






前言
在我们学习模板之前,我们实现过很多的函数和类,其中函数主要是针对某种数据类型的方法,类主要是存储某种数据类型的结构。我们会发现,我们实现的函数或者类的代码一次只能适用一种特定的类型,如果想要适用多种类型,就必须实现多份代码,这样会出现代码的冗余,显然会比较麻烦,所以C++为了解决这样的问题,就引入了模板,即所谓的泛型编程。
一、泛型编程
之前我们实现函数或者类的时候,通常都是针对处理的某种特定的类型而实现的,那么这样的实现显然就具有局限性。所以我们今天必须学习泛型编程来解决问题。泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础比如我们现在以实现一个交换函数为例:
- 代码1:不使用模板
// 实现一个交换函数
void Swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
void Swap(int& a,int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 0, b = 1;
Swap(&a, &b);
cout << a << " " << b << endl;
return 0;
}
运行结果:

分析:对于上面的代码,虽然确实可以实现a和b的交换,但是一旦a和b的类型发生改变,该交换函数无法实现功能了,因为上面的函数是针对整型类型而实现的,所以显然对其他类型就不适合了。
- 代码2:修改交换变量类型
// 实现一个交换函数
void Swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
int main()
{
int a = 0, b = 1;
Swap(&a, &b);
cout << a << " " << b << endl;
// 增加了double类型
double c = 1.2, d = 3.14;
Swap(&c, &d);
cout << c << " " << d << endl;
return 0;
}
编译结果:


分析:根据传统的写法,我们写出来的交换函数只能适用于一种特定的类型,不能适用于其他的类型。
- 代码3:根据泛型编程实现一个交换函数
// 指明函数模板的模板参数
template <class T>
void Swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 0, b = 1;
Swap(a, b);
cout << a << " " << b << endl;
double c = 1.2, d = 3.14;
Swap(c, d);
cout << c << " " << d << endl;
return 0;
}
运行结果:

通过上面使用模板实现的交换函数不仅能够实现整型的交换,而且能够实现double类型的交换
总结:通过上面的代码样例,我们可以发现,如果我们使用传统的写法来实现交换函数,那么我们要交换多少种类型就需要实现多少个交换函数,显然就会比较复杂,因此我们需要使用泛型编程来实现上述函数,我们使用模板写的只是一个函数模板,真正在调用的时候并不是调用这个模板,而是编译器根据实参的类型进行推演,从而实例化出具体的函数,从而才被调用。
二、函数模板
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。上面代码3实现的交换函数就是一个函数模板,在实际的使用过程中,函数模板中的模板参数的推导通常有两种情况:
- 编译器可以通过调用函数中传的实参的类型进行推导,从而实例化出特定的函数
- 我们在调用函数的时候显示指定模板参数的类型
比如上面的交换函数的使用过程中:
- 代码1:根据调用时实参传的类型进行推导
template <class T>
void Swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 0, b = 1;
Swap(a, b);
cout << a << " " << b << endl;
double c = 1.2, d = 3.14;
Swap(c, d);
cout << c << " " << d << endl;
return 0;
}
运行结果:

- 代码2:调用函数处显示指定模板参数的类型
// 在函数调用时显示指定模板参数的类型
template <class T>
void Swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 0, b = 1;
Swap<int>(a, b);
cout << a << " " << b << endl;
