










小谈:一直想整理机器学习的相关笔记,但是一直在推脱,今天发现知识快忘却了(虽然学的也不是那么深),但还是浅浅整理一下吧,便于以后重新学习。
📙参考:ysu期末复习资料和老师的课件
目录
1.机器学习的理解
1.1 机器学习的定义
机器学习专门研究计算机怎样模拟或实现人类的学习行为,以获取新知识或技能,重新组织已有的知识结构使之不断改善自己的性能。
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进,通过参数优化的学习模型,能够用于预测相关问题的输出。
1.2 机器学习的发展历程
推理期→知识期→学科形成→繁荣期
- 推理期:认为只要给机器赋予逻辑推理能力,机器就能具有智能
- 知识期:认为要使机器具有智能,就必须设法使机器拥有知识
- 学科形成:20世纪80年代,机器学习成为一个独立学科领域并开始迅速发展、各种机器学习技术百花齐放
- 繁荣期:20世纪90年代后,统计学习方法占主导
1.3 机器学习的方式

2.机器学习的一些基本概念
2.1 机器学习中的专业术语
- 样本(sample)或者输入(input):送入模型的数据点。
- 目标(traget)真实值。对于外部数据源,理想情况下,模型应该能够预测出目标。
- 预测(prediction)或输出(output):从模型出来的结果。
- 预测误差(prediction error)或损失值(loss value):模型预测与目标之间的距离。
- 类别(class):分类问题中供选择的一组标签。比如”猫“和”狗“就是两个类别。
- 标签(label):分类问题中类别标注的具体例子。比如”猫“是0,”狗“是1.
- 真值(ground-truch)或标注(annotation):数据集的所有目标。
- 二分类(binary classification):一种分类任务,包括两个类别,每个输入样本都应被划分到两个类别的其中一类。
- 多分类(multiclass classification):一种分类任务,包括多个类别,每个输入 样本都应被划分到多个类别的其中一类,如手写数字分类。
- 多标签分类(multilabel classification):一种分类任务,每个输入样本都可以分配多个标签。比如,一幅画像里面既有狗又有猫,那么应该同时标注”猫“标签和”狗标签“。
- 标量回归(scalar regression):目标是连续标量值的任务,比如预测房价。
- 向量回归(vector regression):目标是一组连续值的任务,如果对多个值进行回归,那就是向量回归。
- 小批量(mini-batch)或批量(batch):模型同时处理的一部分小样本。样本通常取2的幂,这样便于GPU上的内存分配。训练时,小批量用来为模型权重计算一次梯度下降更新。
2.2 评估机器学习模型
2.2.1 训练集、验证集、测试集
训练集:用来训练模型
验证集:用于评估模型,即对模型进行预测试
测试集:是在找到最佳参数后,对模型进行最后测试
2.2.2 参数
1.模型参数:权重
在训练集上学习,在验证集上预测试
2.模型超参数:模型配置
比如,选择网络层数或每层卷积核个数,需根据模型在验证集上的表现作为反馈信号进行调节,这本身也是一种学习。
2.3 拟合
2.3.1 欠拟合
欠拟合:未能学习到训练数据中的关系。
2.3.2 过拟合
过拟合:过分依赖训练数据,对训练数据拟合的非常好,但是丧失了一般性,导致对于新的待预测样本,预测效果差。
解决过拟合的方法:正则化、减小网络大小、添加权重正则化、添加dropout正则化
3.监督学习、半监督学习和无监督学习的特点
3.1 监督学习
监督学习:从给定的有标注的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。
⏰总结:有标签数据进行类别预测或者回归分析。
常见任务:包括分类与回归。
3.1.1 回归问题
回归用于预测输入变量和输出变量之间的关系。
回归问题的学习等价于函数拟合:选择一条函数曲线使其很好地拟合已知数据且很好地预测未知数据。
3.1.2 分类问题
分类问题的输出为有限个离散值的集合。
分类问题包括学习和分类两个过程。
学习过程中,根据已知的训练数据集学习一个分类器。
分类过程中,利用学习的分类器对新输入实例进行分类。
3.2 无监督学习
没有标注的训练数据集,需要根据样本间的统计规律对样本集进行分析
⏰总结:无标签数据寻找数据中隐藏的结构
常见任务:聚类
无监督学习的目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
3.3 半监督学习
结合(少量的)标注训练数据和(大量的)未标注数据来进行数据的分类学习。
半监督学习可进一步分为纯半监督学习和直推学习,前者假定训练数据中的未标记样本并非待测的数据,而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。
3.4 强化学习
基于环境的反馈而行动,通过不断与环境交互、试错,使整体行动收益最大化,强化学习不需要训练数据的Label,但是它需要每一步行动环境给予的反馈,是奖励还是惩罚,基于反馈不断调整训练对象的行为。
⏰总结:决策过程+奖励机制+学习一系列的行动
(强化学习接触的很少,以后遇到会补充)
4.机器学习的一般流程
数据预处理→特征工程→数据建模→结果评估

