









形成
卷积神经网络最初是受到视觉系统的神经机制启发、针对二维形状的识别设计的一种生物物理模型,在平移情况下具有高度的不变形,在缩放和倾斜情况下也具有一定的不变形。这种生物物理模型集成了“感受野”的思想,可以看作一种特殊的多层感知器或者前馈神经网络,具有局部连接、权值共享的特点,其中大量神经元按照一定方式组织起来对视野中的交叠区域产生反应。
发展历程
1962 1962 1962年, H u b e i Hubei Hubei和 W i e s e l Wiesel Wiesel通过对猫的视觉皮层细胞的研究,提出了感受野的概念。关于感受野的详细介绍请看深度学习入门基础CNN系列——感受野和多输入通道、多输出通道以及批量操作基本概念。
1979 1979 1979年,日本学者 F u k u s h i m a Fukushima Fukushima在感受野概念的基础上,提出了神经认知模型的概念,该模型是被认为实现的第一个卷积神经网络。
1989 1989 1989年, L e C u n LeCun LeCun等人首次使用了权值共享技术。 1998 1998 1998年, L e C u n LeCun LeCun等人将卷积层和下采样层相结合,设计卷积神经网络的主要结构,形成了现代卷积神经网络的雏形 ( L e N e t ) (LeNet) (LeNet)。
2012 2012 2012年,卷积神经网络的发展取得了历史性的突破, A l e x K r i z h e v s k y Alex\ Krizhevsky Alex Krizhevsky和他的老师 G e o f f r e y E . H i n t o n Geoffrey\ E. Hinton Geoffrey E.Hinton等人采用修正线性单元 ( R e c t i f i e d L i n e a r U n i t , R e L u ) (Rectified\ Linear\ Unit,\ ReLu) (Rectified Linear Unit, ReLu)作为激活函数提出了著名的 A l e x N e t AlexNet AlexNet,并在 2012 2012 2012年的 I L S V R C ILSVRC ILSVRC竞赛中获得了第一名,称为深度学习发展史上的重要拐点。
在理论上,卷积神经网络是一种特殊的多层感知器或前馈神经网络。标准的卷积神经网络一般由输人层、交替的卷积层和池化层、全连接层和输出层构成,如下图所示。其中,卷积层也称为“检测层”,“池化层”又称为下采样层,它们可以被看作特殊的隐含层,卷积层的权值也称为卷积核。虽然卷积核一般是需要训练的,但有时也可以是固定的,比如直接采用
G
a
b
o
r
Gabor
Gabor 滤波器。作为计算机视觉领域最成功的一种深度学习模型,卷积神经网络在深度学习兴起之后已经通过不断演化产生了大量变种模型。
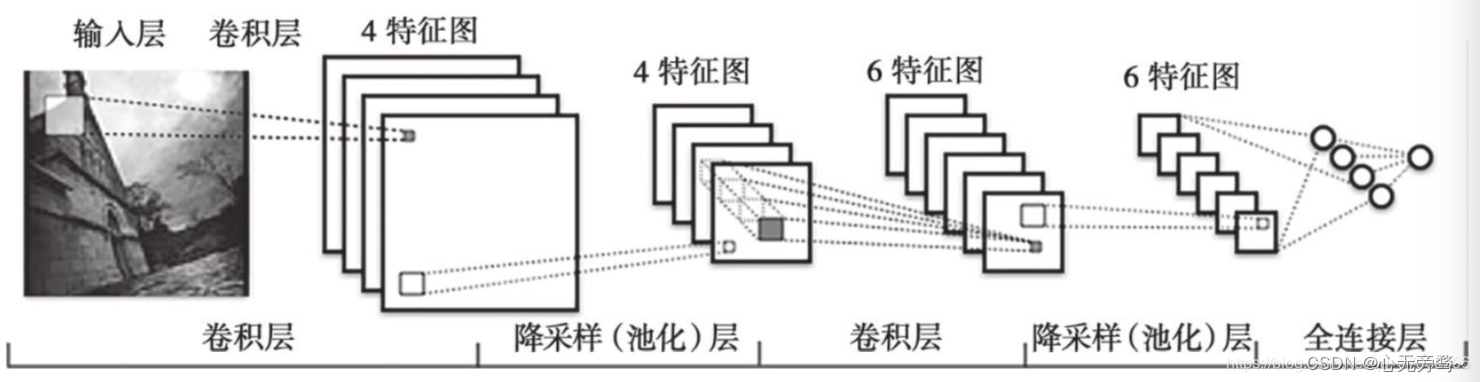
从结构的角度看,卷积神经网络起初只能处理黑白或灰度图像,变种模型通过把红、绿、蓝3个颜色通道作为一个整体输人已能直接处理彩色图像,有些还可以直接处理多帧图像甚至连续图像 。同时,变种模型可以使用多个相邻的卷积层或多个相邻的池化层,也可以使用重叠池化和最大池化,还可以使用修正线性单元、渗漏修正线性单元
(
L
c
a
k
R
e
L
U
,
L
R
e
L
U
)
(LcakReLU,LReLU)
(LcakReLU,LReLU)、参数修正线性单元
(
P
a
r
a
m
e
t
r
i
c
R
e
