






文章目录
1、NLP文本处理

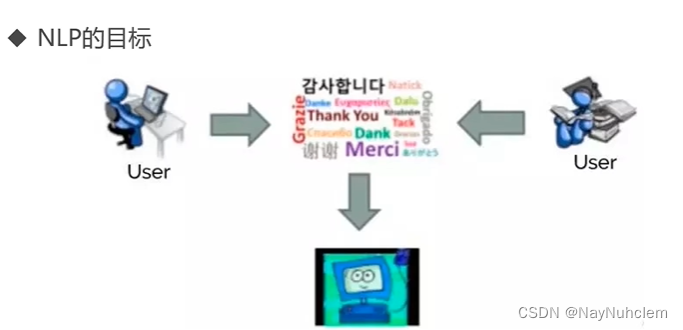
NLP的目标
聊天机器人的主要目标是准确理解和解释用户输入。NLP 在此过程中发挥着至关重要的作用,它使聊天机器人能够理解并提取人类语言的含义。NLP 算法采用标记化、句法分析和语义解析等技术将用户消息分解为有意义的组件。通过破译用户查询的意图和上下文,聊天机器人可以提供适当的响应,从而实现更有效、更自然的对话。
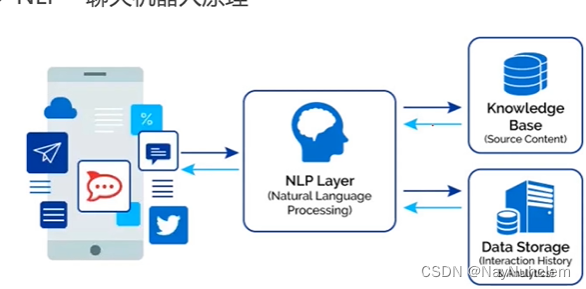
NLP-聊天机器人的原理
核心原理是利用 机器学习 和 深度学习 算法,对大量的语料库进行训练和学习,从而实现对自然语言的理解和生成。
传统nlp与深度学习nlp的区别
输入没有区别,而深度学习nlp在网络结构做了一个预处理,同时深度学习NLP主要依赖于神经网络和大规模数据,而传统NLP则主要依赖于规则和手工工程。

2、文本处理方法
文本处理方法处理前面的TF-IDF,Jieba分词,还有Onehot(独热编码),Onehot(独热编码)可以将类别变量转换为数字型变量(变得稀疏)如下图。
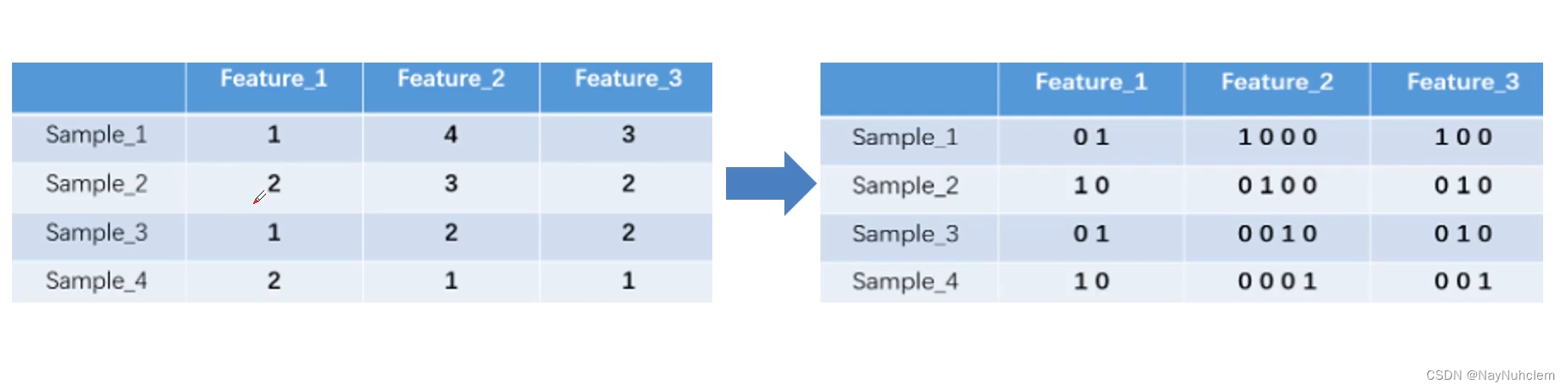

