






一、模型选择
1.支持切换思考与非思考模式
2.原生支持mcp功能,要定义可用工具,您可以使用MCP配置文件,使用Qwen-Agent集成的工具,或者自行集成其他工具。。
3.Qwen3原生支持长达32,768个token的上下文长度。对于总长度(包括输入和输出)远超这一限制的对话,我们建议使用RoPE缩放技术来有效处理长文本。我们已经通过YaN方法验证了模型在高达131,072个token的上下文长度下的性能。
4.支持标准化输出格式
5.文件大小6G
二、租用云服务器
2.1 租云服务
可以参考我前面的博客
参考完我的云服务器使用博客后,应该要达到,设置好anaconda环境。
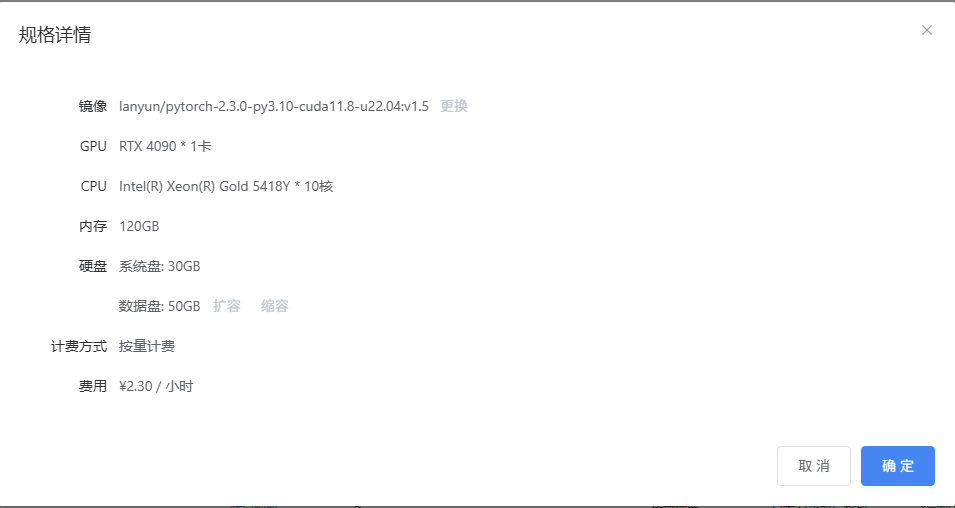
我的云服务器的配置如下图
三、下载模型和VLLM框架
3.1 下载模型到指定路径
新建一个modle的文件夹存储魔塔社区下载的模型
modelscope download --model Qwen/Qwen3-4B --local_dir /root/lanyun-tmp/modle/Qwen3-4B
上述命令,要切换到你自己的路径。
如果显示没有modelscope.
pip install modelscope
3.2 查看模型配置

{
"architectures": [
"Qwen3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 2560,