double c = 1.2, d = 3.14;
Swap<double>(c, d);
cout << c << " " << d << endl;
return 0;
}
运行结果:

总结:在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用
double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。注意:调用的不是函数模板本身,而是编译器经过推演后使用函数模板实例化处的函数。
三、函数模板实例化
函数模板实例化:用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化
- 隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
cout << Add(a1, a2) << endl;
cout << Add(d1, d2) << endl;
return 0;
}
运行结果:

分析:上面的代码中编译器根据调用函数时传的实参类型进行推演,从而实例化出对应类型的实例函数,这种现象就是隐式实例化。
2. 显式实例化:在调用函数的函数名后使用<类型>中指定模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
cout << Add<int>(a1, a2) << endl;
cout << Add<double>(d1, d2) << endl;
return 0;
}
运行结果:

分析:上面代码中,调用函数时已经指定了具体的类型,所以编译器会直接根据调用函数时指定的具体类型实例化出对应的实例函数,而不需要进行推演,这个过程就是显式实例化。
四、模板参数的匹配原则
- 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数。如果同时存在非模板函数和模板函数,在调用函数时,如果存在现成的可以匹配的函数实例,那么将不再调用模板函数进行实例化,会直接调用非模板函数进行使用。
- 代码1:
int Add(int& left, int& right)
{
return left + right;
}
double Add(double& left, double& right)
{