当词特别多时,那么编码维度非常大,计算量也会很大。一般我们会采用新的文本处理方法Word2vec和Stopwords,Word2vec把每一个词映射成一个二维向量,该向量就代表这个词。Stopwords:停用词是指搜索引擎已编程忽略的常用词(例如“the”,“a”,“an”,“in”)

3、Word2Vec
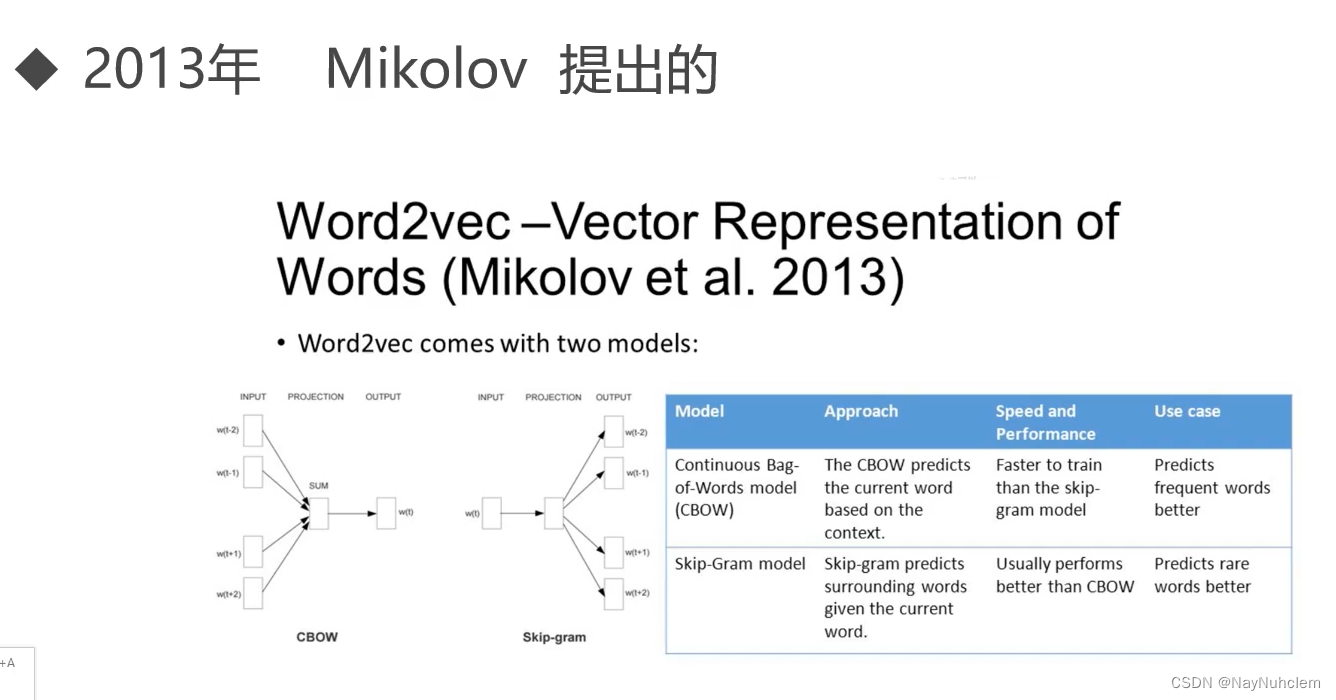
3.1word2vec模式下的两个模型:CBOW和SkipGram
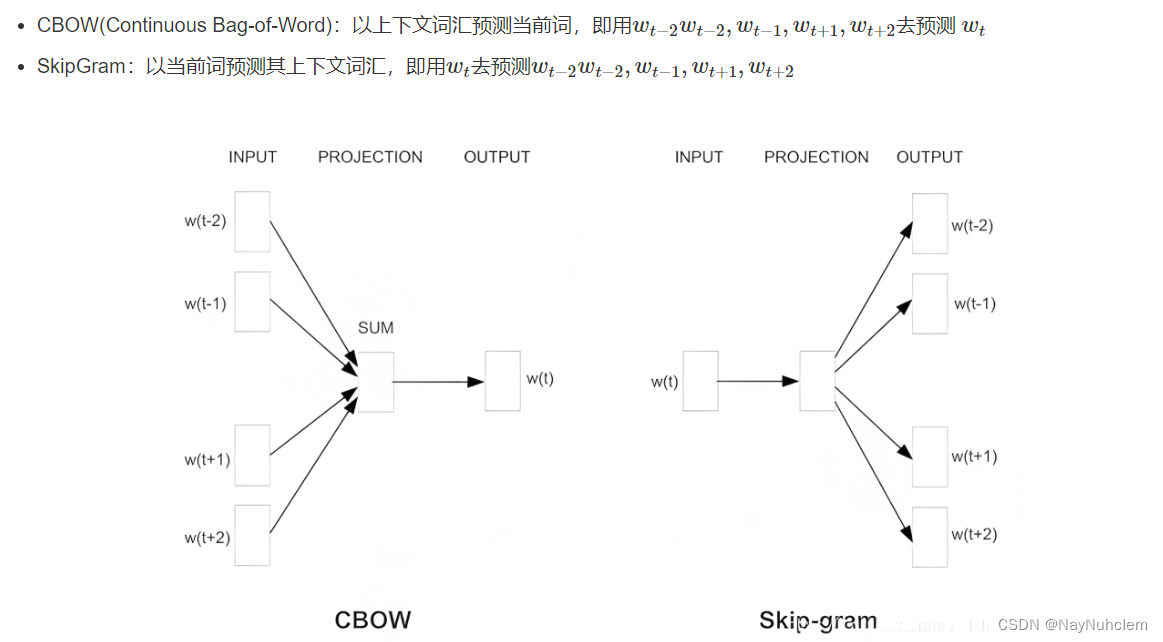