L
U
,
P
R
e
L
U
)
(Parametric\ ReLU,PReLU)
(Parametric ReLU,PReLU)或指数线性单元
(
E
x
p
o
n
e
n
t
i
a
l
L
i
n
e
a
r
U
n
i
t
,
E
L
U
)
(ExponentialLinear\ Unit,ELU)
(ExponentialLinear Unit,ELU)取代
s
i
g
m
o
i
d
sigmoid
sigmoid单元作为激活函数,也可以在输出层采用软最大函数
s
o
f
t
m
a
x
softmax
softmax 替代
s
i
g
m
o
i
d
sigmoid
sigmoid函数以产生伪概率。此外,卷积神经网络可以设计成李生结构
(
s
i
a
m
e
s
e
a
r
c
h
i
t
e
c
t
u
r
e
)
(siamese\ architecture)
(siamese architecture),把原始数据映射到目标空间,产生对几何扭曲的鲁棒性。最后,券积神经网络可以设计成快道结构,允许信息通过快道无阻碍地跨越多层流动,使得用梯度下降训练非常深的网络变得更加容易。
从卷积核的角度看,卷积神经网络可以通过采用非常小的卷积核,比如
1
×
1
1\times 1
1×1和
3
×
3
3\times 3
3×3大小,被加深成一个更深的网络,比如 16层或19层的
V
G
G
N
e
r
54
VGGNer54
VGGNer54)。如果采用参数修正线性单元代替修正线性单元,可以把
V
G
G
N
e
t
VGGNet
VGGNet发展成
M
S
R
A
N
e
t
MSRANet
MSRANet。而且,卷积神经网络通过使用小卷积核在保持总体计算代价的条件下增加深度和宽度,并与“摄入模块
(
i
n
c
e
p
t
i
o
n
m
o
d
u
l
e
)
(inceptionmodule)
(inceptionmodule)”进行集成,可以用来建立谷歌网络
(
G
o
o
g
L
e
N
e
t
)
(GoogLeNet)
(GoogLeNet) 。此外,卷积神经网络通过使用微型多层感知器代替卷积核,还可以被扩展成更为复杂的网络,例如“网中网
(
N
e
t
w
o
r
k
I
n
N
e
t
w
o
r
k
,
N
I
N
)
(Network\ In\ Network,NIN)
(Network In Network,NIN)
从区域的角度看,区域卷积神经网络
(
R
e
g
i
o
n
−
b
a
s
e
d
C
N
N
,
R
−
C
N
N
)
(Region-based\ CNN,R-CNN)
(Region−based CNN,R−CNN)可以用来抽取区域卷积特征,并通过区域提议进行更加鲁棒的定位和分类)。空间金字塔池化网络
(
S
p
a
t
i
a
l
P
y
r
a
m
i
d
P
o
o
l
i
n
g
N
e
t
,
S
P
P
N
e
t
)
( Spatial\ Pyramid\ Pooling Net,SPPNet)
(Spatial Pyramid PoolingNet,SPPNet)可以克服其输人大小固定的缺点,办法是在最后一个卷积层和第一个全连接层之间插人一个空间金字塔池化层 。不管输人的大小如何,空间金字塔池化层都能够产生固定大小的输出,并使用多尺度空间箱
(
s
p
a
t
i
a
l
b
i
n
)
(spatial\ bin)
(spatial bin)代替滑动窗口对在不同尺度上抽取的特征进行池化。虽然与
R
−
C
N
N
R-CNN
