






 本文介绍了如何使用pdfplumber库在Python中读取PDF文件,包括获取元数据(如标题、作者等)、操作页面(如提取文本和过滤特定关键字),以及利用ImageMagick进行可视化。重点展示了如何通过filter方法筛选页面内容和PageImage对象的使用方法。
本文介绍了如何使用pdfplumber库在Python中读取PDF文件,包括获取元数据(如标题、作者等)、操作页面(如提取文本和过滤特定关键字),以及利用ImageMagick进行可视化。重点展示了如何通过filter方法筛选页面内容和PageImage对象的使用方法。
import pdfplumber
with pdfplumber.open("path/to/file.pdf") as pdf:
first_page = pdf.pages[0]
print(first_page.chars[0])读取PDF
pdfplumber有两个方式:返回的是pdfplumber.PDF的实例
pdfplumber.open("路径")
pdfplumber.load()(这个不会)
pdfplumber.PDF
表示:单个PDF
属性:.metadata和.pages
.metadata:用于获取PDF文件的元数据。元数据是关于文档的描述性信息,如标题、作者、创建日期等。
用法:
- 首先,你需要使用pdfplumber打开一个PDF文件并创建一个PDF对象,如:pdf = pdfplumber.open(‘example.pdf’)。
- 然后,你可以使用metadata属性来访问PDF文件的元数据,如:metadata = pdf.metadata。
import pdfplumber
# 打开PDF文件
pdf = pdfplumber.open('example.pdf')
# 获取PDF文件的元数据
metadata = pdf.metadata
# 打印元数据
print(metadata)
# 关闭PDF文件
pdf.close()
输出结果可能是一个包含PDF文件元数据的字典,例如:
{
'Title': 'Example PDF',
'Author': 'John Doe',
'Subject': 'An example PDF document',
'Keywords': 'pdfplumber, example',
'Producer': 'PDFlib 9.1.2 (C++/Win64)',
'Created': '2021-01-01T12:00:00Z',
'Modified': '2021-01-02T09:30:00Z'
}
上述例子中,metadata字典包含了PDF文件的标题、作者、主题、关键词、生成器、创建日期和修改日期等信息。
.pages:用于获取PDF文件中的所有页面。它返回一个Page对象的列表,每个Page对象代表PDF文件中的一页。
用法:
- 首先,你需要使用pdfplumber打开一个PDF文件并创建一个PDF对象,如:pdf = pdfplumber.open(‘example.pdf’)。
- 然后,你可以使用pages属性来获取PDF文件中的所有页面,如:pages = pdf.pages。
import pdfplumber
# 打开PDF文件
pdf = pdfplumber.open('example.pdf')
# 获取PDF文件中的所有页面
pages = pdf.pages
# 打印页面数量
print(len(pages))
# 遍历所有页面并打印文本内容
for page in pages:
text = page.extract_text()
print(text)
# 关闭PDF文件
pdf.close()
上述例子中,我们首先打开一个名为example.pdf的PDF文件,并使用pages属性获取所有页面。然后,我们打印页面数量,并使用一个循环遍历所有页面并提取文本内容进行打印。
页面索引是从0开始的,所以第一页可以通过索引0来访问,例如:pages[0]。每个页面都是一个Page对象,你可以使用Page对象的方法和属性来进行操作,如提取文本、提取表格、提取图像等。
pdfplumber.page类的属性:
.page_number: 页码顺序,从1 开始
.width: 页面宽度
.height: 页面高度
.objects/.chars/.lines/.rects/.curves/.figures/.images等
pdfplumber.page类的方法:
.crop(bounding_box): 返回裁剪后的页面,bounding_box对象是四元组(x0, top, x1, bottom)落在边框内的都会被涵盖
.within_bbox(bounding_box): 和上一个相似,但是指挥涵盖全部落在边框内的部分
.filter(test_function):
(可以使用这个过滤简历当中的特定关键字如“java”"前端"“算法工程师”等,将一整页的PDF浓缩成由“特定关键词”构成的字符串,如技能字符串、职位字符串)
(缺点是有点慢:有很多关键词是不是要遍历这一页很多遍才能全部提取出来,才能全部放进去一个字符串?)
