







主题背景
近年来随着大数据技术产业的加速发展,全国各地对大数据技术类的人才需求也越来越多,为了明确今后大数据技术类产业人才培养方向,在多地进行大数据技术类公司岗位情况调研分析。你将承担模拟调研分析的任务,通过在招聘网站进行招聘信息的爬取,获取到公司工作地点、岗位名称、招聘要求、招聘人数等信息,并通过对数据的清洗和分析,得出各地域招聘人数,“大数据”职位薪资待遇等信息。
大数据价值链中最重要的一个环节就是数据分析,其目标是提取数据中隐藏的数据,提供有意义的建议以辅助制定正确的决策。本次大作业通过 Hive 进行数据分析,从杂乱无章的数据
中萃取和提炼有价值的信息,进而找出研究对象的内在规律。
数据:

任务要求
- 将清洗后的数据(hivedata)加载到 Hive 数据仓库中;
- 通过运行 HQL 命令完成数据分析统计;
- 在 Hive 中执行 SQL 脚本,并查看表中大数据职位区域分析、大数据职位薪资待
遇分析、技能要求分析和福利待遇分析。
Hive操作错误解决:

set hive.exec.mode.local.auto=true;
结果保存
hive -e "select * from test.t order by count desc" > /opt/out/city.txt
- 图例
运行HQL命令完成数据分析统计
# 外部表形式
create external table hiveexam(area string, day string, welfare array<string>, require array<string>) row format delimited fields terminated by "," collection items terminated by "-" location "/user/exam";