R−CNN 相比,空间金字塔池化网络具有能够直接输人可变大小图像的优势,但是它们需要一个多阶段的管道把特征写人硬盘,训练过程较为麻烦。为了解决这个训练问题,可以在
R
−
C
N
N
R-CNN
R−CNN中插入一个特殊的单级空间金字塔池化层(称为感兴趣区池化层,
R
O
I
p
o
o
l
i
n
g
l
a
y
e
r
)
ROI\ pooling\ layer)
ROI pooling layer),并将其提取的特征向量输入到一个最终分化成两个兄弟输出层的全连接层,再构造一个单阶段多任务损失函数对所有网络层进行整体训练,建立快速区域卷积神经网络
(
F
a
s
t
R
−
C
N
N
)
(Fast\ R-CNN)
(Fast R−CNN),其优点是可以通过优化一个单阶段多任务损失函数进行联合训练。为了减少区域提议的选择代价,可以插人一个区域提议网络与
F
a
s
t
R
−
C
N
N
Fast\ R-CNN
Fast R−CNN共享所有卷积层,进一步建立更快速区域卷积神经网络
(
F
a
s
t
e
r
R
−
C
N
N
)
(Faster\ R-CNN)
(Faster R−CNN),产生几乎零代价的提议预测对象(或称为目标、物体)边界及有关分数 。为了获得实时性能极快的对象检测速度,可以把输入图像划分成许多网格,并通过单个网络构造的整体检测管道,直接从整幅图像预测对象的边框和类概率建立
Y
O
L
O
YOLO
YOLO模型,只需看一遍图像就能知道对象的位置和类别。为了更准确地定位对象,还可以在多尺度特征图的每个位置上,使用不同长宽比的缺省框建立单次检测器
(
S
S
D
)
(SSD)
(SSD)来取代
Y
O
L
O
YOLO
YOLO。此外,采用空间变换模块有助于卷积神经网络学到对平移、缩放、旋转和其他扭曲更鲁棒的不变性。最后,可以把
F
a
s
t
e
r
R
−
C
N
N
Faster\ R-CNN
Faster R−CNN 扩展成掩膜区域卷积神经网络
(
M
a
s
k
R
−
C
N
N
)
(Mask\ R-CNN)
(Mask R−CNN),在图像中有效检测对象的同时,还能够对每个对象实例生成一个高质量的分割掩膜。
从优化的角度看,许多技术可以用来训练卷积神经网络,比如丢失输出 、丢失连接和块归一化
(
b
a
t
c
h
n
o
r
m
a
l
i
z
a
t
i
o
n
)
(batch\ normalization)
(batch normalization)。丢失输出是一种减小过拟合的正则化技术,而丢失连接是丢失输出的推广。块归一化(或批量归一化)则是按迷你块大小对某些层的输入进行归一化处理的方法。此外,残差网络
(
R
e
s
i
d
u
a
l
N
e
t
w
o
r
k
,
R
e
s
N
e
t
)
(Residual\ Network,ResNet)
(Residual Network,ResNet) 采用跨越2~3层的连接策略也是一种重要的优化技术,可以用来克服极深网络的训练困难。借助残差学习能够快速有效地成功训练超过150层甚至1000层的深层卷积神经网络,他在
I
L
S
V
R
C
ILSVRC
ILSVRC &
C
O
C
O
2015
COCO 2015
COCO2015的多任务评测中发挥了关键作用,全部取得了第一名的突出成绩。最后,为了优化模型的结构,还可以采用火焰模块
(
f
i
r
e
m
o
d
u
l
e
)
(fire\ module)
(fire module)建立卷积神经网络的挤压模型
S
q
u
e
e
z
e
N
e
t
SqueezeNet
SqueezeNet,也可以结合深度压缩
