







目录
文章目录
对于binaryheap.cpp的分析
引言
该文件是典型的C++文件,binaryheap即二叉堆。二叉堆是一个重要的数据结构,它具有高效的时间复杂度,如插入和删除操作的时间复杂度为 O(log n),其中 n 是堆中元素的数量。该文章继承于上篇对于binaryheap.h的分析,两篇博客建议对照阅读。
二叉堆是一种特殊的二叉树数据结构,它满足以下两个性质:
-
堆属性:每个父节点的值都不小于(或不大于)其子节点的值。在本实现中,我们默认使用大根堆的属性。
-
完全二叉树:除了最底层,其他层的节点都被完全填充,且所有节点都向左对齐。
代码
代码部分挑出了一些较为重要的函数具体分析和解释,忽略了一些基本操作函数,详情可见源码
初级函数
allocate
static void sift_down(binaryheap* heap, int node_off);
static void sift_up(binaryheap* heap, int node_off);
static inline void swap_nodes(binaryheap* heap, int a, int b);
binaryheap* binaryheap_allocate(int capacity, binaryheap_comparator compare, void* arg)
{
int sz; // size of binaryheap
binaryheap* heap = NULL;// binaryheap pointer
sz = offsetof(binaryheap, bh_nodes) + sizeof(Datum) * capacity;// calculate size of binaryheap
heap = (binaryheap*)palloc(sz); // allocate memory
heap->bh_space = capacity; // set capacity
heap->bh_compare = compare; // set compare function
heap->bh_arg = arg; // set arg
heap->bh_size = 0; // set size
heap->bh_has_heap_property = true; // set heap property
return heap;
}
该函数为初始化的二叉堆分配空间(对应代码20-35行),函数的返回值是 binaryheap* 类型,接受三个参数:capacity,compare 和 arg。
首先是初始化sz作为分配空间大小为0,然后就是设置堆顶指针为空,
再接着计算sz的大小,即使用 offsetof 宏计算了 binaryheap 结构体的大小,并把它加上了 capacity 倍 sizeof(Datum) 的大小,最终得到了二叉堆的总大小 sz。然后使用 palloc 函数分配了 sz 大小的内存,并把返回的指针赋给了 heap 变量。
紧接着设置了二叉堆的空间大小、比较函数和参数。把二叉堆的大小设置为 0,表示它还没有任何元素。
把二叉堆的 heap property 标记为 true,返回二叉堆指针 heap。
calculate
static inline int left_offset(int i)
{
return 2 * i + 1; // calculate left offset
}
static inline int right_offset(int i)
{
return 2 * i + 2; // calculate right offset
}
static inline int parent_offset(int i)
{
return (i - 1) / 2; // calculate parent offset
}
二叉堆的左右孩子节点和父节点的计算方法封装
如图所示二叉堆(大顶堆),如果下标从0开始的话,构造是这样的:
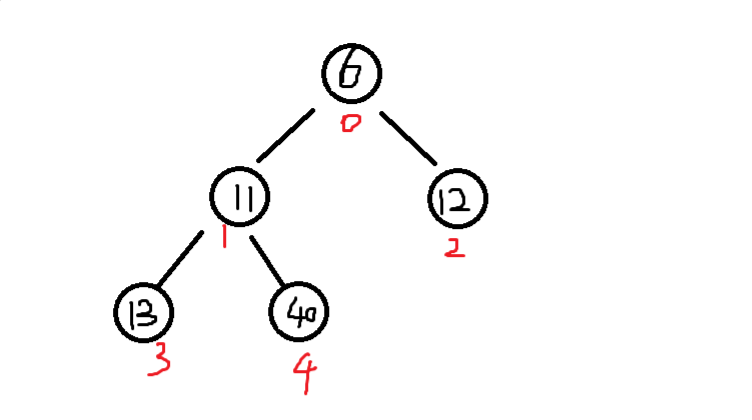
根节点的下标为0,它的左孩子下标为2 = 2 × 0+1,右孩子下标为3 = 2×0+2;
反过来,下标为1,2的节点的父节点是(1-1)/2 = (2-1)/2 = 0,同理对于下标为1的节点也是一样的道理
add_unordered
/*
* binaryheap_add_unordered
*
* Adds the given datum to the end of the heap's list of nodes in O(1) without
* preserving the heap property. This is a convenience to add elements quickly
* to a new heap. To obtain a valid heap, one must call binaryheap_build()
* afterwards.