4.1 数据预处理
数据预处理:数据清洗、数据集成、数据采样
4.1.1 数据清洗
数据清洗:对各种脏数据进行对应方式的处理,得到标准、干净、连续的数据,提供给数据统计,数据挖掘等使用。
确保数据的五个性质:完整性、合法性、一致性、唯一性、权威性!
数据清洗要保证:数据的完整性、数据的合法性、数据的一致性、数据的唯一性、数据的权威性
(这个期末考试考到了,没有写上一致性😶)
解析一下数据的一致性吧:
不同来源的不同指标,实际内涵是一样的,或是同一指标内涵不一致。
解决方法:建立数据体系,包含但不限于指标体系、维度、单位等
4.1.2 数据采样
(1)数据不平衡
数据不平衡,指数据集的类别分布不均。
(2)解决方法
解决方法:过采样(Over-Sampling)、欠采样(Under-Sampling)
过采样:通过随机复制少数类来增加其中的实例数量,从而可增加样本中少数类的代表性。
欠采样:通过随机地消除占多数的类的样本来平衡类分布,直到多数类和少数类的实例实现平衡。
4.1.3 数据集拆分
(1)常将数据划分为3份
- 训练数据集,train dataset:用来构建机器学习模型
- 验证数据集,validation dataset:辅助构建模型,用于在构建过程中评估模型,提供无偏估计,进而调整模型参数
- 测试数据集,test dataset:用来评估训练好的最终模型的性能
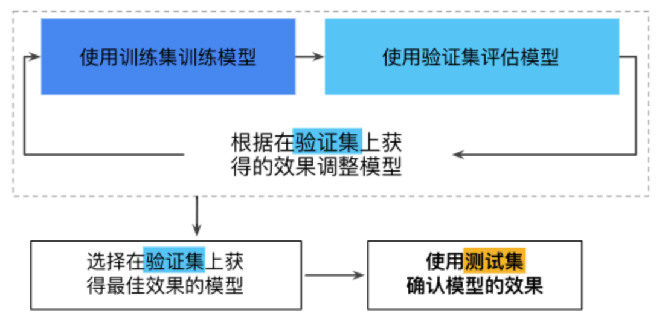
(2)常用拆分方法
①留出法(Hold-Out)
直接将数据集划分为互斥的集合,如通常选择 70% 数据作为训练集,30% 作为测试集。
需要注意的是保持划分后集合数据分布的一致性,避免划分过程中引入额外的偏差而对最终结果产生影响。
②K-折交叉验证法
将数据集划分为 k 个大小相似的互斥子集,并且尽量保证每个子集数据分布的一致性。
这样,就可以获取 k 组训练 - 测试集,从而进行 k 次训练和测试,k通常取值为10。
4.2 特征工程
特征工程:特征编码、特征选择、特征降维、规范化
4.2.1 特征编码
Feature Encoding:机器学习要求特征必须是数字的,通过编码实现。
数据集中经常会出现字符串信息,例如男女、高中低等,这类信息不能直接用于算法计算,需要将这些数据转化为数值形式进行编码,便于后期进行建模。
比如:
one-hot 编码:one-hot表示就是把每个词表示为一个长向量。
语义编码:
可参考:NLP入门-词向量_词向量表示方法分布式表示-CSDN博客
4.2.2 特征选择
Feature Selection:减少特征数量,增强模型泛化能力,减少过拟合,增强对特征和特征值之间的理解。
常用的方法有:过滤法、包装法、嵌入法
(1)过滤法
按照发散性或相关性对各特征进行评分,设定阈值完成特征选择。
互信息:指两个随机变量之间的关联程度,即给定一个随机变量后,另一个随机变量的确定性。
所以,互信息取值最小为0,意味着给定一个随机变量对,确定和另一个随机变量没有关系,越大表示另一个随机变量的确定性越高。
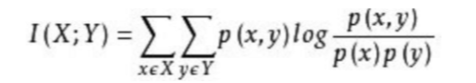
- 包裹法
选定特定算法,然后通过不断的启发式方法来搜索特征。
- 嵌入法
利用正则化的思想,将部分特征属性的权重调整到0,则这个特征相当于就是被舍弃了。
常见的正则有L1的Lasso,L2的Ridge,和一种综合L1和L2这两个方法的Elastic Net方法。
4.2.3 特征降维
特征选择完成后,可能由于特征矩阵过大,导致计算量大、训练时间长,因此降低特征矩阵维度也是必不可少的。
(1)主成分分析(PCA)
将原始特征空间映射到彼此正交的特征向量空间,在非满秩的情况下使用SVD分解来构建特征向量。
(2)线性判别分析(LDA)
给出一个标注了类别的数据集,投影到了一条直线之后,能够使得点尽量的按类别区分开。
4.2.4 特征规范化
不同属性具有不同量级时会导致:
①数量级的差异将导致量级较大的属性占据主导地位;
②数量级的差异将导致迭代收敛速度减慢;
③依赖于样本距离的算法对于数据的数量级非常敏感。
Feature Normalization/Scaling,便于梯度下降更快收敛
Rescaling:将特征变换到[0,1]或者[-1,1]
Standardization:特征分布为0均值1
Scaling to uint length:特征向量的模为1
4.3 数据建模
数据建模:回归问题、分类问题、聚类问题、其他问题
4.4 结果评估
结果评估:拟合度量、查准率、查全率、F1值、PR曲线、ROC曲线
4.4.1 详解
(1)准确率 Accuracy
Accuracy:是指在分类中,分类正确的记录个数占总记录个数的比。
accuracy=预测正确的个数/总数
(2)召回率 Recall
召回率(Recall)也叫查全率,是指在分类中样本中的正例有多少被预测正确了。