return left + right;
}
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
cout << Add<int>(a1, a2) << endl;
cout << Add<double>(d1, d2) << endl;
return 0;
}
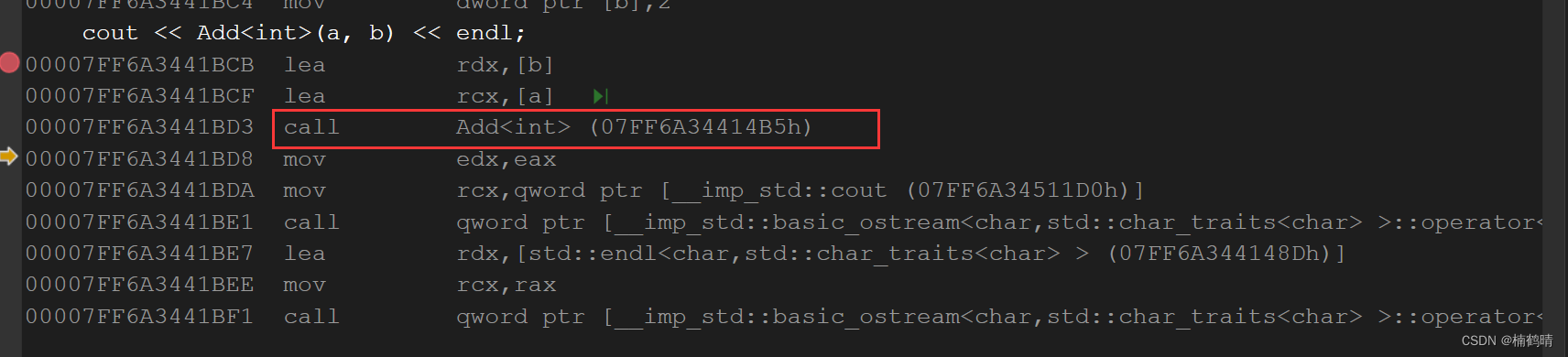
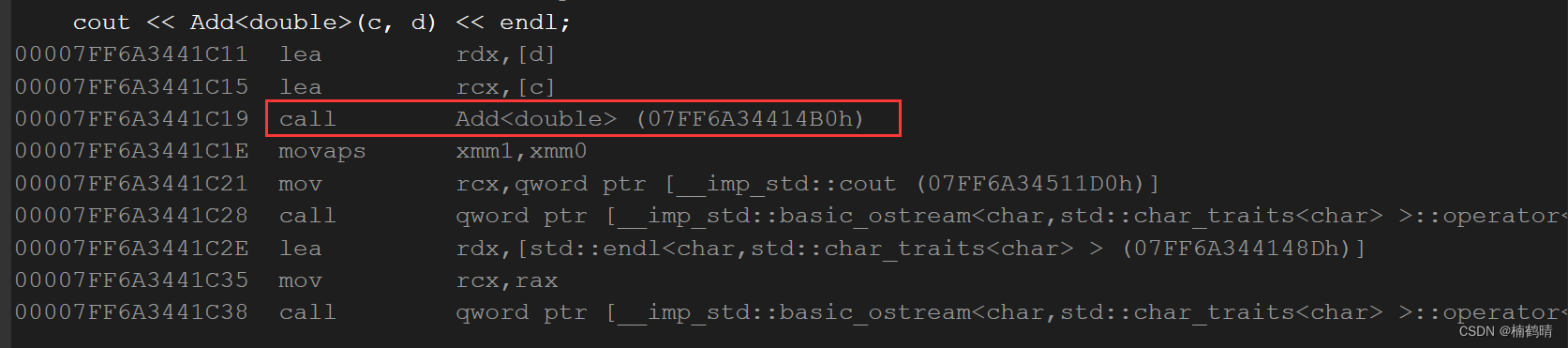
分析:上述的代码中调用的是模板函数进行实例化,因为我们在调用的时候显示指定了模板参数的类型,所以调用函数的时候就会使用模板函数进行实例化。
- 代码2:
int Add(int& left, int& right)
{
return left + right;
}
double Add(double& left, double& right)
{
return left + right;
}
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
cout << Add(a1, a2) << endl;
cout << Add(d1, d2) << endl;
return 0;
}
调试结果:
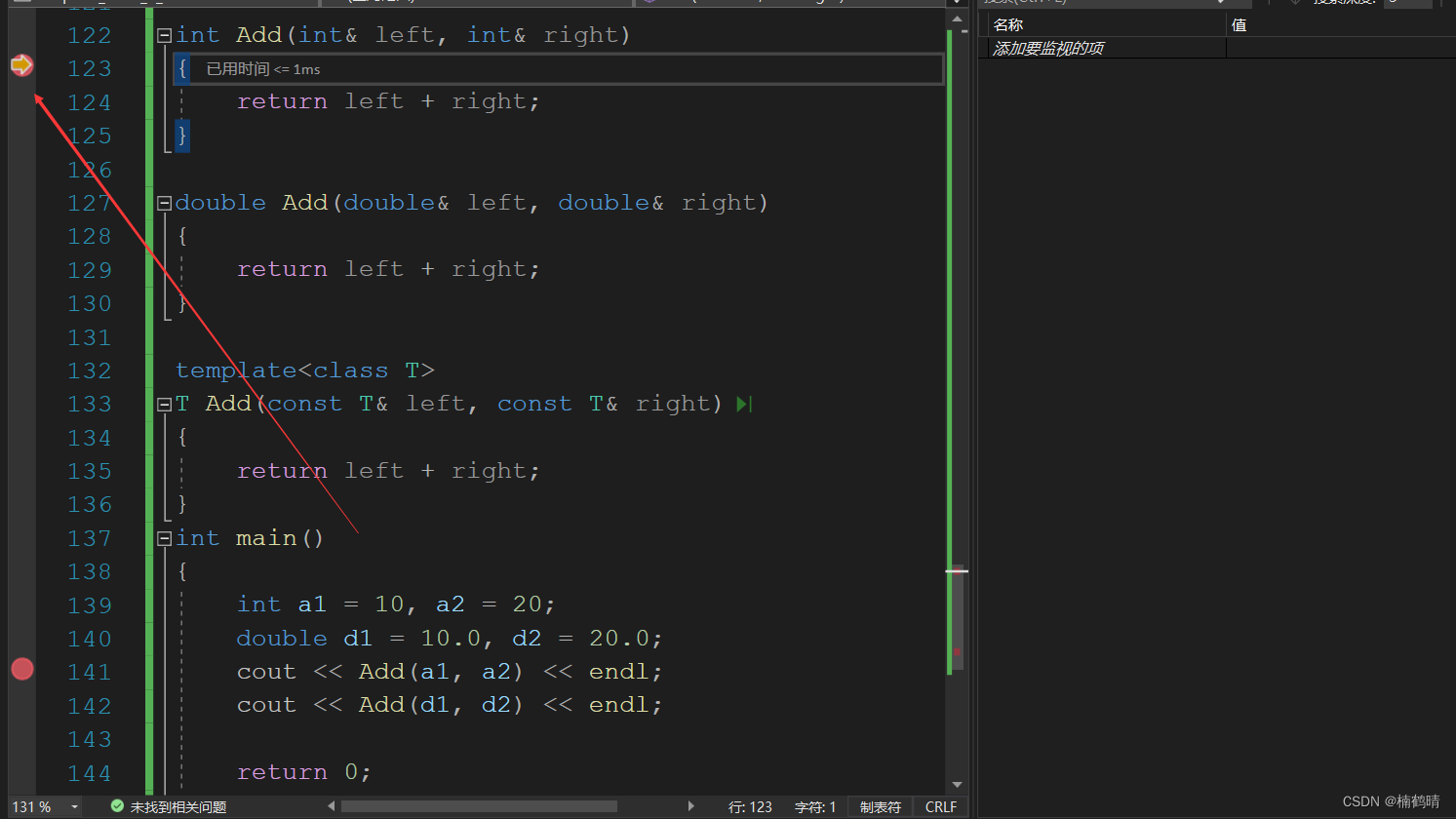
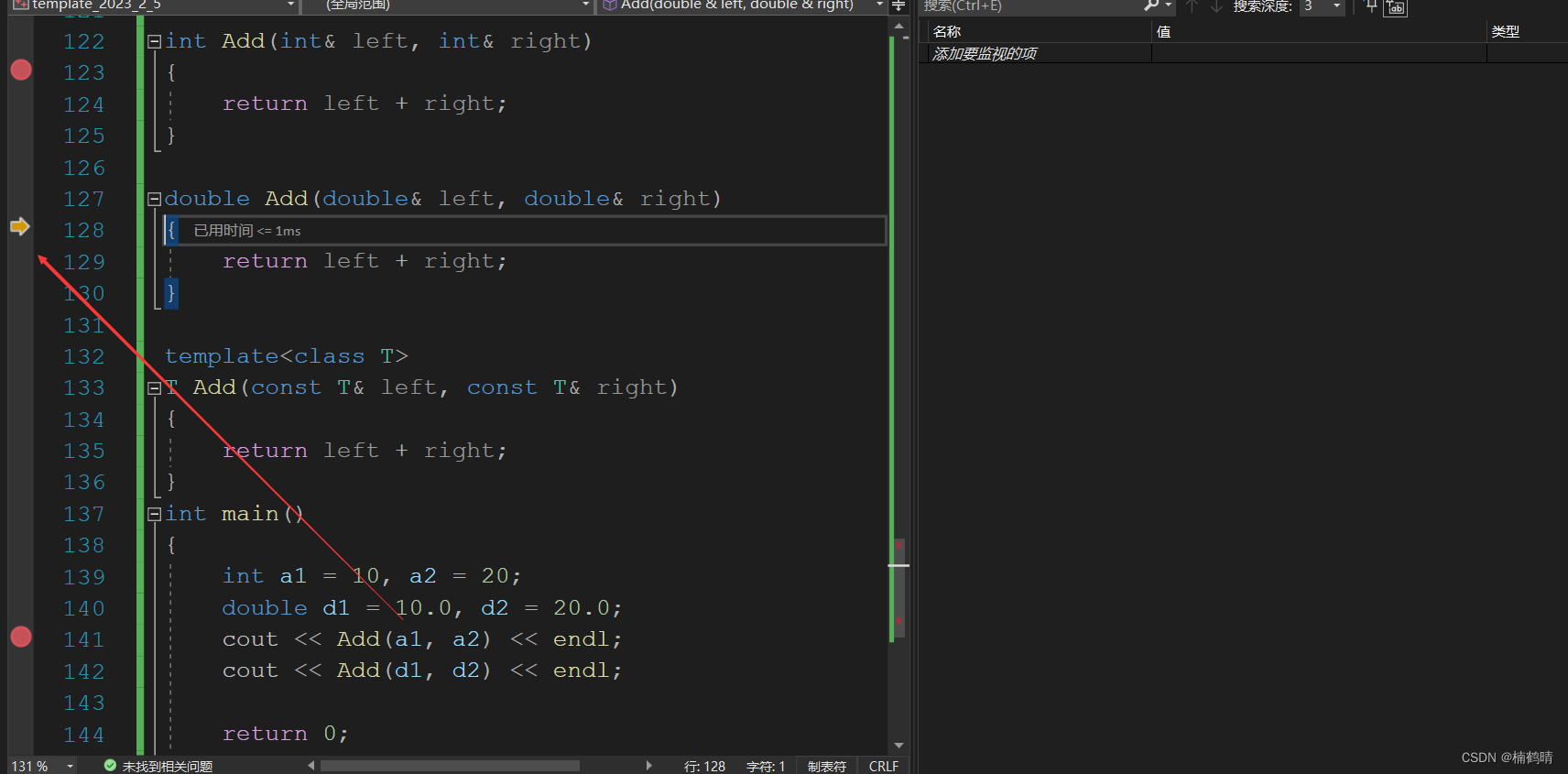
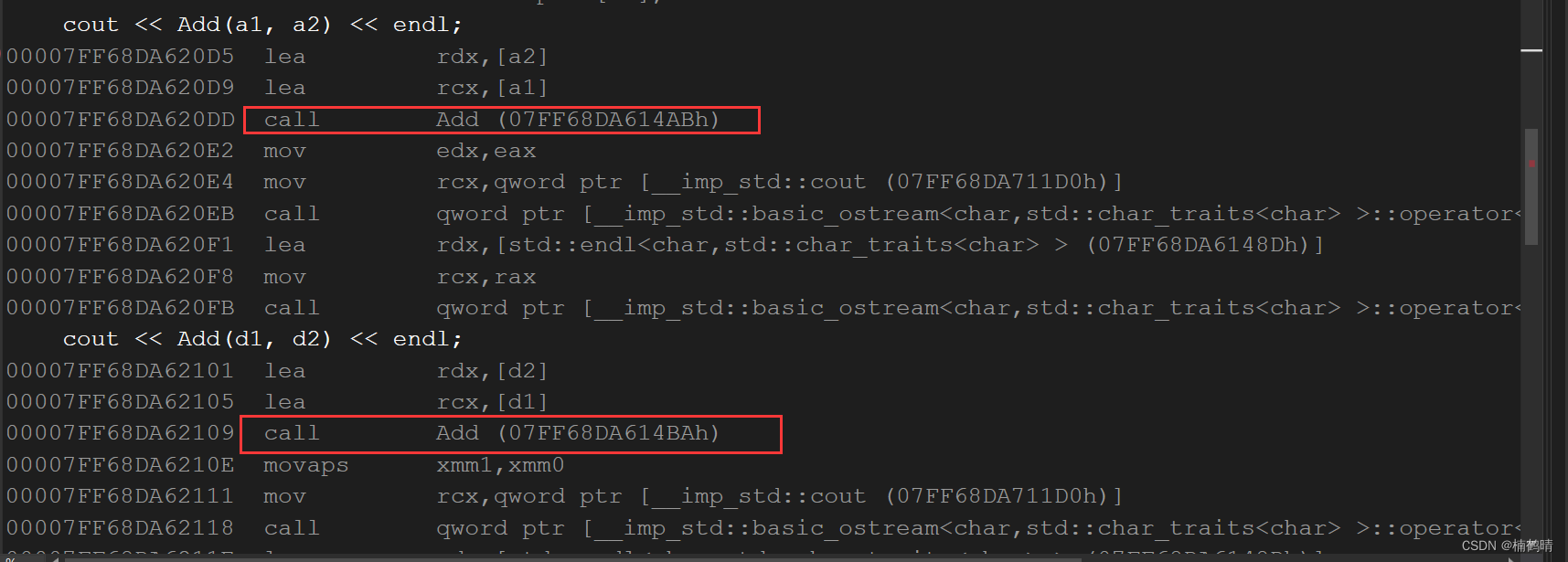
通过上面的调试,我们可以观察到在调用Add(a1,a2)的时候就是调用现成匹配的非模板函数,调用Add(d1,d2)的时候也是调用现成的非模板函数进行使用。因此,函数调用匹配的一个原则:在没有显示实例化的情况下,有现成的优先调用现成的非模板函数进行使用
- 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
/ 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2);
Add(1, 2.0);
}
int main()
{
Test();
return 0;
}
上面的代码中,第一个调用显然是调用具体现成的非模板函数,但是第二个调用地方,因为第二个参数是double类型,和现成的非模板函数不太匹配,因此,第二个函数调用会调用函数模板去进行推演实例化出一个更加匹配的函数实例。