(
d
e
e
p
c
o
m
p
r
e
s
s
i
o
n
)
(deep\ compression)
(deep compression)技术进一步减少网络的参数。
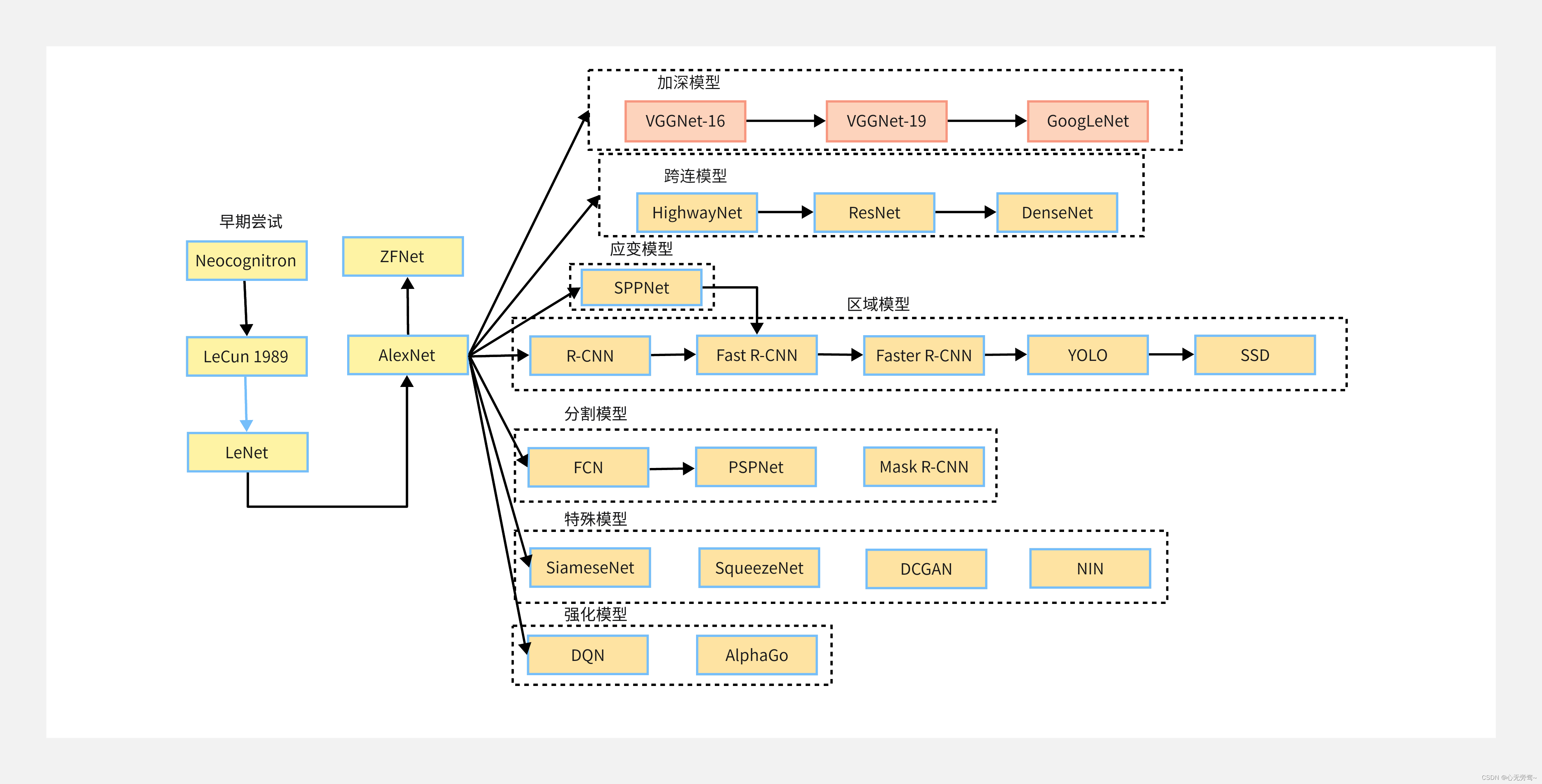
从模型演变的角度看,卷积神经网络的发展脉络如下图所示。从图中可以看出,现代卷积神经网络以
L
e
N
e
t
LeNet
LeNet为雏形,在经过
A
l
e
x
N
e
t
AlexNet
AlexNet的历史突破之后,演化生成了很多不同的网络模型主要包括:加深模型、跨连模型、应变模型、区域模型、分割模型、特殊模型和强化模型等等,加深模裂的代表是
V
G
G
N
e
t
−
16
、
V
G
G
N
e
t
−
19
VGGNet-16、VGGNet-19
VGGNet−16、VGGNet−19 和
G
o
o
g
L
e
N
e
t
GoogLeNet
GoogLeNet;跨连模型的代表是
H
i
g
h
w
a
y
N
e
t
、
R
e
s
N
e
t
HighwayNet、ResNet
HighwayNet、ResNet和
D
e
n
s
e
N
e
t
DenseNet
DenseNet;应变模型的代表是
S
P
P
N
e
t
SPPNet
SPPNet;区域模型的代表是
R
−
C
N
N
、
F
a
s
t
R
−
C
N
N
、
F
a
s
t
e
r
R
−
C
N
N
、
Y
O
L
O
和
S
S
D
R-CNN、Fast\ R-CNN、Faster\ R-CNN、YOLO和SSD
R−CNN、Fast R−CNN、Faster R−CNN、YOLO和SSD;分割模型的代表是
F
C
N
、
P
S
P
N
e
t
FCN、PSPNet
FCN、PSPNet和
M
a
s
k
R
−
C
N
N
Mask\ R-CNN
Mask R−CNN ;特殊模型的代表是
S
i
a
m
e
s
e
N
e
t
、
S
q
u
e
e
z
e
N
e
t
、
D
C
G
A
N
、
N
I
N
SiameseNet、SqueezeNet、DCGAN、NIN
SiameseNet、SqueezeNet、DCGAN、NIN; 强化模型的代表是
D
Q
N
DQN
DQN和
A
I
p
h
a
G
o
AIphaGo
AIphaGo
应用和影响
自从卷积神经网络在深度学习领域闪亮登场之后,很快取得了突飞猛进的进展,不仅显著提高了手写字符识别的准确率,而且屡屡在图像分类与识别、目标定位与检测等大规模数据评测竞赛中名列前茅、战绩辉煌。此外,卷积神经网络在人脸验证、交通标志识别、视频游戏、视频分类、语音识别、机器翻译、围棋程序等各个方面也获得广泛的成功应用。
在手写字符识别方面,
L
e
C
u
n
LeCun
LeCun等人早在
1998
1998
1998年就采用卷积神经网络模型使
M
N
I
S
T
MNIST
MNIST数据集上的错误率达到了
0.95
0.95
0.95%以下,
S
i
m
a
r
d
Simard
Simard等人在
2003
2003
2003年采用交叉训练卷积神经网络把
M
N
I
S
T
MNIST
MNIST数据集上的错误率进一步降到了
0.4
0.4
0.4%,
R
a
n
z
a
t
o
Ranzato
Ranzato等人在
2006
2006
2006年采用大卷积神经网络和无监督预训练又把
M
N
I
S
T
MNIST
MNIST数据集上的错误率降到了
0.39
0.39
0.39%,
C
i
r
e
s
a
n
Ciresan