# 传入数据
./hdfs dfs -put /opt/file/hivedata /user/exam
# 数据分组 作为查看
select area, collect_set(welfares), collect_set(requires) from hiveexam lateral view explode(welfare) x as welfares lateral view explode(require) w as requires group by area;
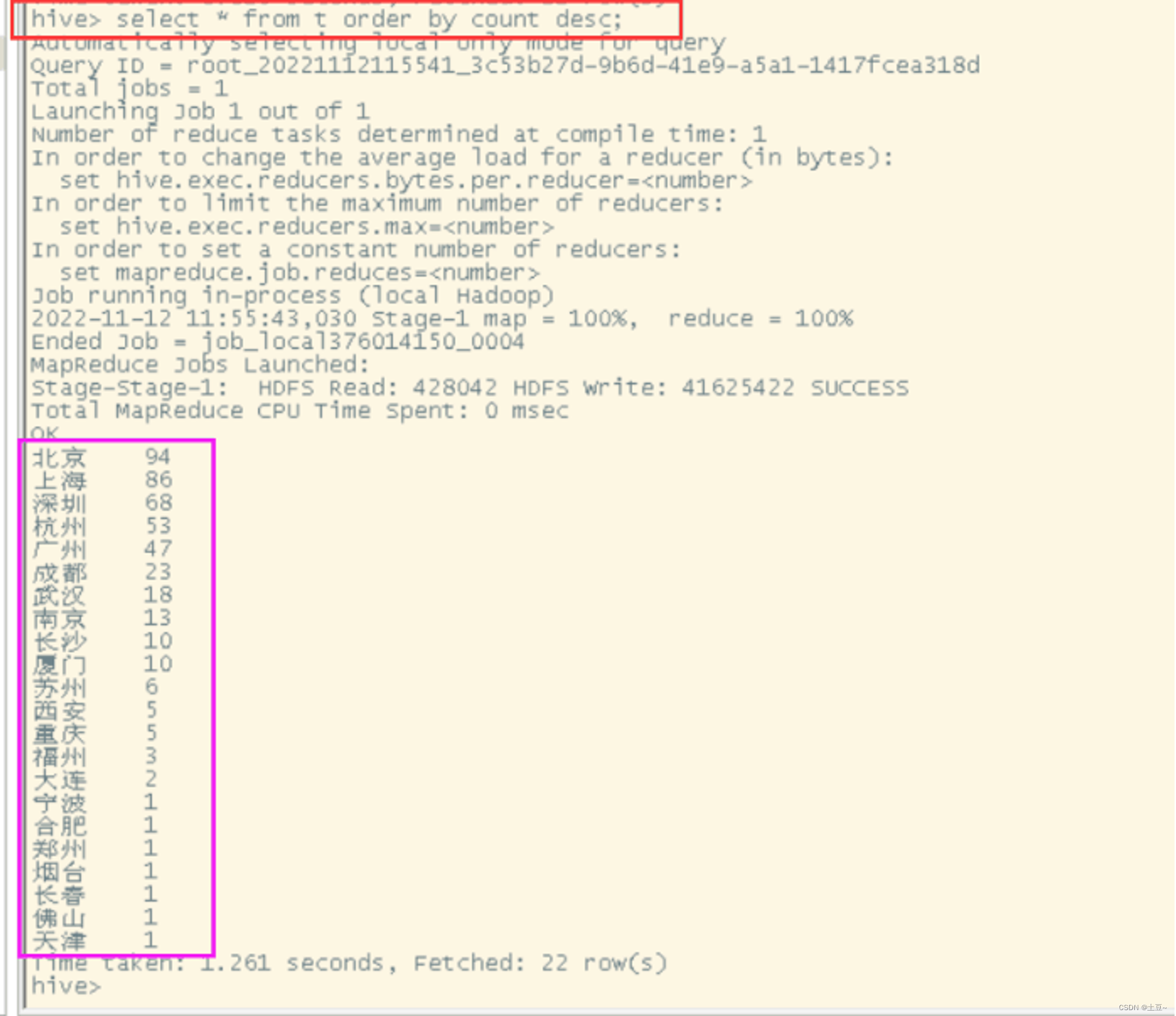
1、城市区域分析
# 将数据分组赋值给临时表
create table temp_hive_exam(area string, count int);
insert into temp_hive_exam select area, count(*) from hiveexam group by area;
select * from temp_hive_exam order by count desc;
- 图例
保存至HDFS下
create table desc_city(city string, count int);
insert into desc_city select * from t order by count desc;
