






目录
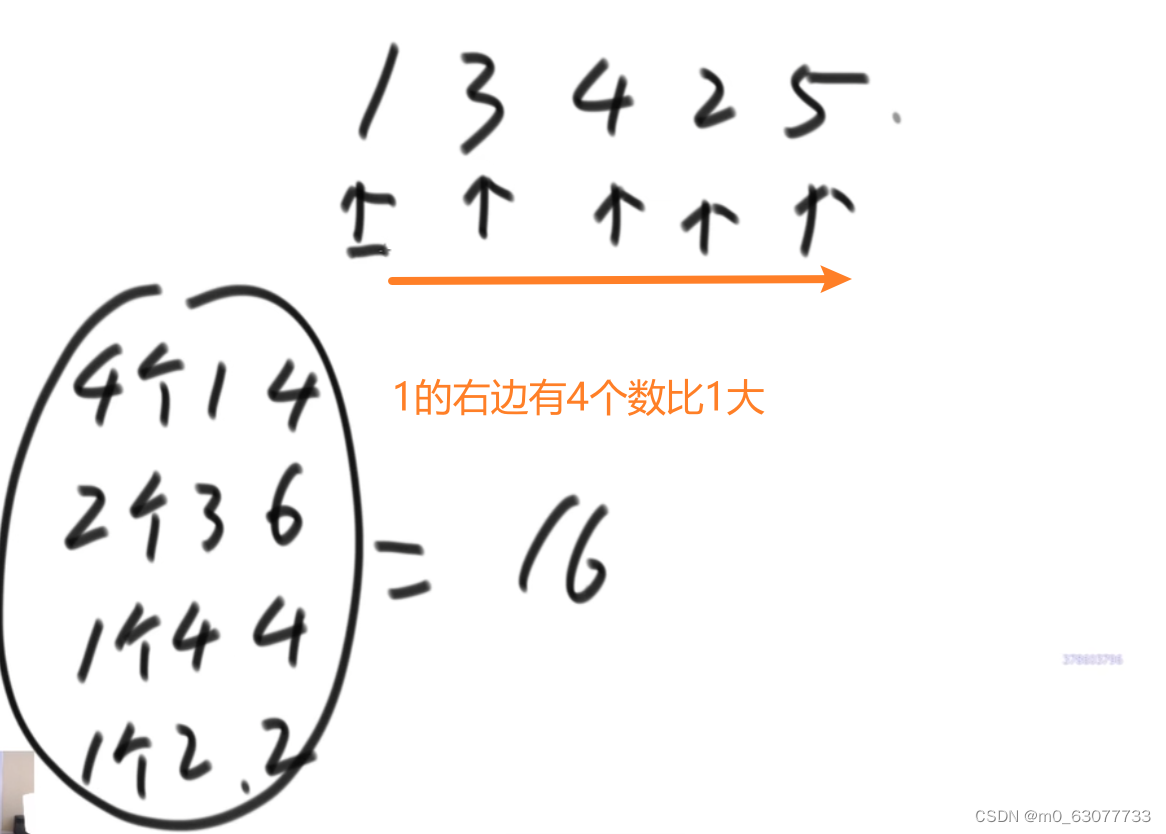
2.问题可以转换为,算一个数,右边有多少个数比他大:比1大有4个,比3大有2个…
1.0版本:选择最后一个数值作为num,然后将前面的值进行划分【上面问题一和递归的结合】
3.0版本【随机选择一个数来划分,那个极端好和极端坏的情况都是等概率事件,复杂度与概率求期望,得到期望复杂度为 O ( N log N ) O(N\log N)O(NlogN)。】
1.1 给定一组数组,创建一个堆,初始化heapsize=0,然后先从0~0有序,然后0~1有序,然后逐次将数值放入堆中形成大根堆
1.4 .根节点和最后一个节点交换完后,将最后一个节点(最大值)断开
一、归并排序
1.归并排序的思想
归并排序的主要思想是分治法。主要过程是: 将n个元素从中间切开,分成两部分。(左边可能比右边多1个数) 将步骤1分成的两部分,再分别进行递归分解。直到所有部分的元素个数都为1。 从最底层开始逐步合并两个排好序的数列
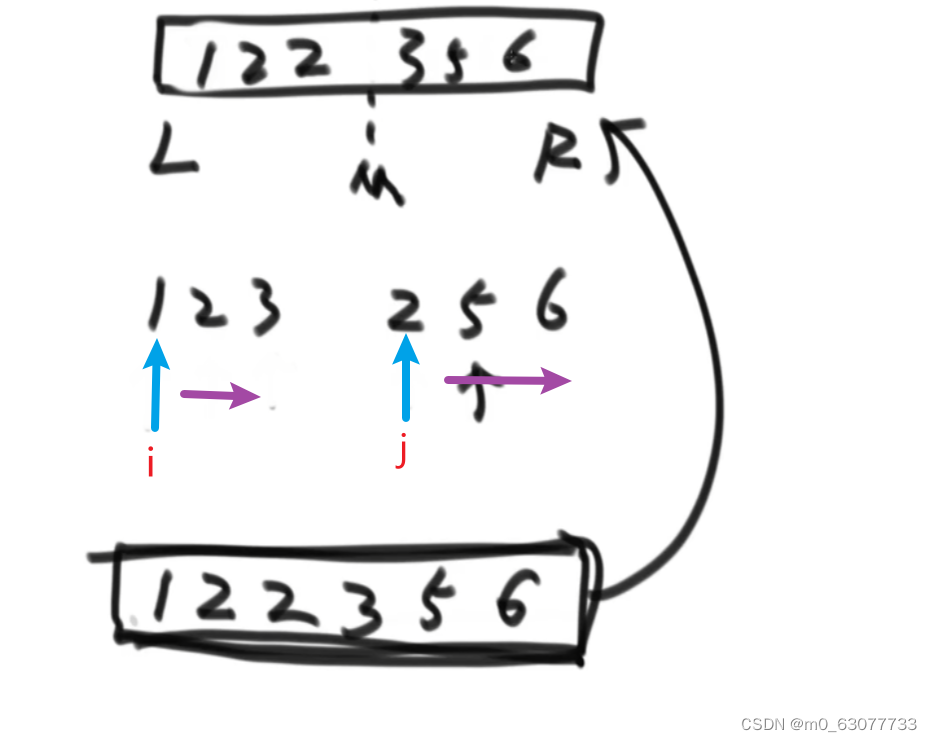
2.代码实现
public static void mergeSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
mergeSort(arr, 0, arr.length - 1);
}
public static void mergeSort(int[] arr, int l, int r) {
if (l == r) {
return;
}
int mid = l + ((r - l) >> 1);
mergeSort(arr, l, mid);
mergeSort(arr, mid + 1, r);
merge(arr, l, mid, r);
}
// merge是一个普通的过程,不是递归
public static void merge(int[] arr, int l, int m, int r) {
// 辅助空间
// 一共有:r - l + 1个数
int[] help = new int[r - l + 1];
// i是用于遍历help数组的
int i = 0;
int p1 = l;
int p2 = m + 1;
while (p1 <= m && p2 <= r) {//一直往help里面黏贴,同时p1或p2指针一直右移直至越界
help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
// p1 <= m和 p2 <= r 只会中一个
while (p1 <= m) {//把没越界的指针后面剩余的数组黏贴到help里面
help[i++] = arr[p1++];
}
while (p2 <= r) {//把没越界的指针后面剩余的数组黏贴到help里面
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++) {//把排好序的help数组黏贴到原始数组的位置
arr[l + i] = help[i];
}
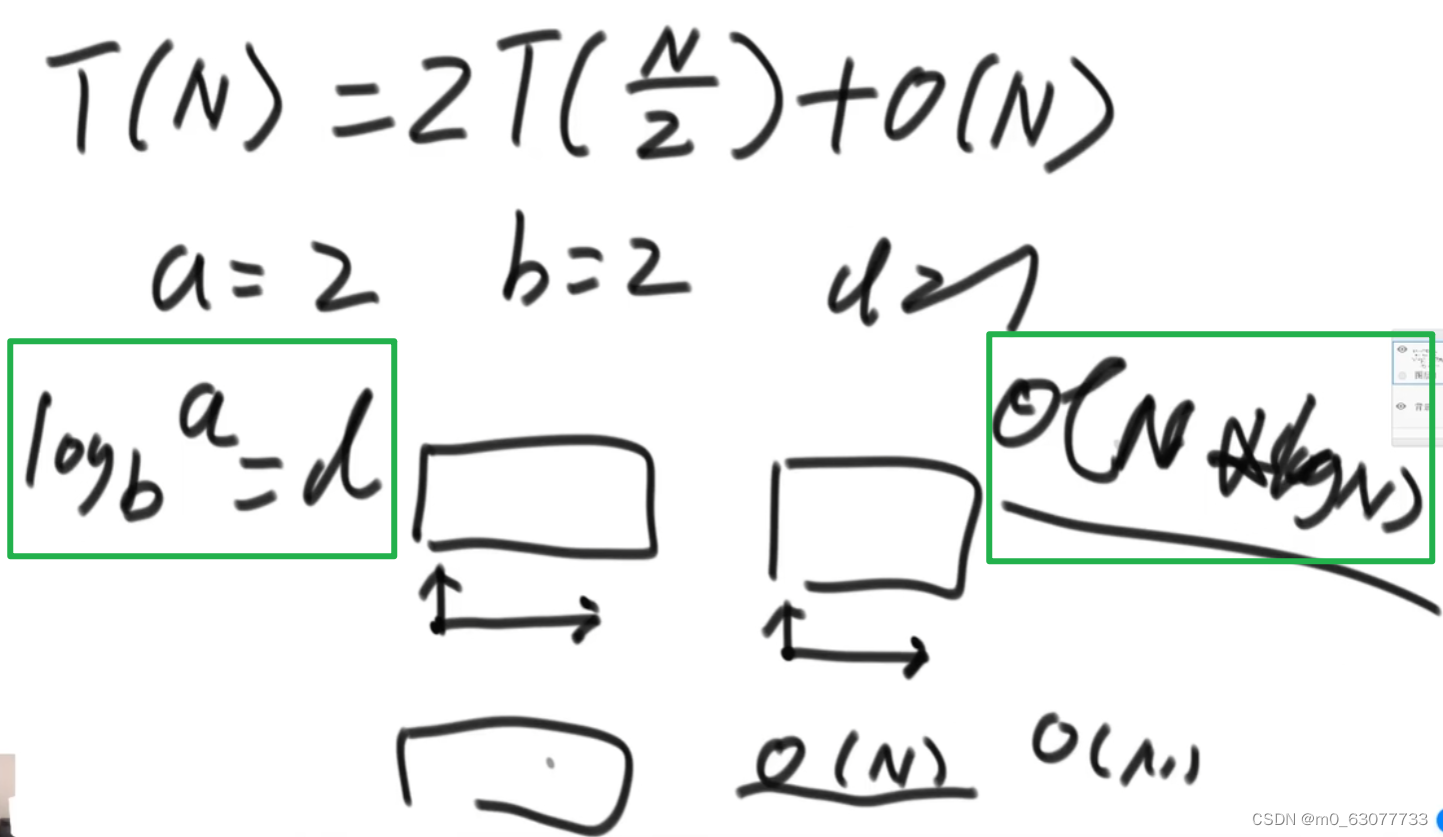
}3.时间复杂度计算