Ciresan等人在
2012
2012
2012年采用卷积神经网络的委员会模型把
M
N
I
S
T
MNIST
MNIST数据集上的错误率降到了目前的最低水平
0.23
0.23
0.23%。
更详细的统计结果请访问网址http://yann.lecun.com/exdb/mnist/。
在图像分类方面,由
K
r
i
z
h
e
v
s
k
y
、
S
u
t
s
h
e
v
e
r
和
H
i
n
t
o
n
Krizhevsky、Sutshever 和 Hinton
Krizhevsky、Sutshever和Hinton 组织的超级视觉队
(
S
u
p
e
r
V
i
s
i
o
n
)
(SuperVision)
(SuperVision)于
2012
2012
2012年实现了一个深层卷积神经网络,参加大规模视觉识别挑战赛(ImageNet LargeScale Visual Recognition Challenge 2012,ILSVRC-2012)时获得了最好的前5测试错误率
(
16.4
(16.4
(16.4%
)
)
),比第二名的成绩低
10
10
10%左右。这个卷积神经网络现在称为
A
l
e
x
N
e
t
AlexNet
AlexNet,使用了
“
d
r
o
p
o
u
t
”
“dropout”
“dropout”优化技术和
“
R
e
L
U
”
“ReLU”
“ReLU”激活函数,以及非常有效的
G
P
U
GPU
GPU实现,显著加快了训练过程。
2013
2013
2013~
2017
2017
2017年的挑战赛中,成绩最好的图像分类系统分别是
C
l
a
e
i
f
a
i
、
G
o
o
g
L
e
N
e
t
Claeifai、GoogLeNet
Claeifai、GoogLeNet残差网络、六模型集成
(
e
n
s
e
m
b
l
e
o
f
6
m
o
d
e
l
s
)
(ensemble\ of\ 6\ models)
(ensemble of 6 models)、双通道网络
(
D
u
a
l
P
a
t
h
N
e
t
w
o
r
k
.
D
P
N
)
(Dual\ Path\ Network.DPN)
(Dual Path Network.DPN),它们都使用了卷积神经网络的模型结构。这些网络获得的前 5 测试错误率分别为
11.7
11.7
11.7%、
6.7
6.7
6.7%、
3.57
3.57
3.57%、
2.99
2.99
2.99%和
3.41
3.41
3.41%。
在 I L S V R C ILSVRC ILSVRC 2012 2012 2012~ 2017 2017 2017年的单目标定位挑战赛上,获得最好错误率的系统都集成了卷积神经网络,分别是 A l e x N e t AlexNet AlexNet、 O v e r f e a t Overfeat Overfeat、 V G G N e t VGGNet VGGNet、 R e s N e t ResNet ResNet、集成模型 3 ( e n s e m b l e 3 ) 3(ensemble3) 3(ensemble3) 和双通道网络,相应的最好错误率分别为 34.2 34.2 34.2%、 29.9 29.9 29.9%、 25.3 25.3 25.3%、 9.02 9.02 9.02%、 7.71 7.71 7.71%和 6.22 6.22 6.22%。