五、类模板
我们之前实现的类,在一次的使用过程中只能是存储一种类型,不能实现创建多个类的时候能够存储多种类型,这就是C语言中typedef的缺陷。所以今天我们将学习类模板,实现一种和存储的数据类型无关的类。面以实现一个Vector类模板为例:
template<class T>
class Vector
{
public:
Vector(size_t capacity = 10)
: _pData(new T[capacity])
, _size(0)
, _capacity(capacity)
{}
// 使用析构函数演示:在类中声明,在类外定义。
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size() { return _size; }
T& operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
}
private:
T* _pData;
size_t _size;
size_t _capacity;
};
// 注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template <class T>
Vector<T>::~Vector()
{
if (_pData)
delete[] _pData;
_size = _capacity = 0;
}
当我们在使用这个类模板创建对象的时候就需要显示指定模板参数的类型,否则就会报错:
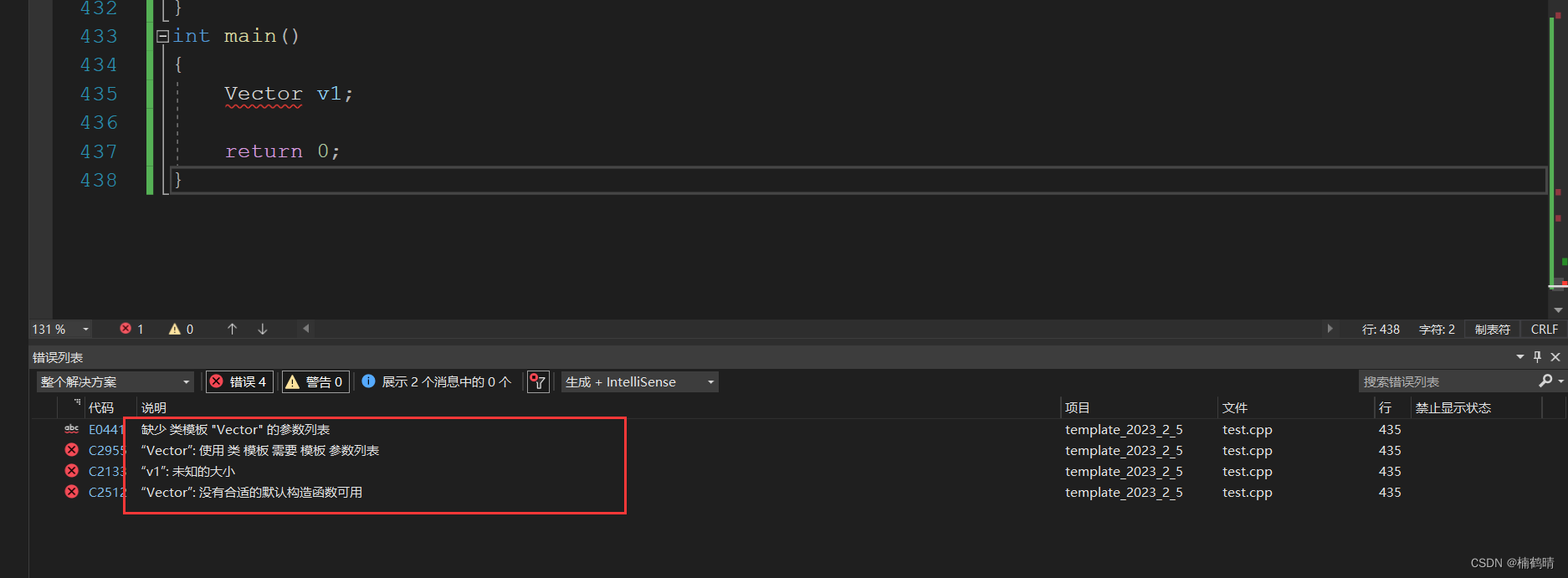
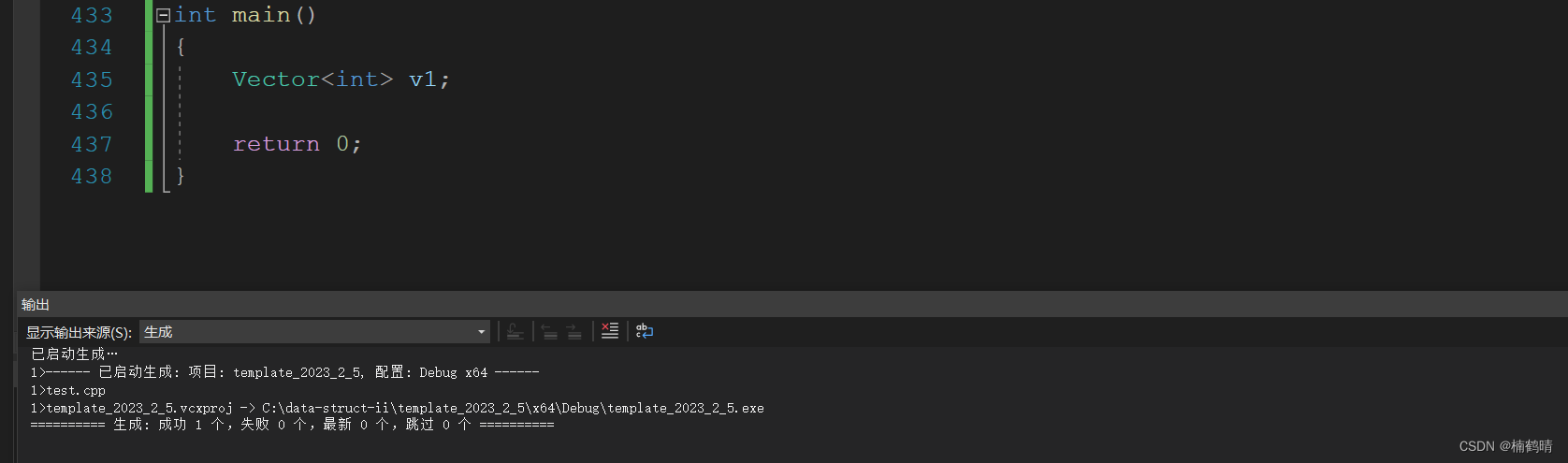
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,如:Vector<int> v1;类模板名字不是真正的类,而实例化的结果才是真正的
需要注意的是:类模板中的成员函数如果声明和定义分离,声明在类中,定义在类外,那么在成员函数定义的时候需要指定:模板参数列表和类域(也需要指定模板参数),下面以Vector中的拷贝构造函数和赋值运算符重载函数为例:
- 声明:

定义:

六、非类型模板参数