"initializer_range": 0.02,
"intermediate_size": 9728,
"max_position_embeddings": 40960,
"max_window_layers": 36,
"model_type": "qwen3",
"num_attention_heads": 32,
"num_hidden_layers": 36,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000,
"sliding_window": null,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.51.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 151936
}
上述配置信息不明白的可以复制问deepseek,此处不解释。
3.2 下载VLLM框架和启动服务
参考官方文档
创建虚拟环境和启动虚拟环境
conda create -n vllm python=3.12 -y
conda activate vllm
下载VLLM框架
pip install "vllm>=0.8.5"
启动VLLM服务
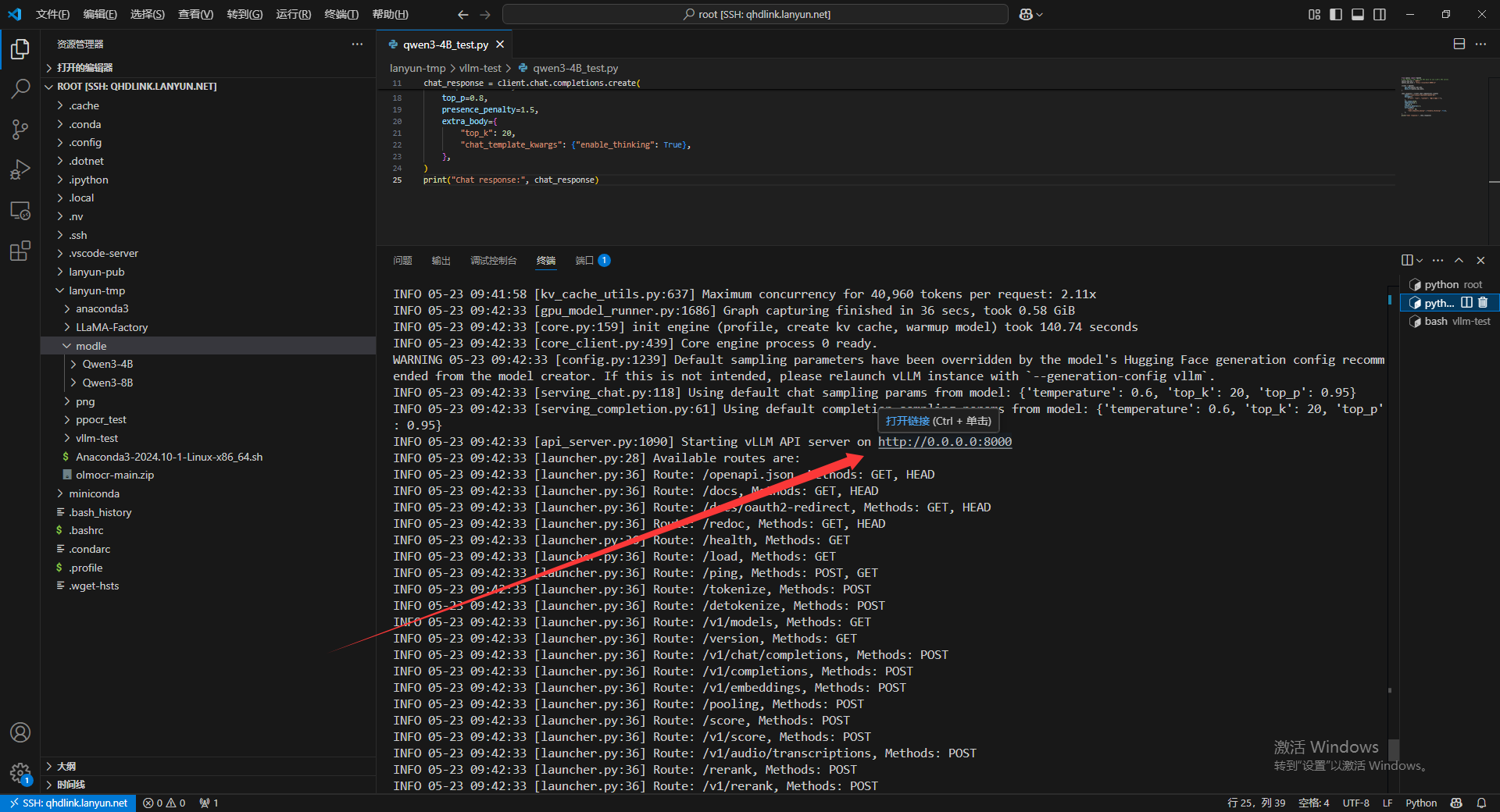