*/
void binaryheap_add_unordered(binaryheap* heap, Datum d)
{
if (heap->bh_size >= heap->bh_space) // judge whether heap is full
elog(ERROR, "out of binary heap slots"); // throw error
heap->bh_has_heap_property = false; // set heap property
heap->bh_nodes[heap->bh_size] = d; // add node
heap->bh_size++; // increase size
}
这段代码是用于向二叉堆(binary heap)中添加元素的函数 binaryheap_add_unordered。但需要注意,该函数添加元素到堆的末尾,而不会保持堆的性质。这个函数通常用于快速将元素添加到堆中,但在使用堆之前,必须调用 binaryheap_build() 函数来确保堆性质得以恢复。
下面我将通过一个简单的例子来说明代码的工作原理:
假设有一个空的二叉堆 heap,初始状态如下:
(empty heap)
- 我们调用
binaryheap_add_unordered(heap, 20)来向堆中添加元素 20。由于堆是空的,添加操作是 O(1) 的。
20
- 然后,我们调用
binaryheap_add_unordered(heap, 10)来添加元素 10,再次添加操作是 O(1) 的。
20
/
10
- 接着,我们调用
binaryheap_add_unordered(heap, 30)来添加元素 30,仍然是 O(1) 的操作。
20
/ \
10 30
- 最后,我们调用
binaryheap_add_unordered(heap, 15)来添加元素 15。
20
/ \
10 30
/
15
需要注意的是,虽然添加操作是 O(1) 的,但在添加完所有元素后,堆的性质可能被破坏了,因此不能立即执行堆操作,如弹出最小值或最大值。为了使堆有效,需要在添加完所有元素后调用 binaryheap_build() 函数,该函数会重新组织堆以恢复堆的性质。
这个函数对于快速构建堆很有用,特别是在需要一次性添加多个元素到堆中的情况下,然后再调用 binaryheap_build() 来维护堆的性质。
高级函数
sift_up
/*
* Sift a node up to the highest position it can hold according to the
* comparator.
*/
static void sift_up(binaryheap* heap, int node_off) {
while (node_off != 0) { // loop until root
int cmp; // compare result
int parent_off; // parent offset
/*
* If this node is smaller than its parent, the heap condition is
* satisfied, and we're done.
*/
parent_off = parent_offset(node_off); // calculate parent offset
cmp = heap->bh_compare(heap->bh_nodes[node_off], heap->bh_nodes[parent_off], heap->bh_arg); // compare two nodes
if (cmp <= 0) {
break; // break loop
}
/*
* Otherwise, swap the node and its parent and go on to check the