在类模板中,除了有类型模板参数之外,还有非类型模板参数,类型模板参数是类型,非类型模板参数不是类型,而是一个常量,其功能和C语言中提供的宏类似,但是C语言中的宏使用起来还是具有很大的缺陷,如:我们要指定一个静态容器中数组的大小,我们可以使用宏来定义一个常量,但是在同一份代码中,使用宏来处理的话只能创建出相同大小的容器,但是使用类模板中的非类型模板参数就不一样了,非类型模板参数的使用支持创建出不同大小的容器:
// 非类型模板参数
template <class T,size_t N>
class Vector
{
public:
Vector()
{}
private:
T _a[N];
int _size;
};
int main()
{
Vector<int, 100> v1;
Vector<int, 200> v2;
Vector<double, 50> v3;
Vector<double, 100> v4;
cout << sizeof(v1) << endl;
cout << sizeof(v2) << endl;
cout << sizeof(v3) << endl;
cout << sizeof(v4) << endl;
return 0;
}
调试结果:
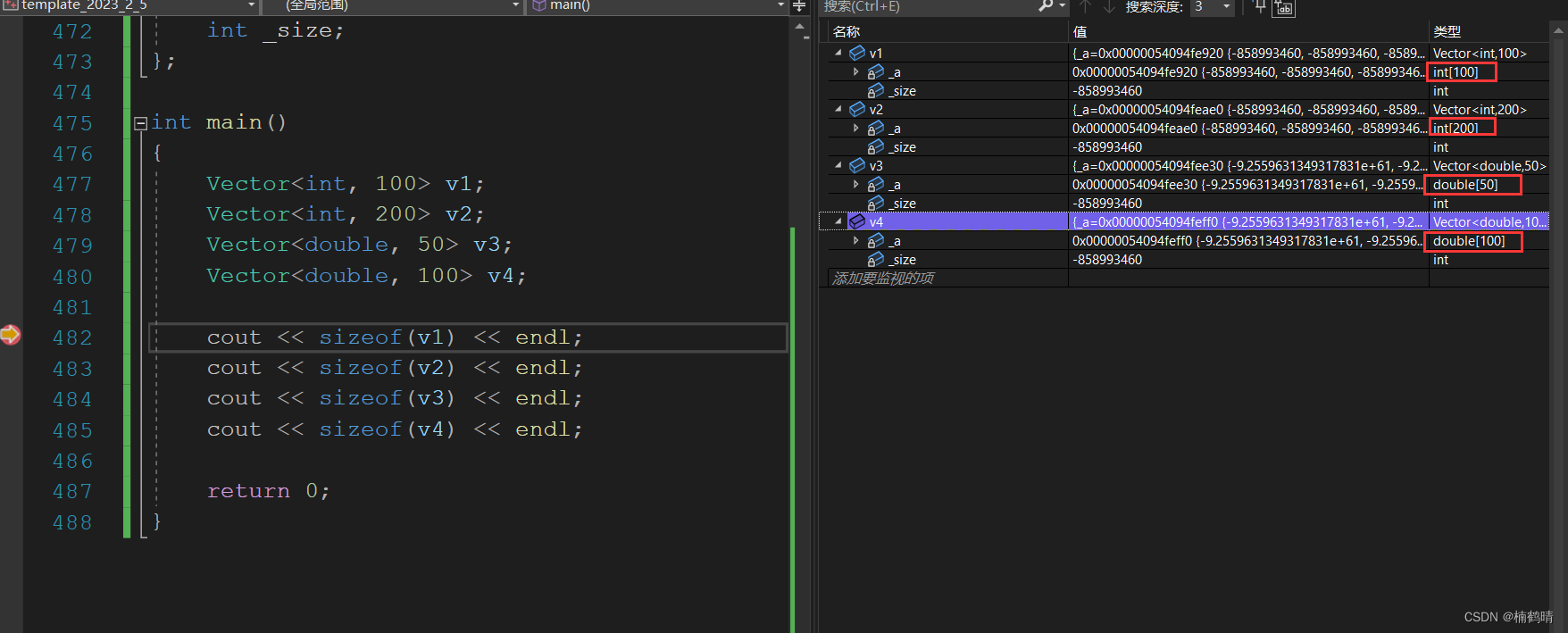
运行结果:
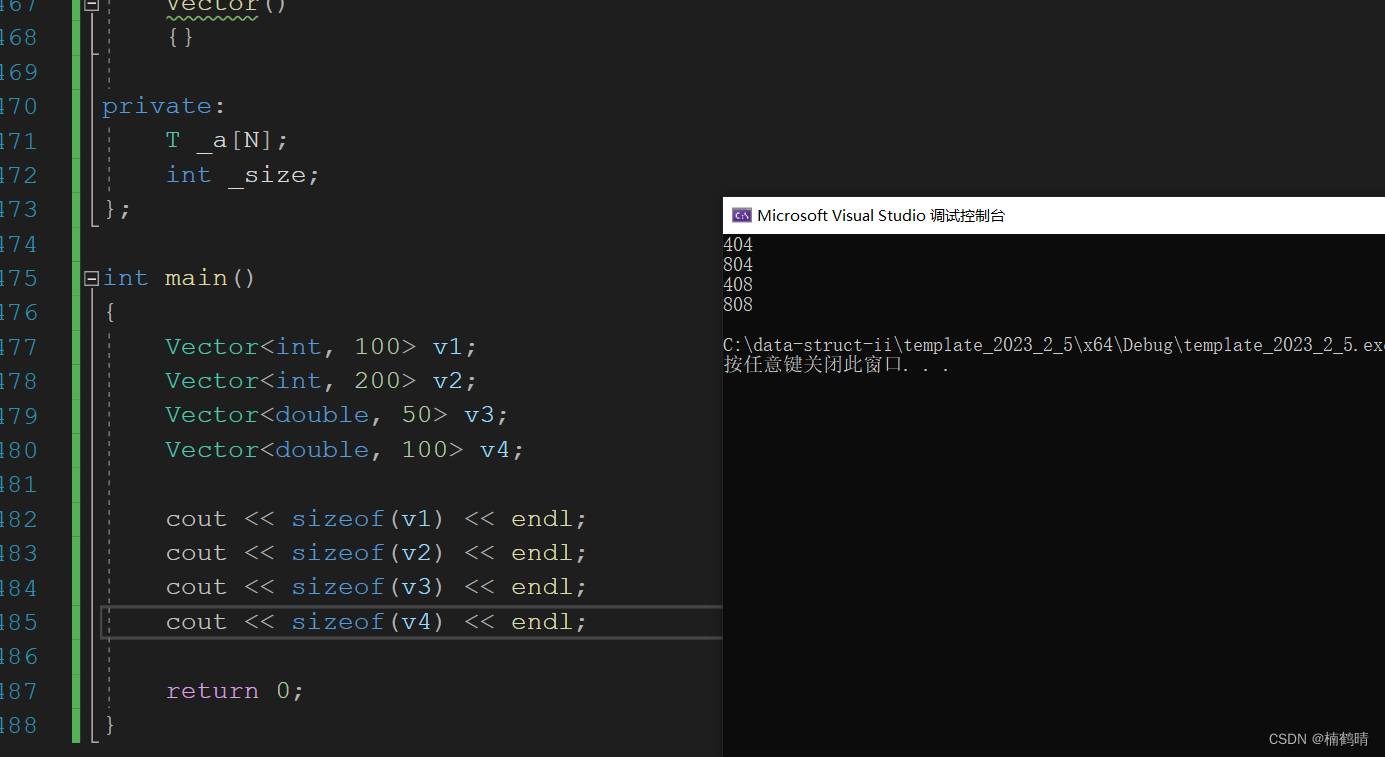
分析:通过上面的代码展示,我们可以看出,使用非类型模板参数之后,确实可以创建出不同大小的对象
注意:非类型模板参数只能是整型,不能是浮点型等其他类型。非类型模板参数是一个常量,只允许创建对象时显示指定,不允许在后序的使用过程中进行修改。
七、模板的分离编译
- 分离编译:一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。像我们之前的习惯,就是将声明放在头文件,定义放在源文件,这种就是分离编译。
- 模板是不允许函数模板或者类模板的声明和定义分别放在两个文件的,类模板主要是指类模板中的成员函数的声明和定义不能放在两个文件。
例子1:函数模板声明和定义分离在两个文件(加法函数)
- 头文件

- 源文件
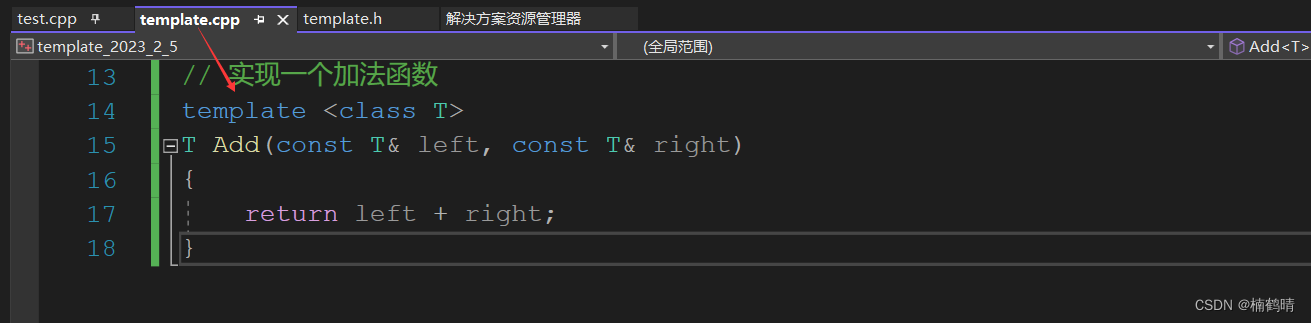
- 调用