Word2Vec用神经网络把词转成向量的模型。
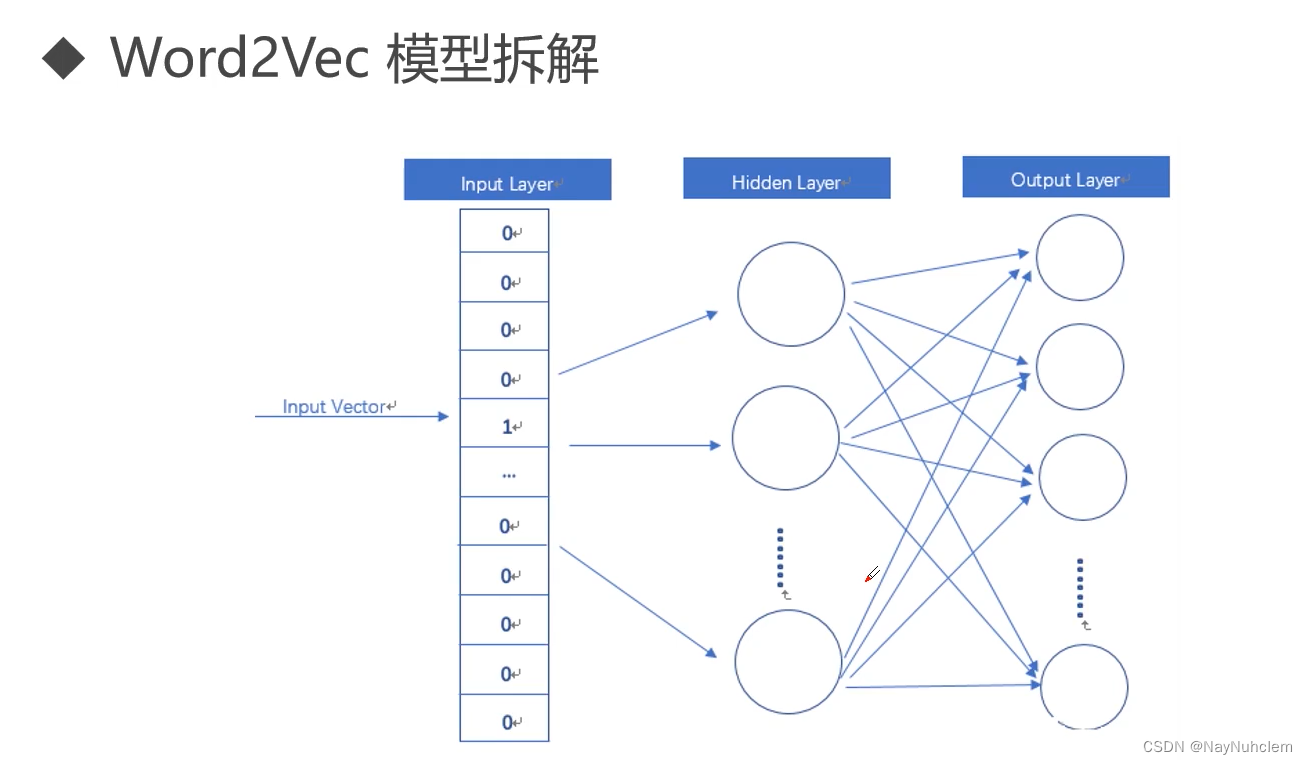
3.2word2vec模式分解
3.3word2vec发展