4.归并排序的扩展 :小和问题

1.直接遍历的复杂度:
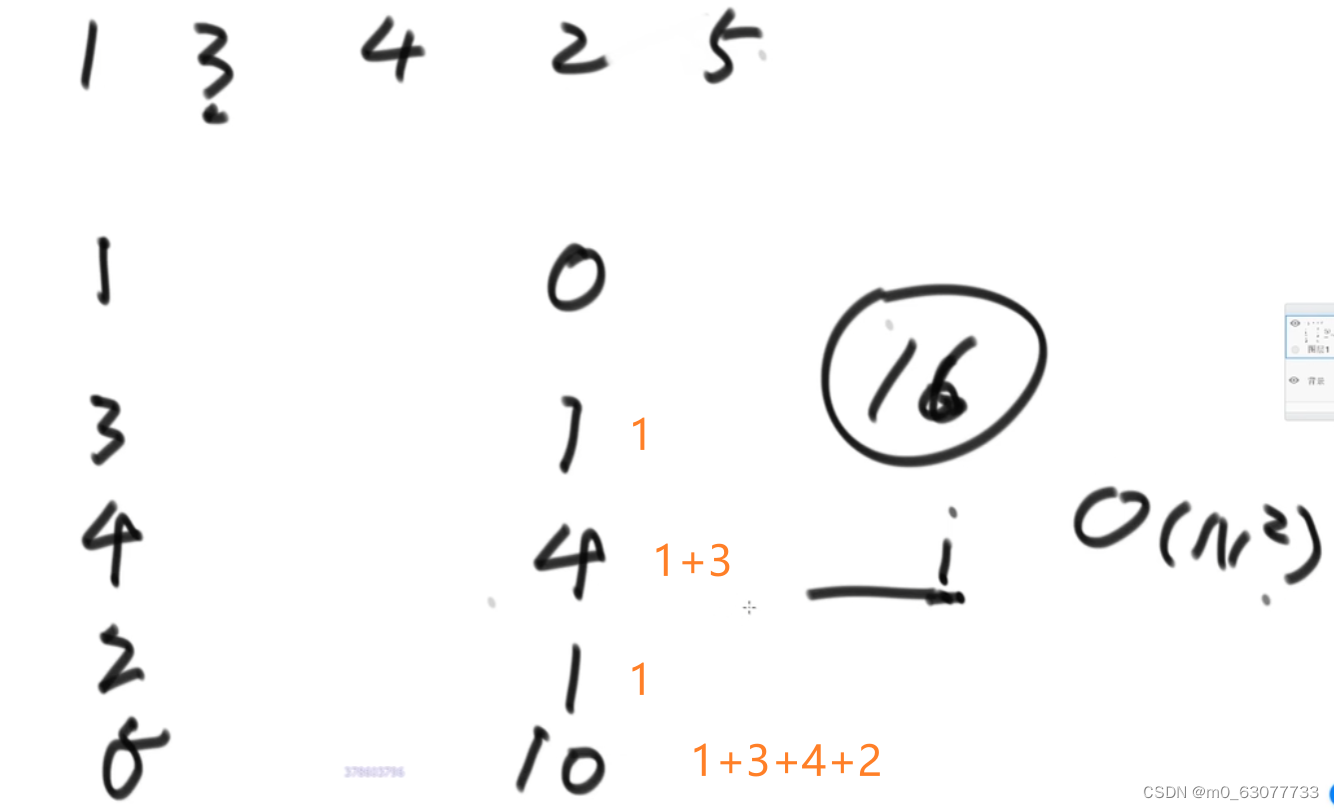
2.问题可以转换为,算一个数,右边有多少个数比他大:比1大有4个,比3大有2个…
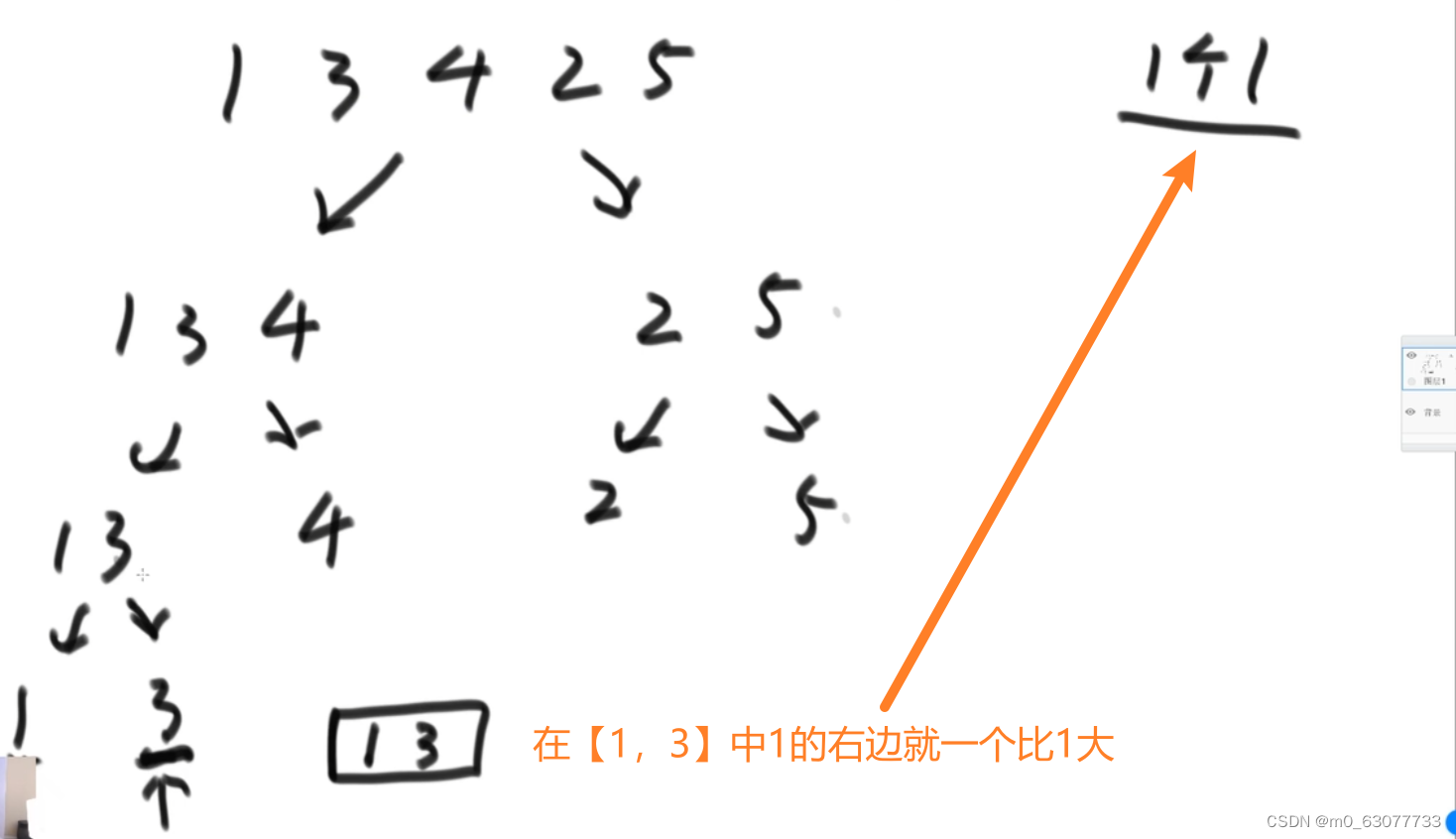
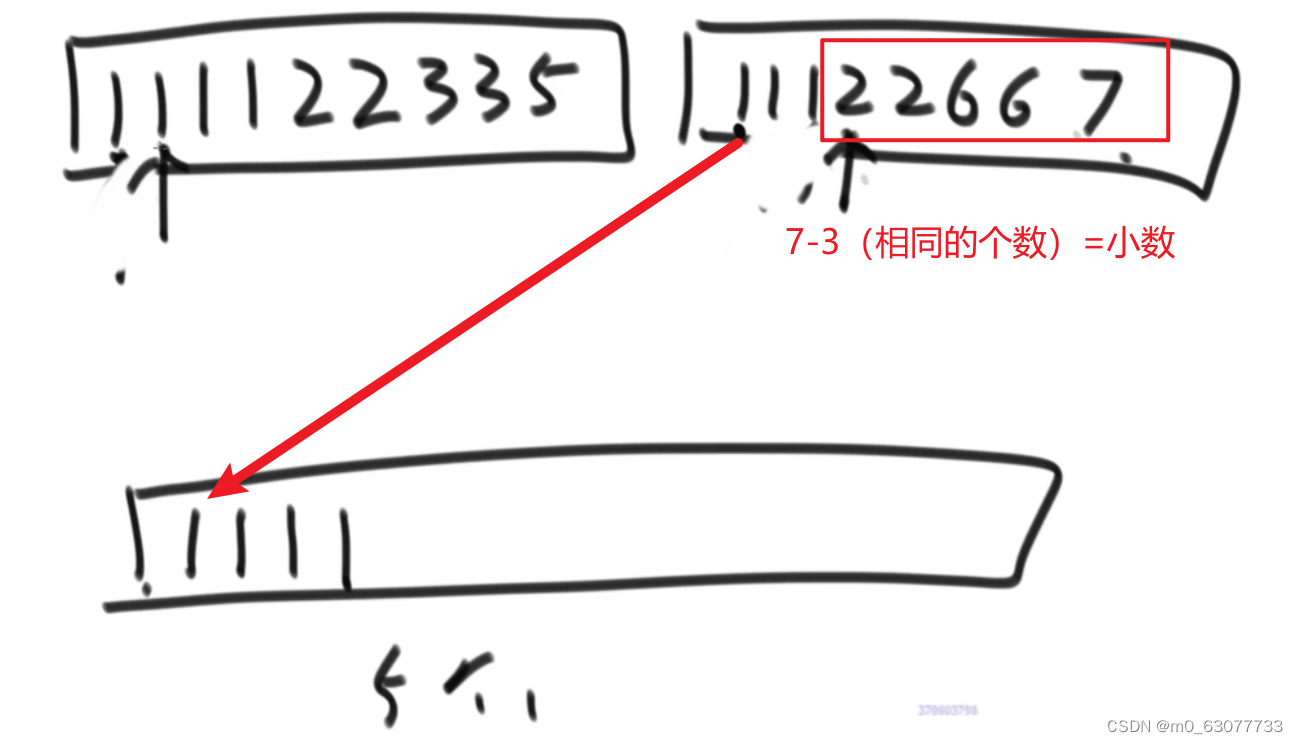
注意点:当左右数组中有相同的数值,则应该向拷贝右组
因为要先知道右数组中有多少个跟左数组中的数值相同的个数,然后将右组中全部的个数-相同的个数,得出左组数值的小项
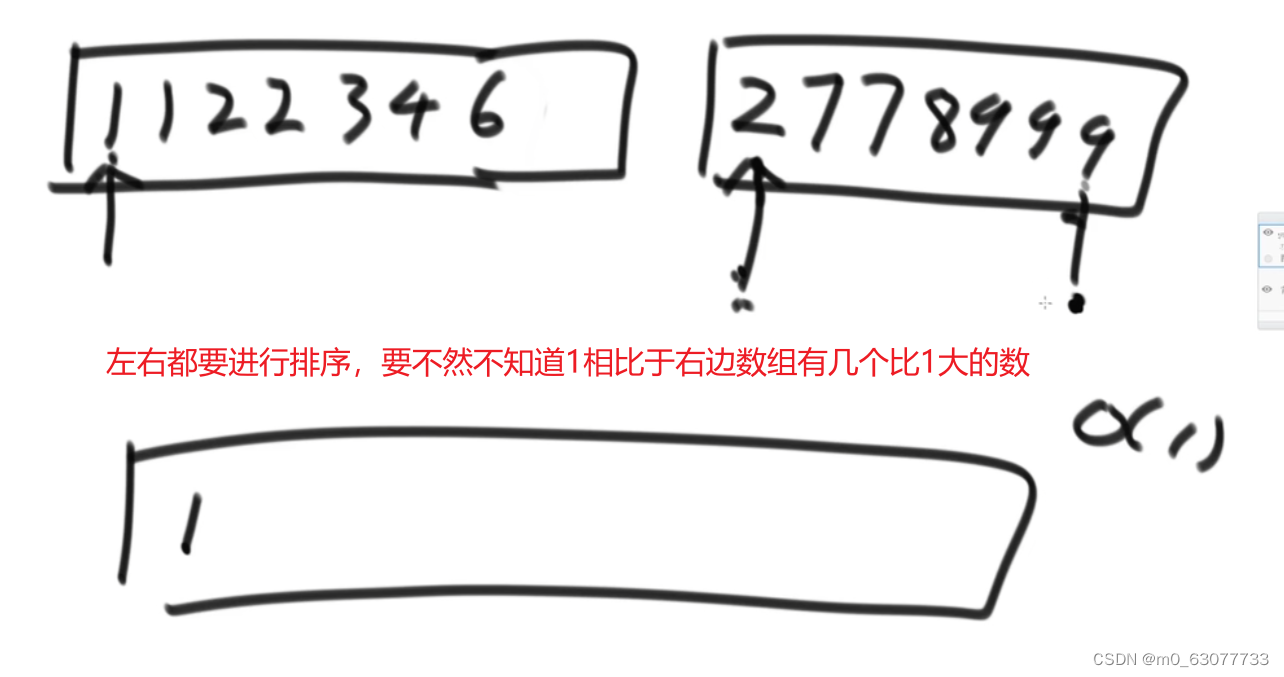
注意点:左右两组中的数值必须都是有序的
两个数组求小和,左边的第一个数比右边的第一个数小,可以知道右边数组的其他数都比左边的大,要是没排序就是乱的,右边数组后面的数就不一定比它大了
同一组中不会产生小值
public static int smallSum(int[] arr) {
if (arr == null || arr.length < 2) {
return 0;
}
return mergeSort(arr, 0, arr.length - 1);
}
public static int mergeSort(int[] arr, int l, int r) {
if (l == r) {
return 0;
}
int mid = l + ((r - l) >> 1);
return mergeSort(arr, l, mid) //左侧排序求小和
+ mergeSort(arr, mid + 1, r) //右侧侧排序求小和
+ merge(arr, l, mid, r);//2侧排序求小和
}
public static int merge(int[] arr, int l, int m, int r) {
int[] help = new int[r - l + 1];
int i = 0;
int p1 = l;
int p2 = m + 1;
int res = 0;
while (p1 <= m && p2 <= r) {
res += arr[p1] < arr[p2] ? (r - p2 + 1) * arr[p1] : 0;//记录右边的数组有几个数比左边当前数要大
help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];//一直往help里面黏贴,同时p1或p2指针一直右移直至越界,将2个数组合并重排
}
while (p1 <= m) {//把没越界的指针后面剩余的数组黏贴到help里面
help[i++] = arr[p1++];
}
while (p2 <= r) {//把没越界的指针后面剩余的数组黏贴到help里面
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++) {//把排好序的help数组黏贴到原始数组的位置
arr[l + i] = help[i];
}
return res;
}5.归并排序的扩展 :逆序对问题
在一个数组中,左边的数如果比右边的数大,则折两个数构成一个逆序对,请打印所有逆序对。
示例:对于0来说,30,20,40,50都是逆序对。
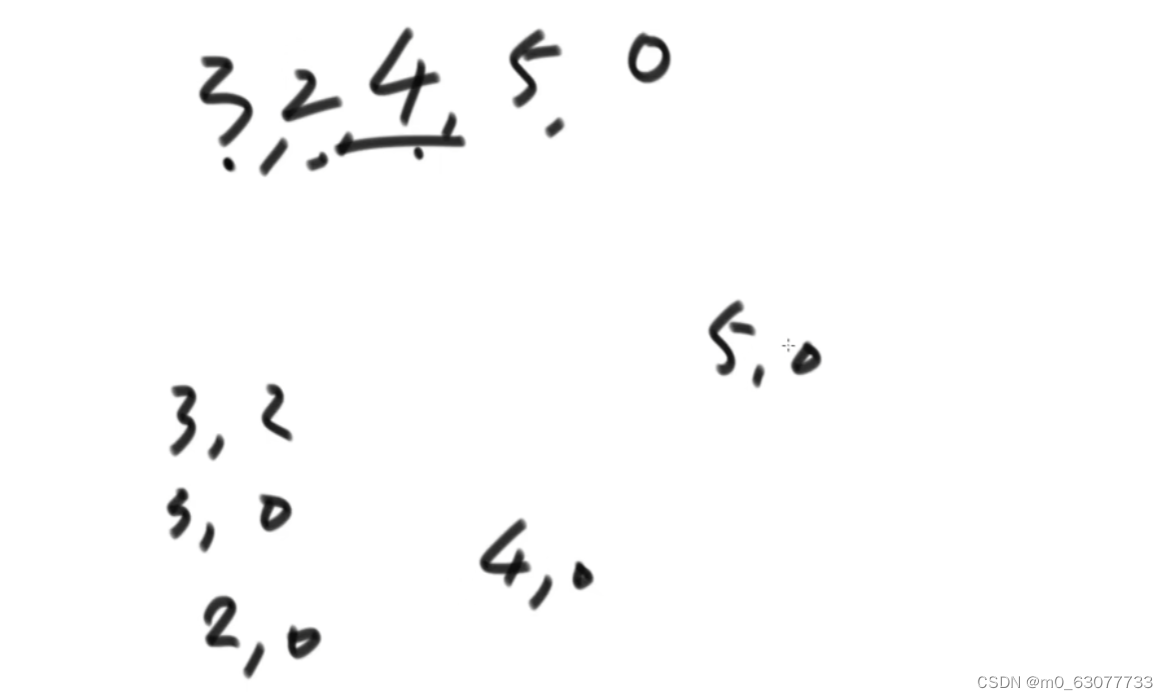
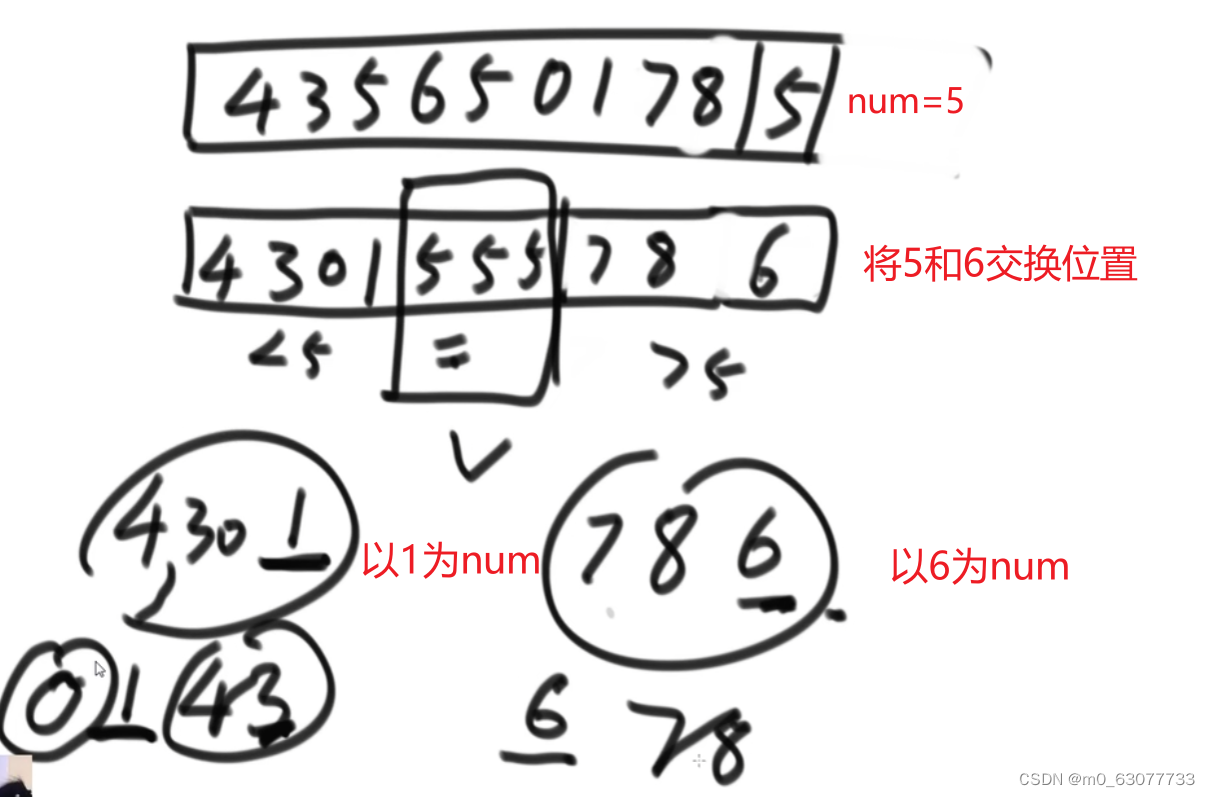
二、快速排序的引入---荷兰国旗问题【进行严格的排序】
1.问题一:

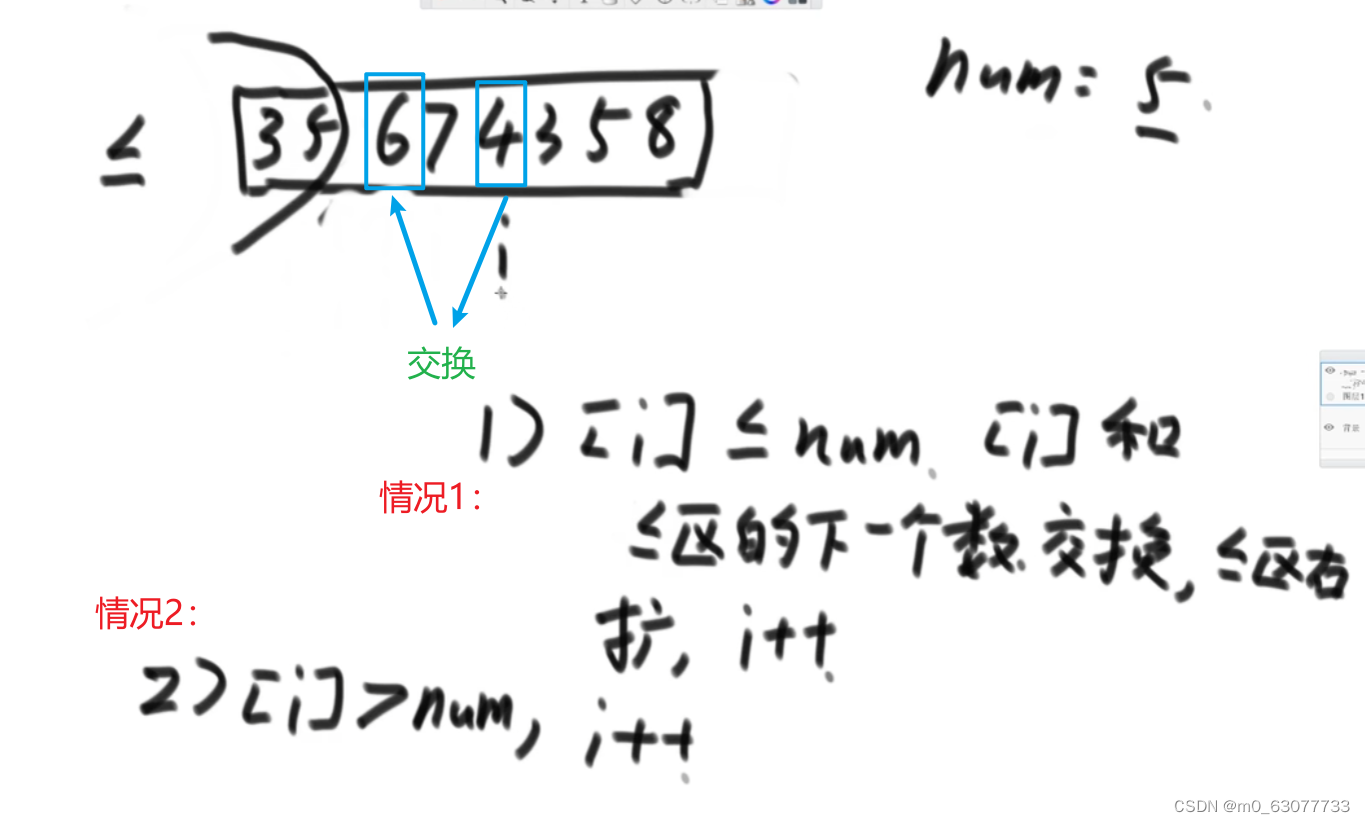
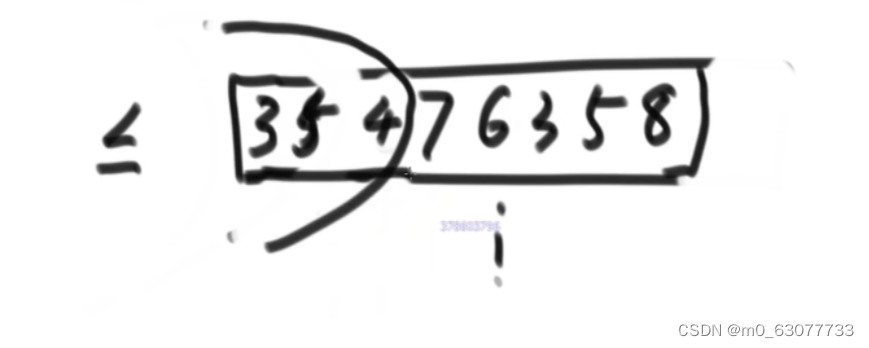
小于区域不断往右扩展,遇到比num大的数,就与未比较的区域的数交换,把大于num的数扔到右边,直到小于区域与右边的大于区域相遇。
2.问题二:

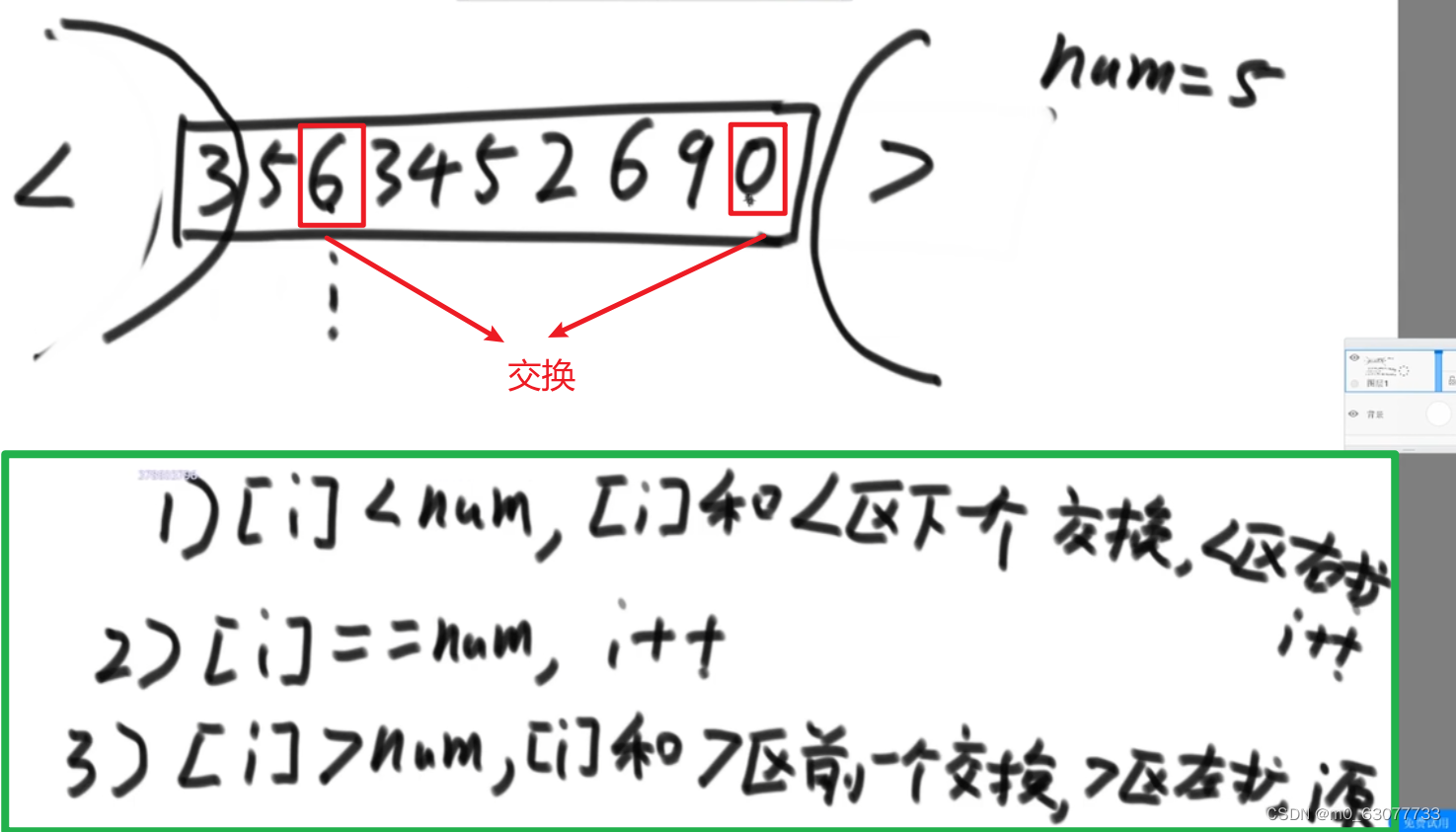
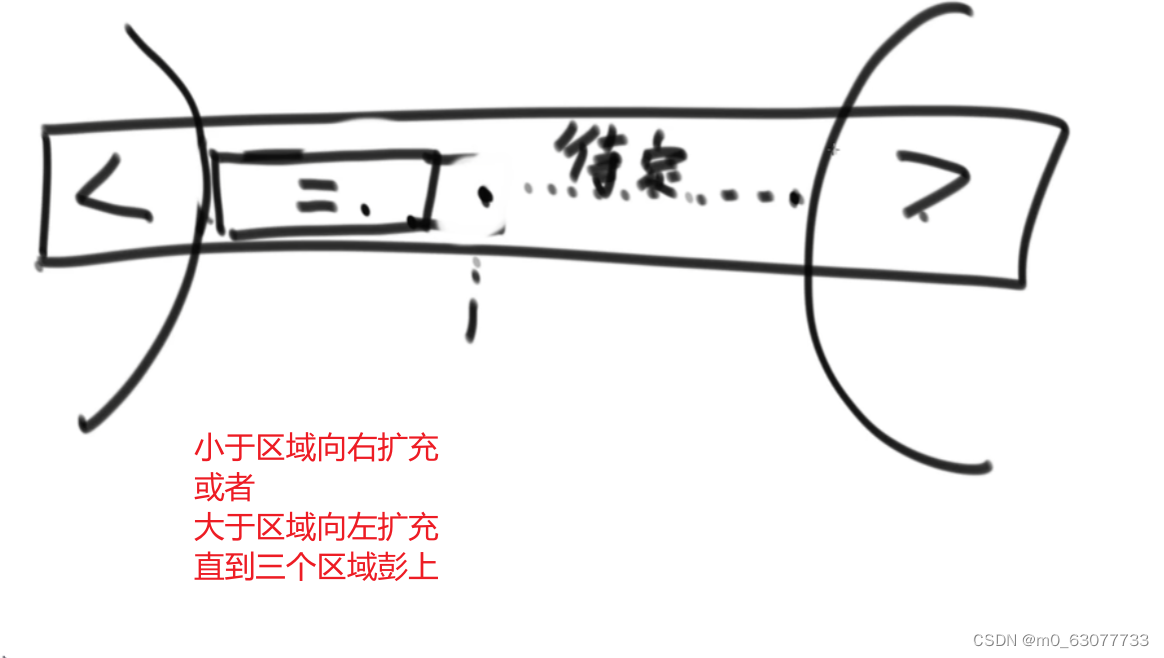
三、快速排序
1.0版本:选择最后一个数值作为num,然后将前面的值进行划分【上面问题一和递归的结合】
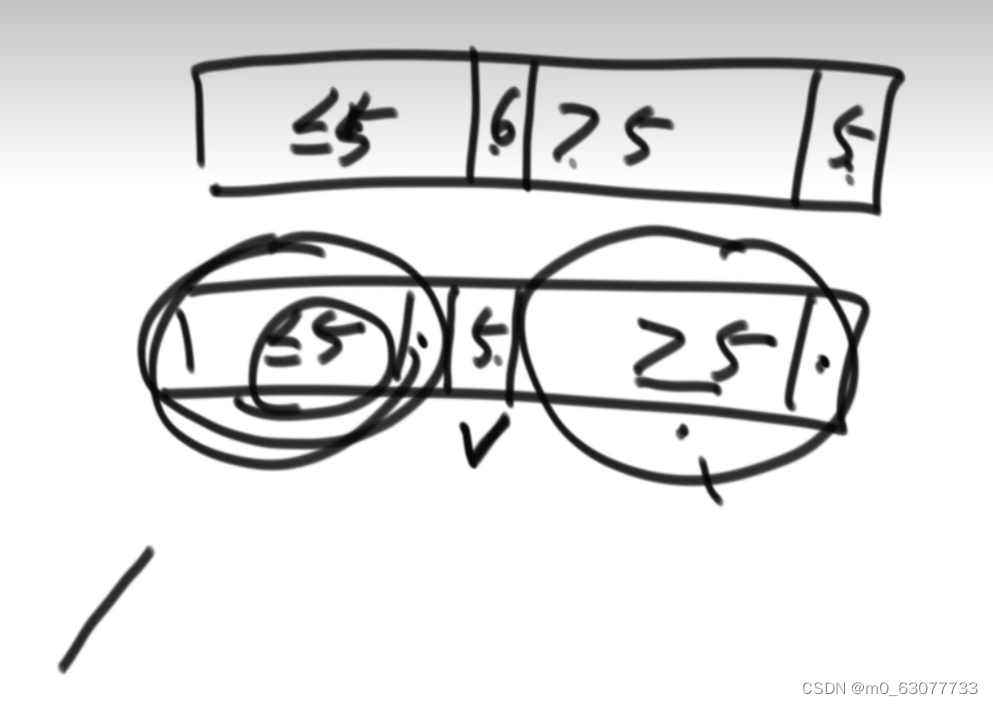
2.0版本【上面问题二(荷兰国旗问题)和递归的结合】
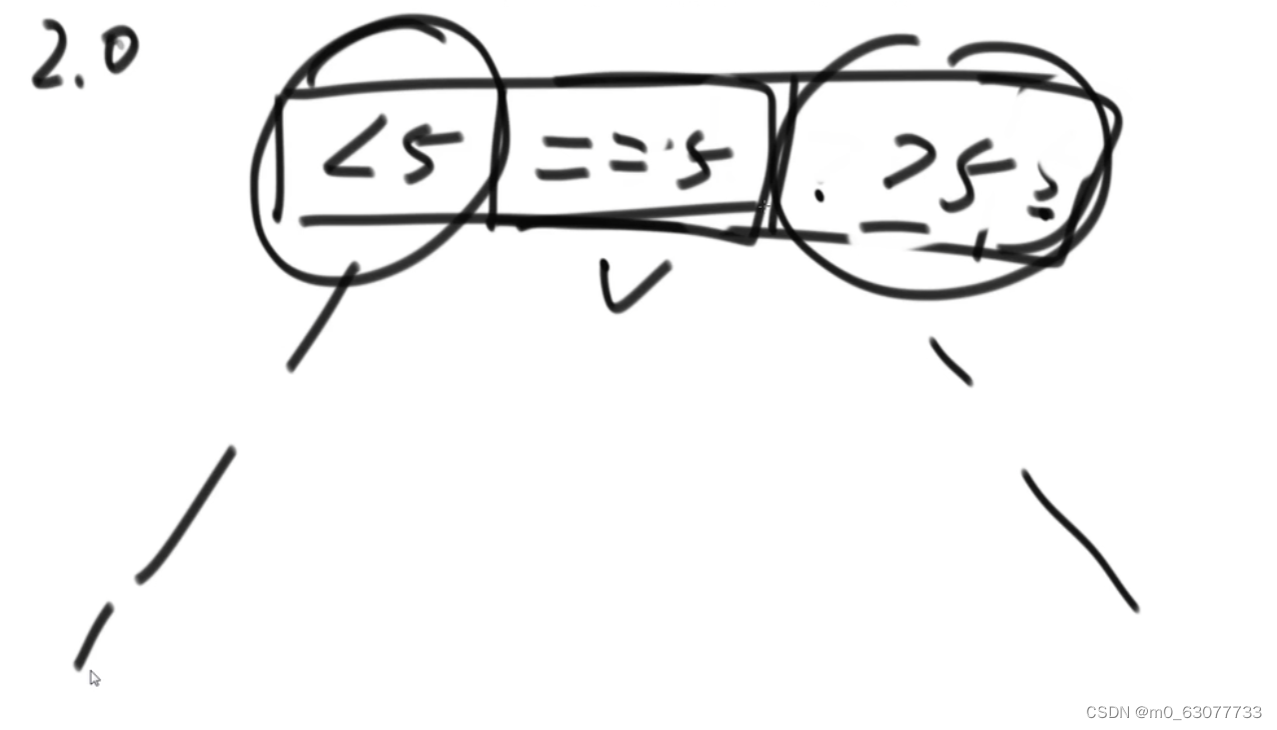
1.0,2.0版本,都有可能遇到划分的极端情况,左边区域很大,右边很小,复杂度就为 O ( N 2 ) O(N^2)O(N 2 )。
3.0版本【随机选择一个数来划分,那个极端好和极端坏的情况都是等概率事件,复杂度与概率求期望,得到期望复杂度为 O ( N log N ) O(N\log N)O(NlogN)。】
随机取出一个数值,放在最后。以这个数为num

