






# 前言
本人也是一个小白,什么也不懂,如果有什么地方说错了,可以评论区交流,大家一起进步OVO
资源获取:https://github.com/THU-MIG/yolov10
如果没有魔法可能比较难下,可以去其他博主那百度网盘下载,我这里还没弄。
建议可以全部下载下来,反正也不大,可以在代码中修改,反复调参对比使用。
本文目的在于裁剪影像,训练模型,预测(包含矢量提取),以及最后的merge。输入的是一张影像和一个预训练模型,最后得到的是一张完整的影像,以及一个merge之后的屋顶光伏矢量
# 一.裁剪影像
由于本人使用的是遥感影像检测屋顶光伏,tif影像太大影响操作,所以要先进行裁剪操作。话不多说直接上代码(如果无需此操作可以跳过)
## crop_tif函数
def crop_tif(input_file, output_dir, crop_size):
# 打开输入的 TIFF 文件
dataset = gdal.Open(input_file)
if dataset is None:
print(f"错误: 无法打开文件: {input_file}")
return
img_width = dataset.RasterXSize
img_height = dataset.RasterYSize
crop_width, crop_height = crop_size
# 获取投影和地理信息
projection = dataset.GetProjection()
geo_transform = dataset.GetGeoTransform()
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 计数器用于命名裁剪后的图像
counter = 1
# 计算裁剪区域的数量
for i in range(0, img_width, crop_width):
for j in range(0, img_height, crop_height):
# 定义裁剪区域
x_offset = i
y_offset = j
x_size = min(crop_width, img_width - x_offset)
y_size = min(crop_height, img_height - y_offset)
# 读取裁剪区域的数据
try:
data = dataset.ReadAsArray(x_offset, y_offset, x_size, y_size)
except Exception as e:
print(f"错误: 读取裁剪区域数据失败: {e}")
continue