3.4word2vec的不足

3.5word2vec的改进
但是在平时中使用word2vec更多
4、CBOW和SkipGram


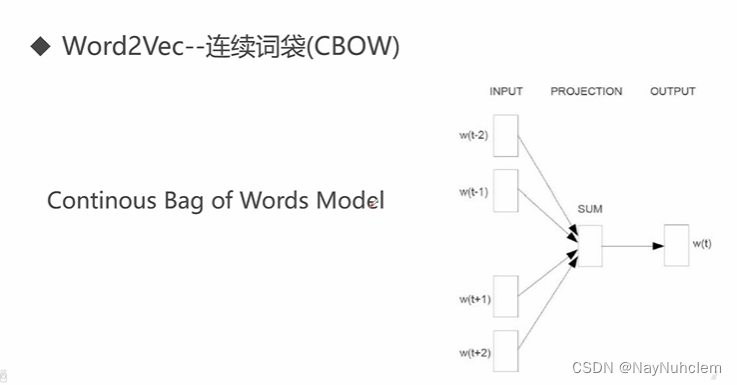

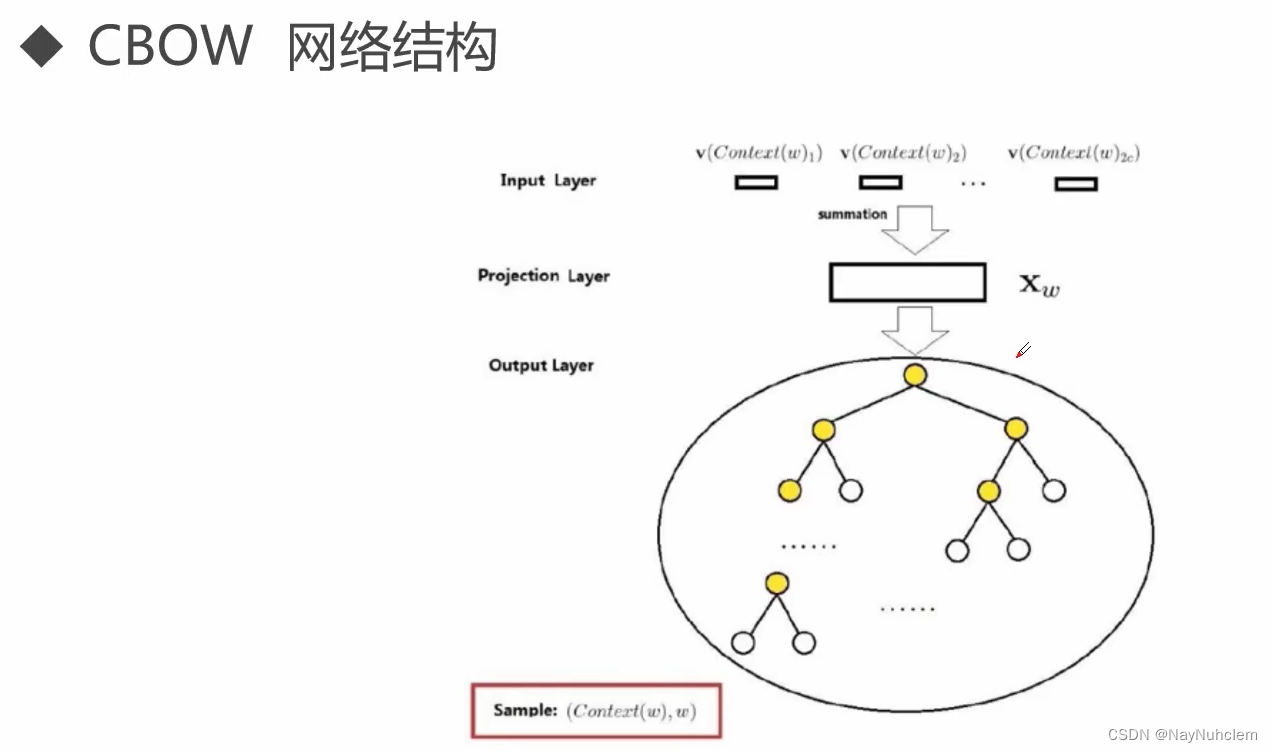
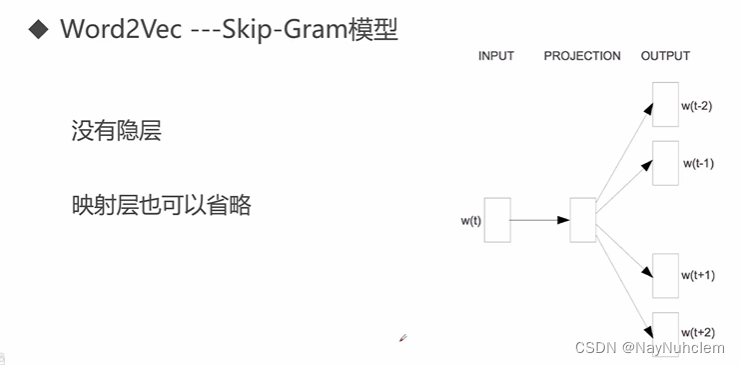