在 I L S V R C − 2014 ILSVRC-2014 ILSVRC−2014的目标检测挑战赛上, L i n Lin Lin 等人将 R − C N N 和 N I N R-CNN和NIN R−CNN和NIN相结合,获得了 37.2 37.2 37.2%的平均准确率, S z e g e d y Szegedy Szegedy 等人使用 G o o g L e N e t GoogLeNet GoogLeNet获得了 43.9 43.9 43.9%的平均准确率。在 I L S V R C − 2015 ILSVRC-2015 ILSVRC−2015的目标检测挑战赛上, H e He He 等人将 F a s t e r R − C N N Faster R-CNN FasterR−CNN 和 R e s N e t ResNet ResNet 相结合,获得了 62.1 62.1 62.1%的平均准确率,比第二名高出了 8.5 8.5 8.5%。在 2016 2016 2016 年的目标检测挑战赛上, Z e n g Zeng Zeng 等人采用门控双向卷积神经网络 ( g a t e d b i − d i r e c t i o n a l C N N ) ( gated\ bi-directional\ CNN) (gated bi−directional CNN),获得了 66.28 66.28 66.28% 的平均准确率在 2017 2017 2017 年的目标检测挑战赛上, S h u a i Shuai Shuai 等人将特征金字塔网络与门控双向卷积神经网络相结合,获得了 73.14 73.14 73.14%的平均准确率。
在人脸验证方面,
F
a
n
Fan
Fan等人于2014年建立了一个金字塔卷积神经网络
(
P
y
r
a
m
i
d
C
N
N
)
(Pyramid\ CNN)
(Pyramid CNN),在
L
F
W
LFW
LFW数据集上获得了
97.3
97.3
97.3%的准确率,其中
L
F
W
LFW
LFW是
“
L
a
b
e
l
e
d
F
a
c
e
s
i
n
t
h
e
W
i
l
d
”
“Labeled\ Faces\ in\ the\ Wild”
“Labeled Faces in the Wild”的缩写。
2015
2015
2015年,
D
i
n
g
Ding
Ding等人利用精心设计的卷积神经网络和三层堆叠的自编码器建立了一个复杂的混合模型,在
L
F
W
LFW
LFW数据集上获得了高于
99.0
99.0
99.0%的准确率。
S
u
n
Sun
Sun等人提出了-个由卷积层和摄人层
(
i
n
c
e
p
t
i
o
n
l
a
y
e
r
)
(inception\ layer)
(inception layer)堆叠而成的
D
e
e
p
I
D
3
DeepID3
DeepID3模型,在
L
F
W
LFW
LFW数据集上获得了
99.53
99.53
99.53%的准确率。此外,
S
c
h
r
o
f
Schrof
Schrof等人实现了
“
F
a
c
e
N
e
t
”
“FaceNet”
“FaceNet”系统,在
L
F
W
LFW
LFW和
Y
o
u
T
u
b
e
YouTube
YouTube人脸数据集上分别获得了
99.63
99.63
99.63%和
95.12
95.12
95.12% 的准确率。
在交通标志识别方面,
C
i
r
e
s
a
n
Ciresan
Ciresan等人于
2011
2011
2011年实现了一个由卷积神经网络和多层感知器构成的委员会机器,在德国交通标志识别标准数据集
(
G
e
r
m
a
n
T
r
a
f