# 创建裁剪后的文件路径
output_file = os.path.join(output_dir, f"crop_{counter}.tif")
driver = gdal.GetDriverByName('GTiff')
if driver is None:
print("错误: 未找到 GTiff 驱动")
return
out_dataset = driver.Create(output_file, x_size, y_size, dataset.RasterCount, gdal.GDT_Byte)
if out_dataset is None:
print(f"错误: 无法创建输出文件: {output_file}")
continue
# 设置投影和地理信息
out_dataset.SetProjection(projection)
out_dataset.SetGeoTransform([
geo_transform[0] + x_offset * geo_transform[1],
geo_transform[1],
geo_transform[2],
geo_transform[3] + y_offset * geo_transform[5],
geo_transform[4],
geo_transform[5]
])
# 写入数据
for band in range(dataset.RasterCount):
out_band = out_dataset.GetRasterBand(band + 1)
out_band.WriteArray(data[band])
out_band.FlushCache()
# 清理
out_dataset = None
print(f"裁剪完成: {output_file}")
counter += 1
函数中使用gdal.open()打开tif图像,如果打开会弹出报错。
影像高度:img_height
影像宽:img_weight
裁剪高度:crop_height
裁剪宽:crop_weight
当然,裁剪后的地理信息也不能丢失。
用for循环遍历进行影像裁剪。
## process_directory函数
def process_directory(input_dir, output_dir, crop_size):
# 遍历目录中的所有 TIFF 图像
for filename in os.listdir(input_dir):
if filename.lower().endswith('.tif'):
input_file = os.path.join(input_dir, filename)
print(f"处理文件: {input_file}")