含义:pdfplumber.Page.filter(test_function)是pdfplumber库中Page对象的方法,用于根据指定的条件过滤页面中的文本元素,并返回一个新的Page对象。
用法:filter()的参数test_function是一个函数,该函数将用于对页面中的每个文本元素进行测试。函数返回值为True的文本元素将被保留,返回值为False的文本元素将被过滤掉。
import pdfplumber
# 打开PDF文件
with pdfplumber.open("document.pdf") as pdf:
# 获取第一页
first_page = pdf.pages[0]
# 定义一个函数,用于判断文本元素是否包含特定关键字
def contains_keyword(element):
return "important" in element["text"]
# 使用filter()过滤出包含特定关键字的文本元素
filtered_page = first_page.filter(contains_keyword)
# 打印过滤结果
print(filtered_page.extract_text())
在上面的例子中,我们使用pdfplumber库打开一个PDF文件,并获取第一页。然后,定义了一个名为contains_keyword的函数,用于判断文本元素是否包含特定关键字"important"。接下来,使用filter()方法对第一页进行过滤,保留包含特定关键字的文本元素。最后,使用extract_text()方法提取过滤结果的文本内容,并打印出来。
注意:pdfplumber库是用于处理PDF文件的库,Page对象表示PDF中的一页。filter()方法用于过滤Page对象中的文本元素,而不是过滤整个PDF文件。
.extract_text(x_tolerance = 0,y_tolerance = 0):将页面的所有字符对象整理到一个字符串中。若两个字符之间的差大于x_tolerance就添加空格,若大于y_tolerance就添加换行符。
(应该用不上,我们的简历PDF是要从争端的文字中提取出精确的关键词,技能的关键词和期待职位的关键词)
