






1. 插入排序
步骤:
1.从第一个元素开始,该元素可以认为已经被排序
2.取下一个元素tem,从已排序的元素序列从后往前扫描
3.如果该元素大于tem,则将该元素移到下一位
4.重复步骤3,直到找到已排序元素中小于等于tem的元素
5.tem插入到该元素的后面,如果已排序所有元素都大于tem,则将tem插入到下标为0的位置
重复步骤2~5
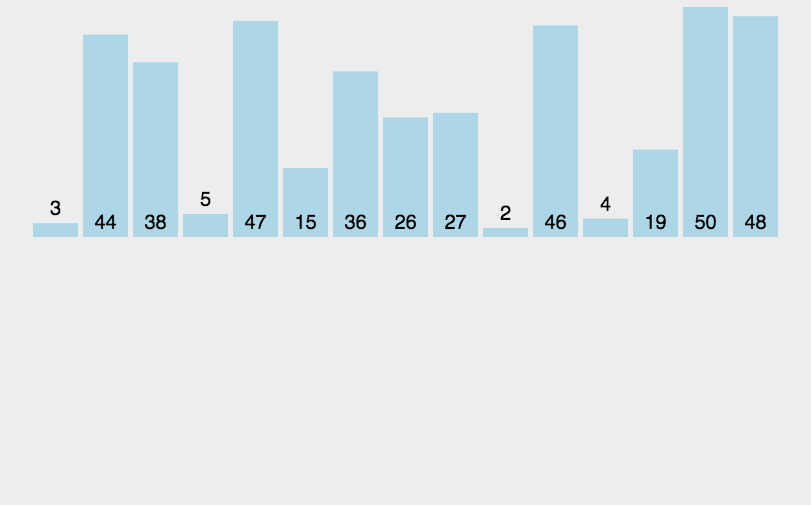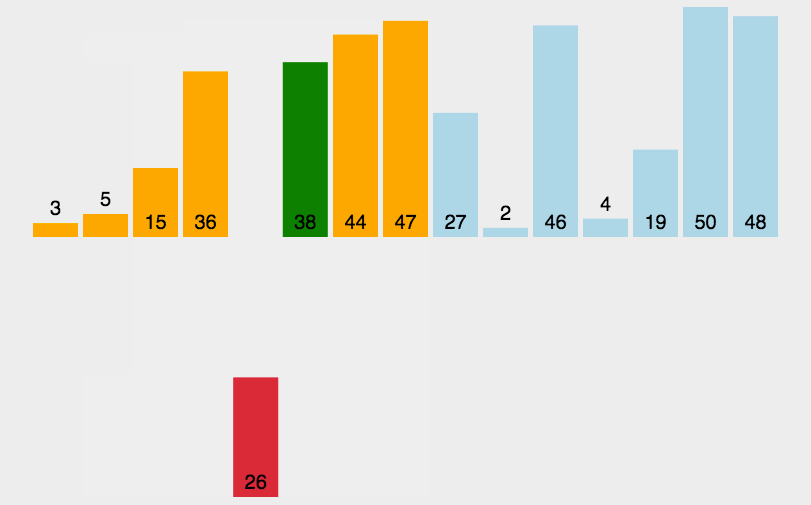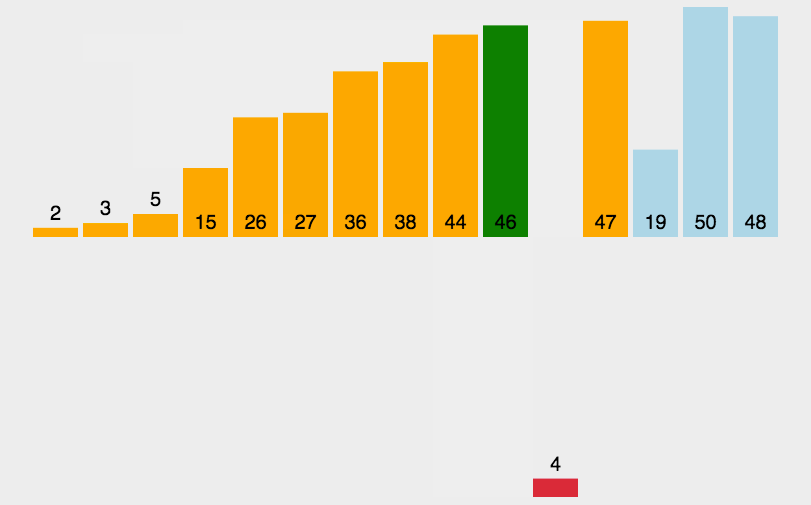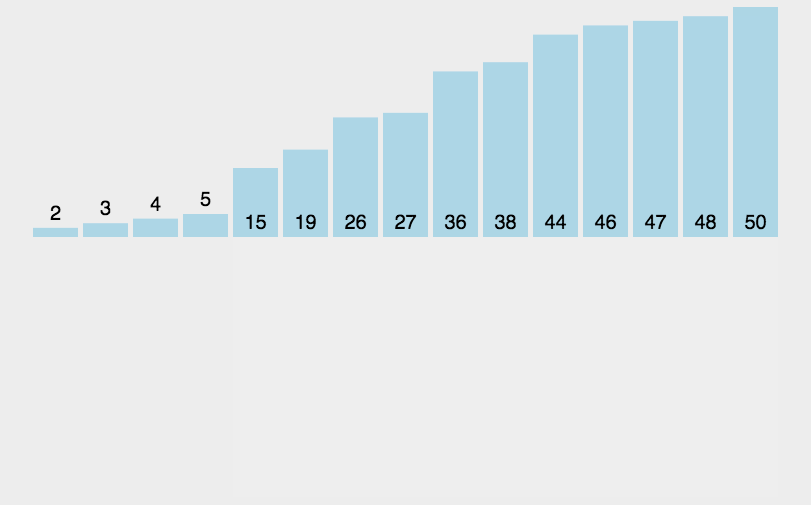
思路:
在待排序的元素中,假设前n-1个元素已有序,现将第n个元素插入到前面已经排好的序列中,使得前n个元素有序。按照此法对所有元素进行插入,直到整个序列有序。
但我们并不能确定待排元素中究竟哪一部分是有序的,所以我们一开始只能认为第一个元素是有序的,依次将其后面的元素插入到这个有序序列中来,直到整个序列有序为止。
时间复杂度:最坏情况下为O(N*N),此时待排序列为逆序,或者说接近逆序
最好情况下为O(N),此时待排序列为升序,或者说接近升序。
空间复杂度:O(1)
2.希尔排序
1.先选定一个小于N的整数gap作为第一增量,然后将所有距离为gap的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复上述操作…
2.当增量的大小减到1时,就相当于整个序列被分到一组,进行一次直接插入排序,排序完成。