我的模型路径是 /root/lanyun-tmp/modle/Qwen3-4B ,到时候切换成自己的。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B
需要更多 vllm参数设置可以参考官网。
启动好的VLLM服务默认的URL地址,http://0.0.0.0:8000 ,这个地址和我们平常调用阿里、deepseek的URL地址没有区别,我们的/root/lanyun-tmp/modle/Qwen3-4B即是模型文件地址也是模型的名字。
3.3 下载nvitop检测资源
新建终端,执行下面命令
pip install nvitop && nvitop
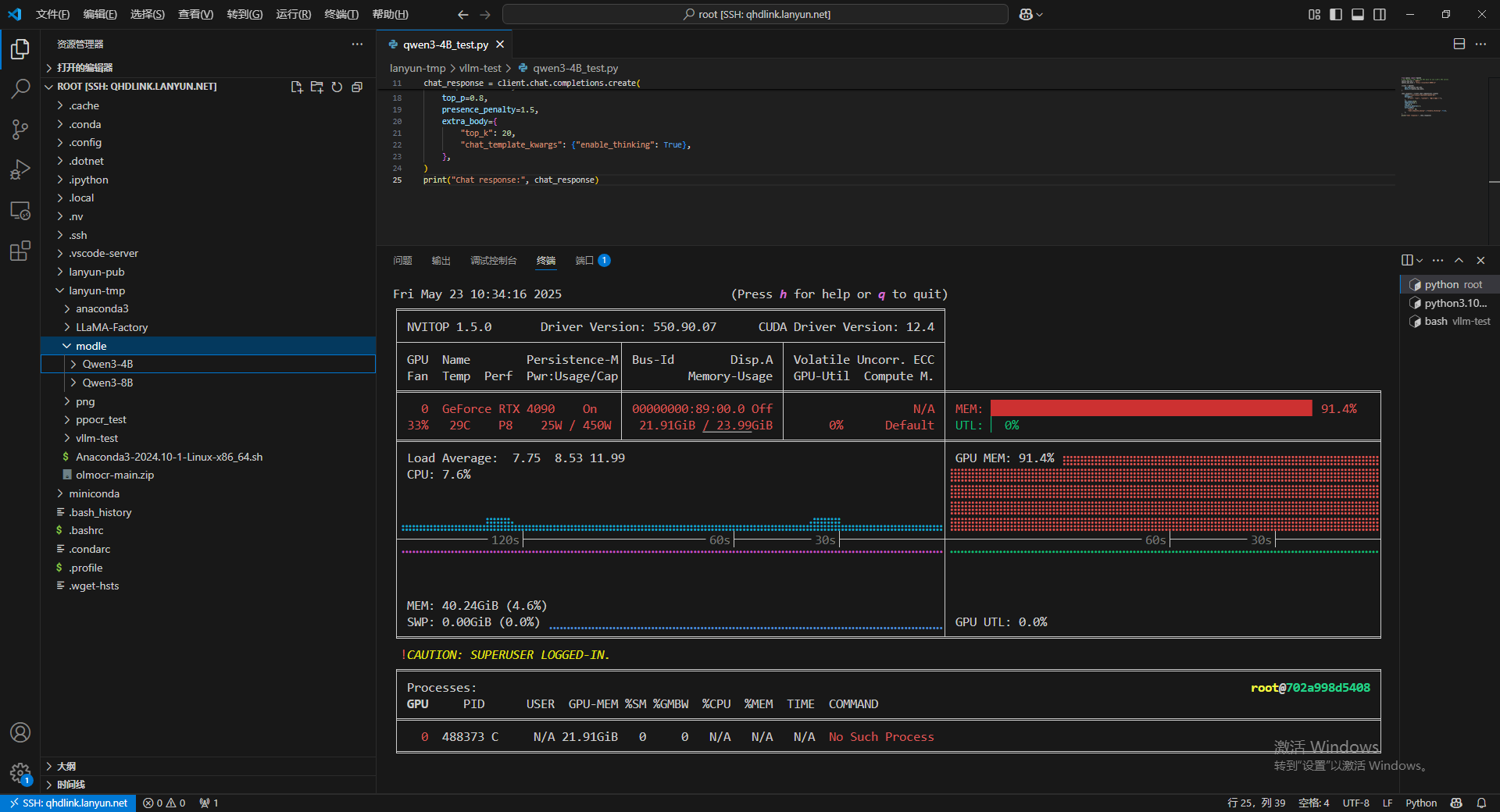
可以看到,我们VLLM服务启动后,GPU资源占了90%。
MEM是显存占用率,UTL是GPU利用率。
3.4 执行pyhon脚本,测试qwen3-4B本地模型
新建文件,qwen3-4B_test.py再保存。
# 导入OpenAI官方Python SDK(需安装openai库)
from openai import OpenAI# 本地vLLM API服务的配置(适用于自托管大模型服务)
openai_api_key = "EMPTY" # 本地部署通常无需有效API密钥[2,5](@ref)
