






多机多卡训练SD系列模型(二)
前言
尝试使用Dreambooth的方式,所以迁到了kohya-trainer这个项目
Dreambooth
论文链接
https://arxiv.org/abs/2208.12242
代码链接
https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
Dreambooth主要能用来训练一个特定对象的物体,比如一个叫TOM的猫,或者是个特定的动漫人物,通过搭配图片,tag,prompt,让特定的词与特殊的图像做绑定,来生成特定的物体。
Dreambooth既可以用来直接对底模微调,也可以作为一种方式来训练LoRA模型,通常会与正则化数据一起使用(非必需)。
相关内容在这里有中文文档
https://github.com/bmaltais/kohya_ss/tree/master
运行脚本
accelerate launch --num_cpu_threads_per_process 1 train_db.py
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型的目录>
--dataset_config=<数据准备时创建的.toml文件>
--output_dir=<训练模型的输出目录>
--output_name=<训练模型输出时的文件名>
--save_model_as=safetensors
--prior_loss_weight=1.0
--max_train_steps=1600
--learning_rate=1e-6
--optimizer_type="AdamW8bit"
--xformers
--mixed_precision="fp16"
--cache_latents
--gradient_checkpointing
其中accelerate库可以指定各种训练配置,将在后续用作多级多卡训练
--num_cpu_threads_per_process 1是其中一个参数,

原文档中提到的prior_loss_weight个人认为比较看正则化数据的数量和质量,1.5上下也是不错的。
正则化数据是作为特定名称的后的类数据,比如:
训练一只叫lucky的狗,这个文件名可以取10_lucky dog,这里的10是图像重复次数,lucky是特定名称,而dog就是这个类,这个数据中就lucky的图像。
10_lucky dog
1_dog
1_dog就是正则化图像,数据就是全部不同种类的狗的数据,而前面的数字取值要大致为一张lucky,一张其他的狗也就是
训练数据重复次数*训练数据集图像 == 正则化数据重复次数*正则化数据集图像
比如12张lucky的图像,重复十次就有120张,如果正则化图像有60张,就重复两次。
注意尽量正则化图像不要包含训练图像,如果要训练的是一个大类,而且数据量很大,可以均分,然后一半做训练集,一半做正则集(具体会在kohya-trainer部分)
一般dreambooth微调出来的模型效果会很明显,并且过拟合很快,判断过拟合可以用生成图片质量如何,噪声含量来判断,如果微调后的底模质量骤降,就是过拟合了。
数据准备
dreambooth的数据准备主要分两部分,一个部分是数据集准备,一部分是文件命名,kohya_ss中提到了三种图文训练方式
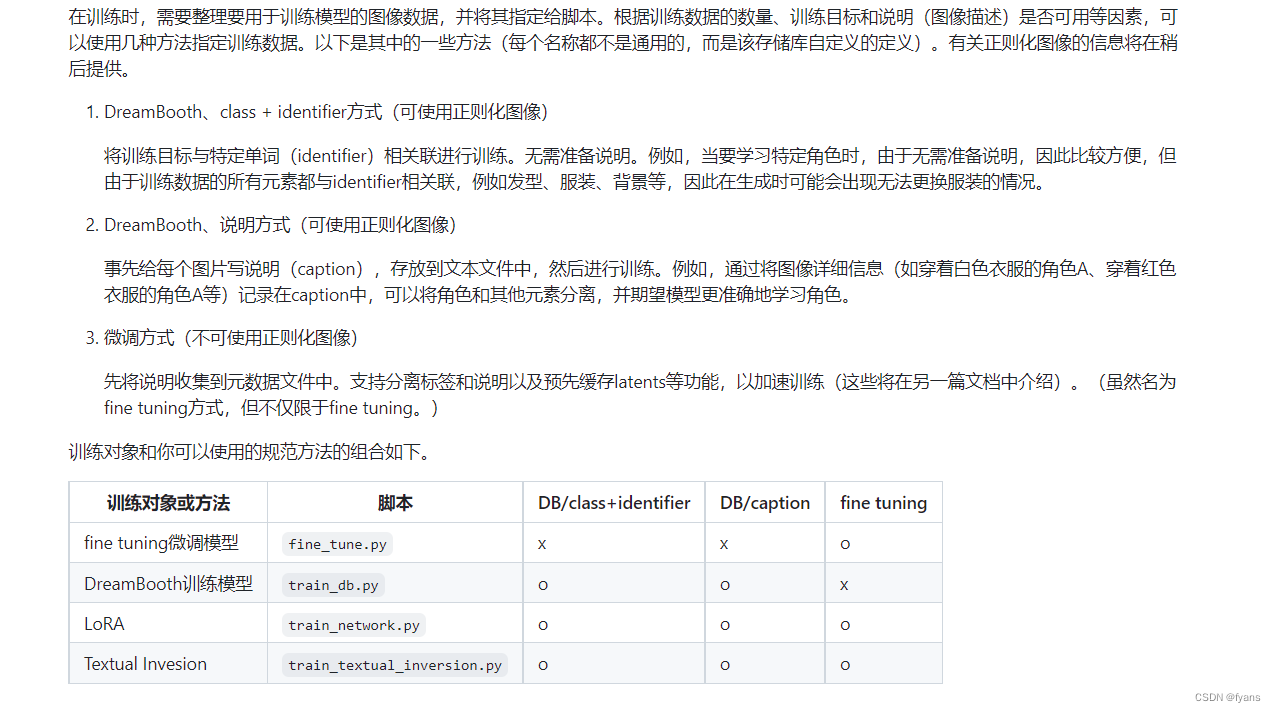
这里首先是用到了class+identifier和caption的方法
数据集
首先按照要求训练的数据集和正则数据集依照NUM_NAME CLASS 这样的命名方式来取名后,(这里我才知道linux除了用单引号来使用含空格的文件名,比如/'a dog'还可以用/a\ dog反斜杠加空格来使用文件0.o)
然后就是对数据打标,其实建议用Deepbooru来给能明显形容的打标,这样也好check,不然就是一句一句看,正则化数据也是可以打标的,虽然会稍微增加训练时间,并且会对数据集要求更高,但是效果会好一些。
有些打标是默认以txt文件储存的,所以需要在配置文件中加上
--caption_extension = ".txt"
或者是在处理的时候以.caption格式
结果
最后储存的模型是依照.ckpt的格式来储存模型,可以用webui

选择需要测试的模型来测试,最好在达标的时候添加一些特定的触发词,可以用-来连接或者其他,比如a dog name lucky,触发词和txt2image的原理还没有过多了解。
总结
这次训练主要是因为环境中本身就已经用了lora-script的项目,很多环境是通用的,就直接从kohya_ss中拉下来train_db.py的文件直接跑了,上面还是有很多比如打标,剪裁,命名的步骤,这些在后面的项目中其实都可以省略了。后面会研究用dreambooth来训练lora,以免污染到底模。















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