crop_tif(input_file, output_dir, crop_size)
print(f"文件处理完成: {input_file}")这个函数就比较简单了,遍历目录下所有以.tif结尾的影像,然后进行裁剪。(要不是一个一级标题下只跟着一个二级标题太尴尬我也不会拿出来说TAT)
原图像:
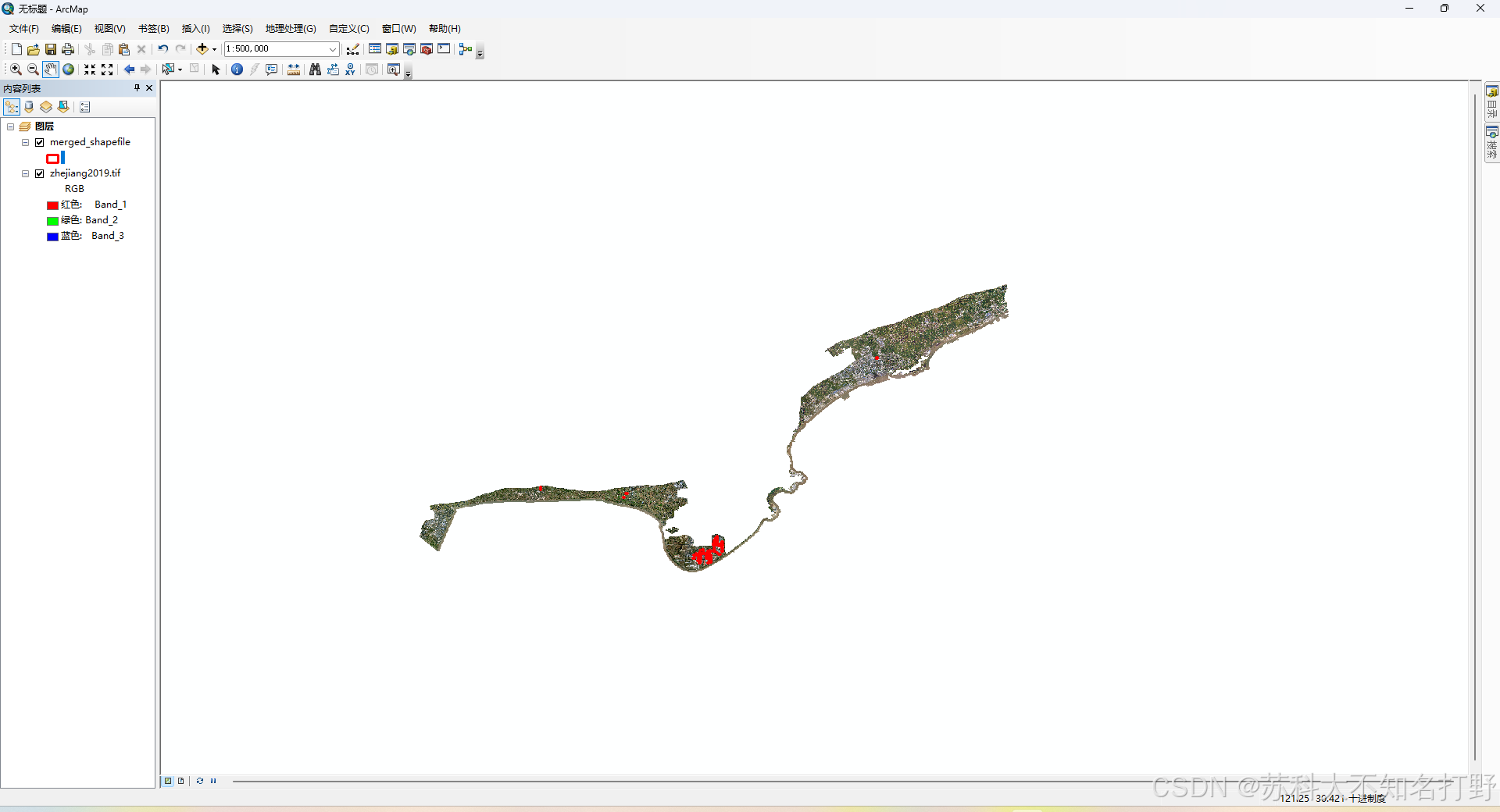
裁剪之后:
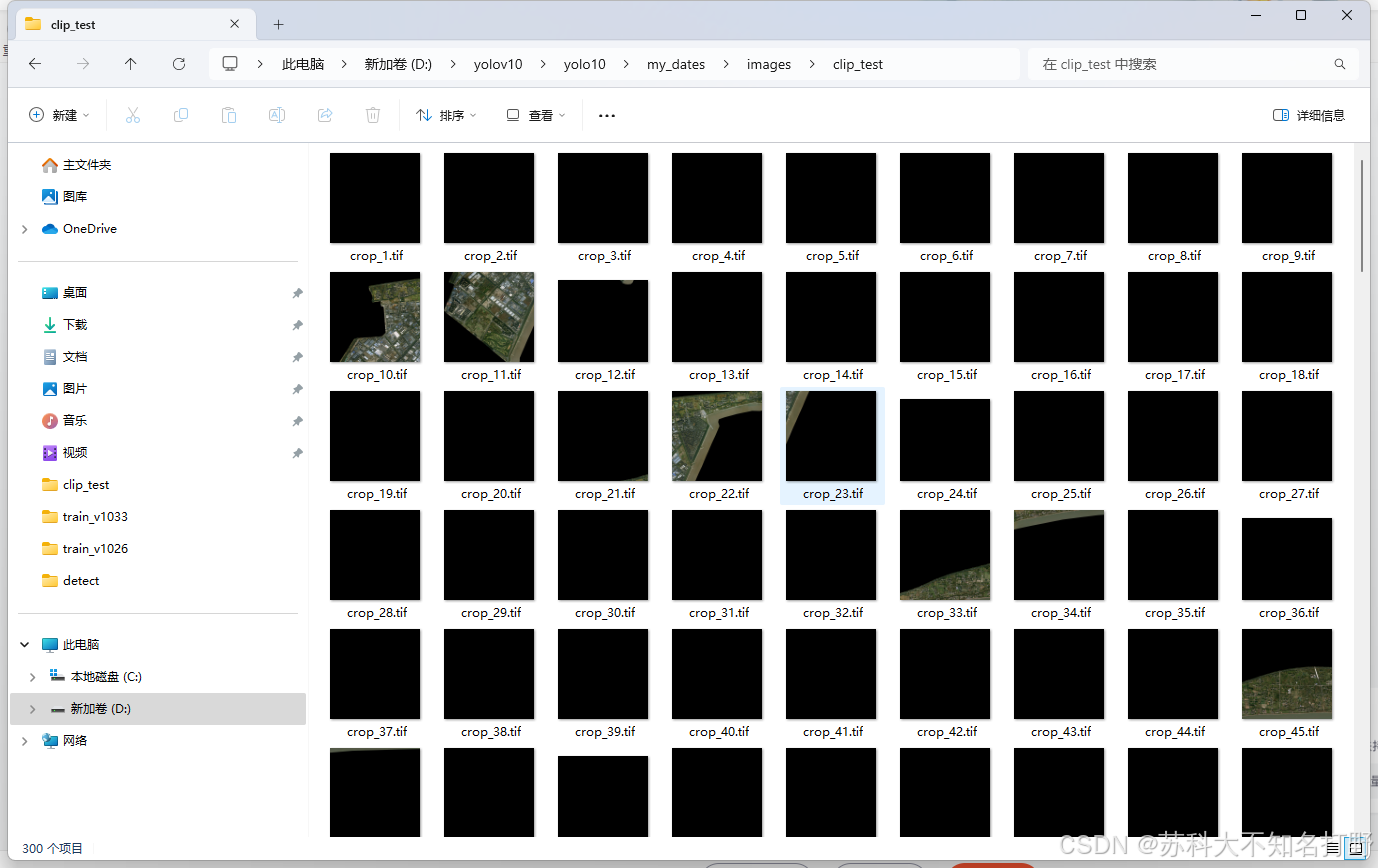
当然这里有很多黑色的无用的影像,这里我们先不做处理,后面会处理它。黑色是由于这张影像太不规则了,裁到了影像之外的地方。
# 二.模型训练
刚刚跳过裁剪的同学们可以看过来了,这里都要考的。文章开头给了链接可以下载各种版本的yolov10与训练权重,可以自行下载

## 数据集的准备
yolo的数据集需要有标签,而且标签的形式需要是txt的形式。可以自行准备图片然后用以下工具自行添加标签作为数据集
https://github.com/wkentaro/labelme 由此下载labelme
点击Download zip 下载压缩包
在ananconda prompt中下载labelme 以及pyqt5
pip install pyqt5