# 查看数据
select * from desc_city;
hive -e "select * from test.desc_city" > /opt/out/city.txt
./hdfs dfs -put /opt/out/city.txt /hiveout
#查看
./hdfs dfs -cat /hiveout/city.txt
- 图例
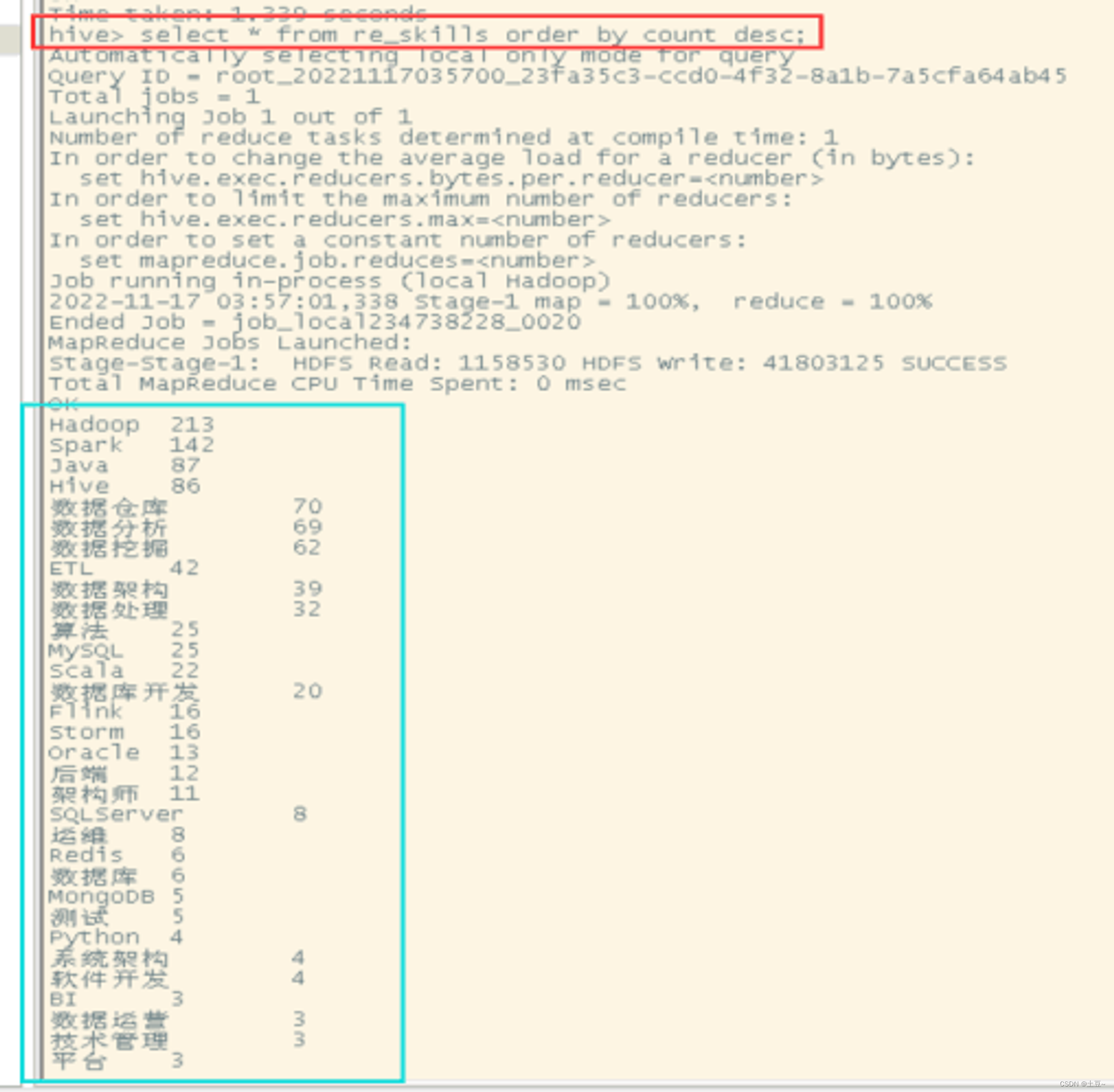
2、技能分析
create table temp_skill as select explode(s.require) from hiveexam s;
create table re_skills(name string, count int);
insert into re_skills select col, count(*) from temp_skill group by col;
select * from re_skills order by count desc;
- 图例
# 保存至HDFS
create table desc_skill(skill string, count int);
insert into desc_skill select * from re_skills order by count desc;
# 查看数据
select * from desc_skill;
hive -e "select * from test.desc_skill" > /opt/out/skills.txt