四、堆排序前序:二叉树
不完全二叉树示例:
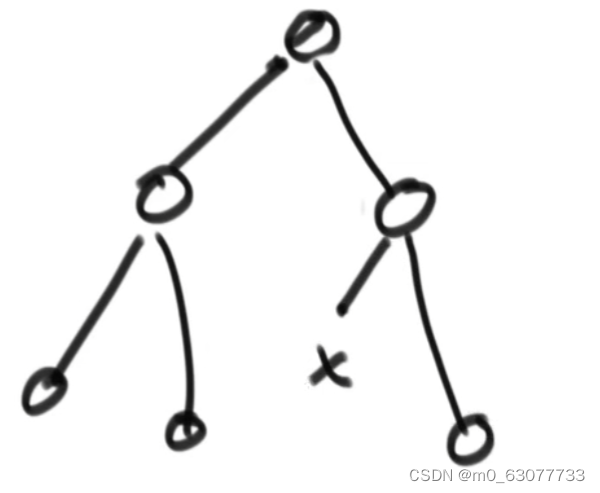
二叉树结构:
要求从0出发
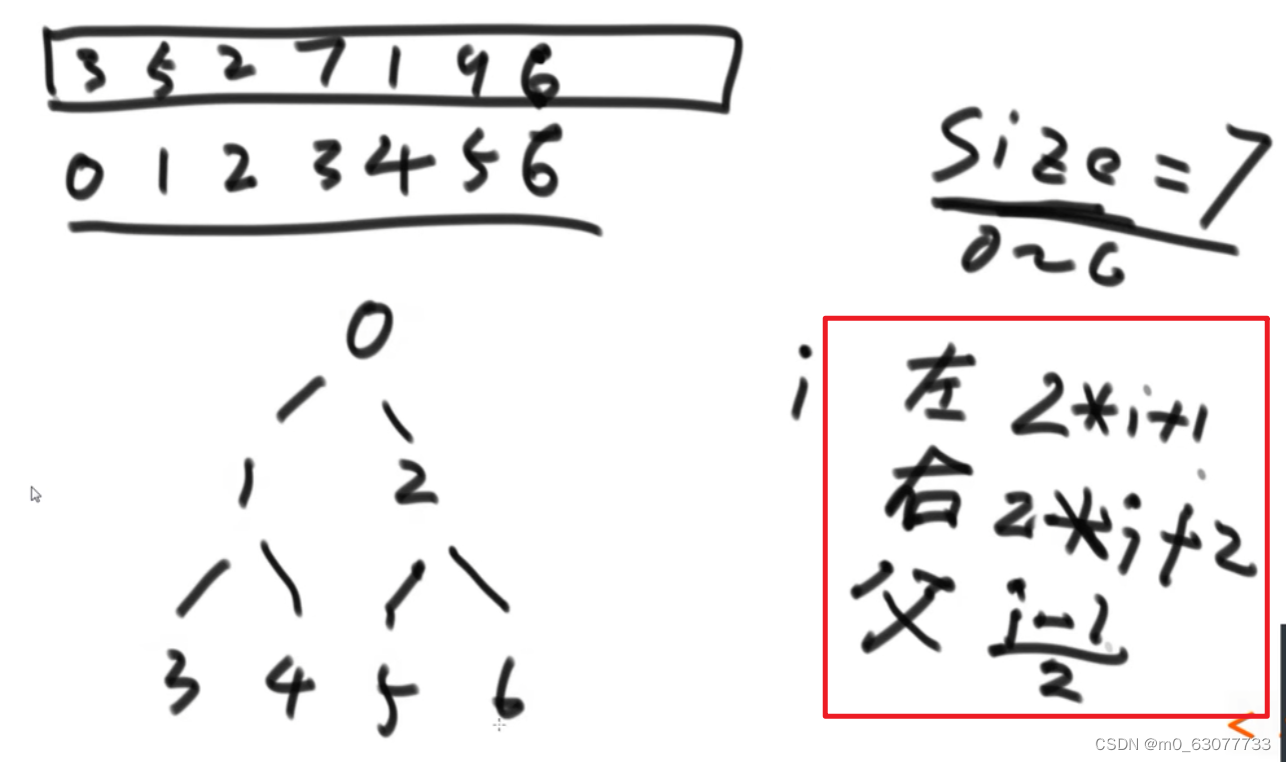
大根堆:父节点的数比子节点的数要大