word2vec中两个重要的技术
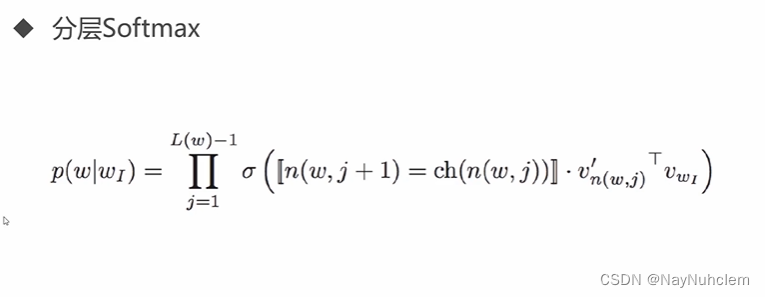
word2vec对每个词语计算出一个输出概率,然后进行归一,Softmax可以进行一个多分类。
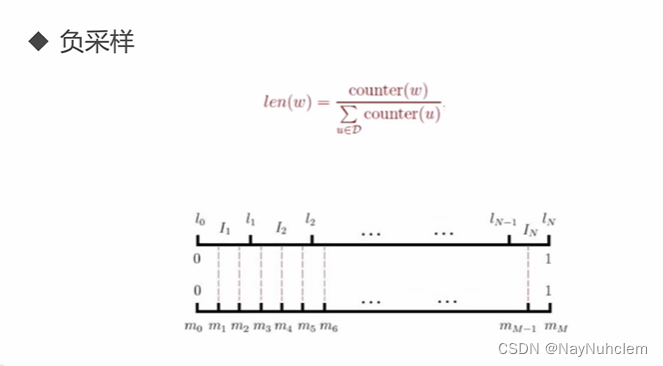
在计算过程中减少计算量,但是不影响训练模型的效果,通过负采样进行一个优化。