* node's new parent.
*/
swap_nodes(heap, node_off, parent_off);
node_off = parent_off; // set new node offset
}
}
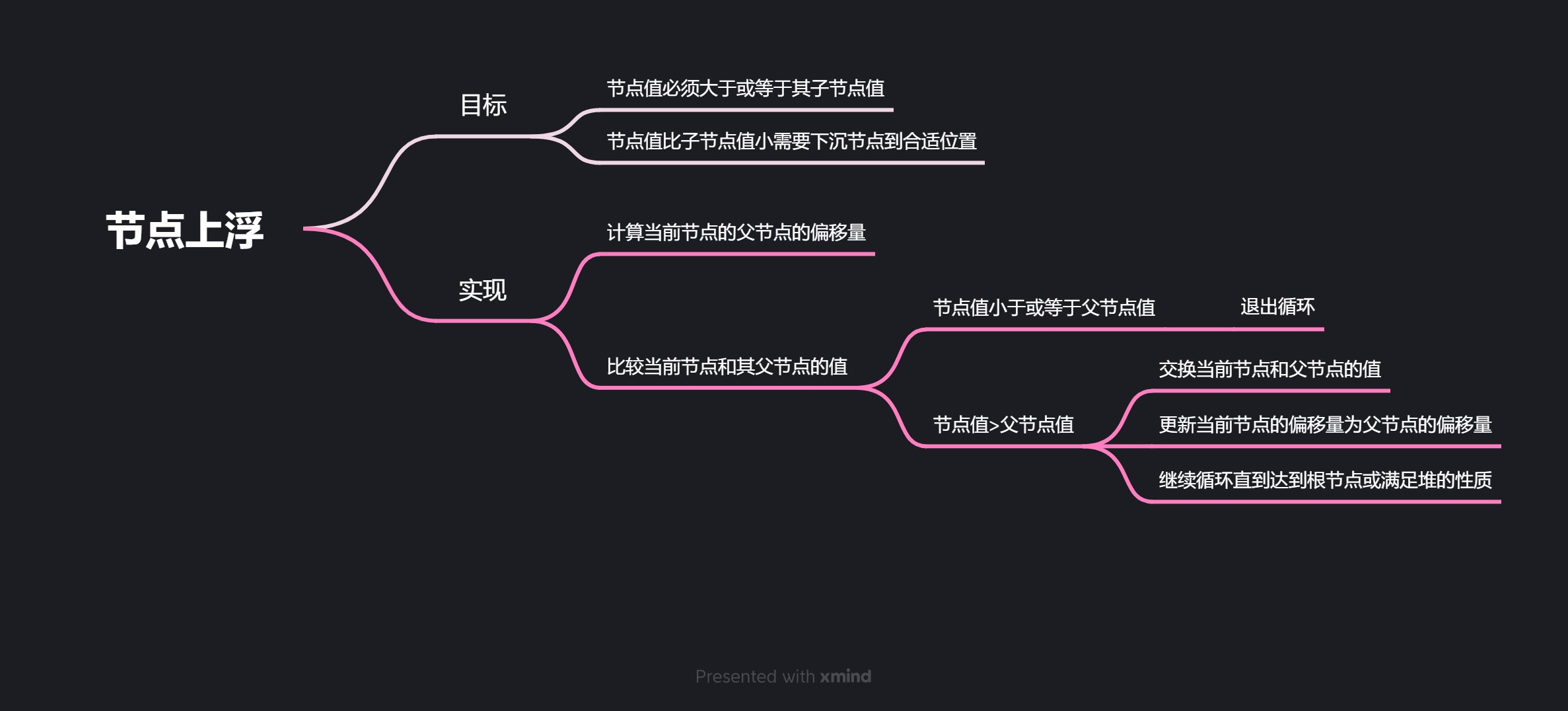
这段代码实现了二叉堆中节点上浮的功能。在二叉堆中,每个节点的值都必须大于或等于其父节点的值。如果一个节点的值比其父节点的值大,就需要将该节点上浮到合适的位置,以满足堆的性质。
具体实现如下:
-
首先,通过parent_offset函数计算出当前节点的父节点的偏移量。
-
然后,通过调用heap->bh_compare函数比较当前节点和其父节点的值,得到比较结果cmp。
-
如果cmp小于等于0,说明当前节点的值小于或等于其父节点的值,堆的性质已经满足,退出循环。
-
否则,交换当前节点和其父节点的值,然后将当前节点的偏移量更新为父节点的偏移量,继续循环直到达到根节点或堆的性质满足为止。
下面我将通过一个简单的例子来说明代码的工作原理:
假设有一个最大堆(根节点的值最大),并且我们希望插入一个新元素 60 到堆中。
初始堆状态:
50
/ \
40 30
/ \ / \
10 20 25 15
- 首先,我们将新元素 60 放在堆的底部,并将
node_off设置为新元素的位置,即 7(堆的底部,从零开始计数)。
50
/ \
40 30
/ \ / \
10 20 25 15
/
60
-
进入循环,检查新元素 60 是否大于其父节点的值。计算父节点位置:
parent_off= 3(60 的父节点位置,从零开始计数)。
-
然后,比较新元素 60 和其父节点 40 的值:
heap->bh_compare(60, 40, heap->bh_arg)返回 1(60 大于 40),所以需要交换。
-
进行节点交换,将新元素 60 和其父节点 40 交换位置,并更新
node_off为 3(父节点的位置)。
50
/ \
40 30
/ \ / \
60 20 25 15
/
10
-
再次进入循环,检查新元素 60 是否大于其父节点的值。计算父节点位置:
parent_off= 1(60 的新父节点位置)。
-
比较新元素 60 和其父节点 40 的值:
heap->bh_compare(60, 40, heap->bh_arg)返回 1(60 大于 40),所以需要再次交换。
-
进行节点交换,将新元素 60 和其父节点 40 交换位置,并更新
node_off为 1(父节点的位置)。
50
/ \
60 30
/ \ / \
40 20 25 15
/
10
-
再次进入循环,检查新元素 60 是否大于其父节点的值。计算父节点位置:
parent_off= 0(60 的新父节点位置,已经是根节点)。
-
比较新元素 60 和其父节点 50 的值:
heap->bh_compare(60, 50, heap->bh_arg)返回 1(60 大于 50),所以需要再次交换。
-
进行节点交换,将新元素 60 和其父节点 50 交换位置,并更新
node_off为 0(新根节点的位置)。
60
/ \
50 30
/ \ / \
40 20 25 15
/
10
- 由于新元素 60 不再大于其父节点的值,循环结束。此时,堆的性质得以恢复,新元素 60 处于正确的位置。
通过这个例子,可以看到 sift_up 函数的作用是将指定位置的节点向上移动,以满足二叉堆的性质,确保新插入的元素占据了正确的位置,以维护堆的性质。这是在堆排序和优先队列等算法中的重要操作。
sift_down
/*
* Sift a node down from its current position to satisfy the heap
* property.
