:cuda out of memory

说明:这是没办法了,7b的模型本地5.6G的专用GPU内存和7.7G的共享GPU内存确实不够用。















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