./hdfs dfs -put /opt/out/skills.txt /hiveout
#查看
./hdfs dfs -cat /hiveout/skills.txt
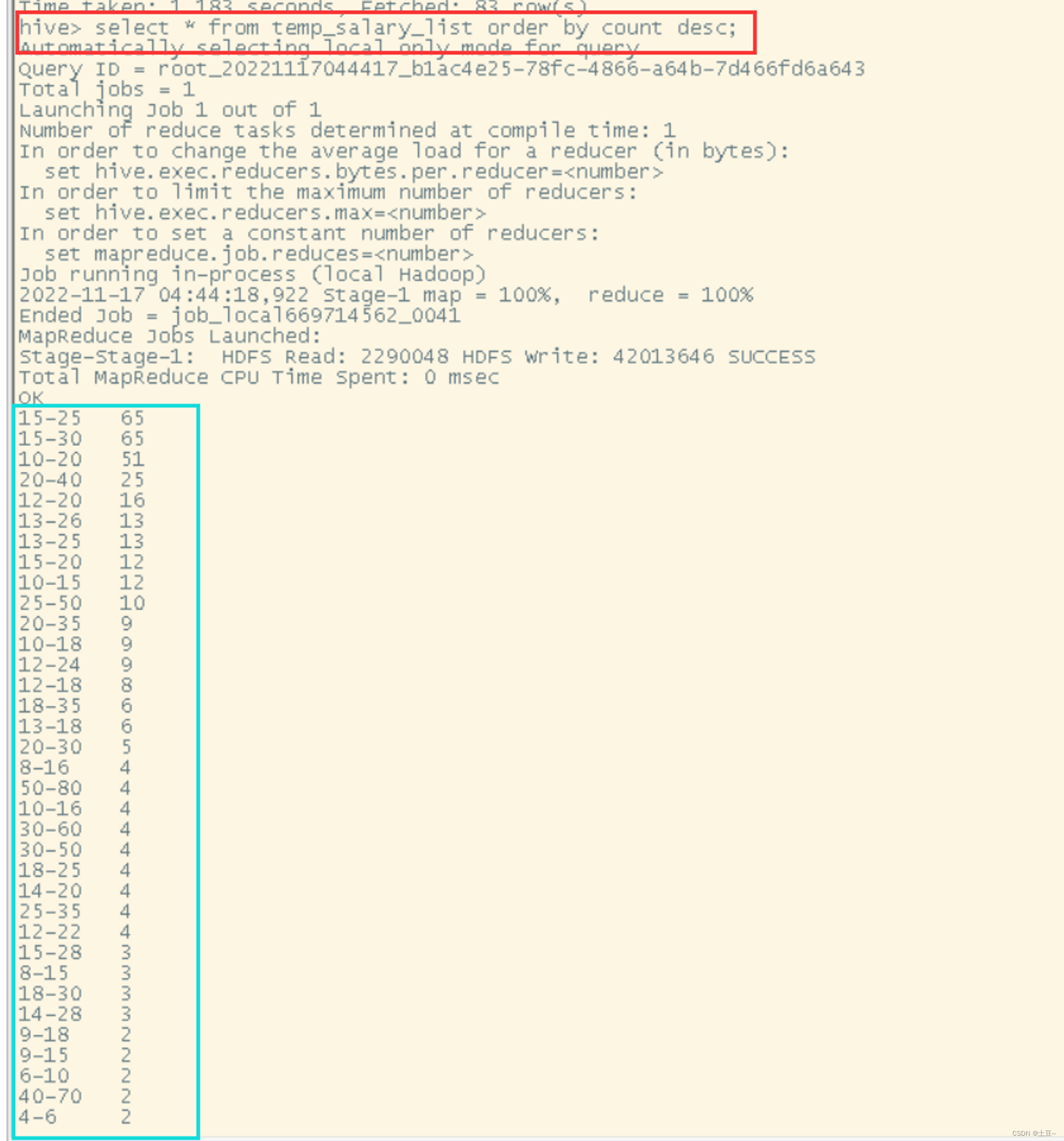
3、薪资分析
create table temp_salary as select day from hiveexam s;
create table temp_salary_list(salary string, count int);
insert into temp_salary_list select day, count(*) from temp_salary group by day;
select * from temp_salary_list order by count desc;
-
图例
# 保存至HDFS
create table desc_salary(salary string, count int);
insert into desc_salary select * from temp_salary_list order by count desc;
# 查看数据
select * from desc_salary;
hive -e "select * from test.desc_salary" > /opt/out/salary.txt;
./hdfs dfs -put /opt/out/salary.txt /hiveout
#查看