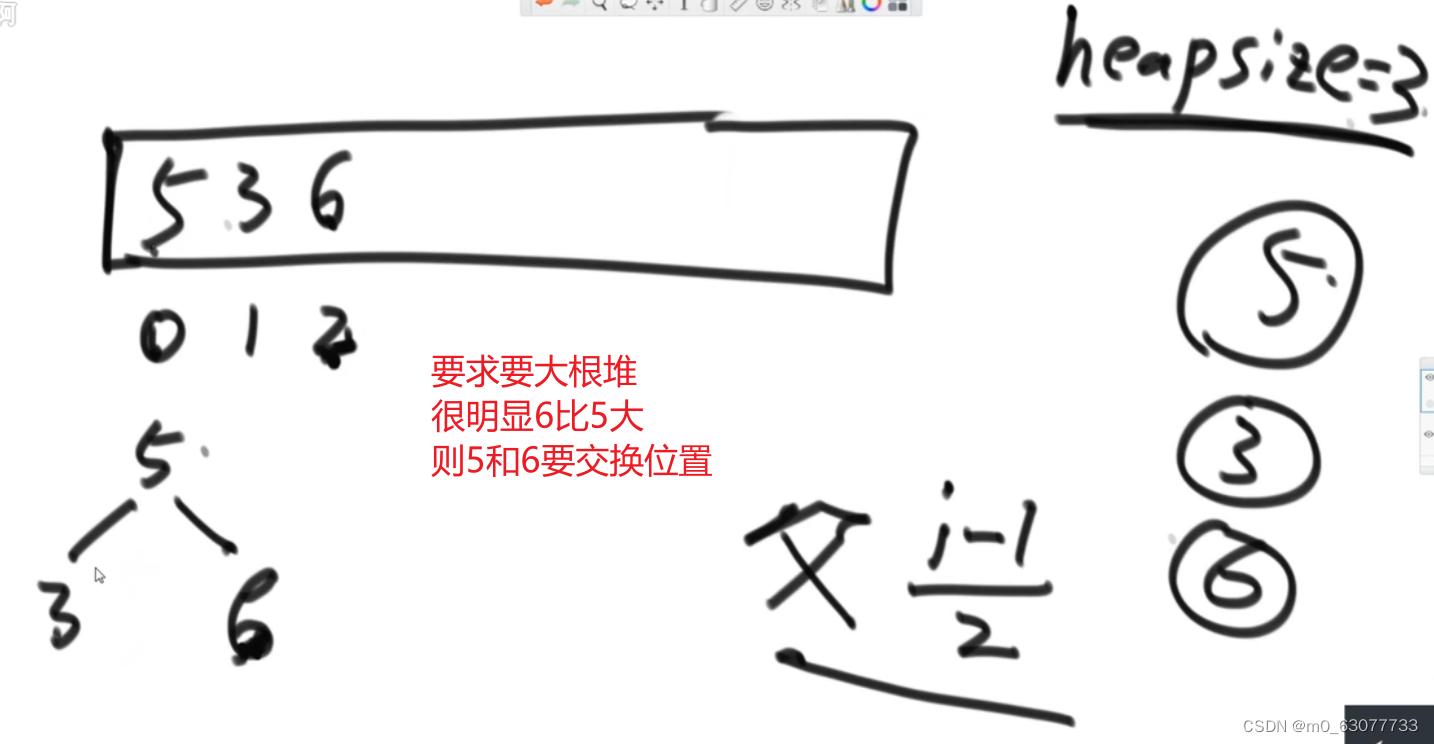
如果新值比父大,则向上窜
把新的数插入到堆中 :heapInsert
public static void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {//当前节点数值大于父节点位置
//(index - 1) /2:父亲的位置
//0位置也符合
swap(arr, index, (index - 1) /2);
index = (index - 1)/2 ;
}
}
时间复杂度:O(logn)
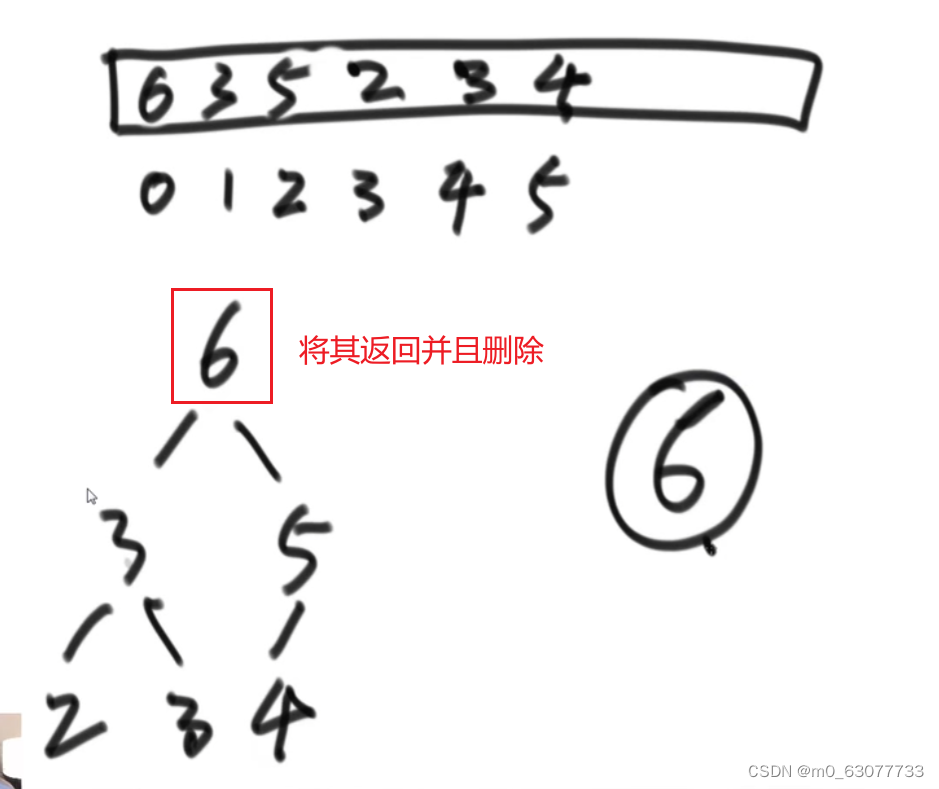
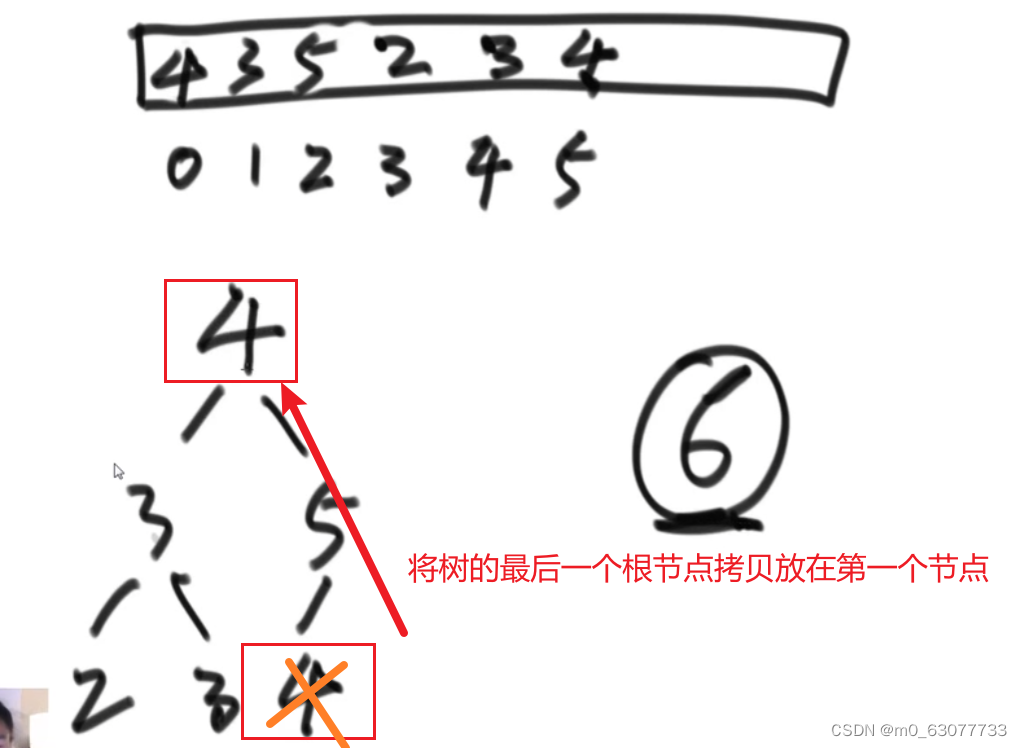
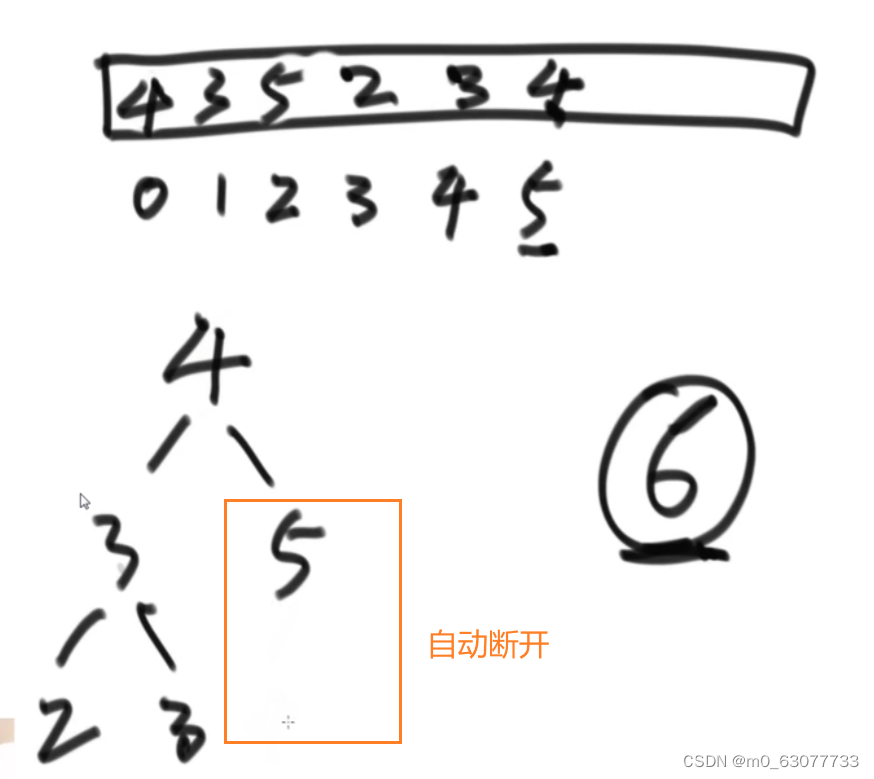
要删除最大的那个数值,然后找出剩余的最大值
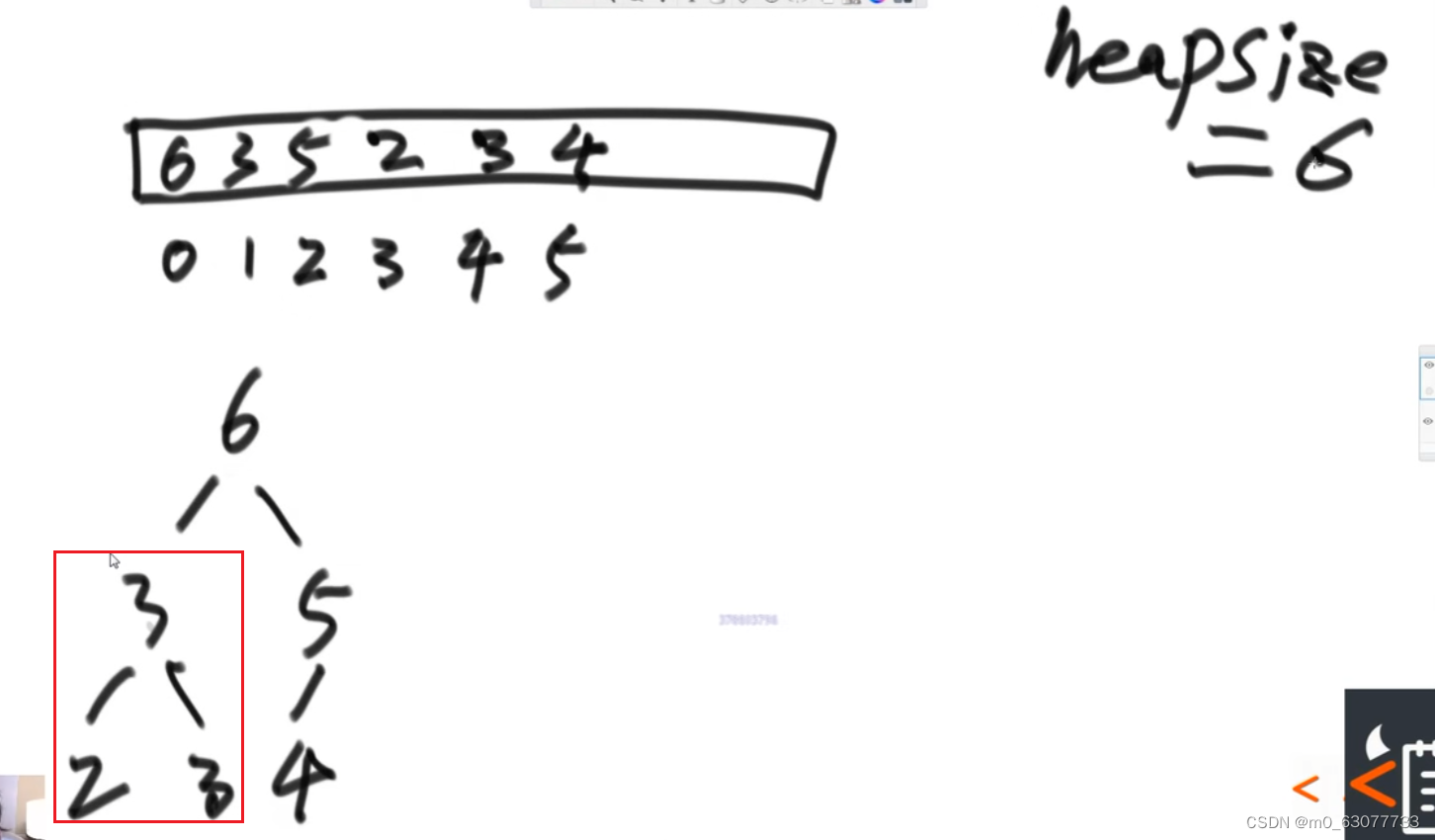
过程
先将树中的最后一个数值提到根节点位置,最大数字于heapsize最后一个元素交换,heapsize减一,然后第一个数做heapify的下移(与左右两个孩子进行比较)操作,如此反复,就能将全部数字排序
代码
//某数a在index位置,将其往下移动
public static void heapify(int[] arr, int index, int heapSize) {//size为数组长度
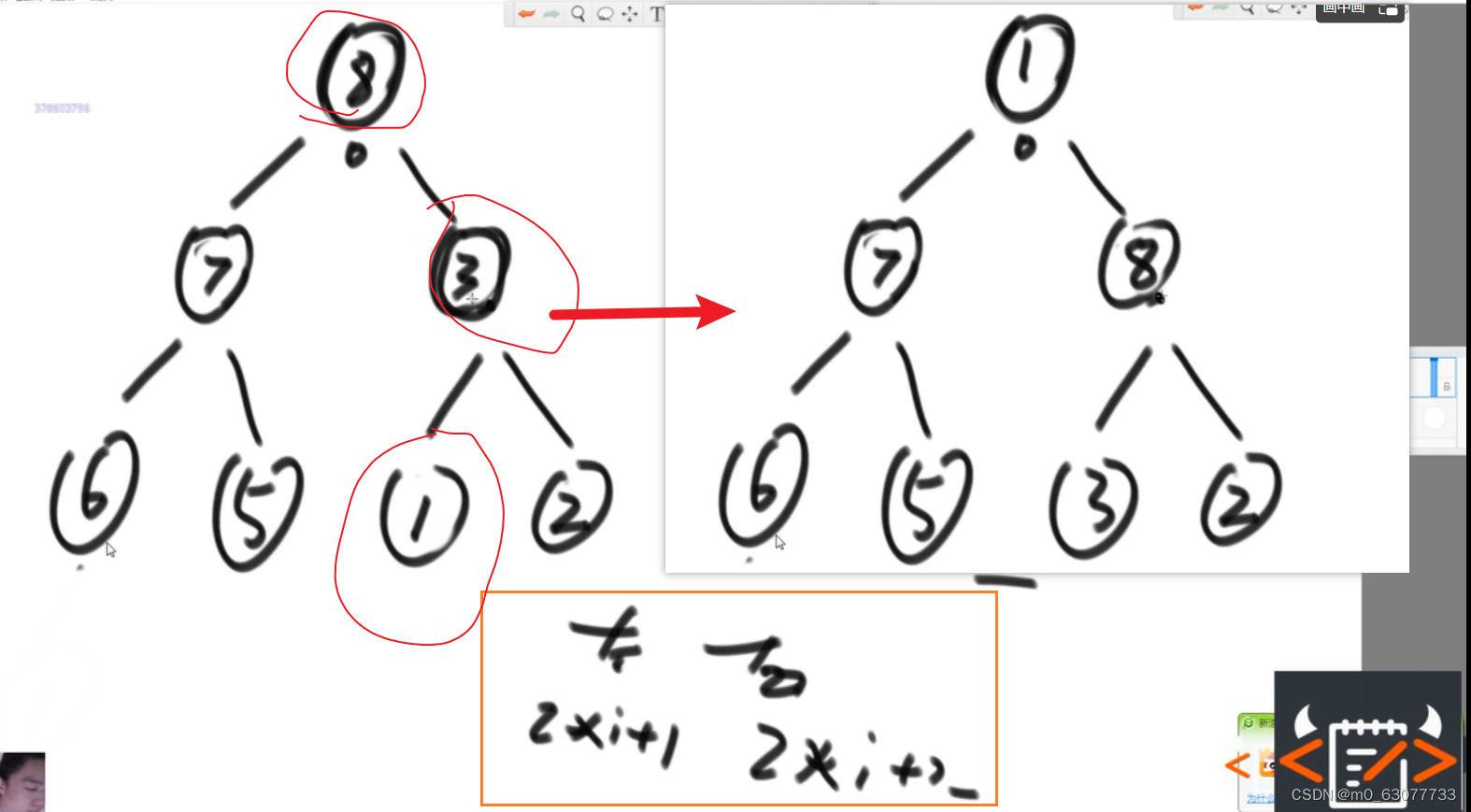
//查找左子树的位置公式:i*2+1
int left = index * 2 + 1;//左孩子位置
//不仅判断left是否越界并且判断是否有右孩子
while (left < heapSize) {//判断孩子是否存在
//只有当右孩子存在且大于左孩子时,才取右孩子作为最大值;
//其余情况选左孩子,包括
// 1.右孩子不存在
// 2.右孩子存在但没左孩子大
//largest记录最大值的位置
//arr[left + 1]:右孩子 arr[left ]:左孩子
int largest = left + 1 < size && arr[left + 1] > arr[left] ? left + 1 : left;
//比较父节点和大孩子之间谁大,记录下大的值的位置
largest = arr[largest] > arr[index] ? largest : index;
//如果父节点比较大,堆结构排好,退出,接着下一次查找
if (largest == index) {
break;
}
//孩子比较大,交换父和孩子的位置
swap(arr, largest, index);
//记录某数a的新位置
//此时index应该指向原来largest位置上
index = largest;
//记录处于新位置的某数a的左孩子
left = index * 2 + 1;
}
}
时间复杂度

