







 本文介绍了如何使用Python构建音乐推荐系统,包括数据读取、用户与歌曲播放统计、数据截取、清洗、拼接。接着通过排行榜首推荐、歌曲相似度推荐和矩阵分解SVD方法进行个性化推荐。
本文介绍了如何使用Python构建音乐推荐系统,包括数据读取、用户与歌曲播放统计、数据截取、清洗、拼接。接着通过排行榜首推荐、歌曲相似度推荐和矩阵分解SVD方法进行个性化推荐。
本文是基于JupyterNotebook做的一个基于Python的音乐推荐系统
目录
1、导入库,定义了一个变量data_home,赋值为'./'
1、导入库,定义了一个变量data_home,赋值为'./'
导入系统需要依赖的包pandas,numpy,time,sqlites
#导入库,定义了一个变量data_home,赋值为'./'
import pandas as pd
import numpy as np
import time
import sqlite3
data_home='./'2、数据读取
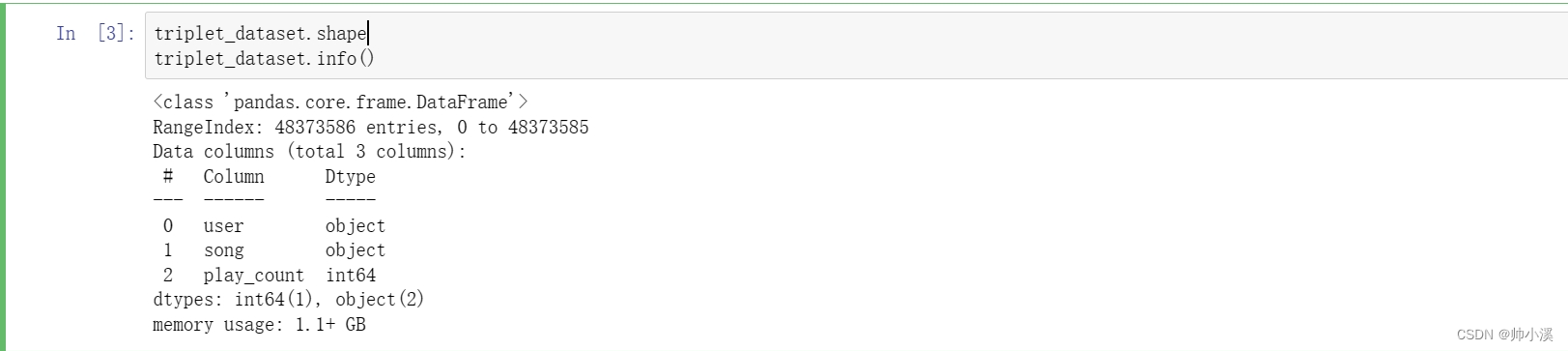
读取原始数据文件train_triplets.txt,1,2步骤的代码如下,通过numpy的read_csv方法读取data_home路径下的train_triplets.txt文件,数据文件中只需要用户,歌曲,播放量三个指标;查看数据大小规模以及各指标格式,发现数据大小为(48373586,3),数据量为千万级别,查看info信息,占用1.1+GB内存,数据量非常庞大,查看大小以及指标代码如下
triplet_dataset=pd.read_csv(filepath_or_buffer=data_home+'train_triplets.txt',
sep='\t',header=None,
names=['user','song','play_count'])triplet_dataset.shape
triplet_dataset.info()输出:
triplet_dataset.head(n=10)输出:
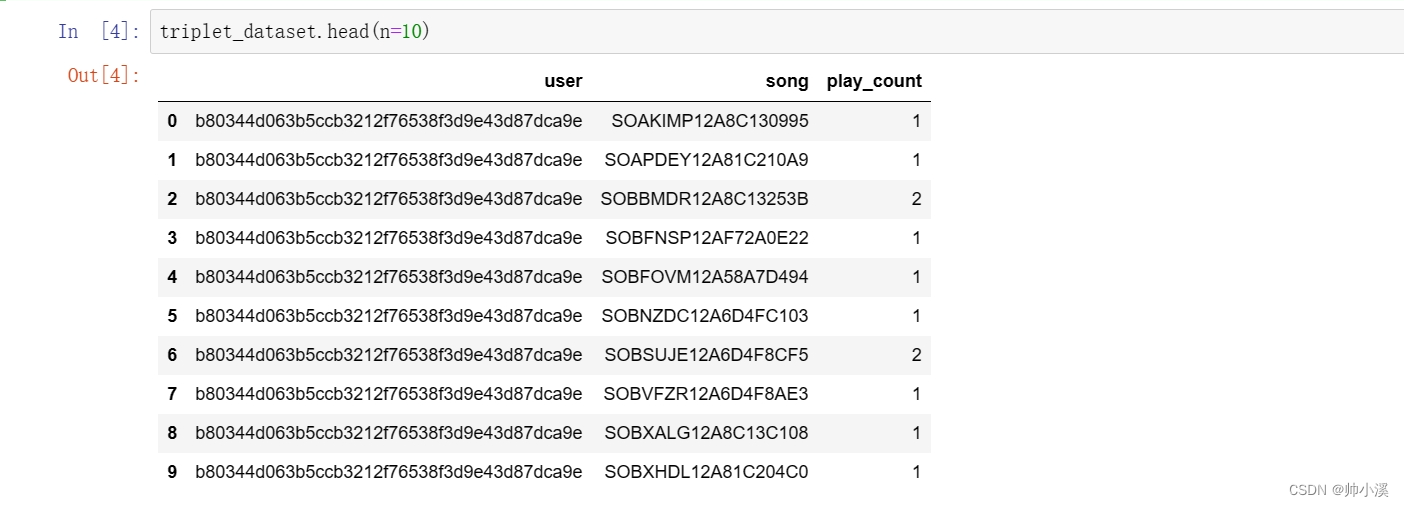
数据中有用户的编号,歌曲编号,用户对该歌曲播放的次数。 有了基础数据之后,我们还可以统计出关于用户与歌曲的各项指标
3、对每一个用户分别统计他的播放总量
output_dict = {}
with open(data_home+'train_triplets.txt') as f:
for line_number, line in enumerate(f):
#找到当前的用户
user = line.split('\t')[0]
#得到其播放量数据
play_count = int(line.split('\t')[2])
#如果字典中已经有该用户信息,在其基础上增加当前的播放量
if user in output_dict:
play_count +=output_dict[user]
output_dict.update({user:play_count})