*/
static void sift_down(binaryheap* heap, int node_off) {
while (true) {
int left_off = left_offset(node_off); // calculate left offset
int right_off = right_offset(node_off); // calculate right offset
int swap_off = 0; // swap offset
/* Is the left child larger than the parent? */
if (left_off < heap->bh_size &&
heap->bh_compare(heap->bh_nodes[node_off], heap->bh_nodes[left_off], heap->bh_arg) < 0)
swap_off = left_off; // set swap offset
/* Is the right child larger than the parent? */
if (right_off < heap->bh_size &&
heap->bh_compare(heap->bh_nodes[node_off], heap->bh_nodes[right_off], heap->bh_arg) < 0) {
/* swap with the larger child */
if (!swap_off || heap->bh_compare(heap->bh_nodes[left_off], heap->bh_nodes[right_off], heap->bh_arg) < 0)
swap_off = right_off; // set swap offset
}
/*
* If we didn't find anything to swap, the heap condition is
* satisfied, and we're done.
*/
if (!swap_off) {
break; // break loop
}
/*
* Otherwise, swap the node with the child that violates the heap
* property; then go on to check its children.
*/
swap_nodes(heap, swap_off, node_off); // swap two nodes
node_off = swap_off; // set new node offset
}
}
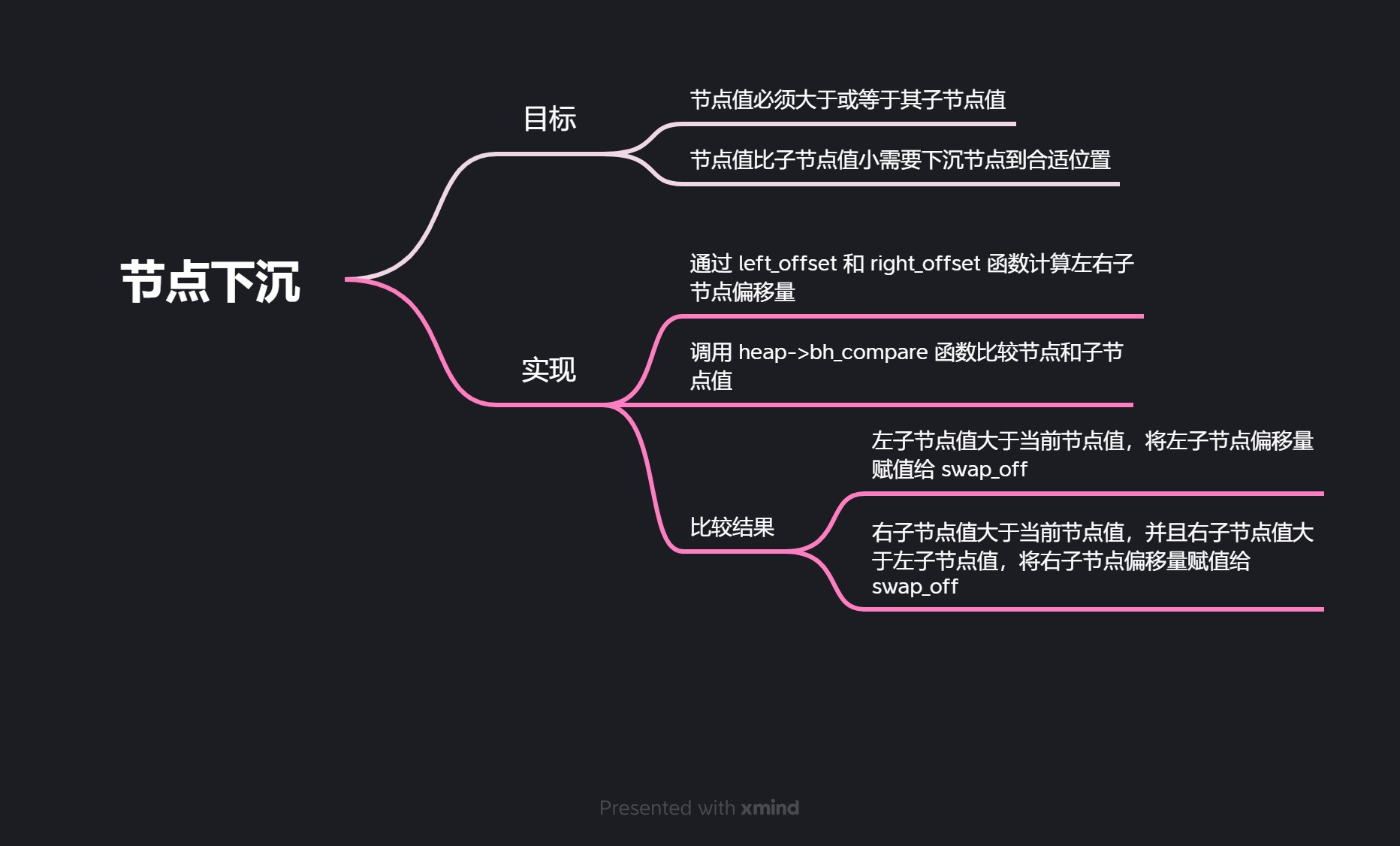
这段代码实现了二叉堆中节点下沉的功能。在二叉堆中,每个节点的值都必须大于或等于其子节点的值。如果一个节点的值比其子节点的值小,就需要将该节点下沉到合适的位置,以满足堆的性质。
具体实现如下:
- 首先,通过left_offset和right_offset函数计算出当前节点的左子节点和右子节点的偏移量。
- 然后,通过调用heap->bh_compare函数比较当前节点和其子节点的值,得到比较结果。
- 如果左子节点的值大于当前节点的值,将左子节点的偏移量赋值给swap_off。
- 如果右子节点的值大于当前节点的值,并且右子节点的值大于左子节点的值,将右子节点的偏移量赋值给swap_off。
- 如果swap_off为0,说明当前节点的值大于或等于其子节点的值,堆的性质已经满足,退出循环。
- 否则,交换当前节点和swap_off对应的子节点的值,然后将当前节点的偏移量更新为swap_off,继续循环直到达到叶子节点或堆的性质满足为止。
下面我将通过一个简单的例子来说明代码的工作原理:
假设有一个二叉堆如下所示(假设是最小堆,即根节点的值最小):
10
/ \