openai_api_base = "http://localhost:8000/v1" # vLLM服务的本地地址# 初始化OpenAI客户端实例
client = OpenAI(
api_key=openai_api_key, # 传入空密钥(第三方/本地服务常见配置)
base_url=openai_api_base, # 指定API服务端点
)# 构造对话生成请求
chat_response = client.chat.completions.create(
model="/root/lanyun-tmp/modle/Qwen3-4B", # 指定本地模型路径(需确保路径正确)
messages=[
{"role": "user", "content": "你好,你是谁"}, # 用户输入的对话历史
],
# 核心生成参数配置:
max_tokens=8192, # 最大生成token数(建议根据模型最大长度设置)[7](@ref)
temperature=0.7, # 随机性控制(0-2,值越高越随机)[3,6](@ref)
top_p=0.8, # 核心采样概率(0-1,与temperature配合使用)[3,6](@ref)
presence_penalty=1.5, # 重复内容惩罚(-2~2,正值减少重复)[3,6](@ref)
# vLLM扩展参数(特定实现的附加配置)
extra_body={
"top_k": 20, # 采样时保留的最高概率token数[3](@ref)
"chat_template_kwargs": {
"enable_thinking": True # 启用模型的思考模式(特定功能)
},
},
)# 打印完整响应对象(包含元数据和生成内容)
print("Chat response:", chat_response)
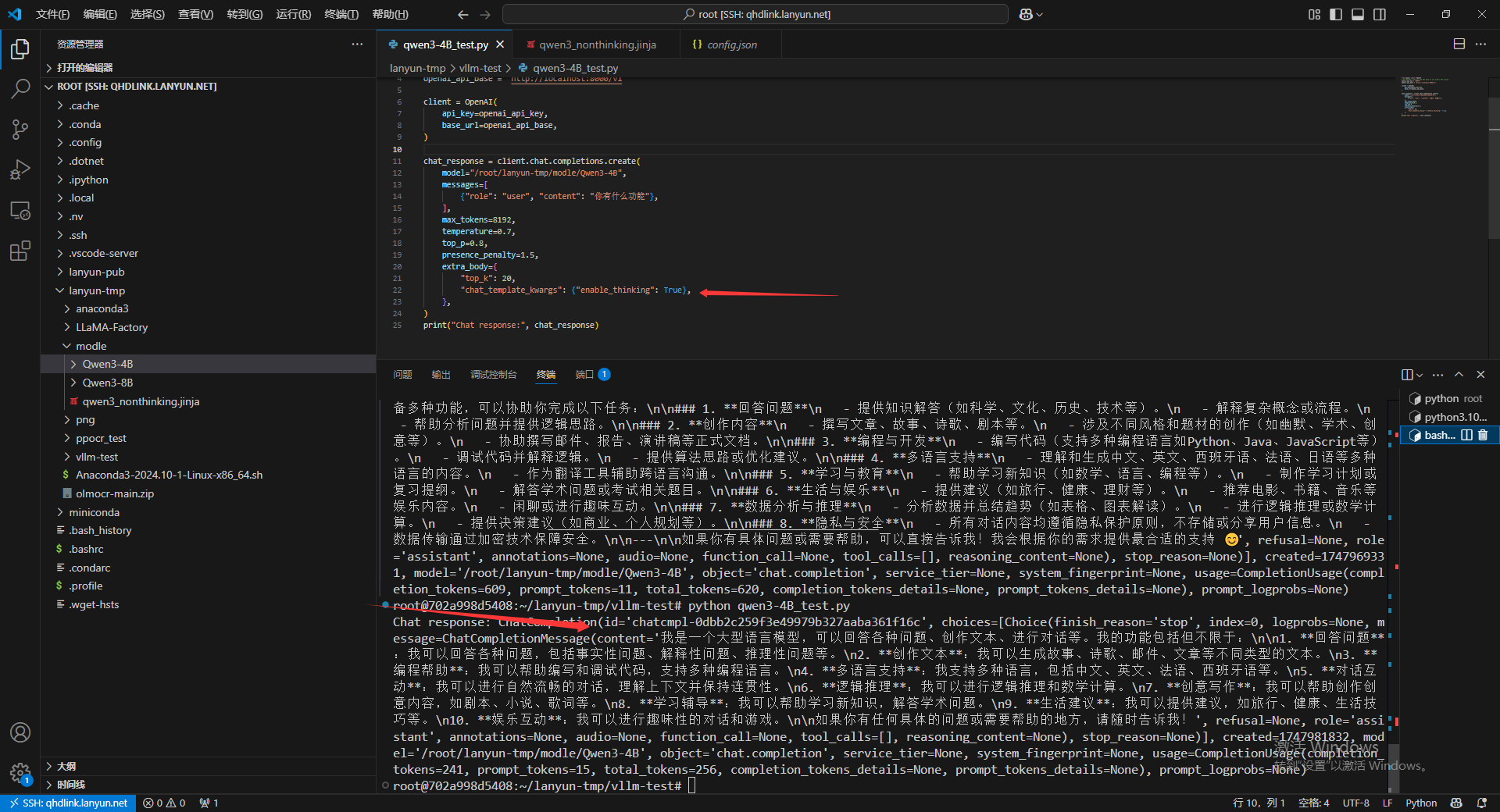
上述代码通过API调用 "enable_thinking": True # 启用模型的思考模式(特定功能)可以设置是否要思考。
新建终端,到 qwen3-4B_test.py的文件路径,执行这个文件
python qwen3-4B_test.py
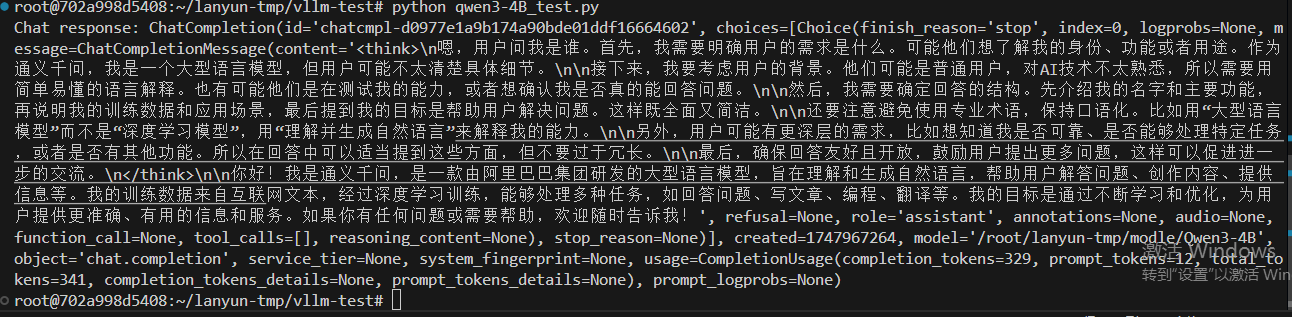
可以成功调用本地大模型。
四、使用openwebui可视化调用本地部署的大模型
🏡 家 | Open WebUI --- 🏡 Home | Open WebUI
4.1 在本地下载openwebui
创建虚拟环境,python版本必须是3.11,官网要求的,不如报错。
conda create -n vllm python=3.11 -y
conda activate vllm
不要安装最新版本的,我的会报错,一直卡住启动不了。