output_dict.update({user:play_count})
# 统计 用户-总播放量
output_list = [{'user':k,'play_count':v} for k,v in output_dict.items()]
#转换成DF格式
play_count_df = pd.DataFrame(output_list)
#排序
play_count_df = play_count_df.sort_values(by = 'play_count', ascending = False)
play_count_df.to_csv(path_or_buf='user_playcount_df.csv', index = False)4、对于每一首歌分别统计他的播放总量
#统计方法跟上述类似
output_dict = {}
with open(data_home+'train_triplets.txt') as f:
for line_number, line in enumerate(f):
#找到当前歌曲
song = line.split('\t')[1]
#找到当前播放次数
play_count = int(line.split('\t')[2])
#统计每首歌曲被播放的总次数
if song in output_dict:
play_count +=output_dict[song]
output_dict.update({song:play_count})
output_dict.update({song:play_count})
output_list = [{'song':k,'play_count':v} for k,v in output_dict.items()]
#转换成df格式
song_count_df = pd.DataFrame(output_list)
song_count_df = song_count_df.sort_values(by = 'play_count', ascending = False)
song_count_df.to_csv(path_or_buf='song_playcount_df.csv',index=False) 5、看看目前的排行情况
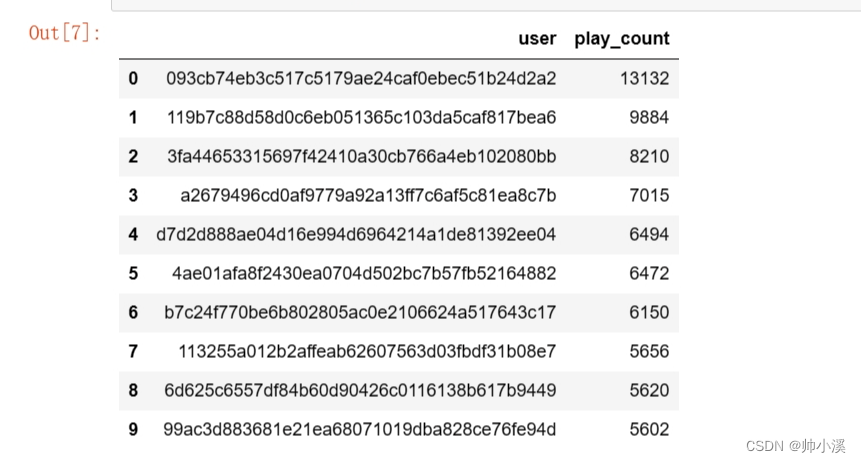
play_count_df=pd.read_csv(filepath_or_buffer='user_playcount_df.csv')
play_count_df.head(n=10)输出:
song_count_df = pd.read_csv(filepath_or_buffer='song_playco 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3962
3962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











