






YOLOv9
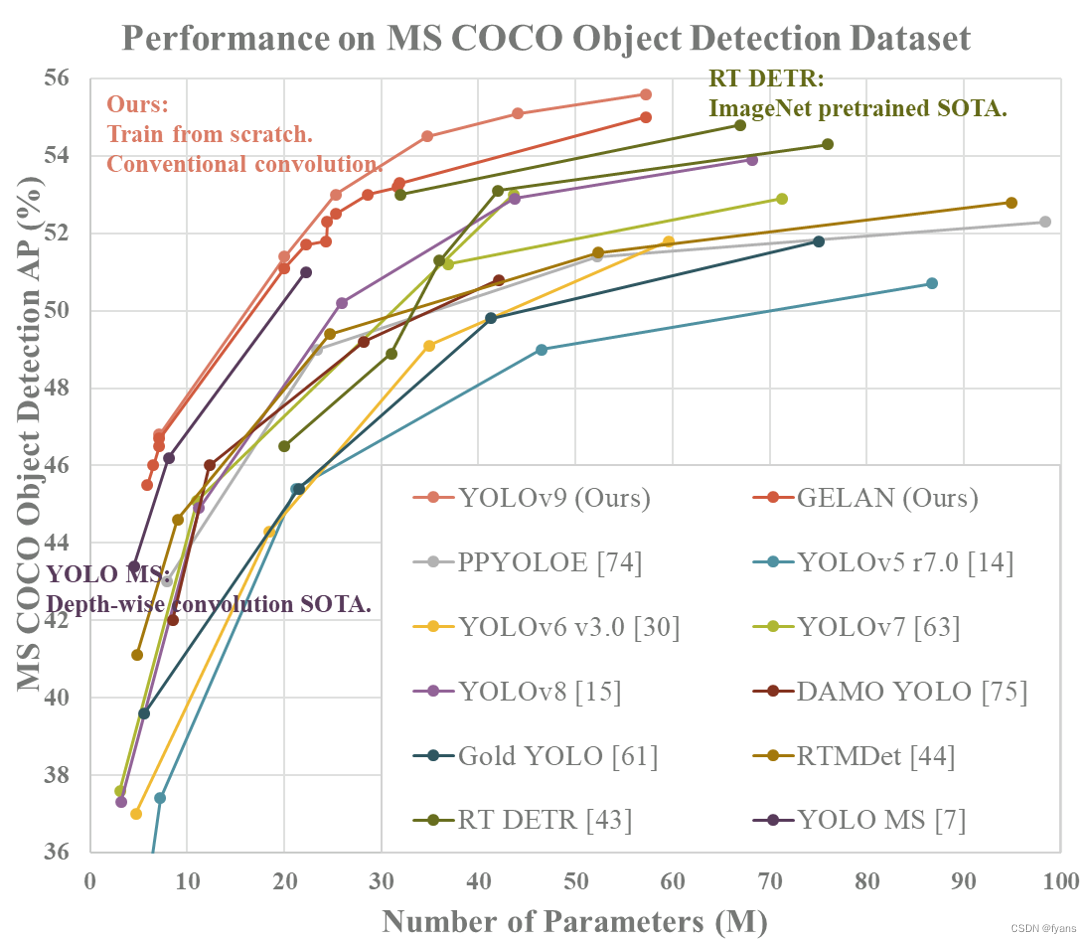
YOLOv9是近期由 YOLOv7 团队提出的,引入了 PGI 概念来应对深度网络实现多个目标所需的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。同期发布的还有一种新的轻量级网络架构GELAN。 GELAN 的架构证实了 PGI 在轻量级模型上取得了优异的结果。