pip install labelme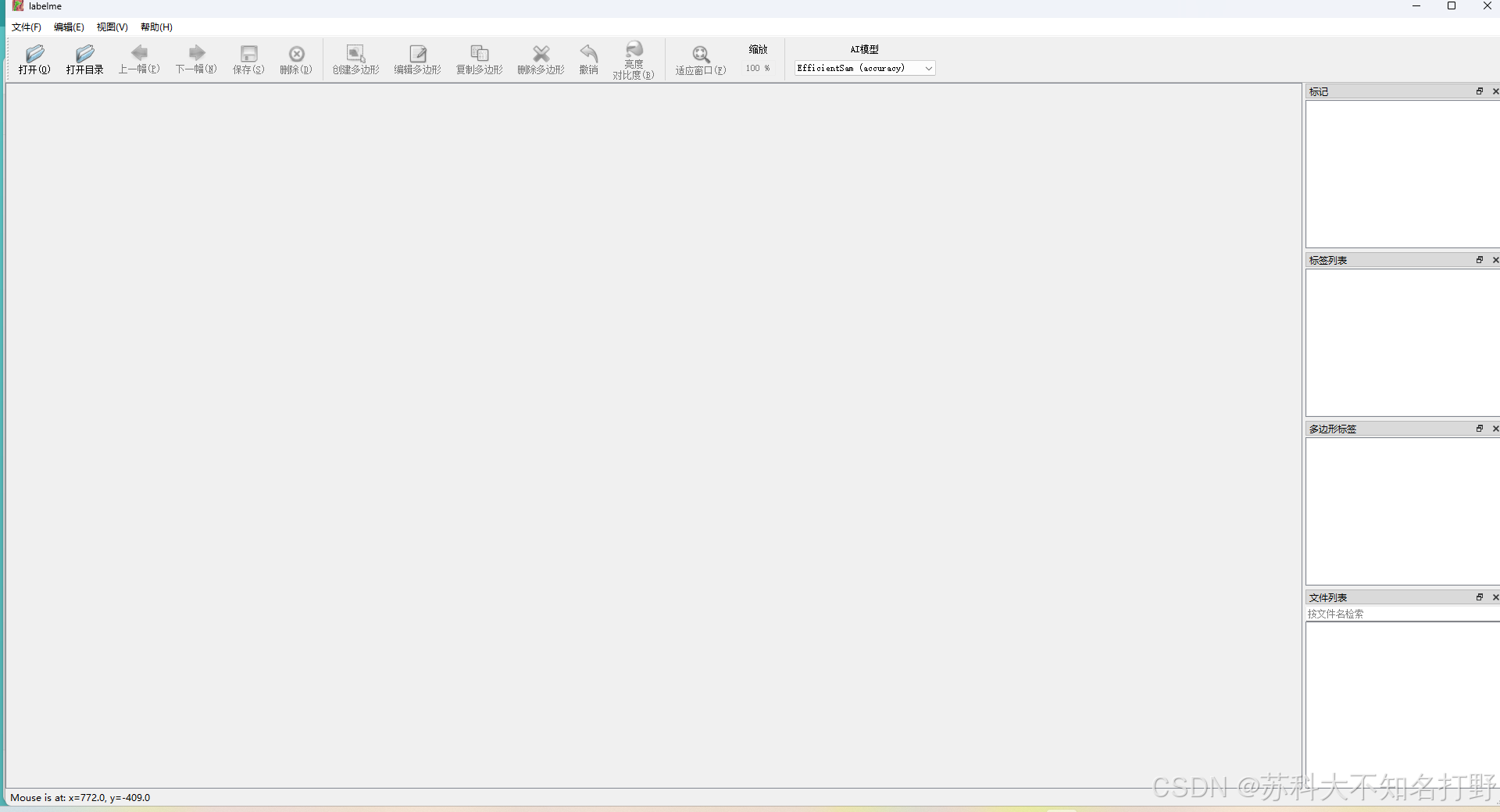
打开页面如上,打开数据集所在目录,一个一个打开影像然后手动框选之后添加标签,告诉机器要识别的这个物品叫什么,有什么特征,以方便训练自己的模型。
## 配置
上面说了,yolov10有很多不同的版本。我们打开所要使用的版本的yaml文件进行修改。
路径在文件夹中位置如下:
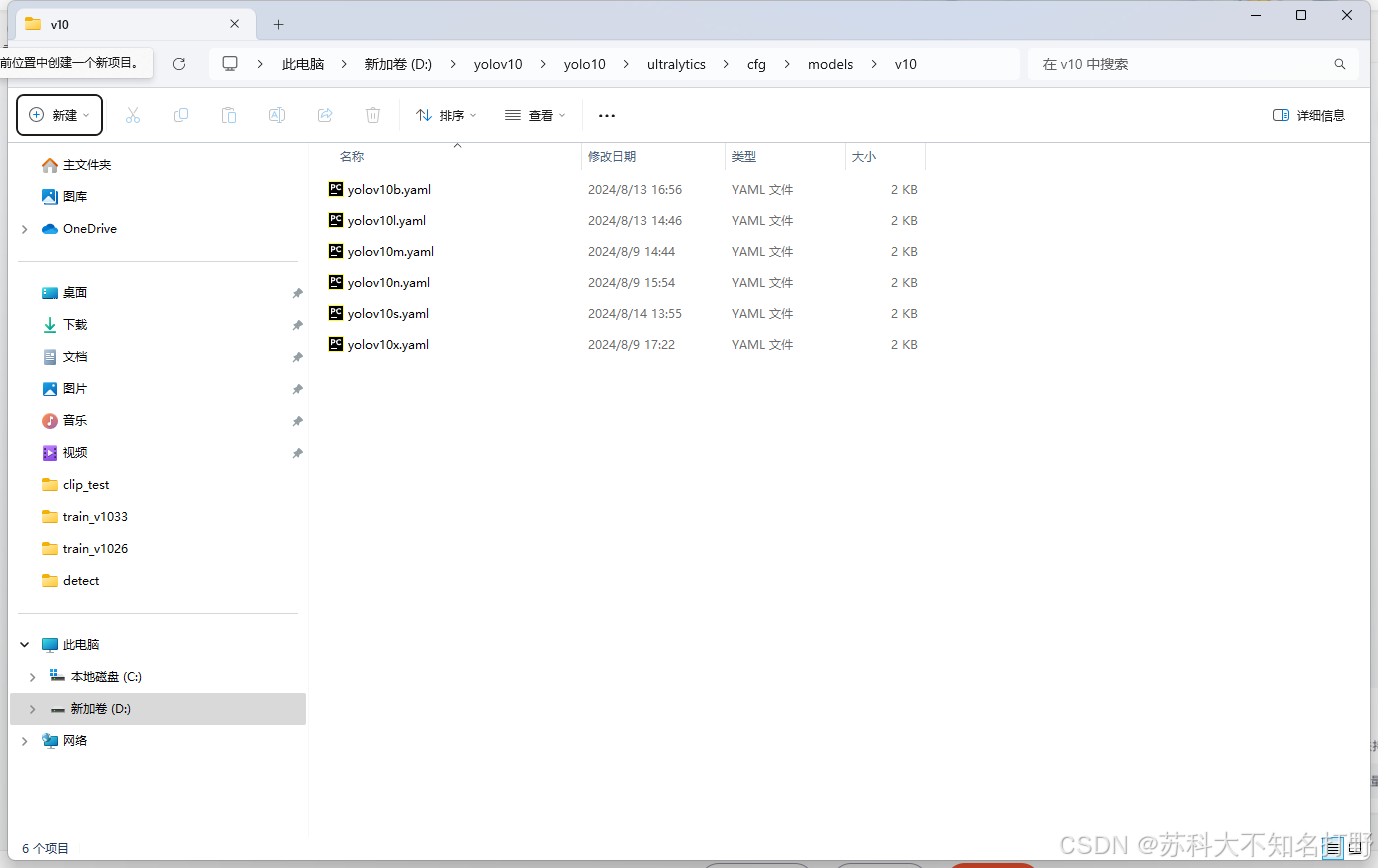
这些是我们的模型配置文件,用pycharm打开他们进行编辑:
![]()
需要修改的地方就这一处,将数字改成我们的标签数量,由于我只需要识别屋顶光伏,所以为1
下面我们需要配置数据集的配置文件,打开与coco联名的yaml文件,位置如下
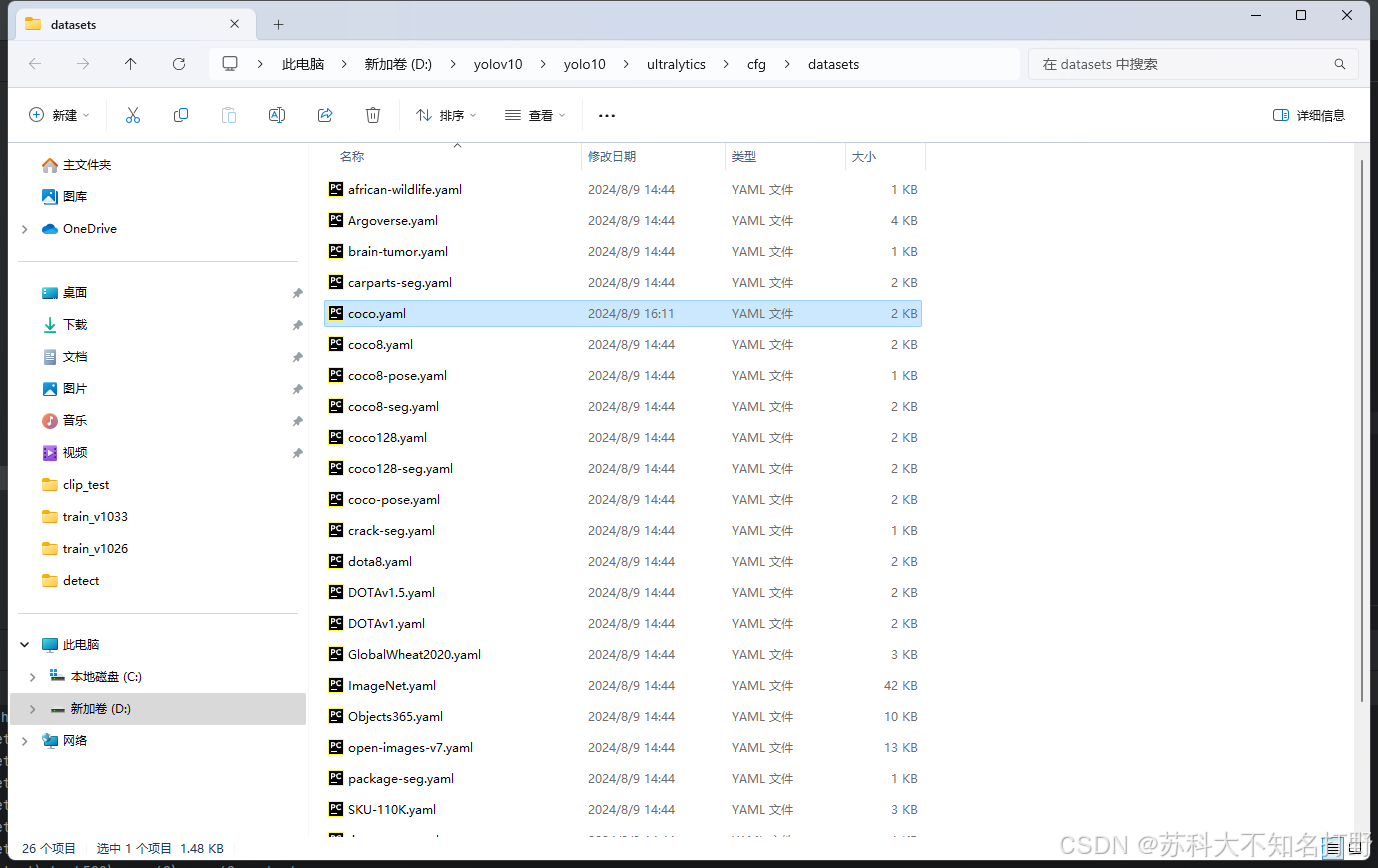
打开之后进行编辑:

将path注释掉,然后输入我们自己所对应的训练集(train)数据,验证集(val)数据。test也不用管。
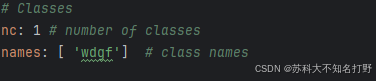
修改标签数量,以及标签的名字。我只有一个叫wdgf的标签,所以就这样很简单。
还有一个地方需要我们配置,就是default.yaml
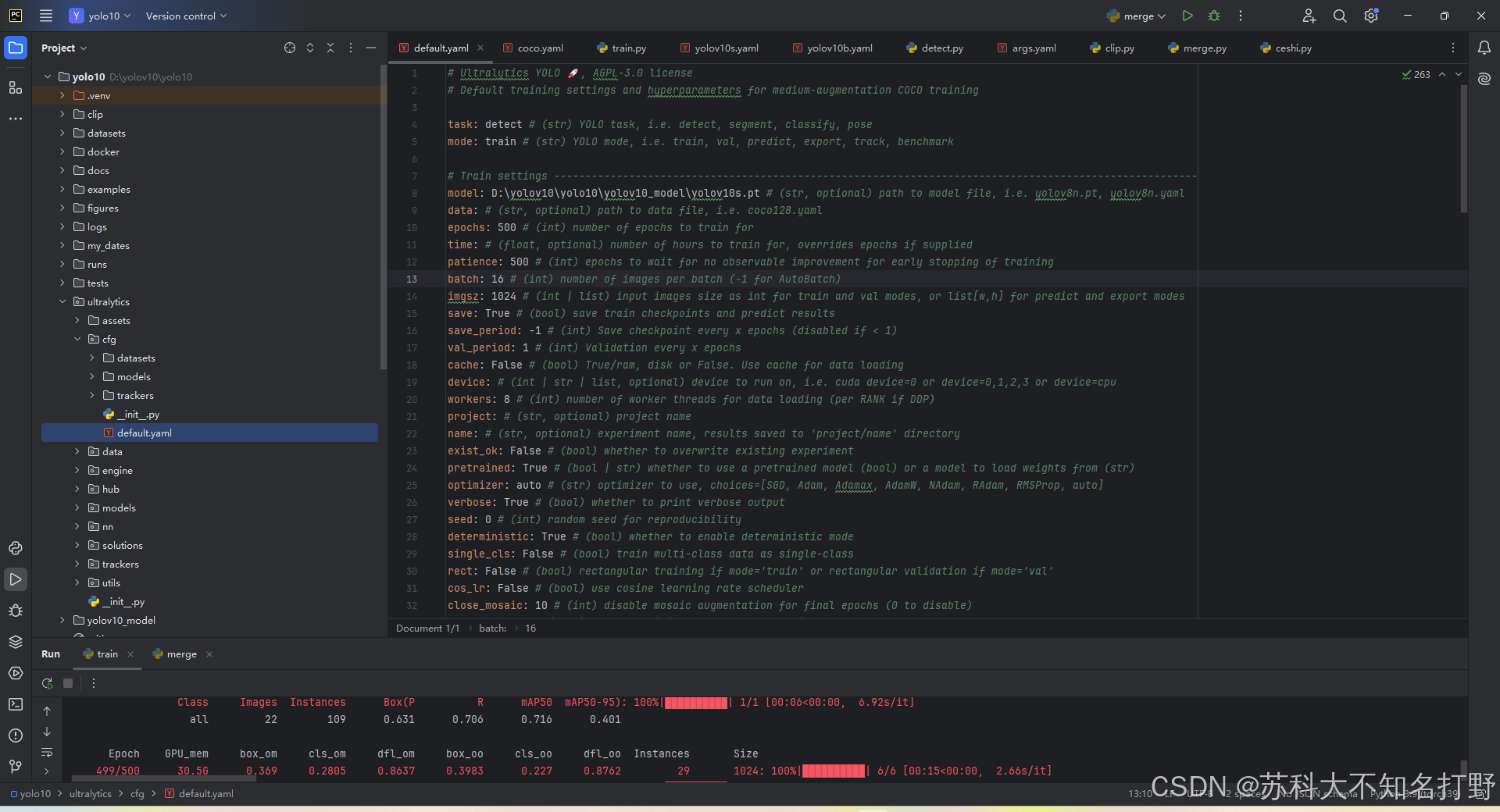