//希尔排序
void ShellSort(int* arr, int n)
{
int gap = n;
while (gap>1)
{
//每次对gap折半操作
gap = gap / 2;
//单趟排序
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tem = arr[end + gap];
while (end >= 0)
{
if (tem < arr[end])
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = tem;
}
}
}
3.选择排序
思路:
每次从待排序列中选出一个最小值,然后放在序列的起始位置,直到全部待排数据排完即可。
实际上,我们可以一趟选出两个值,一个最大值一个最小值,然后将其放在序列开头和末尾,这样可以使选择排序的效率快一倍。
//选择排序
void swap(int* a, int* b)
{
int tem = *a;
*a = *b;
*b = tem;
}
void SelectSort(int* arr, int n)
{
//保存参与单趟排序的第一个数和最后一个数的下标
int begin = 0, end = n - 1;
while (begin < end)
{
//保存最大值的下标
int maxi = begin;
//保存最小值的下标
int mini = begin;
//找出最大值和最小值的下标
for (int i = begin; i <= end; ++i)
{
if (arr[i] < arr[mini])
{
mini = i;
}
if (arr[i] > arr[maxi])
{
maxi = i;
}
}
//最小值放在序列开头
swap(&arr[mini], &arr[begin]);
//防止最大的数在begin位置被换走
if (begin == maxi)
{
maxi = mini;
}
//最大值放在序列结尾
swap(&arr[maxi], &arr[end]);
++begin;
--end;
}
}
4.冒泡排序
思路:
左边大于右边交换一趟排下来最大的在右边
//冒泡排序
void BubbleSort(int* arr, int n)
{
int end = n;
while (end)
{
int flag = 0;
for (int i = 1; i < end; ++i)
{
if (arr[i - 1] > arr[i])
{
int tem = arr[i];
arr[i] = arr[i - 1];
arr[i - 1] = tem;
flag = 1;
}
}
if (flag == 0)
{
break;
}
--end;
}
}
5.堆排序
什么是堆
堆是一种叫做完全二叉树的数据结构,可以分为大根堆,小根堆,而堆排序就是基于这种结构而产生的一种程序算法。
堆的分类
大根堆:每个节点的值都大于或者等于他的左右孩子节点的值
小根堆:每个结点的值都小于或等于其左孩子和右孩子结点的值
排序思想
1.首先将待排序的数组构造成一个大根堆,此时,整个数组的最大值就是堆结构的顶端
2.将顶端的数与末尾的数交换,此时,末尾的数为最大值,剩余待排序数组个数为n-1
3.将剩余的n-1个数再构造成大根堆,再将顶端数与n-1位置的数交换,如此反复执行,便能得到有序数组
注意:升序用大根堆,降序就用小根堆(默认为升序)
6.快速排序
一、简介
快速排序是(Quick sort)是对冒泡排序的一种改进,是非常重要且应用比较广泛的一种高效率排序算法。
二、算法思路
快速排序是通过多次比较和交换来实现排序,在一趟排序中把将要排序的数据分成两个独立的部分,对这两部分进行排序使得其中一部分所有数据比另一部分都要小,然后继续递归排序这两部分,最终实现所有数据有序。
大致步骤如下:
首先设置一个分界值也就是基准值又是也称为监视哨,通过该分界值将数据分割成两部分。
将大于或等于分界值的数据集中到右边,小于分界值的数据集中到左边。一趟排序过后,左边部分中各个数据元素都小于分界值,而右边部分中各数据元素都大于或等于分界值,且右边部分个数据元素皆大于左边所有数据元素。
然后,左边和右边的数据可以看成两组不同的部分,重复上述1和2步骤
当左右两部分都有序时,整个数据就完成了排序。















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