15 30
/ \ /
40 50 100
现在我们想执行 sift_down 操作来维护堆性质。
-
初始时,
node_off为根节点的位置,即 0。 -
首先,计算左右子节点的位置:
left_off= 1(左子节点的位置)right_off= 2(右子节点的位置)
-
然后,代码会检查左子节点是否大于当前节点(10):
heap->bh_compare(10, 15, heap->bh_arg)返回 -1(左子节点小于当前节点),所以不需要交换。
-
接着,代码会检查右子节点是否大于当前节点(10):
heap->bh_compare(10, 30, heap->bh_arg)返回 -1(右子节点小于当前节点),所以不需要交换。
-
由于左右子节点都不需要交换,所以循环结束,堆性质得以保持。
现在,如果我们要执行 sift_down 操作来移除根节点(10),我们会做以下步骤:
- 将根节点(10)与最后一个节点(100)交换,然后将堆的大小减少 1。
100
/ \
15 30
/ \
40 50
-
node_off现在是 0(新根节点的位置)。 -
计算左右子节点的位置:
left_off= 1right_off= 2
-
检查左子节点是否小于当前节点(100):
heap->bh_compare(100, 15, heap->bh_arg)返回 1,需要交换,swap_off被设置为 1。 -
接着,检查右子节点是否小于当前节点(100):
heap->bh_compare(100, 30, heap->bh_arg)返回 1,需要交换heap->bh_compare(15, 30, heap->bh_arg)返回 -1,swap_off不变 -
交换节点15,100
15 / \ 100 30 / \ 40 50node_off更新为swap_off,下标为1 -
再次进入循环,将当前节点(100)与左子节点(40)交换,并更新
swap_off为 3。15 / \ 40 30 / \ 100 50node_off更新为swap_off,下标为4 -
此时,再次检查左右子节点,但发现都不需要交换了。
-
循环结束,堆性质得以恢复。
通过这个例子,你可以看到 sift_down 函数的作用是将指定位置的节点向下移动,以满足二叉堆的性质,确保根节点是最小(或最大)的元素。这是堆排序等算法中的重要操作。
void binaryheap_build(binaryheap* heap)
{
int i; // loop variable
for (i = parent_offset(heap->bh_size - 1); i >= 0; i--) // loop from parent to root
sift_down(heap, i); // sift down
heap->bh_has_heap_property = true; // set heap property
}
void binaryheap_add(binaryheap* heap, Datum d) {
if (heap->bh_size >= heap->bh_space) // judge whether heap is full
elog(ERROR, "out of binary heap slots"); // throw error
heap->bh_nodes[heap->bh_size] = d; // add node
heap->bh_size++; // increase size
sift_up(heap, heap->bh_size - 1); // sift up
}
Datum binaryheap_remove_first(binaryheap* heap) {
Assert(!binaryheap_empty(heap) && heap->bh_has_heap_property); // judge whether heap is empty