./hdfs dfs -cat /hiveout/salary.txt
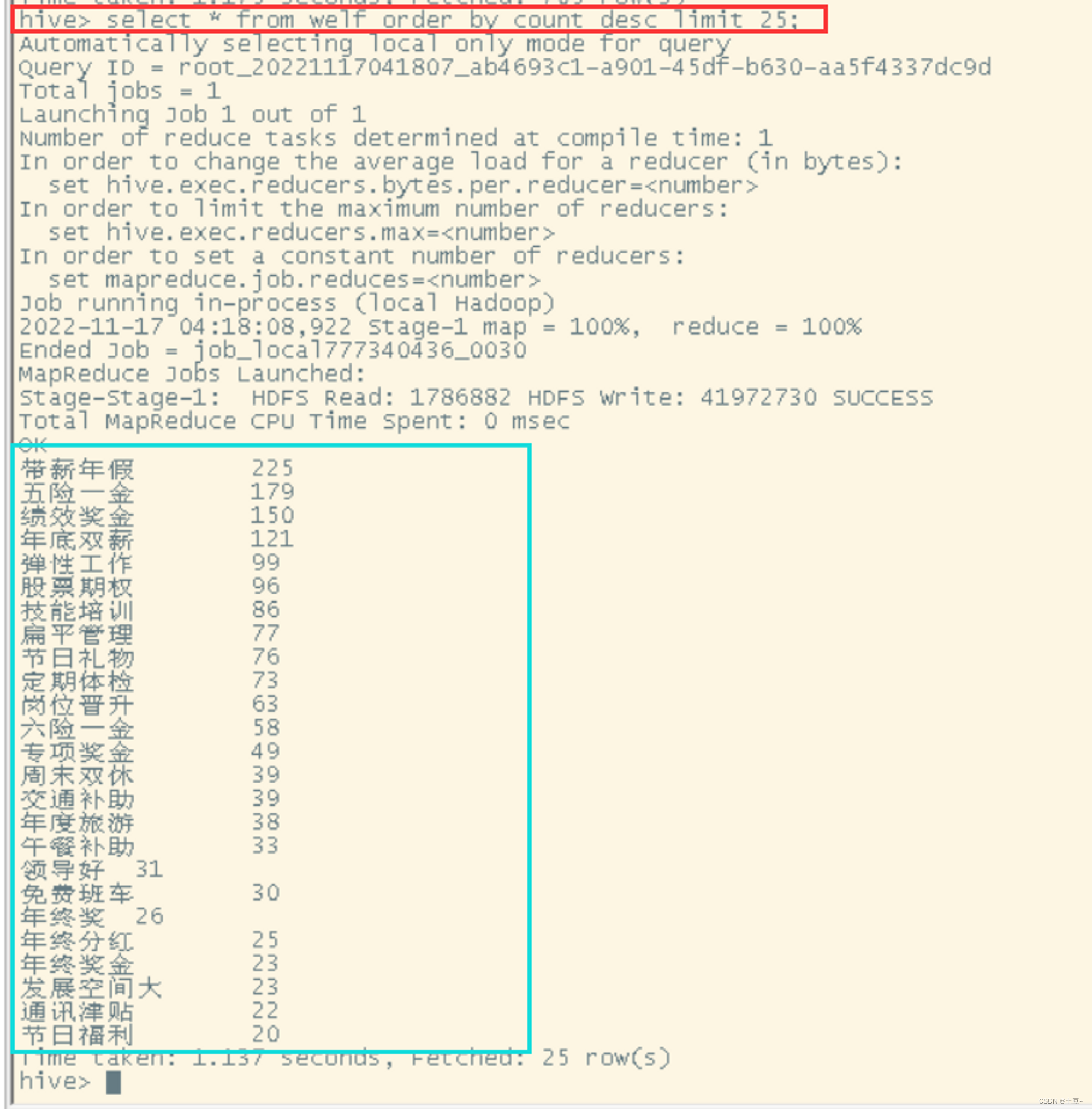
4、福利待遇分析
create table temp_welfare as select explode(s.welfare) from hiveexam s;
create table welf(name string, count int);
insert into welf select col, count(*) from temp_welfare group by col;
select * from welf order by count desc;
- 图例
# 保存至HDFS
create table desc_welfare(welfare string, count int);
insert into desc_welfare select * from welf order by count desc;
# 查看数据
select * from desc_welfare;
hive -e "select * from test.desc_welfare" > /opt/out/welfare.txt;
./hdfs dfs -put /opt/out/welfare.txt /hiveout
#查看
./hdfs dfs -cat /hiveout/welfare.txt















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