f
i
c
S
i
g
n
R
e
c
o
g
n
i
t
i
o
n
B
e
n
c
h
m
a
r
k
,
G
T
S
R
B
)
(German\ Traffic\ Sign\ Recognition\ Benchmark,GTSRB)
(German Traffic Sign Recognition Benchmark,GTSRB)上获得了
99.15
99.15
99.15%的准确率。
2012
2012
2012年,
C
i
r
e
s
a
n
Ciresan
Ciresan等人提出了一个多列卷积神经网络,在
G
T
S
R
B
GTSRB
GTSRB上获得了
99.46
99.46
99.46% 的准确率,超过了人类的识别结果。
在视频游戏方面, M n i h Mnih Mnih等人于 2015 2015 2015年通过结合卷积神经网络和强化学习,开发了一个深度 Q- 网络智能体的机器玩家 ,只需输人场景像素和游戏得分进行训练,就能够让很多经典的 A t a r i 2600 Atari\ 2600 Atari 2600视频游戏成功学会有效的操作策略,达到与人类专业玩家相当的水平。这种深度 Q- 网络智能体在高维感知输入和行为操纵之间的鸿沟上架起了一座桥梁,能够出色地处理各种具有挑战性的任务。
在视频分类方面,使用独立子空间分析
(
I
n
d
e
p
e
n
d
e
n
t
S
u
b
s
p
a
c
e
A
n
a
l
y
s
i
s
,
I
S
A
)
(Independent\ Subspace\ Analysis,ISA)
(Independent Subspace Analysis,ISA)方法Le等人于2011年提出了堆叠卷积ISA 网络,能够从无标签视频数据中学习不变的时空特征。该网络在
H
o
l
l
y
w
o
r
d
2
Hollyword\ 2
Hollyword 2和
Y
o
u
T
u
b
e
YouTube
YouTube数据集上分别获得了
53.3
53.3
53.3%和
75.8
75.8
75.8%的准确率。
2014
2014
2014年,
K
a
r
p
a
t
h
y
Karpathy
Karpathy等人对卷积神经网络在大规模视频分类上的效果进行了广泛的经验评估,在
S
p
o
r
t
s
−
1
M
Sports-1M
Sports−1M测试集的
200
000
200\ 000
200 000个视频上获得了
63.9
63.9
63.9%的
H
i
t
@
1
Hit@1
Hit@1值(即前1准确率)。
2015
2015
2015年,
N
g
Ng
Ng等人采用卷积神经网络和长短期记忆循环神经网络
(
L
S
T
M
)
(LSTM)
(LSTM)的混合模型,在
S
p
o
r
t
s
−
1
M
Sports-1M
Sports−1M测试集上获得了
73.1
73.1
73.1%的
H
i
t
@
1
值
Hit@1值
Hit@1值。
在语音识别方面,
A
b
d
e
l
−
H
a
m
i
d
Abdel-Hamid
Abdel−Hamid等人于
2012
2012
2012年第一次证实,使用卷积神经网络能够在频率坐标轴上有效归一化说话人的差异,并在
T
I
M
I
T
TIMIT
TIMIT音素识别任务上将音素错误率从
20.7
20.7
20.7%降到
20.0
20.0
20.0%。这些结果在
2013
2013
2013年被微软研究院的
A
b
d
e
l
−
H
a
m
i
d
Abdel-Hamid
Abdel−Hamid等人和
D
e
n
g
Deng