v0.6.10 - building the best AI user interface. https://github.com/open-webui/open-webui Fetching 30 files: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:00<?, ?it/s] INFO: Started server process [18928] INFO: Waiting for application startup. 2025-05-23 10:56:44.364 | INFO | open_webui.utils.logger:start_logger:140 - GLOBAL_LOG_LEVEL: INFO - {} 2025-05-23 10:56:44.365 | INFO | open_webui.main:lifespan:473 - Installing external dependencies of functions and tools... - {} 2025-05-23 10:56:44.378 | INFO | open_webui.utils.plugin:install_frontmatter_requirements:185 - No requirements found in frontmatter. - {}
安装这个稳定版本的。
pip install open-webui==0.5.16
启动open-webui服务
open-webui serve
4.2 配置本地大模型
不要输入0.0.0.0:8088,会网页打不开。
登入账号后,请记住,打开左下角的设置
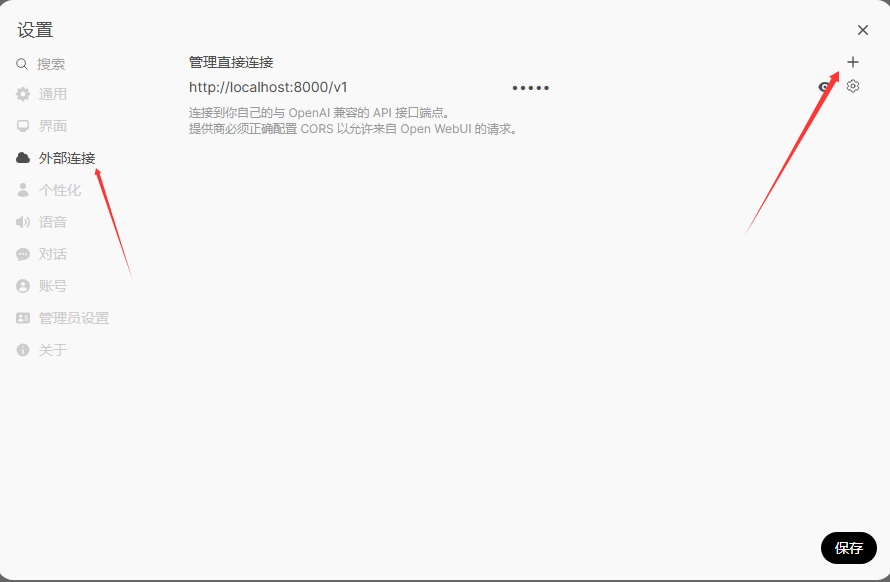
添加刚刚vllm推理的URL和模型ID
http://localhost:8000/v1
/root/lanyun-tmp/modle/Qwen3-4B
密钥随便填。
新开终端,可以测试一下8088端口有没有被占。

4.3 测试对话
4.3.1 思考模式
我们刚刚是通过
vllm serve /root/lanyun-tmp/modle/Qwen3-4B
直接部署这个模型,默认是带有推理模型,这样我们再 open-webui项目的话就是有推理的模型,不好关闭。
open-webui项目可以直接多轮对话。
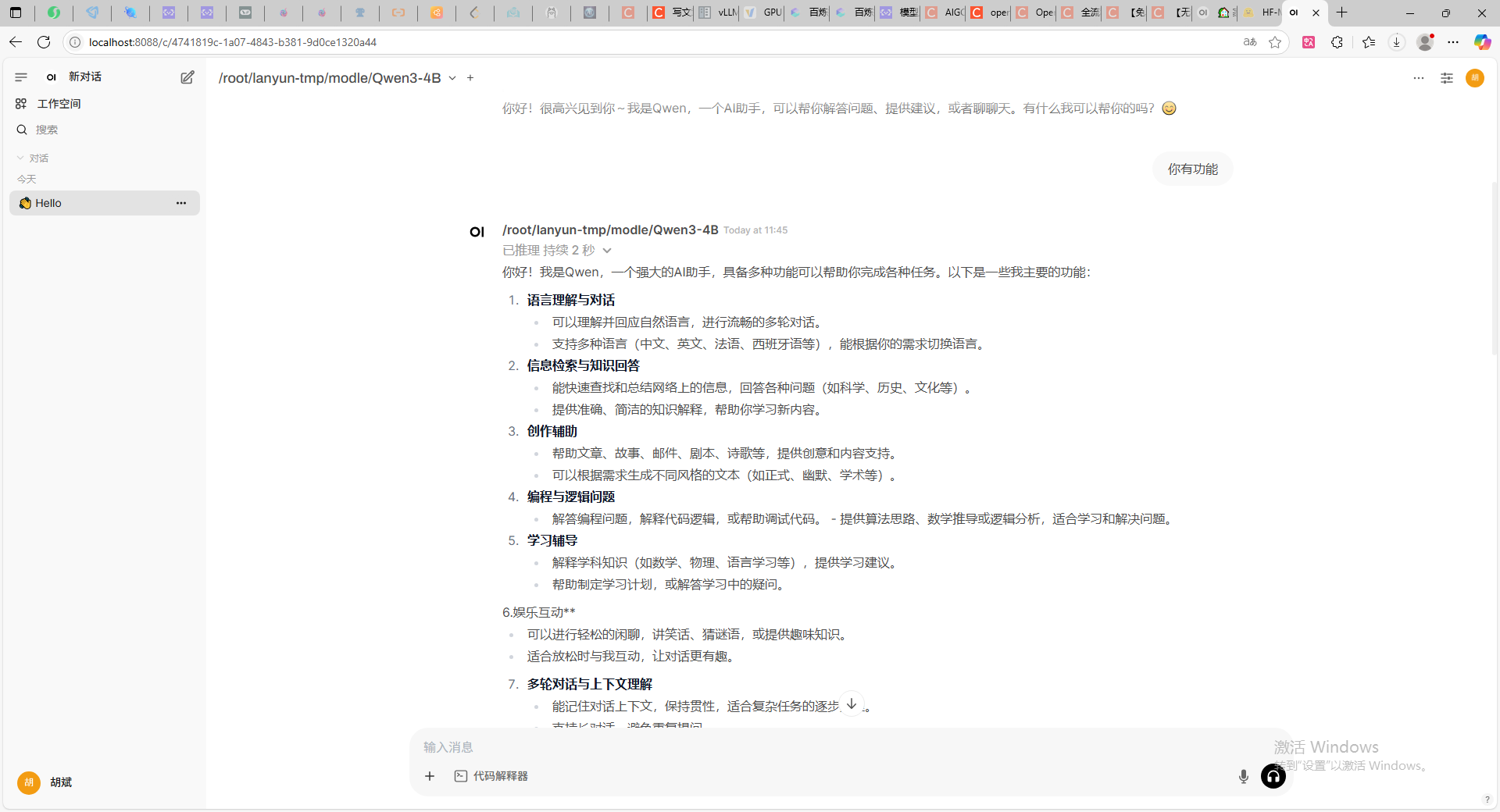
4.3.2 关闭思考模式部署本地模型
上述官网教程中,按图点击蓝色字体,会自动下载一个prompt模版
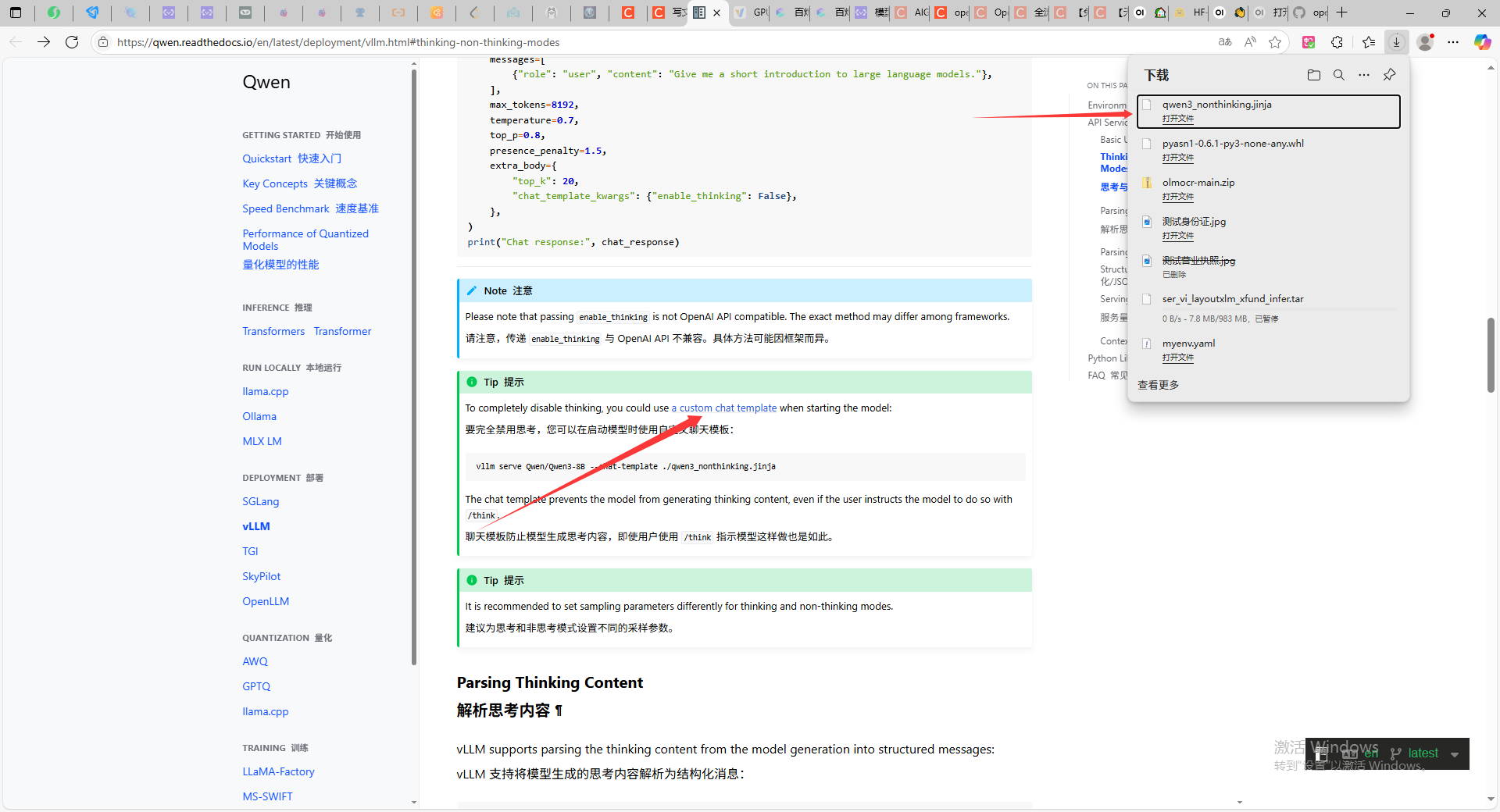
把这个prompt上传到服务器的路径下,比如我就直接放模型路径下,然后复制路径,/root/lanyun-tmp/modle/qwen3_nonthinking.jinja