5、代码小练
Gensim是在做自然语言处理时较为经常用到的一个工具库,主要用来以无监督的方式从原始的非结构化文本当中来学习到文本隐藏层的主题向量表达。
主要包括TF-IDF,LSA,LDA,word2vec,doc2vec等多种模型。
# 导入库
import gzip
import gensim
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
#解压缩我们的数据
data_file="reviews_data.txt.gz"
with gzip.open ('reviews_data.txt.gz', 'rb') as f:
for i,line in enumerate (f):
print(line)
break
#把文件读入list
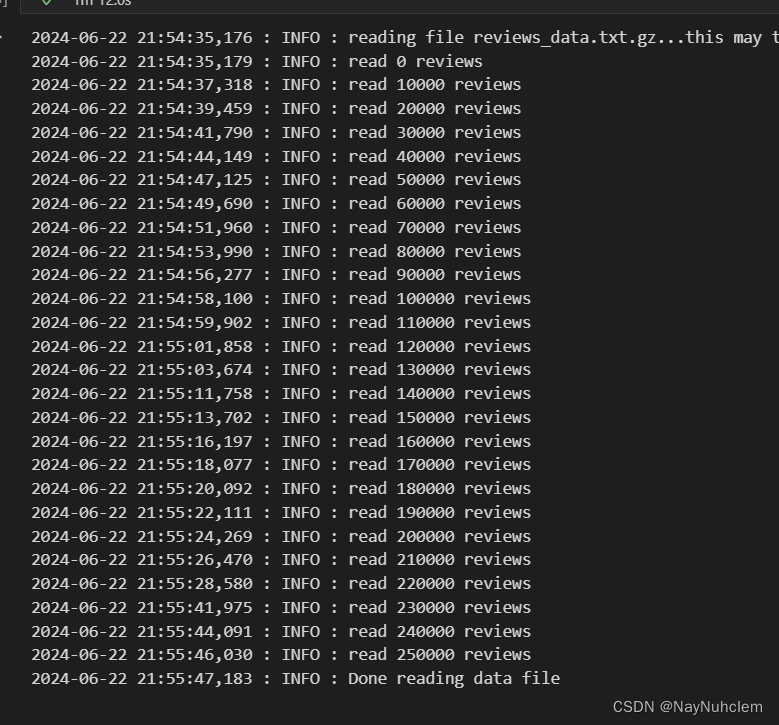
def read_input(input_file):
logging.info("reading file {0}...this may take a while".format(input_file))
with gzip.open (input_file, 'rb') as f:
for i, line in enumerate (f):
if (i%10000==0):#一万次输出一次日志
logging.info ("read {0} reviews".format (i))
# 用于将句子分割为单词列表,simple_preprocess自动过滤了单词长度小于2的词汇
yield gensim.utils.simple_preprocess (line)
#将生成器 read_input(data_file) 生成的每行单词列表转换为一个列表 documents
documents = list (read_input (data_file))
logging.info ("Done reading data file")
#训练一个model
#创建 Word2Vec 模型
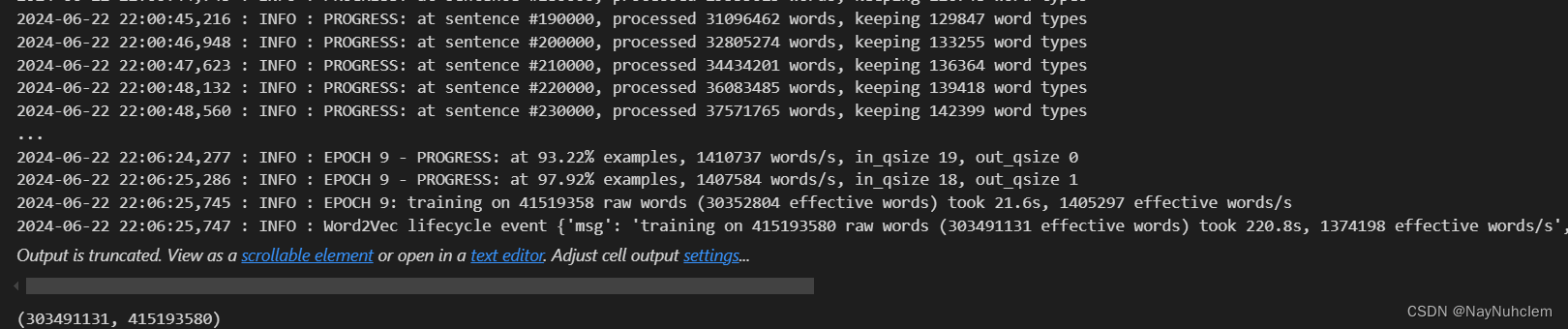
model = gensim.models.Word2Vec(documents, vector_size=150, window=10, min_count=2, workers=10)
#训练 Word2Vec 模型
model.train(documents,total_examples=len(documents),epochs=10)
-
创建 Word2Vec 模型
- gensim.models.Word2Vec:用于训练 Word2Vec 模型的类。
- documents:包含了多个文档(每个文档是一个单词列表)的列表。这是你之前从文件中读取并处理得到的数据。
- size=150:指定生成的词向量的维度为 150。
- window=10:指定了在训练过程中,当前词与预测词之间的最大距离为 10。
- min_count=2:忽略总频率低于此值的所有单词。
- workers=10:用于并行化训练的线程数(仅在安装了 Cython 后才有效)
-
训练 Word2Vec 模型
- train 方法用于训练模型。
- documents:训练数据,与之前创建模型时使用的相同。
- total_examples=len(documents):总的训练样本数,这里是文档的数量。
- epochs=10:迭代训练模型的次数,每个文档会被使用多次,以提高模型的准确性。
#验证结果查找和给定词汇最相似的词汇
w1 = "dirty"
model.wv.most_similar (positive=w1)