https://github.com/WongKinYiu/yolov9
本文记录了使用YOLOv9在安全帽检测上的训练,使用ubuntu22.04,RTX4090
准备环境
yolov9官方提供了一个docker的拉取代码
# create the docker container, you can change the share memory size if you have more.
nvidia-docker run --name yolov9 -it -v your_coco_path/:/coco/ -v your_code_path/:/yolov9 --shm-size=64g nvcr.io/nvidia/pytorch:21.11-py3
# apt install required packages
apt update
apt install -y zip htop screen libgl1-mesa-glx
# pip install required packages
pip install seaborn thop
# go to code folder
cd /yolov9
也可以自己写一个Dockerfile
FROM python:3.10
ENV PYTHONBUFFERED=1
ENV NVIDIA_VISIBLE_DEVICES=all
ENV NVIDIA_DRIVER_CAPABILITIES=compute,utility
WORKDIR /usr/src/
RUN apt-get update
RUN python3.10 -m pip install --upgrade pip
然后将GPU和yolov9目录挂载进去
进入环境后拉取项目
创建虚拟环境安装依赖
python3 -m venv yolov9
source yolov9/bin/activate
pip3 install -r requirement.txt

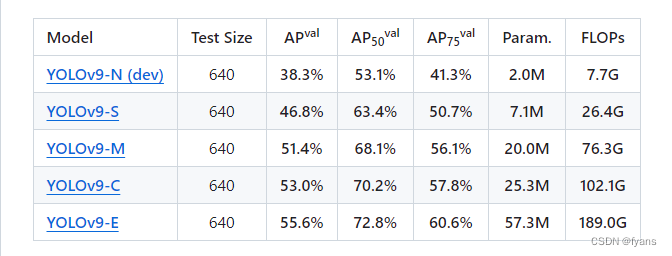
目前yolov9还只能下在-c和-e参数量的模型
这里选取YOLOv9-C来训练,下载后放入容器该目录下
(这里这个是错误的,下载的是yolov9-c-convert)
模型应该在这
准备数据集
这里使用了开源数据集
https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset
也可以在各大平台上搜,挺多的(百度云是真的逆天的慢,这个有Google的链接快很多)
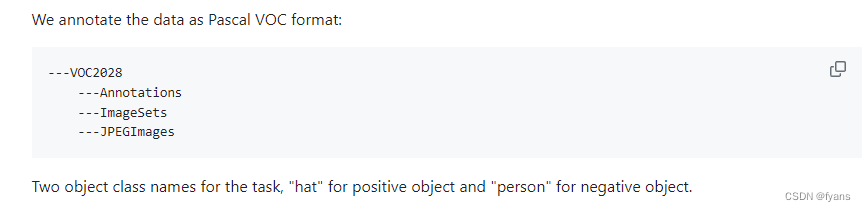
这个数据集是VOC格式的,需要转化为yolo数据集格式,
VOC格式:
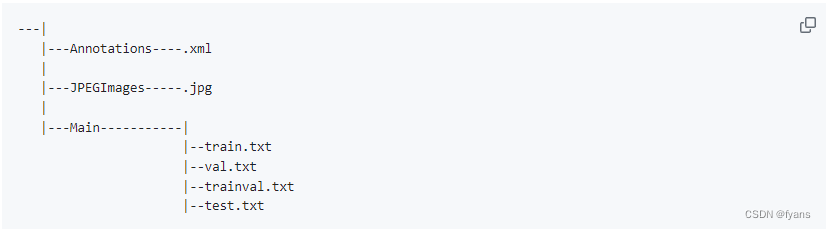
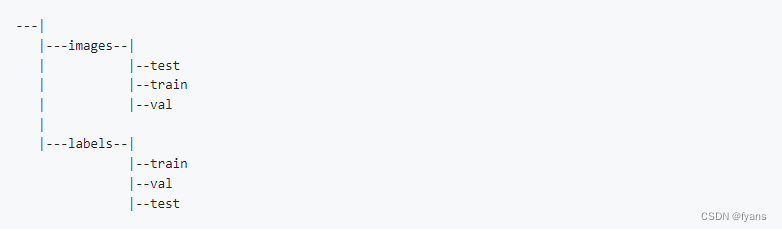
YOLO格式:
用到了https://github.com/ssaru/convert2Yolo这个项目
同样的,先拉区项目,创建虚拟环境,安装依赖
git clone https://github.com/ssaru/convert2Yolo.git
python3 -m venv convert2Yolo
source convert2Yolo/bin/activate
pip3 install -r requirement.txt
项目提供了使用示例
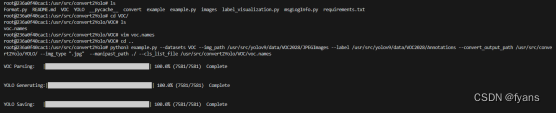
python3 example.py --datasets VOC --img_path ~/VOCdevkit/VOC2012/JPEGImages/ --label ~/VOCdevkit/VOC2012/Annotations/ --convert_output_path ~/YOLO/ --img_type ".jpg" --manifest_path ./ --cls_list_file ~/VOC/voc.names