Deng等人以及
I
B
M
IBM
IBM研究院的
S
a
i
n
a
t
h
Sainath
Sainath等人使用改进的卷积神经网络结构、预训练和池化技术拓展到大词汇语音识别上。进一步的研究表明,卷积神经网络对训练集或者数据差异较小的任务帮助最大。此外,通过结合卷积神经网络、深度神经网络和基于
i
−
v
e
c
t
o
r
i-vector
i−vector的自适应技术,
I
B
M
IBM
IBM的研究人员在
2014
2014
2014年说明他们能够将
S
w
i
t
c
h
b
o
a
r
d
H
u
b
500
Switchboard\ Hub500
Switchboard Hub500评估集的词错误率降至
10.4
10.4
10.4%。
在机器翻译方面,
G
e
h
r
i
n
g
Gehring
Gehring等人使用一种全新的卷积神经网络模型进行从序列到序列的学习,能够在非常大的标准数据集上超越循环神经网络的性能,不仅可以大幅提高翻译速度,同时也提高了翻译质量。比如,这种全新的模型在
W
M
T
’
16
WMT’16
WMT’16英语到罗马尼亚语的翻译任务上可比以前最好的系统提高
1.8
1.8
1.8的
B
L
E
U
BLEU
BLEU分数,在
W
M
T
’
14
WMT’14
WMT’14英语到法语的翻译任务上可比
W
u
Wu
Wu等人的长短期记忆神经翻译模型提高
1.5
1.5
1.5的
B
L
E
U
BLEU
BLEU分数在
W
M
T
′
14
WMT'14
WMT′14英语德语的翻译任务上可超过当前最高水平
0.5
0.5
0.5的
B
L
E
U
BLEU
BLEU分数。
在围棋程序方面,谷歌旗下的
D
e
e
p
M
i
n
d
DeepMind
DeepMind公司开发的
A
l
p
h
a
G
o
AlphaGo
AlphaGo利用深层网络和蒙特卡罗树搜索(Monte Carlo tree search),
2015
2015
2015 年
10
10
10 月首次在完整的围棋比赛中没有任何让子以5比0战胜了人类的专业选手、欧洲冠军、职业围棋二段选手樊麾,这也是计算机围棋程序首次击败围棋职业棋手。
2016
2016
2016年
3
3
3月,
A
l
p
h
a
G
o
AlphaGo
AlphaGo又以4比1战胜了人类的顶尖高手世界冠军、职业围棋九段选手李世石。
2016
2016
2016年末
2017
2017
2017年初,
A
l
p
h
a
G
o
AlphaGo
AlphaGo在中国棋类网站上以
M
a
s
t
e
r
Master
Master为注册账号与中日韩数十位围棋高手进行快棋对决,连续 6 局无一败绩。
2017
2017
2017年
5
5
5月,在中国乌镇围棋峰会上,
A
l
p
h
a
G
o
AlphaGo
AlphaGo以3比0战胜排名世界第一的围棋冠军柯洁。
以上便是卷积神经网络的形成、演变及其它的应用和影响。
✨ 原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{green}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{green}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!

















 1555
1555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











