






 本文介绍了协同过滤推荐算法如何通过用户间的相似性和职位间的关联性进行个性化职位推荐。算法利用用户评分矩阵计算相似度,如使用余弦值,结合用户集合内的相似用户喜好度,实现个性化职位推荐。
本文介绍了协同过滤推荐算法如何通过用户间的相似性和职位间的关联性进行个性化职位推荐。算法利用用户评分矩阵计算相似度,如使用余弦值,结合用户集合内的相似用户喜好度,实现个性化职位推荐。
协同过滤推荐算法 - 知乎 (zhihu.com)
协同过滤
原理:
过群体的行为来找到某种相似性(用户之间的相似性或者标的物之间的相似性),通过该相似性来为用户做决策和推荐。
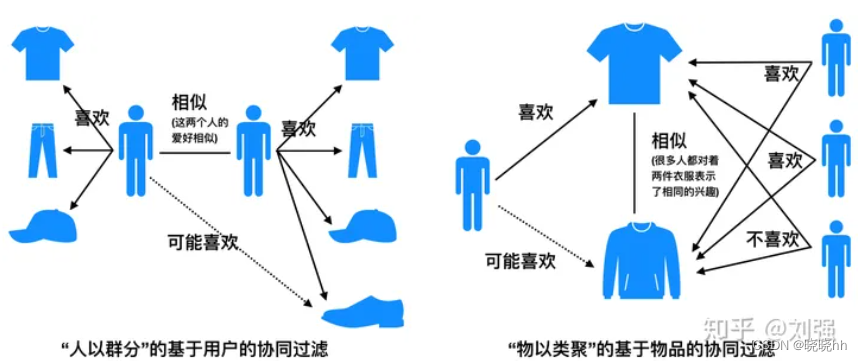
关于用户简历上的偏好相同,推荐相似的职位;关于其他用户职位的喜好相关性,推荐相关的职位
核心:
怎么计算职位之间的相似性,用户之间的相似性
可以采用“矩阵”,里面的元素代表某用户对某职位的评分(或者隐式反馈,如是否具备该职位所需要的技能,是否对该职位感兴趣,对不同类型的数据赋予不同的权重),

行向量:某个用户对推荐职位的评分。
列向量:所有用户对某个职位的评分。
行向量之间的相似度就是用户之间的相似度,列向量之间的相似度就是推荐职位之间的相似度
相似度的计算可以用两个向量之间的cos余弦值来计算。
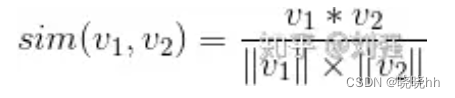
计算完相似度,就要做个性化推荐。
基于用户的协同过滤:
核心思想:用户A,B很相似,可以将A喜欢的职位推荐给用户B。
用户u对推荐职位的喜好程度用score(u,s)计算,u是与该用户最相似用户的集合(如基于相似度找到与该用户最相似的K个用户)
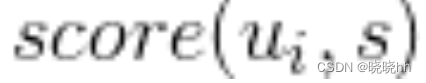 是用户i 对s职位的喜好度。
是用户i 对s职位的喜好度。
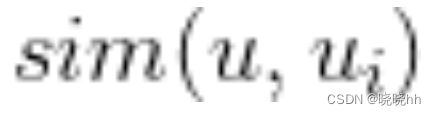 是用户i与用户u的相似度。
是用户i与用户u的相似度。
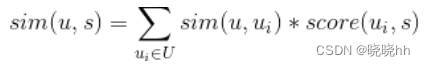 ,用户之间的相似度相当于一个权重,用其他用户对s职位的喜爱度来衡量用户u对某职位的评分(喜爱度)
,用户之间的相似度相当于一个权重,用其他用户对s职位的喜爱度来衡量用户u对某职位的评分(喜爱度)

















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