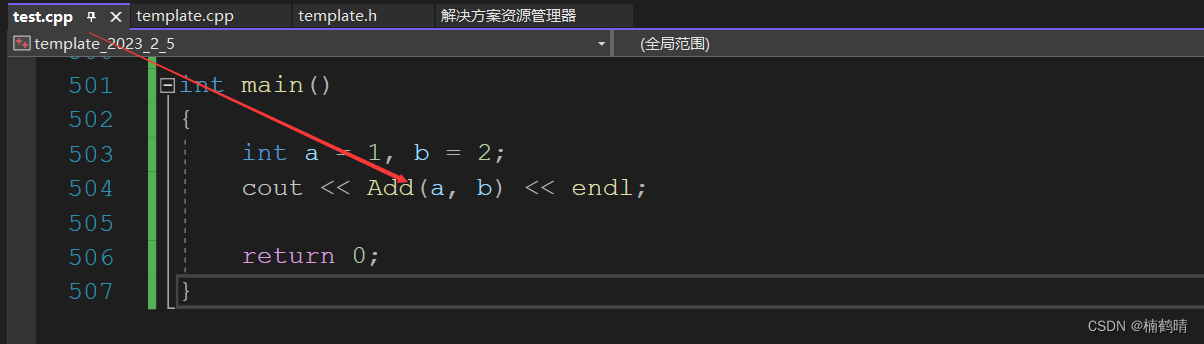
结果:
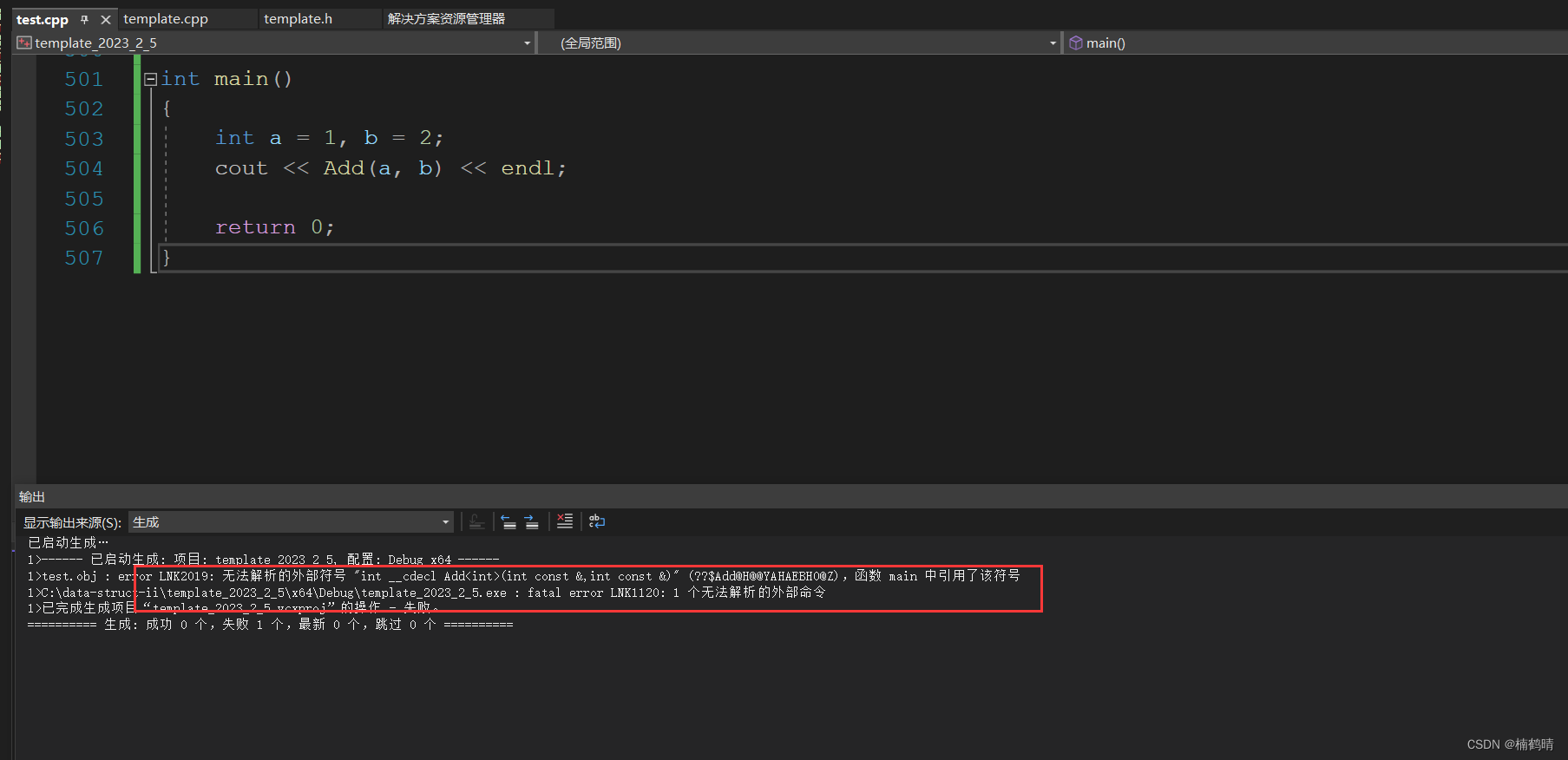
分析: 此时上面报的是链接错误,就是编译器找不到Add函数的地址,也就是符号表中没有Add函数的地址,原因:Add函数的声明放在头文件,定义放在源文件,在进行预处理的时候,<template.h>中的内容会分别在<template.cpp>和<test.cpp>中展开,最终会形成两个文件<template.o>和<test.o>,<template.o>中存在Add函数的声明和定义,但是在形成符号表的时候,由于编译器不知道模板参数T是什么类型,因此无法进行推演形成具体的类型,所以无法在符号表中形成Add函数的地址,在<test.o>中,由于只存在Add函数的声明,没有定义,所以无法形成地址,故最终在链接的时候,调用Add函数处需要到符号表找Add函数的地址,发现找不到,从而出现链接错误。
正确的做法就是:模板的声明和定义不能分离到两个文件中。
- 代码2:
-
- 头文件
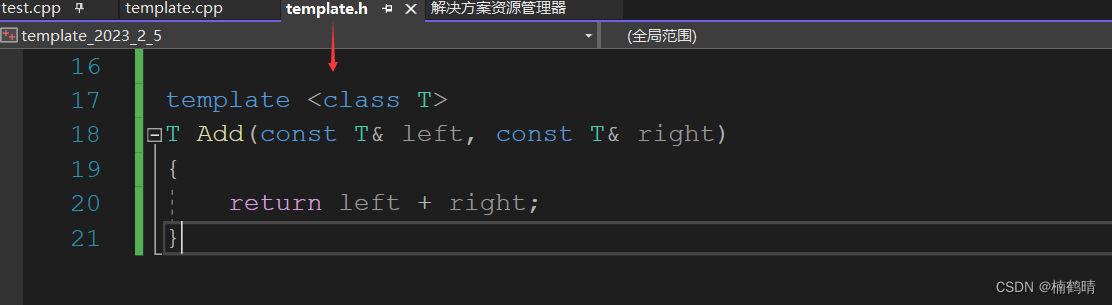
- 头文件
- 调用处
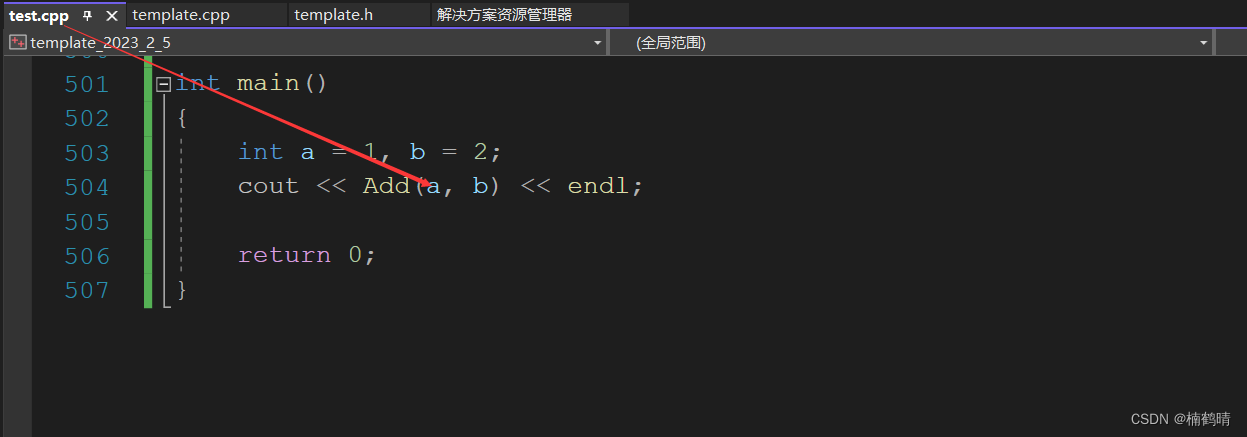
运行结果:

例子2:类模板中成员函数的声明和定义分离在两个文件(Vector) - 头文件:成员函数的声明
template <class T>
class Vector
{
public:
// 成员函数的声明
// 构造函数
Vector(int capacity = 10);
// 拷贝构造函数
Vector(const Vector<T>& v);
// 赋值运算符重载
Vector<T>& operator=(const Vector<T>& v);
// 插入
void push(const T& data);
private:
T* _a;
int _size;
int _capacity;
};
- 源文件:成员函数的定义
// 成员函数的定义
// 构造函数
template <class T>
Vector<T>::Vector(int capacity)
{
_a = new T[capacity];
_size = 0;
}
// 拷贝构造函数
template <class T>