>>
VOC Parsing: |████████████████████████████████████████| 100.0% (17125/17125) Complete
YOLO Generating:|████████████████████████████████████████| 100.0% (17125/17125)Complete
YOLO Saving: |████████████████████████████████████████| 100.0% (17125/17125) Complete
如果报错类似这种
YOLO Generating Result : False, msg : ERROR : 'hat' is not in list, moreInfo : <class 'ValueError'> Format.py 704
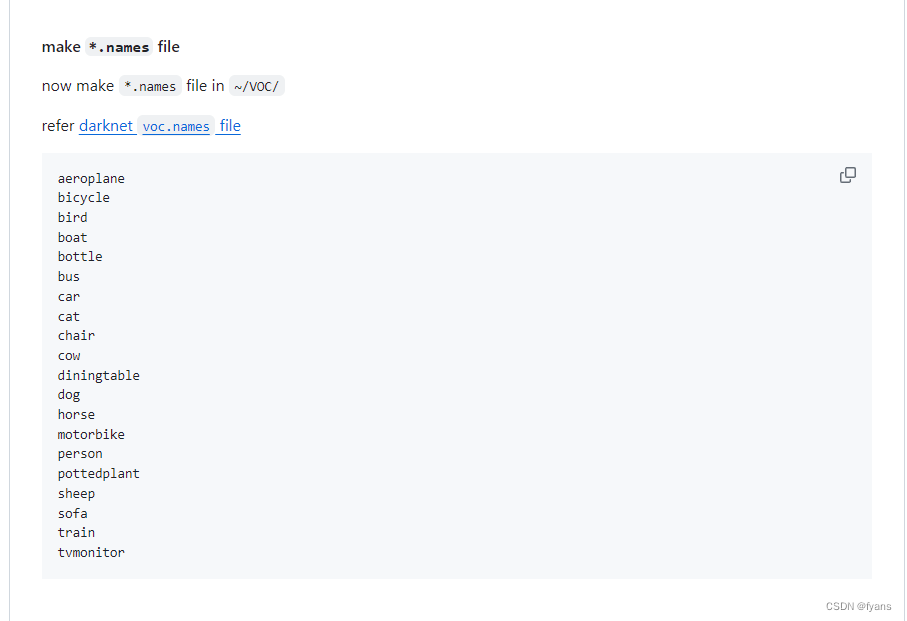
就按照这个步骤创建完文件后,编辑文件添加上去就好了
运行完后检查看看label文件对不对
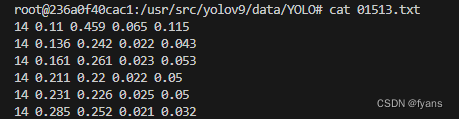
最好看看同目录下的manifest.txt文件,我在使用过程中会有点问题,这个项目是很早之前的了,对文件划分的方法有点bug,会导致和数据集图片的命名不同(这一个bug还没细看,后面再看看他的代码),如果报错了,就找其他项目来转换
https://github.com/yurizzzzz/Helmet-Detection-YoloV5这个项目也有转换代码,目前还没尝试
划分数据集
数据集下好后就划分数据集,这里用的是其他作者的https://blog.csdn.net/heart_warmonger/article/details/136249119
这个是项目链接,可以自行查看
数据集不是特别好,所以对划分数据集的代码进行了一点点修改,添加了异常跳过,

代码:
import shutil
import random
import os
# 原始路径
image_original_path = "/usr/src/yolov9/data/datasets1/datasets/"
label_original_path = "/usr/src/yolov9/data/datasets1/datasets/"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/images/train/")
train_label_path = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/labels/train/")
# 验证集路径
val_image_path = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/images/val/")
val_label_path = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/labels/val/")
# 测试集路径
test_image_path = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/images/test/")
test_label_path = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/labels/test/")
# 训练集目录
list_train = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/sets/train.txt")
