






主从角色介绍
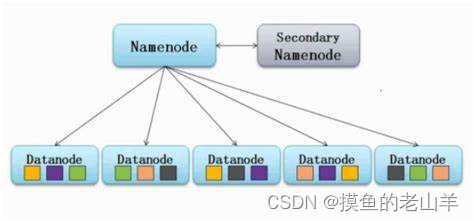
1. Name Node
-
在我们搭建集群的时候,对应不同的机子,肯定给他们分配了不同的角色,其中必定有一台机子是主角色也就是NameNode。
-
NameNode中存储着文件块的元数据,正因为它掌握着这些文件块的信息,所以所有的文件操作都必须仰仗它,它是集群的"老大",它也是访问HDFS文件系统的唯一入口。
-
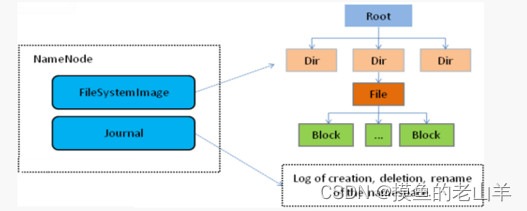
NameNode内部通过内存和磁盘文件两种方式管理元数据。
-
其中磁盘上的元数据文件包括Fsimage内存元数据镜像文件和edits log编辑日志,在后面介绍元数据的时候,会细讲这这二者的作用
怎么查看当前虚拟机的角色
- 在虚拟机的命令行窗口输入start-dfs.sh,会一键启动整个集群的HDFS
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xb6yodad-1669432484595)(C:\Users\HWQ\AppData\Roaming\Typora\typora-user-images\image-20221125183318159.png)]](https://img-blog.csdnimg.cn/8ed3c057b8634ca28a02a3bd9044b457.png)
- 查看当前虚拟机的角色,输入jps(查看当前java进程)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ivTVmBDX-1669432484596)(C:\Users\HWQ\AppData\Roaming\Typora\typora-user-images\image-20221125183346438.png)]](https://img-blog.csdnimg.cn/447f6ca9120c4b629808fa2fd255ab38.png)
可以看到,node01虚拟机同时存在NameNode和DataNode两个角色,意味着这台虚拟机同时存放着所有文件块的元数据,以及部分文件块
2. DataNode
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kQtqEYwh-1669432484596)(C:\Users\HWQ\AppData\Roaming\Typora\typora-user-images\image-20221125183906374.png)]](https://img-blog.csdnimg.cn/708520b7254848c280df4d6210c90f14.png)
-
DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
-
DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块
3. SecondaryNameNode
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8gqeNQDo-1669432484597)(C:\Users\HWQ\AppData\Roaming\Typora\typora-user-images\image-20221125184223019.png)]](https://img-blog.csdnimg.cn/3c1e566ced7d46289ab528f45b17e5b5.png)
- 除了DataNode和NameNode之外,还有另一个守护进程,它称为secondary NameNode。充当NameNode的辅助节点,但不能替代NameNode。
- secondaryNameNode的主要职责就是帮助NameNode减轻压力,一些NameNode做不过来的事情,可以交给secondaryNameNode去做,相当于NameNode的"秘书"。
总结
Namenode
- 所有要跟集群打交道的操作,必须经过NameNode
- 拥有所有DataNode的信息,并且指挥DataNode要干什么,它要g了,那就完蛋
DataNode
- 真正存数据的地方
SecondaryNameNode
- 帮助NameNode合并元数据,减轻NameNode压力















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