if (heap->bh_size == 1) {
heap->bh_size--; // decrease size
return heap->bh_nodes[0]; // return first node
}
/*
* Swap the root and last nodes, decrease the size of the heap (i.e.
* remove the former root node) and sift the new root node down to its
* correct position.
*/
swap_nodes(heap, 0, heap->bh_size - 1); // swap first and last node
heap->bh_size--; // decrease size
sift_down(heap, 0); // sift down
return heap->bh_nodes[heap->bh_size]; // return first node
}
以上代码主要是几个函数
- binaryheap_build:将添加到列表的节点构建为一个二叉堆。
- binaryheap_add:在保持堆属性的情况下,将给定值添加到二叉堆中。
- binaryheap_remove_first:删除根节点,并在重新平衡堆后返回节点指针。调用前必须确保堆不为空。
- binaryheap_replace_first:替换非空堆的顶部元素,保持堆的属性。时间复杂度为O(1)~O(log n)。
build
函数定义了一循环变量i,设置i成为尾节点的父节点,然后调用sift_down(heap, i);目的是确保以当前节点为根的子树满足堆属性。如果子树不满足堆属性,它会通过交换节点的方式来恢复堆属性。最后,将堆属性标记为true
add
函数首先是检查了一下二叉堆是否已经满了(超过了预定的最大空间),如果已经满了则抛出异常。否则,添加d节点到数组末尾,增加数组长度,向上sift_up(heap,heap->bh_size - 1),目的是确保二叉堆不会被破坏
remove_first
顾名思义,这段代码是二叉堆(binary heap)中移除第一个节点的实现。
- 首先,它会判断堆是否为空,如果为空则会抛出一个错误。
- 然后,它会检查堆的大小,如果堆的大小为1,则直接减小堆的大小并返回第一个节点。
- 如果堆的大小大于1,则会将根节点和最后一个节点进行交换,减小堆的大小,并将新的根节点向下移动到正确的位置。最后,它返回被移除的第一个节点。
replace_first
顾名思义,就是替换根节点,具体步骤如下:
- 首先,使用断言确保堆不为空且具有堆属性。
- 然后,将堆的第一个节点替换为给定的节点 d。
- 如果堆中有多个节点(即堆的大小大于1),则调用 sift_down 函数将新的根节点向下移动到其正确的位置
总结
在C++中,其实封装好了二叉堆的实现,而且是以priority_queue的形式。
C++的priority_queue是STL中的一个容器,它是一个优先队列,允许我们在队列的任意位置插入元素,并按照元素的优先级顺序自动排序,队列中的元素总是按照优先级从高到低排序,即越“重要”的元素越靠前,越容易被取出。
priority_queue在头文件中,是一个模板类,使用时需要注意元素类型和比较规则(默认是小于号“<”)的指定。
通过对binaryheap.cpp的详细分析,我们可以了解到具体的二叉堆的构建,维护,修改的整个过程,阅读这类源码可以极大地锻炼我们的底层理解能力,同时也让我们对数据结构之间的认识更加深刻。















 13
13











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