关闭刚刚的VLLM服务,重新启动VLLM服务这次带上参数和,不思考的模版地址,这样后续你的这个模型无论的通过API调用还有open-webui部署都不会有思考模式。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --chat-template /root/lanyun-tmp/modle/qwen3_nonthinking.jinja
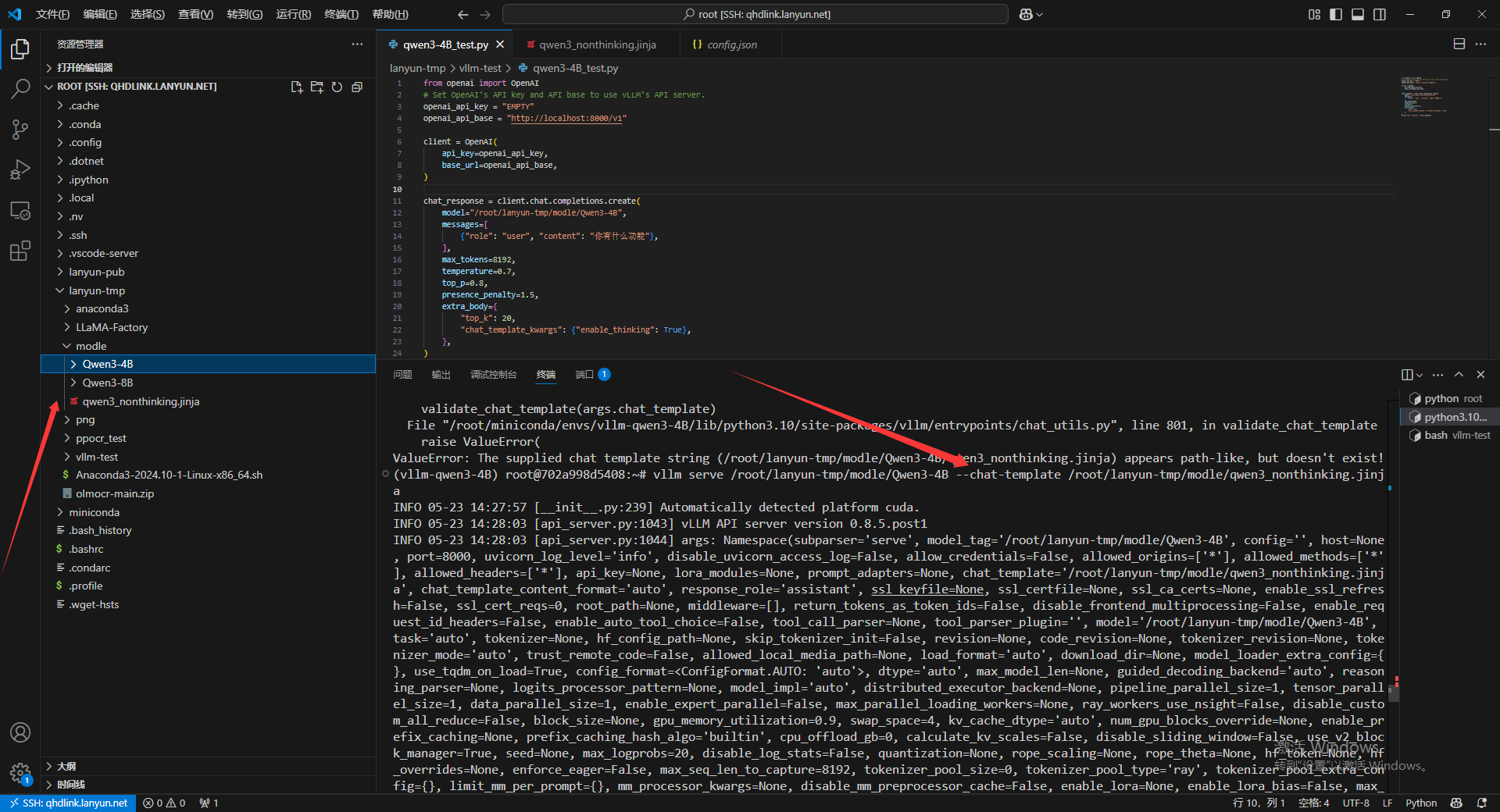 执行刚刚的python代码,可以看到,虽然我的代码已经说明要开启思考模式了,但是模型没有思考。
执行刚刚的python代码,可以看到,虽然我的代码已经说明要开启思考模式了,但是模型没有思考。
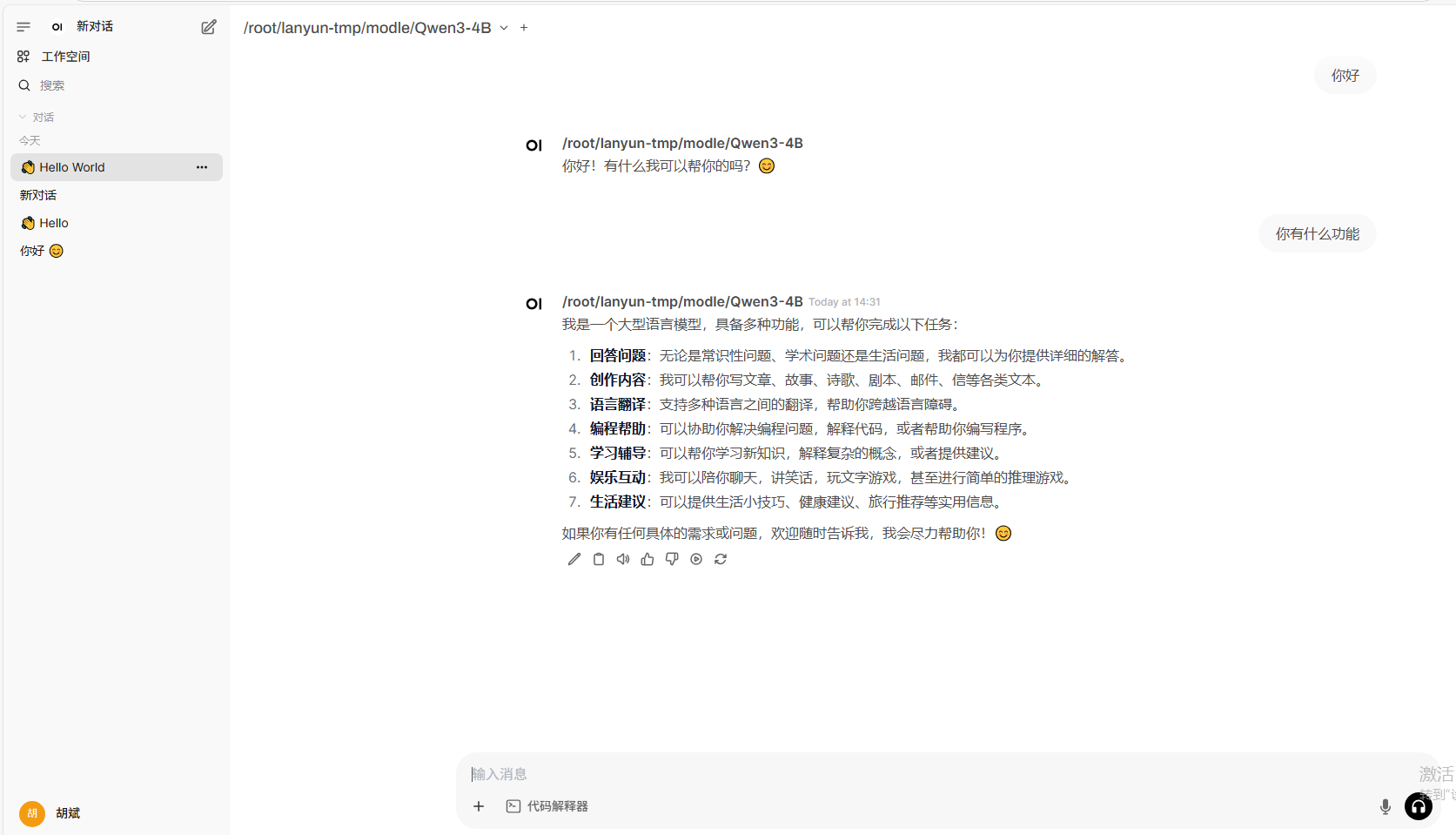
同理open-webui调用本地的大模型,也不会有思考输出。
五、小结
1.本文详细地使用VLLM框架本地部署qwen3-4B模型,混合推理如何关闭,open-webui框架的使用。
2.VLLM框架如何优化GPU显存会在下文介绍,还请点个关注。
2.有什么问题可以留言评论,或者加入我的AIGC学习交流群讨论:1051011605 ,我的博客有很多部署项目的教程,可以尝试部署AI应用,后续还有AI应用的博客持续输出,你们的喜欢是我最大的动力。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