准确率(Accuracy):分类正确的样本个数占所有样本个数的比例

精确率(Precision):分类正确的正样本个数占分类器所有的正样本个数的比例
【分正确的正样本个数 除以 分类器预测出来的正样本个数(也就是真正例+反正例)】

召回率(Recall):分类正确的正样本个数占正样本个数的比例
【分正确的正样本个数 除以样本中正样本的个数(也就是真实情况中正样本的个数,即真正例+假反例)】

F1-Score:精确率与召回率的调和平均值,它的值更接近于Precision与Recall中较小的值

4.4.2 常见曲线
(1)PR曲线
PR曲线:P指精确率,R指查全率,PR曲线用来描述模型的优劣。
如果一个学习器的PR曲线包住了另一个,则可以认为A的性能优于C
如果有交叉,如A、B,综合考虑PR性能,引入平衡点(BEP),基于BEP比较,A优于B
比如下边这个图:
但看PR图,A优于C,B优于C,但是A和B无法比较
如果加上平衡点,A优于C,B优于C,A优于B

(2) AUC( Area under the Curve ),ROC( Receiver Operating Characteristic )
ROC:纵轴:真正例率TPR;横轴:假正例率FPR
AUC是ROC曲线下的面积。
一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting,这个时候调模型可以只看AUC,面积越大一般认为模型越好。

4.4.2 评估模型注意事项
1.数据的代表性
将数据划分为训练集和测试集之前,通常应该随机打乱数据。
2.时间箭头
如果想要根据过去预测未来(股票),那么在划分数据前不应该随机打乱数据,这么做会造成时间泄露。
3.数据冗余
数据中的某些数据点出现了两次,打乱数据并划分训练集和验证集将导致两个数据集之间产生数据冗余。
一定要确保训练集和验证集之间没有交集。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