Vector<T>::Vector(const Vector<T>& v)
{
}
// 赋值运算符重载
template <class T>
Vector<T>& Vector<T>::operator=(const Vector<T>& v)
{}
// 插入
template <class T>
void Vector<T>::push(const T& data)
{
}
- 调用
int main()
{
Vector<int> v1;
Vector<int> v2(v1);
Vector<int> v3;
v3 = v1;
v1.push(1);
return 0;
}
- 结果:
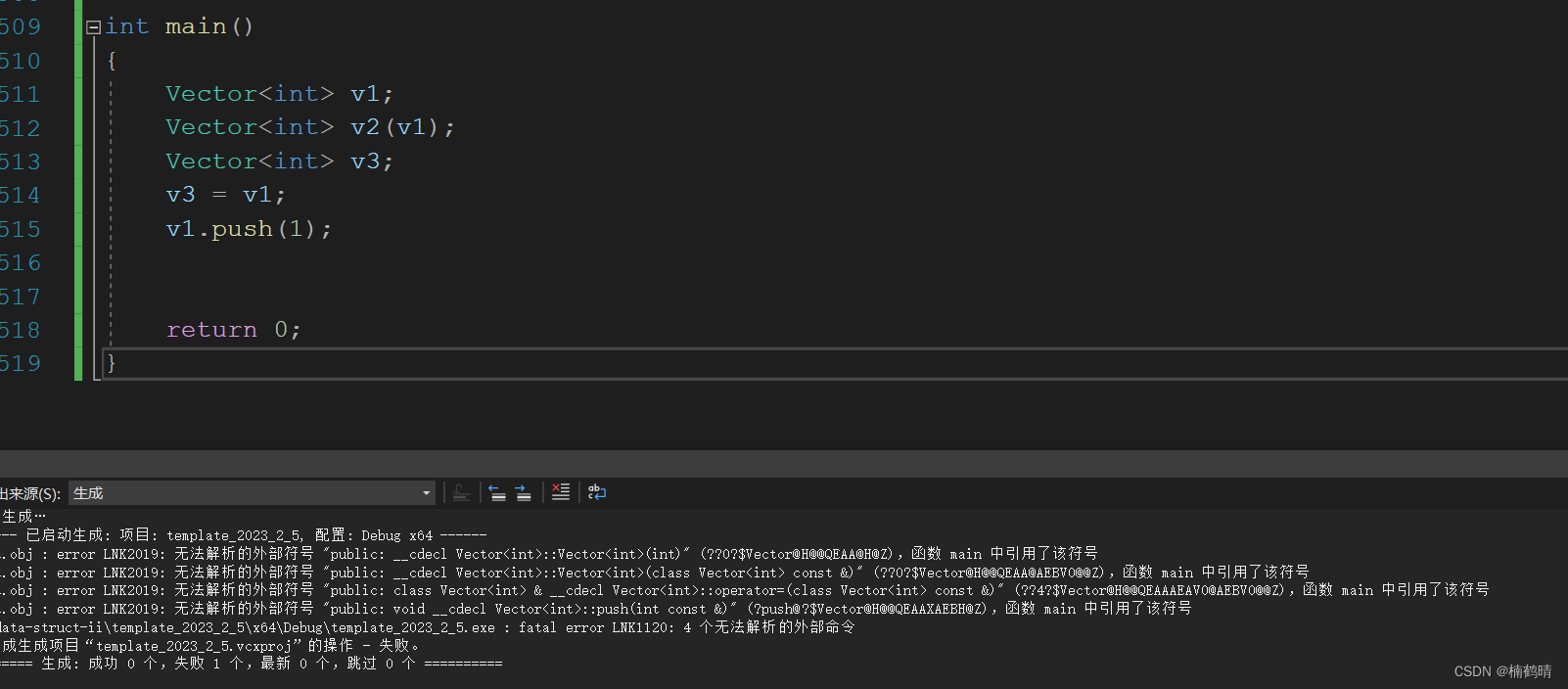
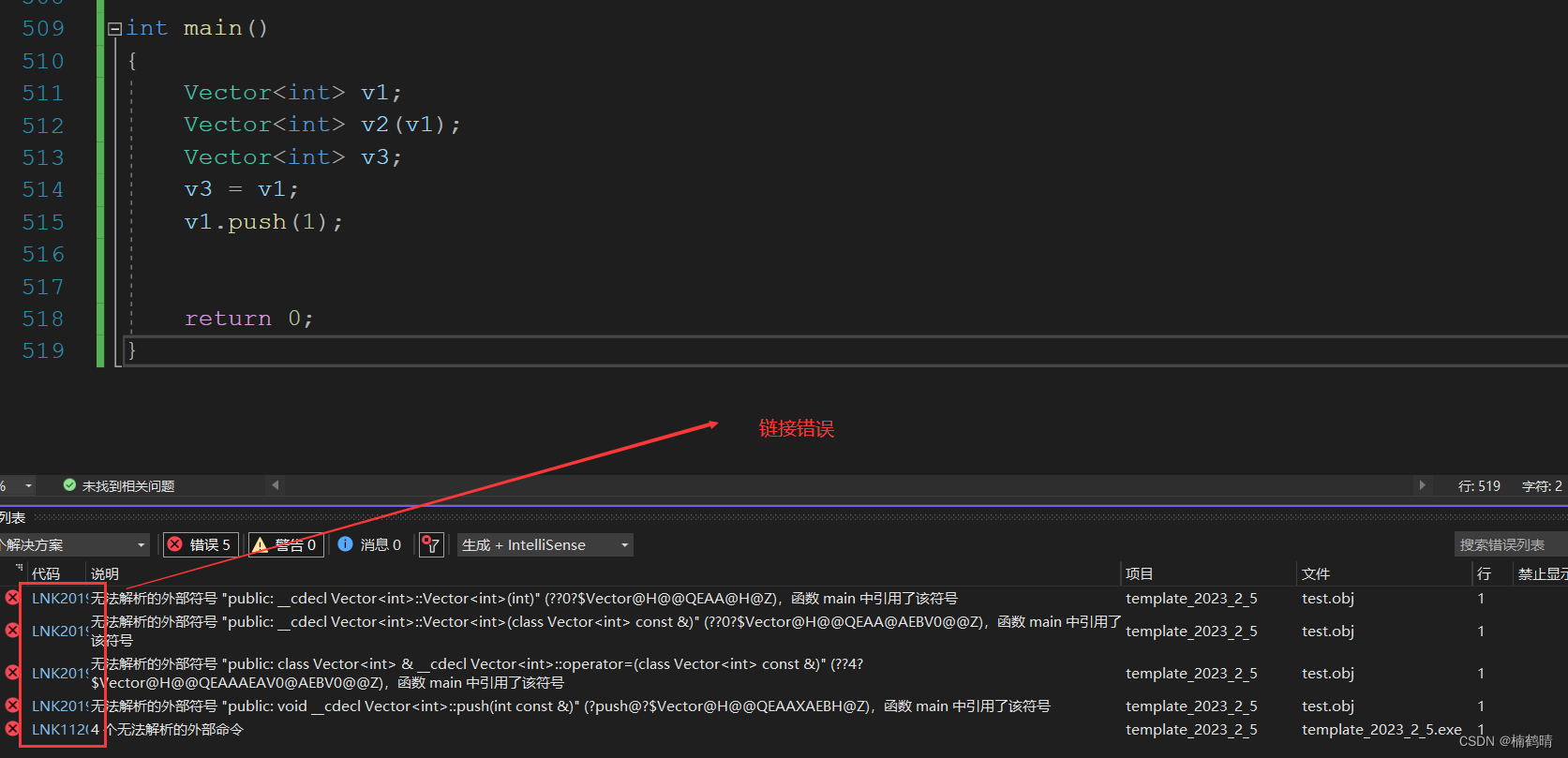
类模板中的成员函数的声明和定义分离在两个文件中,同样在形成符号表时,编译器无法知道模板参数的类型,所以不能形成对应成员函数的地址,所以最终在调用的时候需要去符号表找对应函数的地址就会发现找不到,从而出现链接错误。
修改后的代码:类模板中的成员函数的声明和定义放在同一个文件中
- 头文件
template <class T>
class Vector
{
public:
// 成员函数的声明
// 构造函数
Vector(int capacity = 10)
{
}
// 拷贝构造函数
Vector(const Vector<T>& v)
{
}
// 赋值运算符重载
Vector<T>& operator=(const Vector<T>& v)
{
return *this;
}
// 插入
void push(const T& data)
{}
private:
T* _a;
int _size;
int _capacity;
};
- 调用处
int main()
{
Vector<int> v1;
Vector<int> v2(v1);
Vector<int> v3;
v3 = v1;
v1.push(1);
return 0;
}
- 结果:
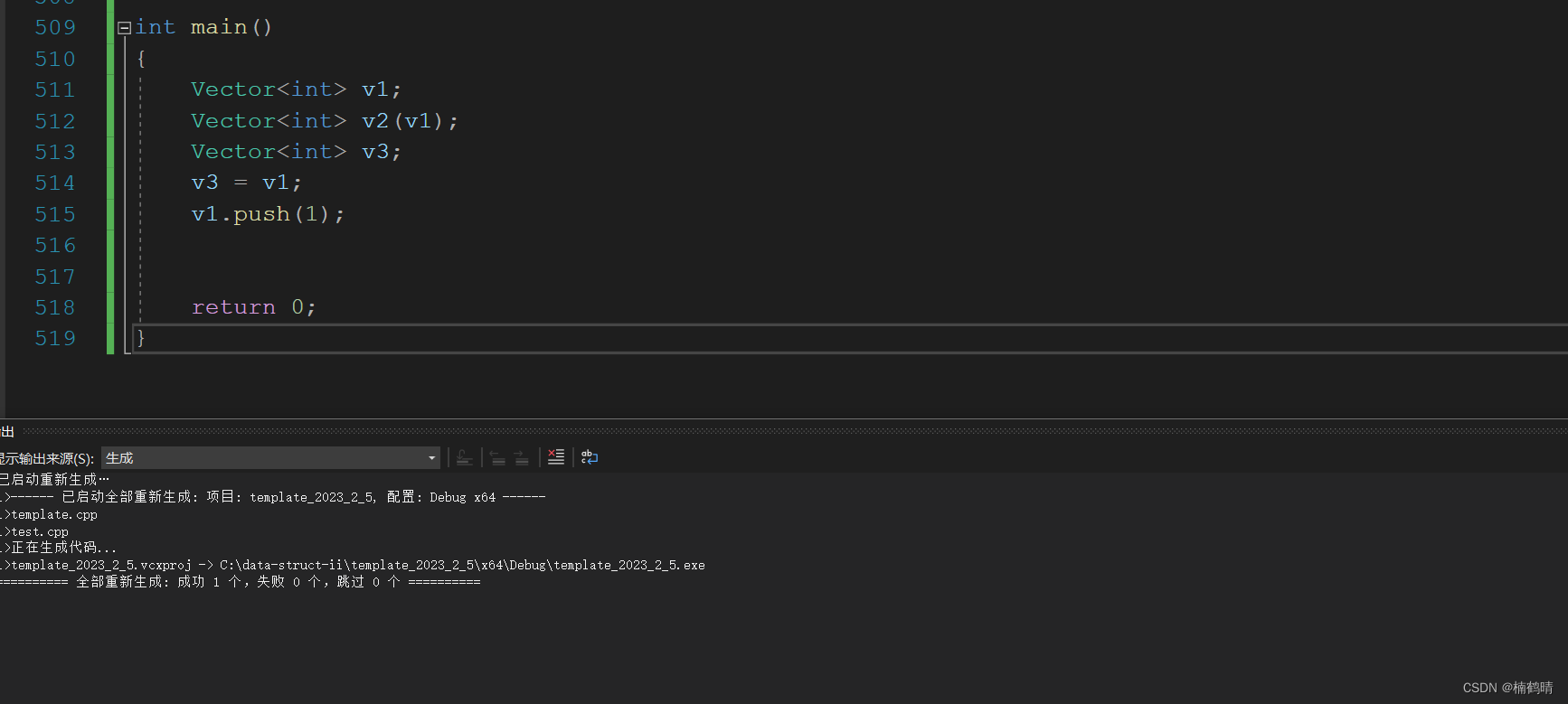














 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