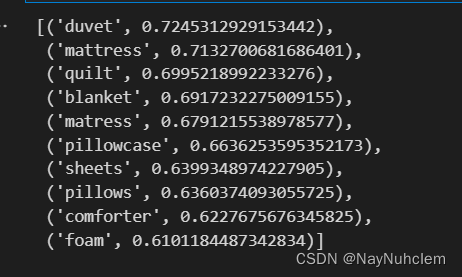
#找到和单词列表 w1 中的词汇相似,同时确保这些词汇不与列表 w2 中的词汇相似
w1 = ["bed",'sheet','pillow']
w2 = ['couch']
model.wv.most_similar (positive=w1,negative=w2,topn=10)
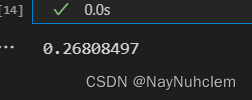
#两个不同单词之间的相似度,通常采用词向量的余弦相似度
model.wv.similarity(w1="dirty",w2="smelly")
# 找出在给定词汇列表中,哪一个词汇与其他词汇最不相关
model.wv.doesnt_match(["cat","dog","france"])

6、什么时候可以使用Word2Vec?
当你需要使用Word2Vec时,有许多应用场景可以考虑。如果你需要构建一个情感词汇表。通过在大量用户评论上训练Word2Vec模型,你可以实现这一目标。你不仅能获得情感的词汇表,而且对词汇表中的大多数单词都能进行建模。
除了原始的非结构化文本数据外,还可以将Word2Vec应用于更加结构化的数据。例如,如果你有一百万条StackOverflow问题和答案的标签,你可以找到与给定标签相关的其他标签,并推荐这些相关的标签以供探索。你可以将每组共现标签视为一个"句子",并在这些数据上训练一个Word2Vec模型。















 3076
3076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