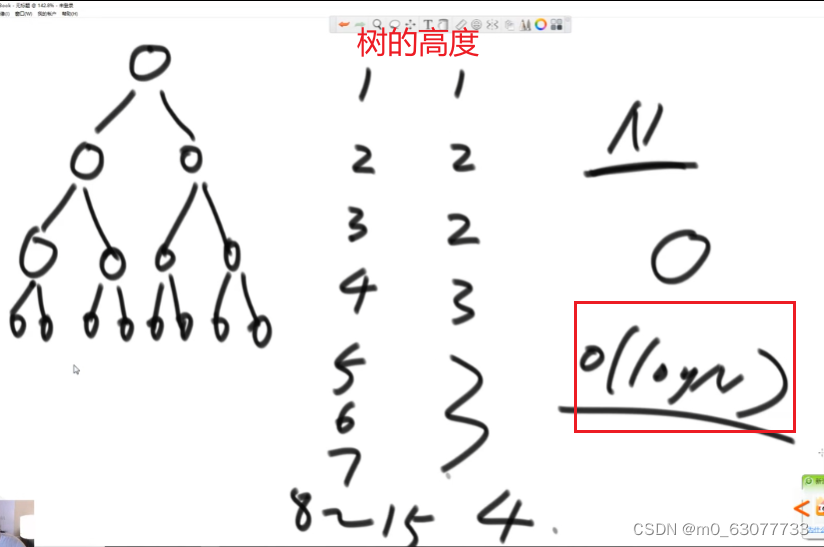
新增一个数,或删除最大值,调整的复杂度都是 O ( log N ) O(\log N)O(logN)。
五、堆排序

1.思路
1.将数组重构成大根堆
2.将数组的
队头元素与队尾元素交换位置3.对去除了队尾元素的数组进行重构,再次重构成大根堆
1.1 给定一组数组,创建一个堆,初始化heapsize=0,然后先从0~0有序,然后0~1有序,然后逐次将数值放入堆中形成大根堆
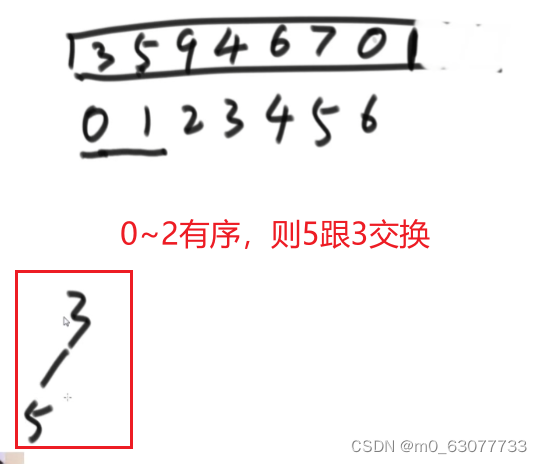
1. 2.将排成大根堆的第一个数值跟最后一个数值进行交换
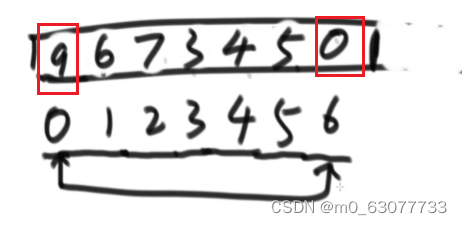
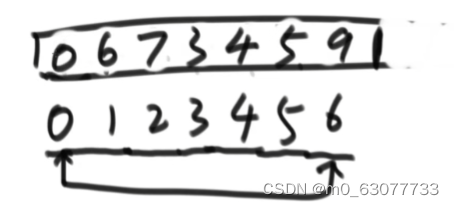
1.3 将heapsize--,将最后这个值跟数组断开联系


1.4 .根节点和最后一个节点交换完后,将最后一个节点(最大值)断开

2.代码实现
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
//将所有数字搞成大根堆
for (int i = 0; i < arr.length; i++) {// O(N)
heapInsert(arr, i);// O(logN)
}
int size = arr.length;
//0位置上的数与heapsize最后一个数交换
swap(arr, 0, --size);
while (size > 0) {// O(N)
//0位置上的数重新调整位置
heapify(arr, 0, size);// O(logN)
//0位置上的数与heapsize最后一个数交换,heapsize减小
swap(arr, 0, --size);// O(1)
}
}
public static void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {//当前节点数值大于父节点位置
swap(arr, index, (index - 1) /2);
index = (index - 1)/2 ;
}
}
//某数a在index位置,将其往下移动
public static void heapify(int[] arr, int index, int size) {//size为数组长度
int left = index * 2 + 1;//左孩子位置
while (left < size) {//判断孩子是否存在
//只有当右孩子存在且大于左孩子时,才取右孩子作为最大值;
//其余情况选左孩子,包括
// 1.右孩子不存在
// 2.右孩子存在但没左孩子大
//largest记录最大值的位置
int largest = left + 1 < size && arr[left + 1] > arr[left] ? left + 1 : left;
//比较父节点和大孩子之间谁大,记录下大的值的位置
largest = arr[largest] > arr[index] ? largest : index;
//如果父节点比较大,堆结构排好,退出
if (largest == index) {
break;
}
//孩子比较大,交换父和孩子的位置
swap(arr, largest, index);
//记录某数a的新位置
index = largest;
//记录处于新位置的某数a的左孩子
left = index * 2 + 1;
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
3.注意点
重点就是:如果我们发现
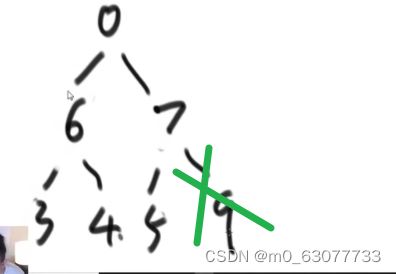
根节点与孩子节点交换顺序之后,我们就需要重新检查交换之后的孩子节点以下的所有节点是否还满足大根堆的定义,因为可能我们交换后的孩子节点的值还是比他的孩子节点要小的.就比方上面那张图里我们所看到的.所以修改后的代码主要就是加上了重新校验的过程.
4.优化 【大根堆的调整】
如果现在有一个完全二叉树,而不是一个数组,则可以使用下面这个方法
3.1 实现思路:先分成多个小树,然后再小树中形成大根堆
全部数字变成大根堆,有优化做法,最小的树做heapify,然后次小…
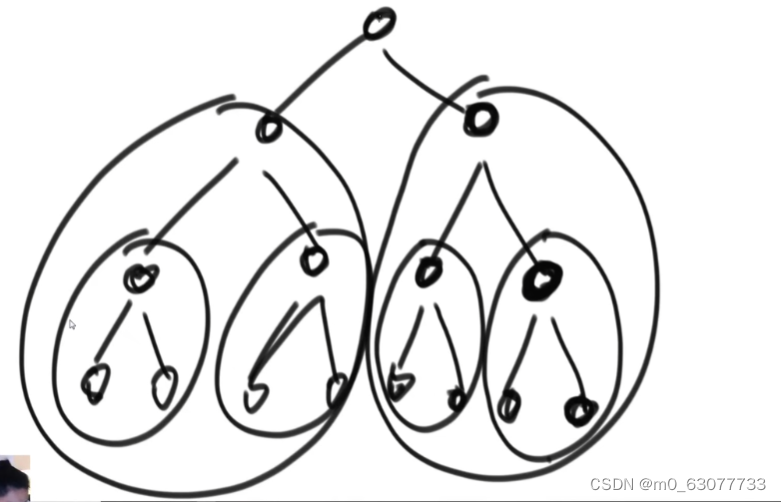
3.2 时间复杂度
假设最底层代价是1,倒数第二层代价是二,如此类推:

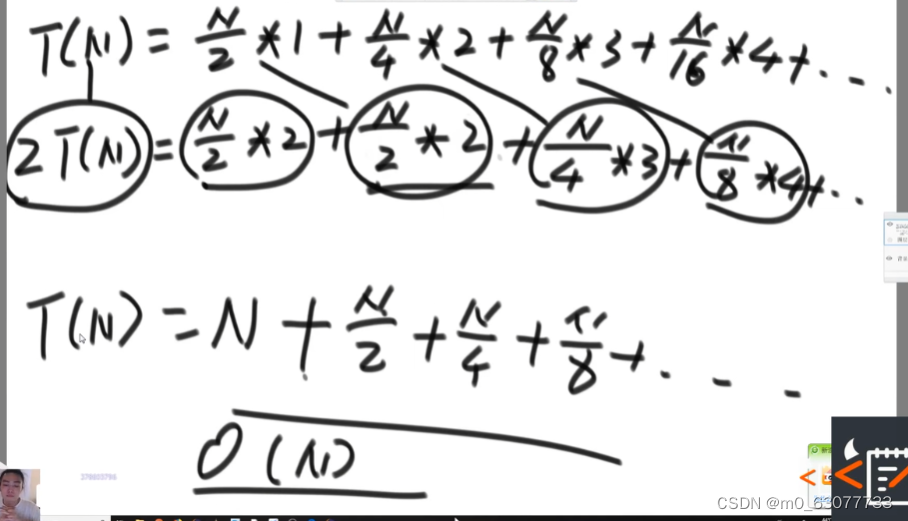
3.3 代码实现
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
//将所有数字搞成大根堆
//做法1:
// for (int i = 0; i < arr.length; i++) {// O(N)
// heapInsert(arr, i);// O(logN)
// }
//做法2:
for (int i = arr.length-1; i >= 0 ; i--) {
heapify(arr, i, arr.length);
}
int size = arr.length;
//0位置上的数与heapsize最后一个数交换
swap(arr, 0, --size);
while (size > 0) {// O(N)
//0位置上的数重新调整位置
heapify(arr, 0, size);// O(logN)
//0位置上的数与heapsize最后一个数交换,heapsize减小
swap(arr, 0, --size);// O(1)
}
}
六、堆排序扩展题目

1.实现思路
假设现在k=6,则先划分前下标为0~6的位置,因为0位置上的正确数一定在0-6这七个数中,所以将这7个数在小根堆中排好序,最小值就可以弹出放到0位置上,然后再加入下一个数,进行重复操作。
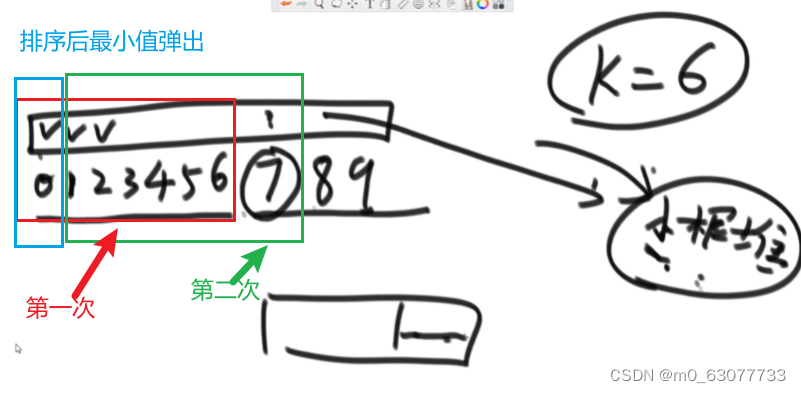
2.代码实现
public void sortedArrDistanceLessK(int[] arr, int k) {
// PriorityQueue:优先级队列的底层就是堆排序
PriorityQueue<Integer> heap = new PriorityQueue<>();
int index = 0;
//k个数形成小根堆
for (; index < Math.min(arr.length, k); index++) {
heap.add(arr[index]);
}
int i = 0;
for (; index < arr.length; i++, index++) {
heap.add(arr[index]);//加一个数
arr[i] = heap.poll();//弹出一个最小值
}
while (!heap.isEmpty()) {//依次弹出k个最小值
arr[i++] = heap.poll();
}
}
public static void main(String[] args) {
// 优先级队列默认就是小根堆
PriorityQueue<Integer> heap = new PriorityQueue<>();
heap.add(8);
heap.add(3);
heap.add(6);
heap.add(2);
heap.add(4);
while (!heap.isEmpty()){
System.out.println(heap.poll());
}
}
七、桶排序
不基于比较排序【如果很大的数组进行桶排序,则浪费空间】
1.计数排序
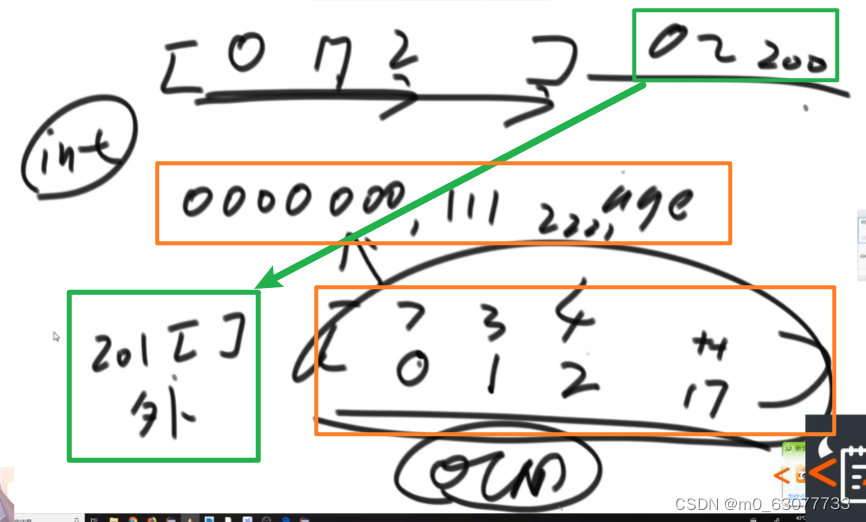
2.基数排序
根据数值中最多位数为主,不够的再数值前面补0
2.1 将根据个位数将数字添加到桶中
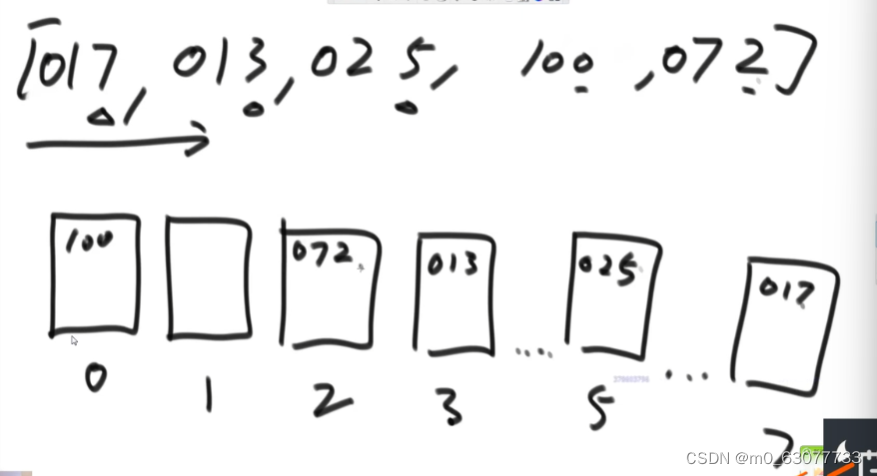
2.2 把桶从左往右导出
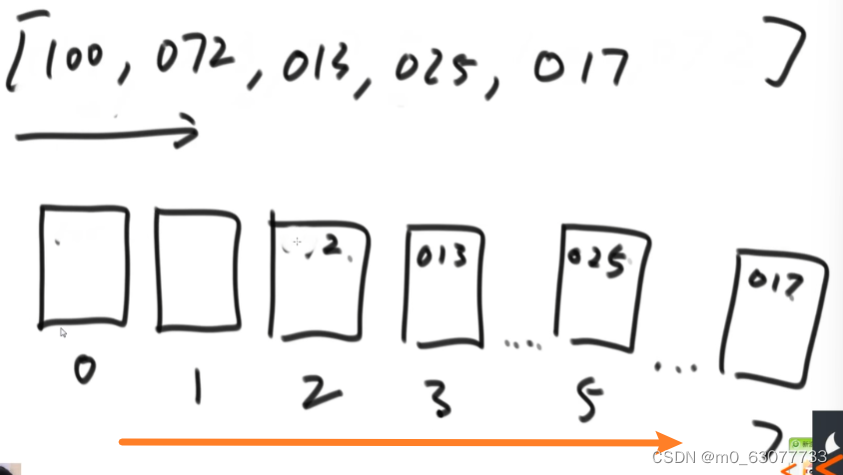
2.3 再根据十位数将数值放入桶中