list_val = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/sets/val.txt")
list_test = os.path.join(cur_path, "/usr/src/yolov9/data/datasets/sets/test.txt")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
def del_file(path):
for i in os.listdir(path):
file_data = os.path.join(path, i)
os.remove(file_data)
def mkdir():
paths = [train_image_path, train_label_path, val_image_path, val_label_path, test_image_path, test_label_path]
for path in paths:
if not os.path.exists(path):
os.makedirs(path)
else:
del_file(path)
def clearfile():
paths = [list_train, list_val, list_test]
for path in paths:
if os.path.exists(path):
os.remove(path)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
val_test = [i for i in list_all_txt if not i in train]
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_original_path, name + '.jpg')
srcLabel = os.path.join(label_original_path, name + ".txt")
try:
if i in train:
dst_train_Image = os.path.join(train_image_path, name + '.jpg')
dst_train_Label = os.path.join(train_label_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = os.path.join(val_image_path, name + '.jpg')
dst_val_Label = os.path.join(val_label_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = os.path.join(test_image_path, name + '.jpg')
dst_test_Label = os.path.join(test_label_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
except Exception as e:
print(f"Error copying files: {e}")
continue
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()
检查一遍看看数据集大致数量有没有问题即可
编写配置文件
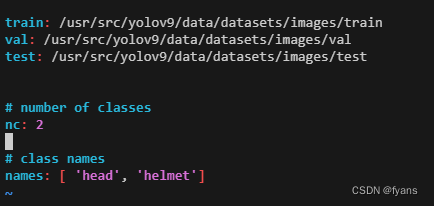
yolov9-yaml文件在
在train.py文件中有启动命令各种参数的解释
这边给个中文解释
def parse_opt(known=False):