似乎不需要调用,如果没有在代码中指明,就会使用这里的配置。我也不太懂
## 训练
接下来就是模型的训练了
模型训练的代码并不是很多,主要是调用我们所调整的配置文件:
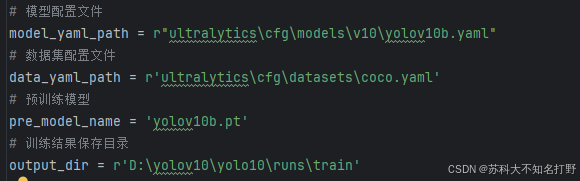
训练时最好使用安装了pytorch的环境,yolo检测是否可以调用GPU之后会调用我们的GPU训练,比CPU快太多了。
![]()
batch需要调整,过大的话所要达到相同的精度就需要更多的轮次(epoch),过小的话,会在局部最优解上浪费太多时间,缓慢前进。
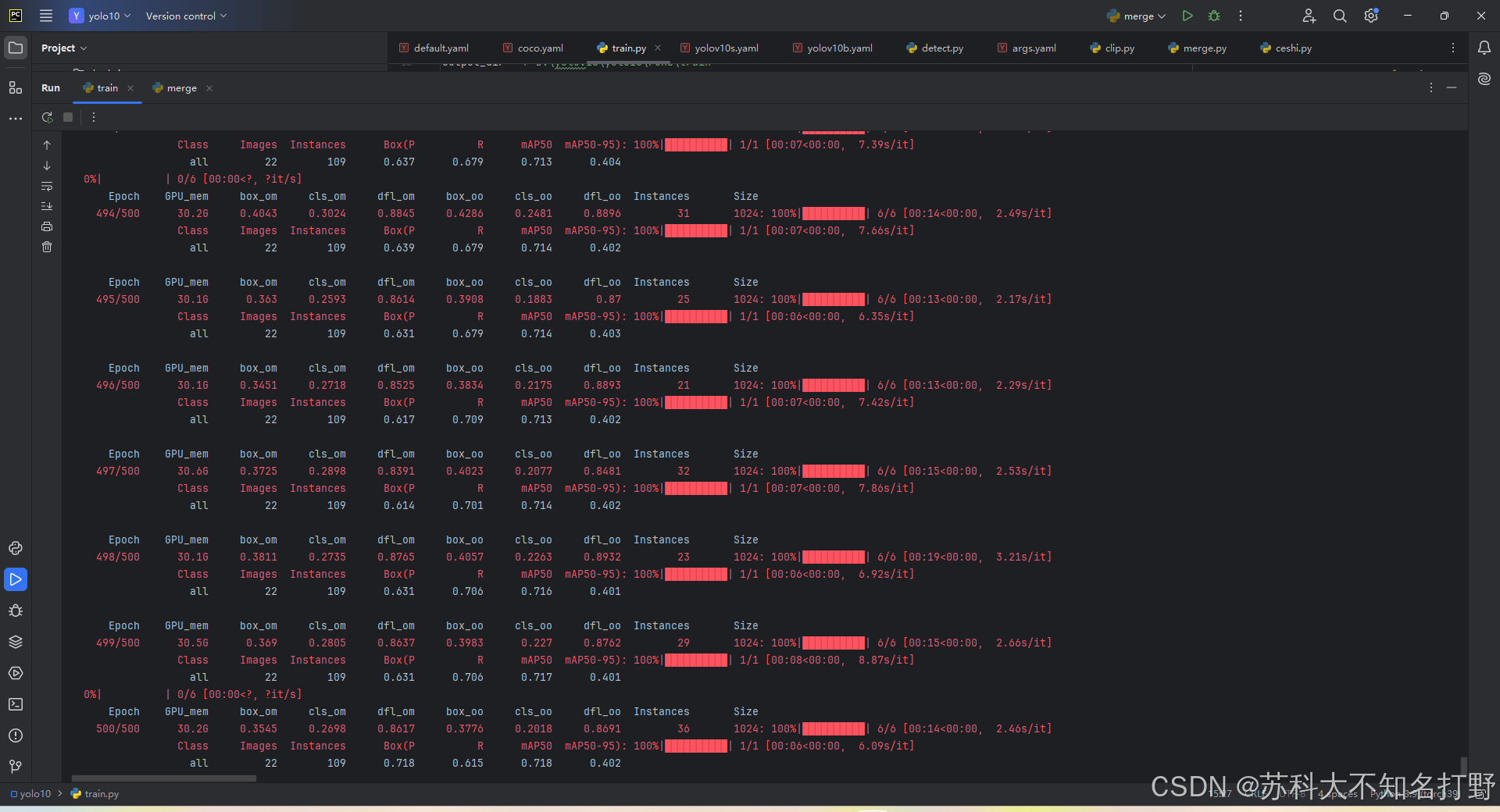
训练之后是这样的这是用yolo10b训练的,比yolo10s慢了一点,准确率相差不多,都还能用。
训练之后会得到这些: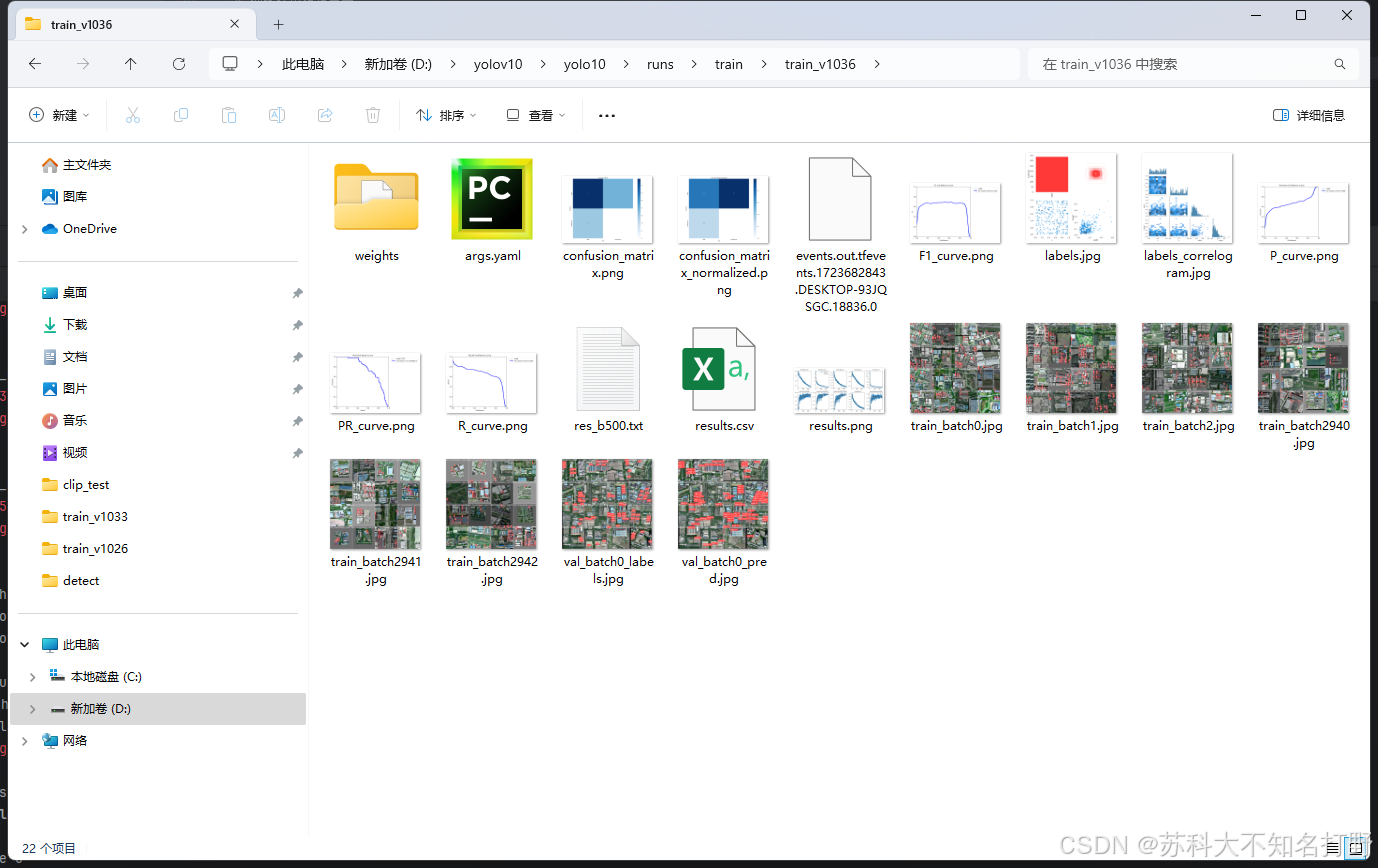
我么需要关注的只有验证集的训练成果,以及weights中的best.pt(最好的)last.pt(最近的)应该不需要使用。
这样我们就训练出了自己所需要的训练模型,接下来就是将他投入使用预测,检验他的战力了。
#三.影像预测
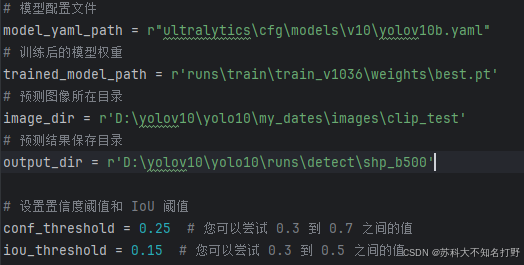
依旧是导入各种参数,这里要注意的是iou(交并比)以及conf(置信度)
iou:在目标检测中常用到一个指标IoU,又称交并比,用于衡量一幅图像中两个边界框的重合度。在训练阶段,可以用于衡量锚框和物体边界框之间的相似度,来给每个锚点划分正负样本,即给锚点匹配标签,同时也可以用作损失函数,通过提高预测边界框与真实边界框之间的相似度来改善网络预测物体边界框的能力;在测试阶段,可以利用IoU来衡量预测边界框之间的重合度,用于过滤重合度高的边界框,即参与NMS运算。
通俗来讲就是防止太密集,过滤重合度高的边框
置信度:置信度(Confidence)在统计学和机器学习中是一个重要的概念,反映了一个估计值或预测结果的可靠性和准确性。置信度通常通过置信区间或置信水平来表示
简而言之,置信度就是yolo目标检测中红框上面的数字,越大就说明机器越相信他,比如你想检测图片中的人,yolo检测出了他并框选他显示:0.25.说明机器觉得他有百分之25的可能是个人。我们可以通过调节置信度,来筛选一些检测结果。
## 四.结束
讲到这里大家应该也都可以使用yolov10来进行自己的目标检测了。大家一起加油,有问题发评论区大家一起解决。

















 3407
3407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