2.4 再将数值输入排序
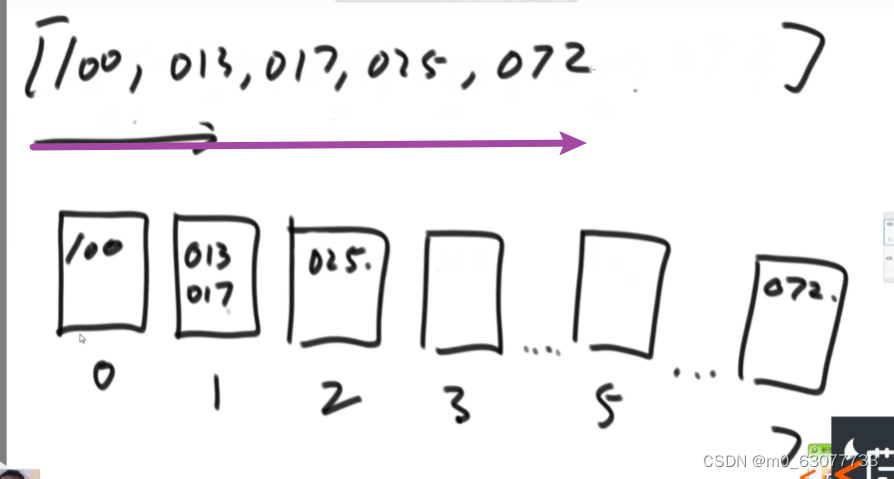
2.5 再根据百位数将数值放入桶中
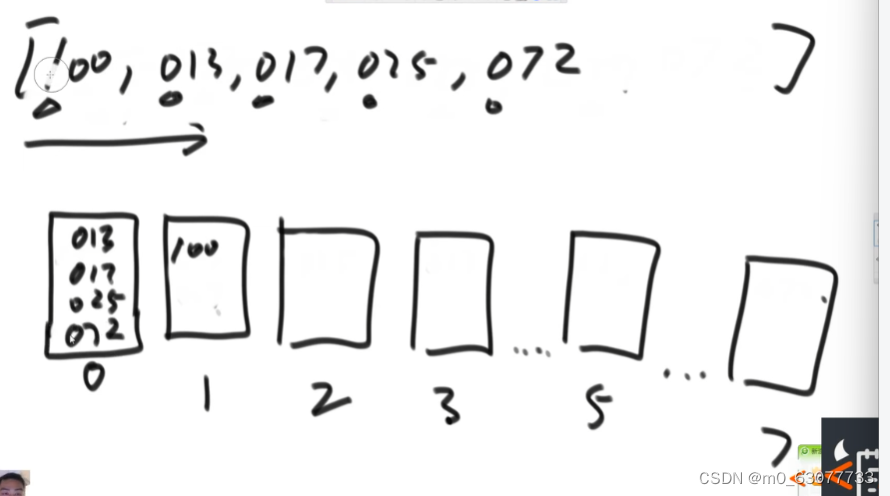
2.6 再将数值输入排序
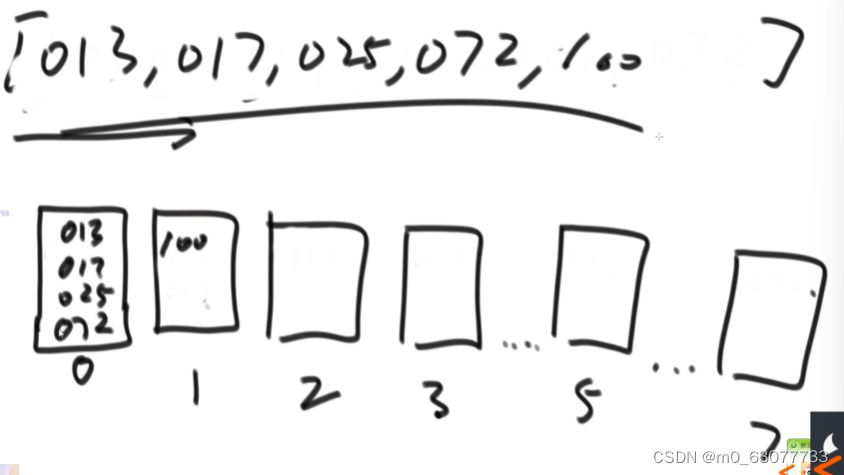
2.7 代码实现
// only for no-negative value
public static void radixSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
radixSort(arr, 0, arr.length - 1, maxbits(arr));
}
//计算最大的十进制位是第几位
public static int maxbits(int[] arr) {
int max = Integer.MIN_VALUE;
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);//寻找数组中最大的数
}
int res = 0;
while (max != 0) {
res++;
max /= 10;//自动整除,因为max是int
}
return res;
}
public static void radixSort(int[] arr, int begin, int end, int digit) {
//digit:表示几位数
//10进制的基底是10
final int radix = 10;
int i = 0, j = 0;
int[] bucket = new int[end - begin + 1];
//digit多少个十进制位,也代表入桶出桶的次数【如果是100,则要进出3次】
for (int d = 1; d <= digit; d++) {
int[] count = new int[radix];
//用于记录当前位上等于0,...,等于9的各有多少个数
for (i = begin; i <= end; i++) {
j = getDigit(arr[i], d);//确认当位上的数是多少
count[j]++;//等于该位上的数,统计加1
}
//用于记录当前位上小于等于0,...,小于等于9的各有多少个数
//同时也记录了当前位上等于0,...,等于9的数组最后一个数出桶后的位置
for (i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
for (i = end; i >= begin; i--) {
j = getDigit(arr[i], d);
bucket[count[j] - 1] = arr[i];//出桶后的位置上放该数
count[j]--;//该桶上的数减一
}
for (i = begin, j = 0; i <= end; i++, j++) {
//把bucket的数组导入arr中,相当于保留了这次桶排序
arr[i] = bucket[j];
}
}
}
3.实现思路
1.我们首先需要第一次遍历我们的序列,得到我们序列中的最大值MAX以及序列中的最小值MIN,找到我们序列中的最大值与最小值之后,那么我们就可以确定序列中的所有都是在MIN~MAX这个数据范围区间之中.
2.第二步我们就是需要根据序列的数据范围来确定我们到底需要几个桶来存放我们的元素,这一步其实是比较关键的,因为桶的数量太多或者太少都会降低桶排序的效率.【故假设桶的数量有【(max-min)/桶长+1】
3.确定完桶的数量之后,我们就可以给每个桶来划分数据范围了.一般是这样划分的,【
(MAX-MIN)/桶的数量+1】,得到的结果就是桶长.之后每个桶的数据范围就通过桶的编号以及桶长就可以确定每个桶的数据范围.就如下面的公式:左闭右开
桶的数据范围=[MIN+(桶的编号-1)*桶长,MIN+桶的编号 *桶长)=(当前数值大小-min)/桶长
有了每个桶的数据范围时候,我们第二次遍历序列将每个元素存到相应的桶里面了.这个过程我们要注意,在往桶里面添加元素的时候,就需要在每个桶里面将元素排好序.4.当我们第二次遍历结束之后,我们就只需要按照桶的编号,在将该编号的桶里面的元素打印出来,桶排序就已经完成了.
使用的公式
nums的长度为L
最小值为min
最大值为max
gap为桶的范围
gap==(max-min)/L +1
桶的个数==(max-min)/gap+1
确定将元素放入哪一个桶中==(nums[i]-min)/gap
八、排序算法的稳定性及其汇总
1.稳定性

2.排序是否可以做到稳定性
2.1 选择排序不能做到稳定性
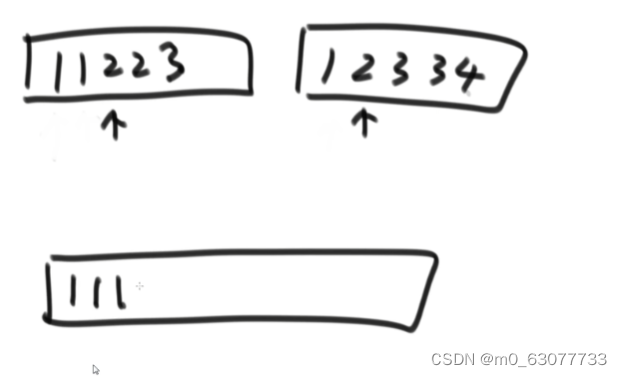
2.2 冒泡排序可以做到稳定性

2.3 插入排序可以做到稳定

2.4 归并排序可以做到稳定
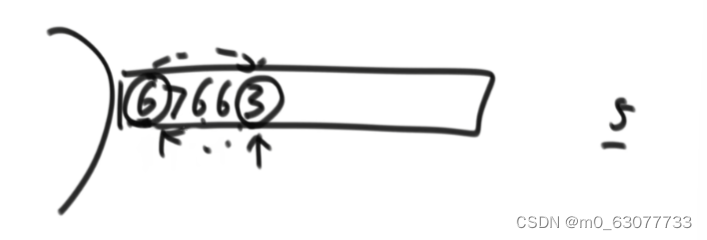
2.5 快速排序做不到稳定性
2.6 堆排序做不到稳定性

2.7 计数排序和基数排序都可以做到稳定性
3.总结

















 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