parser = argparse.ArgumentParser()
# parser.add_argument('--weights', type=str, default=ROOT / 'yolo.pt', help='initial weights path')
# parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--weights', type=str, default='', help='初始权重路径')
parser.add_argument('--cfg', type=str, default='yolo.yaml', help='模型配置文件路径')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件路径')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='超参数文件路径')
parser.add_argument('--epochs', type=int, default=100, help='总训练周期数')
parser.add_argument('--batch-size', type=int, default=16, help='所有 GPU 的总批量大小,-1 表示自动批量大小')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='训练、验证图像大小(像素)')
parser.add_argument('--rect', action='store_true', help='使用矩形训练')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='恢复最近的训练')
parser.add_argument('--nosave', action='store_true', help='仅保存最终检查点')
parser.add_argument('--noval', action='store_true', help='仅在最终周期验证')
parser.add_argument('--noautoanchor', action='store_true', help='禁用自动锚点')
parser.add_argument('--noplots', action='store_true', help='不保存绘图文件')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='对 x 代进行超参数演化')
parser.add_argument('--bucket', type=str, default='', help='gsutil 存储桶')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='图像 --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='使用加权图像选择进行训练')
parser.add_argument('--device', default='', help='cuda 设备,例如 0 或 0,1,2,3 或 cpu')
parser.add_argument('--multi-scale', action='store_true', help='变动 img-size 的 +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='将多类数据训练为单类')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW', 'LION'], default='SGD', help='优化器')