(不确定的是:关于个人信息层面的信息会不会用得到)
对象:pdfplumber.PDF和pdfplumber.Page的实例
提供了四种操作对象的方法。
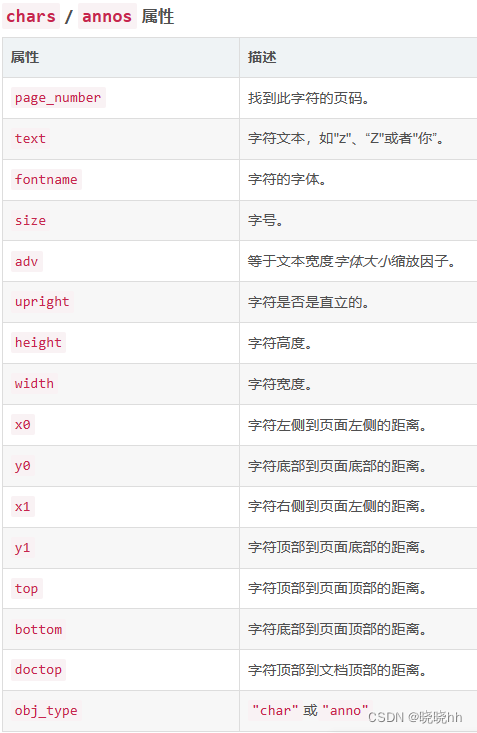
.chars代表每一个独立的字符
.annos注释里的每一个独立的字符
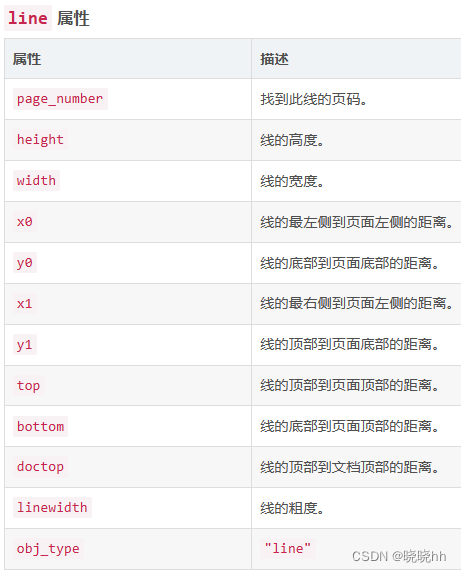
.lines一个独立的一维的线
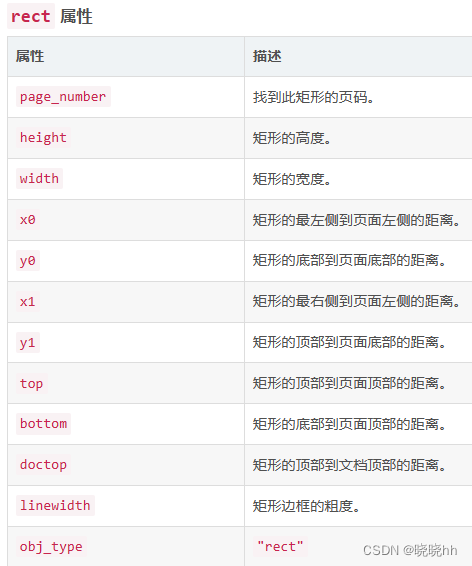
.rects一个独立的二维矩形
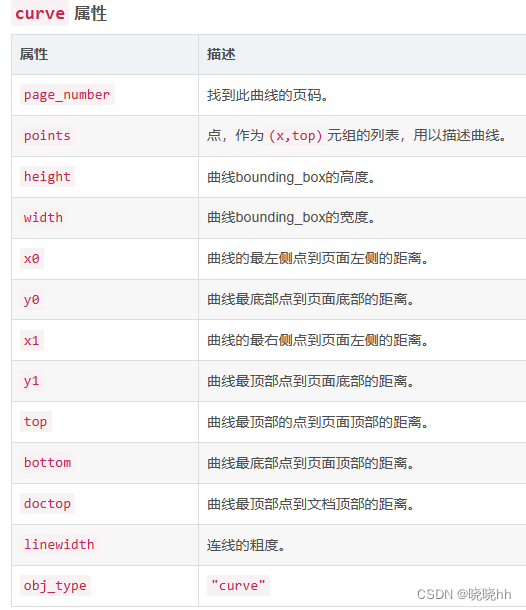
.curves一系列连接的点
.images一个图像
可视化:
(boss在得到系统推荐的人之后,也可以点进去查看个人的技能图片,进行具体的了解)
使用pdfplumber的可视化调试工具需要额外用到两个工具
 http://docs.wand-py.org/en/latest/guide/install.html#install-imagemagick-debian
http://docs.wand-py.org/en/latest/guide/install.html#install-imagemagick-debian页面使用.to_image()创建PageImage,如 im = my_pdf.pages[0].to_image(resolution = 150)(参数默认72,不知道啥意思)
基础的用法:
im.reset() 清除目前已经绘制的所有内容
im.copy() 将图像复制到新的PageImage对象
im.save(path_or_fileobject, format = "PNG") 保存带注释的图像
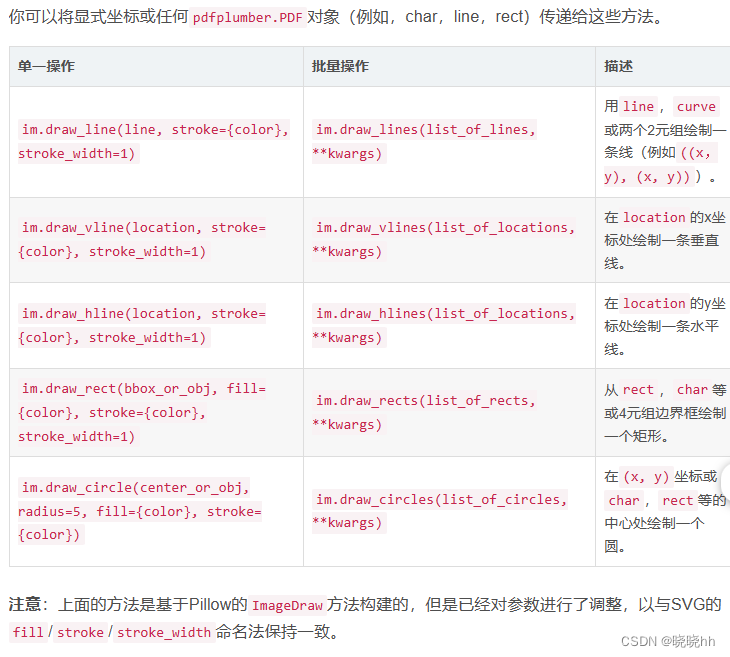
绘图方法:


















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