parser.add_argument('--sync-bn', action='store_true', help='使用 SyncBatchNorm,仅在 DDP 模式下可用')
parser.add_argument('--workers', type=int, default=8, help='最大数据加载器工作进程数(每个 RANK 在 DDP 模式下)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='保存至项目/名称')
parser.add_argument('--name', default='exp', help='保存至项目/名称')
parser.add_argument('--exist-ok', action='store_true', help='现有项目/名称可用,不递增')
parser.add_argument('--quad', action='store_true', help='四重数据加载器')
parser.add_argument('--cos-lr', action='store_true', help='余弦学习率调度器')
parser.add_argument('--flat-cos-lr', action='store_true', help='平坦余弦学习率调度器')
parser.add_argument('--fixed-lr', action='store_true', help='固定学习率调度器')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='标签平滑 epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping 容忍度(不改善的周期数)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='冻结层:backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='每 x 个周期保存一次检查点(如果 < 1 则禁用)')
parser.add_argument('--seed', type=int, default=0, help='全局训练种子')
parser.add_argument('--local_rank', type=int, default=-1, help='自动 DDP 多 GPU 参数,不要修改')
parser.add_argument('--min-items', type=int, default=0, help='实验性')
parser.add_argument('--close-mosaic', type=int, default=0, help='实验性')
# Logger 参数
parser.add_argument('--entity', default=None, help='实体')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='上传数据,"val" 选项')
parser.add_argument('--bbox_interval', type=int, default=-1, help='设置边界框图像记录间隔')
parser.add_argument('--artifact_alias', type=str, default='latest', help='要使用的数据集 artifact 版本')
return parser.parse_known_args()[0] if known else parser.parse_args()
其中路径类的参数有
–weights : yolov9-c.pt的绝对路径
–cfg : yolov9-c.yaml的绝对路径
–data : data.yaml的绝对路径
–project : 训练后文件保存的绝对路径
秉持着先跑起来再说的信念,就先修改这几个,其他都用默认参数
编写启动脚本
#!/bin/bash
# 设置绝对路径
WEIGHTS_PATH="/absolute/path/to/yolov9-c.pt"
CFG_PATH="/absolute/path/to/yolov9-c.yaml"
DATA_PATH="/absolute/path/to/data.yaml"
HYP_PATH="/absolute/path/to/hyp.scratch-high.yaml"
PROJECT_PATH="/absolute/path/to/save/project"
# 启动训练
python train.py --weights $WEIGHTS_PATH --cfg $CFG_PATH --data $DATA_PATH --hyp $HYP_PATH --project $PROJECT_PATH
–hyp 这个默认路径在data/hyp下面,但是下面只有一个hyp.scratch-high.yaml文件,而默认的是hyp.scratch-low.yaml,所以这里先改成hyp.scratch-high.yaml,
这里又遇到了容器共享内存的问题,这个问题在之前使用kohya的训练脚本时候也遇到了这个问题

docker的共享内存默认是64MB,在docker启动的时候忘记添加命令了
--shm-size 5g,或者在docker-compose下面加上 shm_size: 5gb
1.查看容器ID号:
docker ps -a
找到对应容器
2.获取完整容器名:
docker inspect <container_id> | grep Id
3.修改对应容器的配置文件:
vim /var/lib/docker/containers/<full_container_id>/hostconfig.json
找到ShmSize修改对应数值,单位为KB,默认是64M,即67108864(6410241024)
4.重启docker服务
systemctl restart docker
但是重启docker服务的代价很大,如果有很多个容器在运行建议不要重启,所以还是docker cp 把里面的东西拷贝出来,然后重新拉起一个镜像

成功修改,再运行一遍
报错
attributeerror: ‘FreeTypeFont‘ object has no attribute ‘getsize‘
上述划分数据集的作者也在文章中写到了

默认的batchsize是16,24g显存吃不消,改成8也吃不消,改成4好一些,(因为是矩阵计算,一般2乘方会好一些2,4,8,16这样的,具体内容在计算机组成原理里提到过,(我忘了TT),这次我改成了6,测试一下4和6的区别)
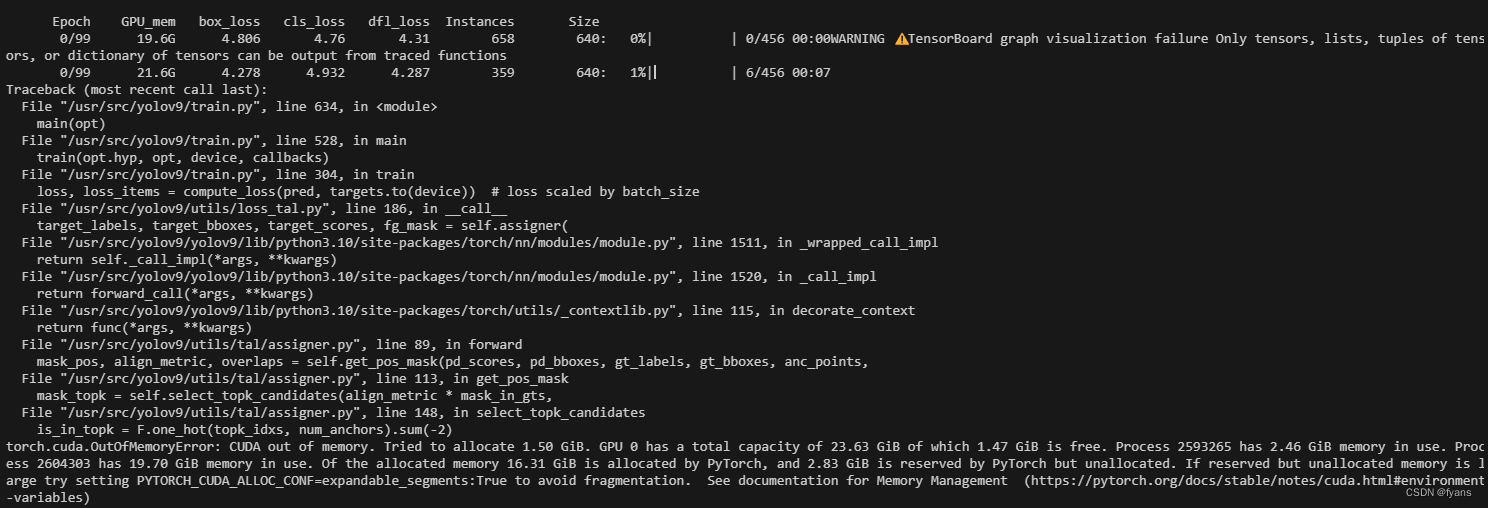
Batch-size为6时,time 2.13,mem 11g

Batch-size为8时 time2.10,mem 15g
时间差不多,显存比较吃紧
100轮3个小时左右
查看结果


标注全是反的。。
刚刚看了一下代码,跑的是yolov9-c-convert,应该跑yolov9-c.pt的文件,
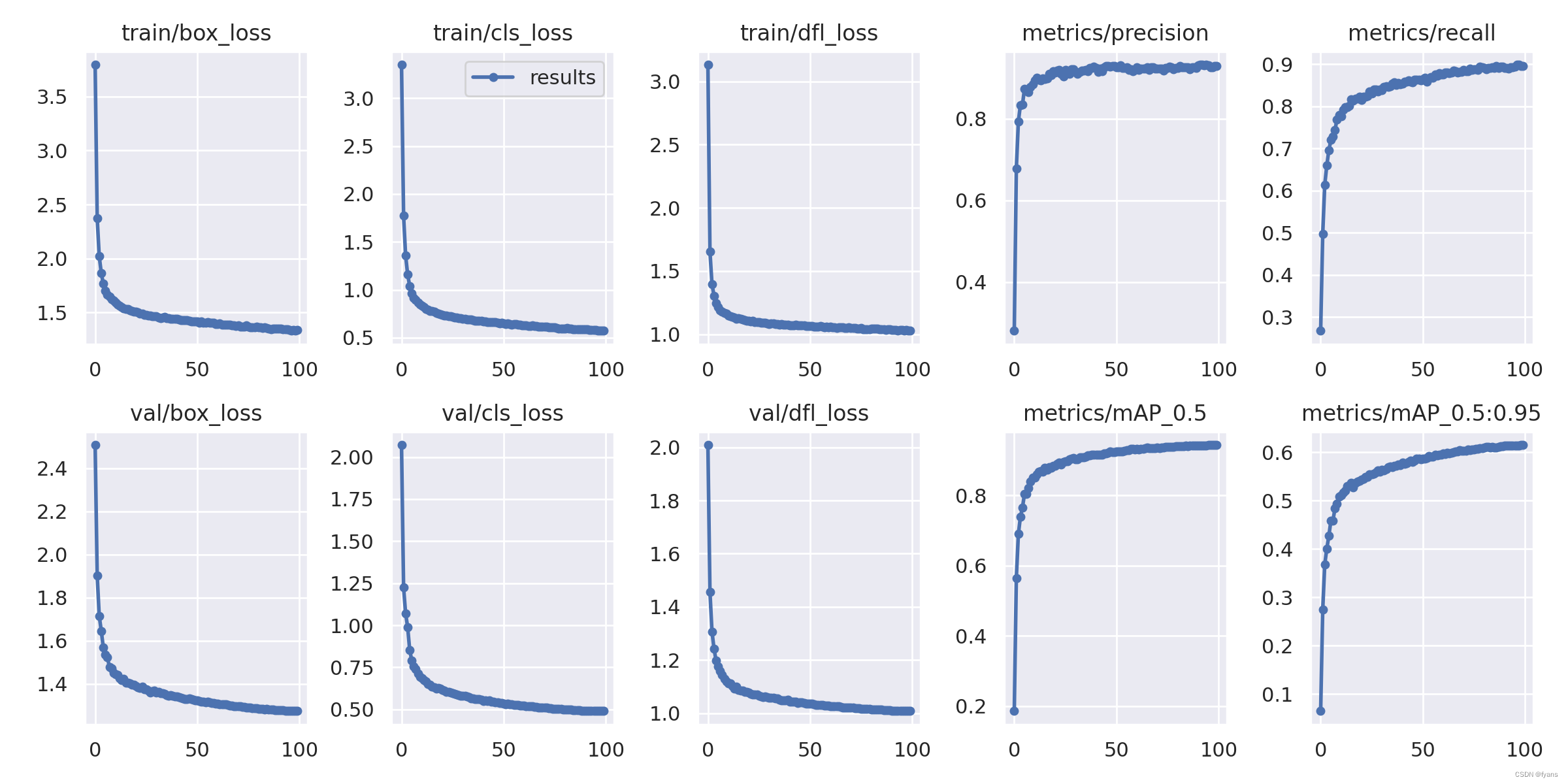
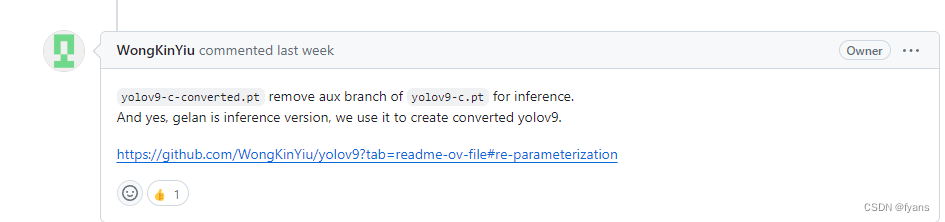

这里更正一个地方,结果的标注有问题可能是和yaml文件配置有关,在后续文章中会重新训练















 1885
1885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









